
This article was originally published on The New Stack (opens new window)
Large Language Models (LLMs) are smart enough to understand context. They can answer questions, leveraging their vast training data to provide coherent and contextually relevant responses, no matter whether the topic is astronomy, history, or even physics. However, due to their inability to connect the dots and remember all the details, LLMs, especially the smaller models like llama2-13b-chat, can hallucinate even when the requested knowledge is in the training data.
A new technique, Retrieval Augmented Generation (RAG), fills the knowledge gaps, reducing hallucinations by augmenting prompts with external data. Combined with a vector database (like MyScale (opens new window)), it substantially increases the performance gain in extractive question-answering systems, even with exhaustive knowledge bases like Wikipedia in the training set.
To this end, this article focuses on determining the performance gain with RAG on the widely-used MMLU dataset. We find that both the performance of commercial and open source LLMs can be significanlty improved when knowledge can be retrieved from Wikipedia using a vector database. More interestingly, this result is achieved even when Wikipedia is already in the training set of these models.
You can find the code for the benchmark framework and this example here (opens new window).
# Retrieval Augmented Generation
But first, let's describe Retrieval Augmented Generation (RAG).
Research projects aim to enhance LLMs like gpt-3.5 by coupling them with external knowledge bases (like Wikipedia), databases, or the Internet to create more knowledgeable and contextually-aware systems. For example, let's assume a user asks an LLM what Newton's most important result is. To help the LLM retrieve the correct information, we can search for Newton's wiki and provide the wiki page as context to the LLM.
This method is called Retrieval Augmented Generation (RAG). Lewis et al. in Retrieval Augmented Generation for Knowledge-Intensive NLP Tasks (opens new window) define Retrieval Augmented Generation as:
"A type of language generation model that combines pre-trained parametric and non-parametric memory for language generation."
Moreover, the authors of this academic paper go on to state that they:
"Endow pre-trained, parametric-memory generation models with a non-parametric memory through a general-purpose fine-tuning approach."
Note:
Parametric-memory LLMs are massive self-reliant knowledge repositories like ChatGPT and Google's PaLM. Non-parametric memory LLMs leverage external resources that add additional context to parametric-memory LLMs.
Combining external resources with LLMs seems feasible as LLMs are good learners, and referring to specific external knowledge domains can improve truthfulness. But how much of an improvement will this combination be?
Two major factors affect a RAG system:
- How much an LLM can learn from the external context
- How accurate and related the external context is
Both of these factors are hard to evaluate. The knowledge gained by the LLM from the context is implicit, so the most practical way to assess these factors is to examine the LLM's answer. However, the accuracy of the retrieved context is also tricky to evaluate.
Measuring the relevance between paragraphs, especially in question answering or information retrieval, can be a complex task. The relevance assessment is crucial to determine whether a given section contains information directly related to a specific question. This is especially important in tasks that involve extracting information from large datasets or documents, like the WikiHop (opens new window) dataset.
Sometimes, datasets employ multiple annotators to assess the relevance between paragraphs and questions. Using multiple annotators to vote on relevance helps mitigate subjectivity and potential biases that can arise from individual annotators. This method also adds a layer of consistency and ensures that the relevance judgment is more reliable.
As a consequence of all these uncertainties, we developed an open-sourced end-to-end evaluation of the RAG system. This evaluation considers different model settings, retrieval pipelines, knowledge base choices, and search algorithms.
We aim to provide valuable baselines for RAG system designs and hope that more developers and researchers join us in building a comprehensive and systematic benchmark. More results will help us disentangle these two factors and create a dataset closer to real-world RAG systems.
Note:
Share your evaluation results at GitHub (opens new window). PRs are very welcome!
# A Simple End-to-End Baseline for a RAG System
![]()
In this article, we focus on a simple baseline evaluated on an MMLU (Massive Multitask Language Understanding) Dataset (opens new window), a widely used benchmark for LLMs (opens new window), containing multiple-choice single-answer questions on many subjects like history, astronomy, and economy.
