In the realm of machine learning, understanding the KNN algorithm is a fundamental step towards mastering predictive modeling. Learning to implement the KNN algorithm in Python (opens new window) opens doors to a versatile and intuitive approach in classification and regression tasks (opens new window). Throughout this blog, readers will delve into the core concepts of KNN, its practical applications, and step-by-step guidance on Python implementation.
# Understanding KNN Algorithm
When exploring the KNN algorithm, it becomes evident that this approach stands out from other machine learning algorithms due to its unique characteristics. Unlike many algorithms, KNN is non-parametric (opens new window), meaning it doesn't assume a specific data distribution (opens new window). This flexibility allows it to handle multi-class classification problems without extensive modifications. Moreover, KNN is known for its simplicity and ease of implementation, making it an excellent choice for beginners in the field of machine learning.
The power of KNN lies in its ability to calculate consistent distance measures (opens new window) between any two instances in the dataset. This distinctive feature categorizes KNN as a non-parametric or non-linear (opens new window) algorithm since it doesn't rely on predefined functional forms. By focusing on proximity rather than complex assumptions about the data, KNN offers a straightforward intuition that resonates with both novice and experienced practitioners.
Primarily used for classification tasks (opens new window), KNN excels at comparing new data entries with existing values across different classes or categories. Its versatility extends beyond traditional applications, finding relevance in various fields due to its proximity-based classification methodology. As one of the oldest and most accurate algorithms for pattern recognition and regression models, KNN continues to be a go-to choice for many data scientists seeking reliable results.
In essence, understanding the core principles behind KNN provides a solid foundation for grasping its practical implications in real-world scenarios. By embracing the simplicity and effectiveness of this algorithm, individuals can unlock a powerful tool that simplifies complex classification tasks (opens new window).
# Implementing KNN in Python
# Libraries Required
To implement the KNN algorithm in Python (opens new window), one must leverage essential libraries to streamline the process. Scikit-learn (opens new window) serves as a pivotal tool, offering the KNeighborsClassifier (opens new window) from sklearn.neighbors to execute the k-nearest neighbors vote effectively. Additionally, incorporating other dependencies ensures a robust environment for seamless implementation.
# Step-by-Step Implementation
The journey of implementing the KNN algorithm in Python embarks with meticulous data preparation (opens new window). This initial step lays the foundation for accurate predictions by organizing and structuring the dataset efficiently. Subsequently, calculating distances between data points becomes imperative to identify the nearest neighbors accurately. Lastly, making predictions based on these calculated distances refines the classification process, delivering insightful outcomes.
# Example Code
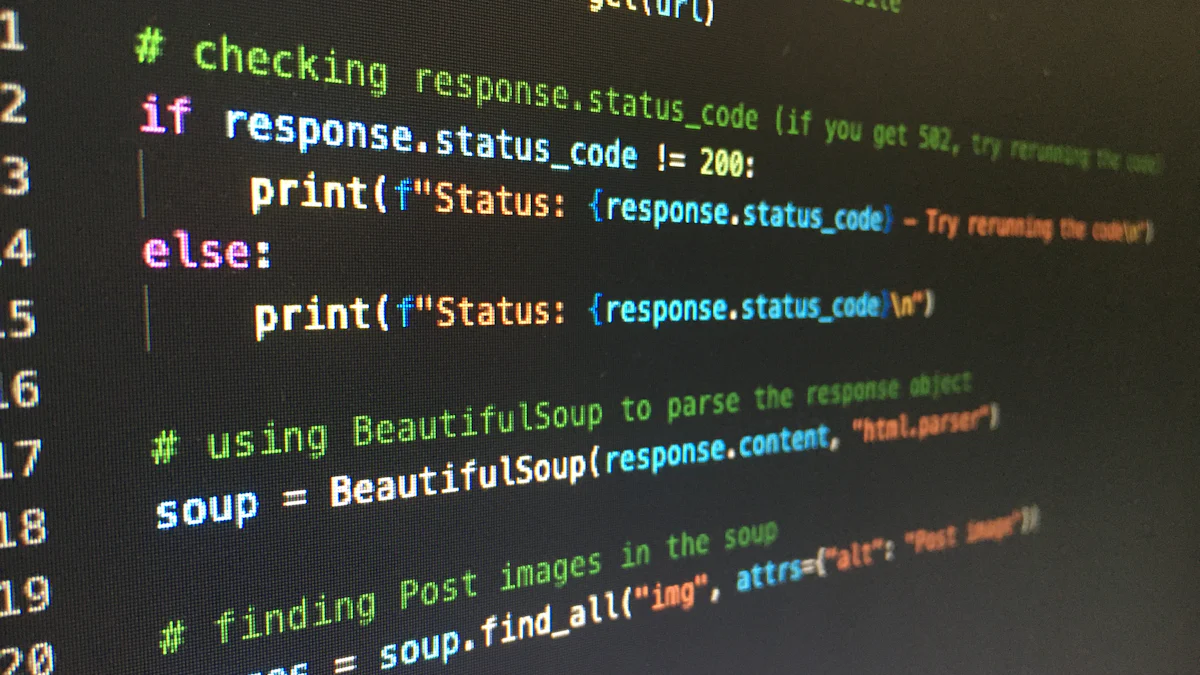