We set out to find out if an LLM can learn from extra contexts by letting it answer multiple-choice questions.
To achieve our aim, we chose Wikipedia as our source of truth because it covers many subjects and knowledge domains. And we used the version cleaned by Cohere.ai (opens new window) on Hugging Face, which includes 34,879,571 paragraphs belonging to 5,745,033 titles. An exhaustive search of these paragraphs will take quite a long time, so we need to use the appropriate ANNS (Approximate Nearest Neighbor Search) algorithms to retrieve relevant documents. Additionally, we use the MyScale database with the MSTG vector index to retrieve the relevant documents.
# Semantic Search Model
Semantic search is a well-researched topic with many models (opens new window) with detailed benchmarks (opens new window) available. When incorporated with vector embeddings, semantic search gains the ability to recognize paraphrased expressions, synonyms, and contextual understanding.
Moreover, embeddings provide dense and continuous vector representations that enable the calculation of meaningful metrics of relevance. These dense metrics capture semantic relationships and context, making them valuable for assessing relevance in LLM information retrieval tasks.
Taking into account the factors mentioned above, we have decided to use the paraphrase-multilingual-mpnet-base-v2 (opens new window) model from Hugging Face to extract features for retrieval tasks. This model is part of the MPNet family, designed to generate high-quality embeddings suitable for various NLP tasks, including semantic similarity and retrieval.
# Large Language Models (LLMs)
For our LLMs, we chose OpenAI's gpt-3.5-turbo and llama2-13b-chat with quantization in 6 bits. These models are the most popular in commercial and open-source trends. The LLaMA2 model is quantized by llama.cpp (opens new window). We chose this 6-bit quantization setup because it is affordable without sacrificing performance.
Note:
You can also try other models to test their RAG performance.
# Our RAG System
The following image describes how to formulate a simple RAG system:
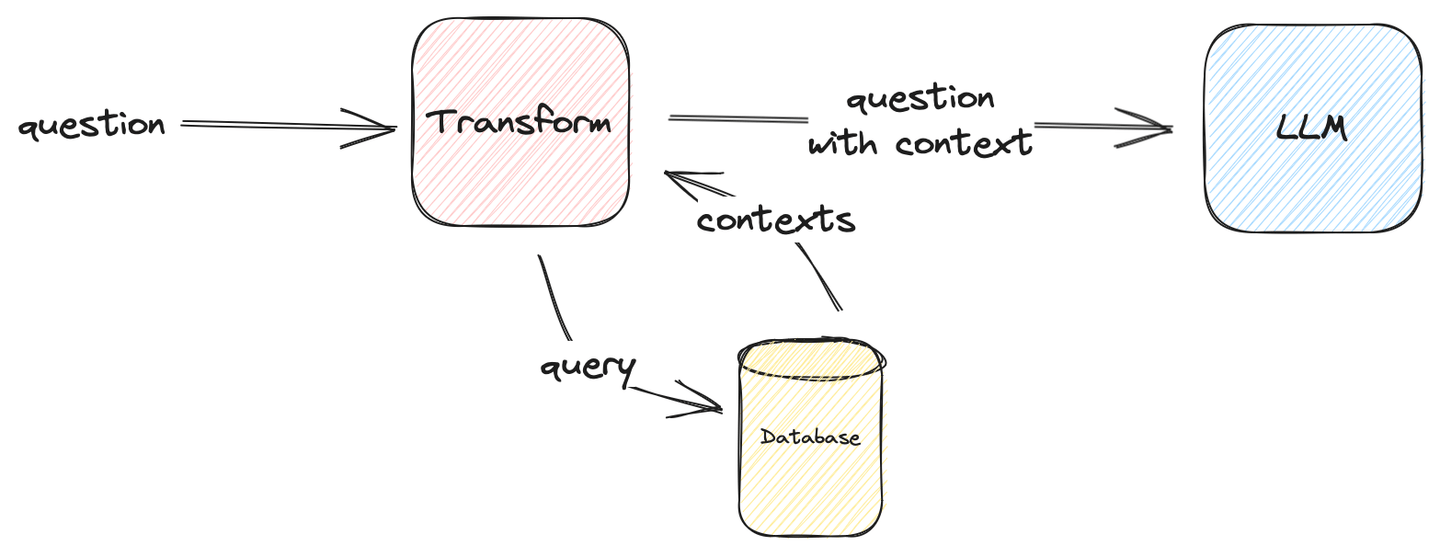
Figure 1: Simple Benchmarking RAG
Note:
Transform can be anything as long as it can be fed into the LLM, returning the correct answer. In our use case, Transform injects context to the question.
Our final LLM prompt is as follows:
template = \
("The following are multiple choice questions (with answers) with context:"
"\n\n{context}Question: {question}\n{choices}Answer: ")
Now let's move on to the result!
# Several Benchmarking Insights
Our benchmark test results are collated in Table 1 below.
But first, our summarized findings are:
Table 1: Retrieval Accuracy with Different Contexts
| Setup | Dataset | Average | |||||
|---|---|---|---|---|---|---|---|
| LLM | Contexts | mmlu-astronomy | mmlu-prehistory | mmlu-global-facts | mmlu-college-medicine | mmlu-clinical-knowledge | |
| gpt-3.5-turbo | ❌ | 71.71% | 70.37% | 38.00% | 67.63% | 74.72% | 68.05% |
| ✅ (Top-1) | 75.66% (+3.95%) | 78.40% (+8.03%) | 46.00% (+8.00%) | 67.05% (-0.58%) | 73.21% (-1.51%) | 71.50% (+3.45%) | |
| ✅ (Top-3) | 76.97% (+5.26%) | 81.79% (+11.42%) | 48.00% (+10.00%) | 65.90% (-1.73%) | 73.96% (-0.76%) | 72.98% (+4.93%) | |
| ✅ (Top-5) | 78.29% (+6.58%) | 79.63% (+9.26%) | 42.00% (+4.00%) | 68.21% (+0.58%) | 74.34% (-0.38%) | 72.39% (+4.34%) | |
| ✅ (Top-10) | 78.29% (+6.58%) | 79.32% (+8.95%) | 44.00% (+6.00%) | 71.10% (+3.47%) | 75.47% (+0.75%) | 73.27% (+5.22%) | |
| llama2-13b-chat-q6_0 | ❌ | 53.29% | 57.41% | 33.00% | 44.51% | 50.19% | 50.30% |
| ✅ (Top-1) | 58.55% (+5.26%) | 61.73% (+4.32%) | 45.00% (+12.00%) | 46.24% (+1.73%) | 54.72% (+4.53%) | 55.13% (+4.83%) | |
| ✅ (Top-3) | 63.16% (+9.87%) | 63.27% (+5.86%) | 49.00% (+16.00%) | 46.82% (+2.31%) | 55.85% (+5.66%) | 57.10% (+6.80%) | |
| ✅ (Top-5) | 63.82% (+10.53%) | 65.43% (+8.02%) | 51.00% (+18.00%) | 51.45% (+6.94%) | 57.74% (+7.55%) | 59.37% (+9.07%) | |
| ✅ (Top-10) | 65.13% (+11.84%) | 66.67% (+9.26%) | 46.00% (+13.00%) | 49.71% (+5.20%) | 57.36% (+7.17%) | 59.07% (+8.77%) | |
| * The benchmark uses MyScale MSTG as a vector index * This benchmark can be reproduced with our GitHub repository retrieval-qa-benchmark | |||||||
# 1. Extra Context Usually Helps
In these benchmarking tests, we compared performance with and without context. The test without context represents how internal knowledge can solve questions. Secondly, the test with context shows how an LLM can learn from context.
Note:
Both llama2-13b-chat and gpt-3.5-turbo are enhanced by around 3-5% overall, even with only one extra context.
The table reports that some numbers are negative, for example, when we insert context into clinical-knowledge to gpt-3.5-turbo.
This might be related to the knowledge base, saying that Wikipedia does not have much information on clinical knowledge or because OpenAI's terms of use and guidelines are clear that using their AI models for medical advice is strongly discouraged and may even be prohibited. Despite this, the increase is quite evident for both models.
Notably, the gpt-3.5-turbo results claim that the RAG system might be powerful enough to compete with other language models. Some of the reported numbers, such as those on prehistory and astronomy are pushing towards the performance of gpt4 with extra tokens, suggesting RAG could be another solution to specialized Artificial General Intelligence (AGI) when compared to fine-tuning.
Note:
RAG is more practical than fine-tuning models as it is a plug-in solution and works with both self-hosted and remote models.
# 2. More Context Sometimes Helps
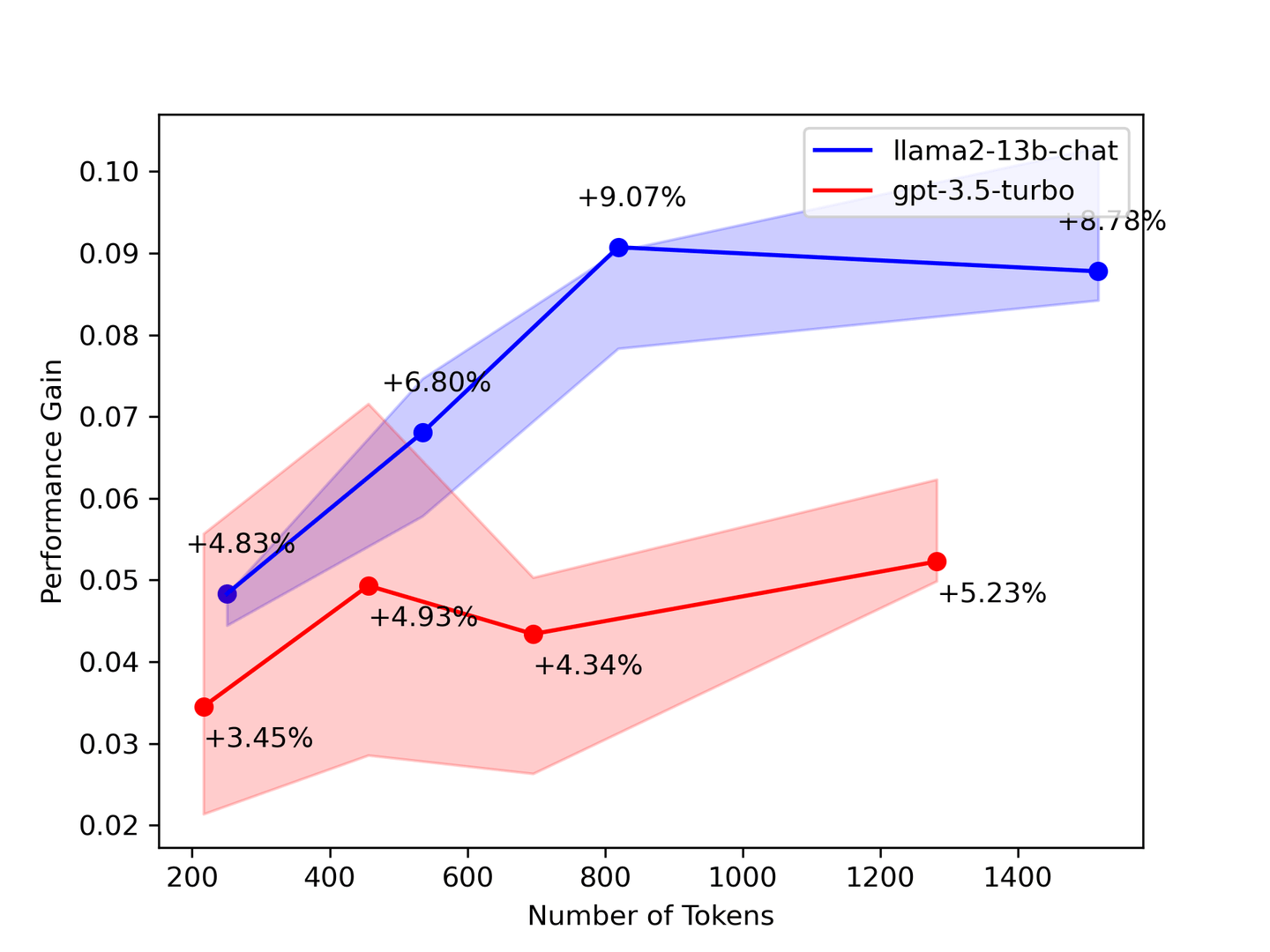
Figure 2: Performance Gain vs. the Number of Contexts
The benchmark above suggests that you need as much context as possible. In most cases, LLMs will learn from all the supplied contexts. Theoretically, the model provides better answers as the number of retrieved documents is increased. However, our benchmarking shows that some numbers dropped the greater the contexts retrieved.
By way of validating our benchmarking results, a paper by Stanford University titled: "Lost in the Middle: How Language Models Use Long Contexts" (opens new window) suggests the LLM only looks at the context's head and tail. Therefore, choose fewer but more accurate contexts from the retrieval system to augment your LLM.
# 3. Smaller Models are Hungrier for Knowledge
The larger the LLM, the more knowledge it stores. Larger LLMs tend to have a greater capacity to store and understand information, which often translates to a broader knowledge base of generally understood facts. Our benchmarking tests tell the same story: the smaller LLMs lack knowledge and are hungrier for more knowledge.
Our results report that llama2-13b-chat shows a more significant increase in knowledge than gpt-3.5-turbo, suggesting context injects more knowledge into an LLM for information retrieval. Additionally, these results imply gpt-3.5-turbo was given information it already knows while llama2-13b-chat is still learning from the context.
# Last But Not Least ...
Almost every LLM uses the Wikipedia corpus as a training dataset, meaning both gpt-3.5-turbo and llama2-13b-chat should be familiar with the contexts added to the prompt. Therefore, the questions that beg are:
- What is the reason for the increases in this benchmark test?
- Is the LLM really learning using the supplied contexts?
- Or do these additional contexts help recall memories learned from the training set data?
We currently don't have any answers to these questions. As a result, research is still needed.

# Contributing to Building a RAG Benchmark Together
Contribute to research to help others.
We can only cover a limited set of evaluations in this blog. But we know more is needed. The results of every benchmark test matter, regardless of whether they are replications of existing tests or some new findings based on novel RAGs.
With the aim of helping everyone create benchmark tests to test their RAG systems, we have open-sourced our end-to-end benchmark framework (opens new window). To fork our repository, check out our GitHub page!
This framework includes the following tools:
- A universal profiler that can measure time consumption of your retreival and LLM generation.
- A graph execution engine that allows you to build complex retrieval pipeline.
- A unified configuration where you can write down all your experiment settings in one place.
It's up to you to create your own benchmark. We believe RAG can be a possible solution to AGI. Therefore, we built this framework for the community to make everything trackable and reproducible.
PRs are welcome!
# In Conclusion
We have evaluated a small subset of MMLU with a simple RAG system built with different LLMs and vector search algorithms and described our process and results in this article. We also donated the evaluation framework to the community and called for more RAG benchmarks. We will continue to run benchmarking tests and update the latest results to GitHub and the MyScale blog, so follow us on Twitter (opens new window) or join us on Discord (opens new window) to stay updated.