For a hands-on understanding of KNN algorithm implementation (opens new window), a code snippet can illuminate the practical application of this methodology. By dissecting and comprehending each segment of the code, individuals can grasp the intricate details behind KNN's functionality. The explanation accompanying the code snippet elucidates how each line contributes to the overall prediction process, empowering enthusiasts to replicate and experiment with their datasets effectively.
# Practical Applications
# Classification Tasks
In real-world scenarios, KNN algorithm (opens new window) finds extensive applications in various classification tasks. One notable example involves the healthcare industry, where KNN aids in medical diagnosis by identifying patterns in patient data. By analyzing symptoms and historical records, healthcare professionals can leverage KNN to classify diseases accurately. Moreover, in the realm of finance, KNN plays a crucial role in fraud detection. Financial institutions utilize this algorithm to detect anomalies (opens new window) in transactions and flag potential fraudulent activities promptly.
Another intriguing application of KNN algorithm lies within the realm of image recognition. For instance, social media platforms employ KNN to categorize images based on content or user preferences. By comparing pixel values and features, the algorithm can accurately classify images into distinct categories. Furthermore, in e-commerce platforms, KNN facilitates personalized product recommendations by analyzing customer behavior and purchase history.
# Regression Tasks
In regression tasks, KNN algorithm showcases its versatility by offering precise predictions based on proximity measures. A prime example is seen in the field of real estate, where KNN assists in property price estimation. By considering similar properties' prices and characteristics within a specific vicinity, real estate agents can predict accurate property values using the algorithm's regression capabilities.
Moreover, in marketing analytics, KNN algorithm proves invaluable for predicting customer lifetime value (CLV). By analyzing past purchasing behaviors and customer demographics, businesses can forecast CLV accurately using regression techniques offered by KNN.
# Advantages and Limitations
# Pros of KNN
Simple Implementation: The straightforward nature of the KNN algorithm Python implementation makes it accessible to beginners.
Versatility: From classification to regression tasks, KNN adapts well to various scenarios.
Intuition: The proximity-based approach offers an intuitive understanding of how predictions are made.
Robustness: Despite noisy data or outliers (opens new window), KNN algorithm remains robust due to its reliance on neighboring points.
# Cons of KNN
Computationally Expensive: As the dataset grows larger, calculating distances between points becomes more computationally intensive.
Sensitivity to Outliers: Outliers can significantly impact predictions since they influence nearest neighbors' calculations.
Need for Optimal K Value: Selecting the right value for k is crucial as an inappropriate choice may lead to inaccurate predictions or classifications.
Recapping the essence of the KNN algorithm (opens new window) reveals its simplicity and effectiveness in predictive modeling. By understanding the core principles and implementation steps, individuals can harness the power of proximity-based classification for diverse tasks. Encouraging hands-on practice with real datasets empowers enthusiasts to explore the algorithm's potential fully. Embrace the intuitive nature of KNN in Python and embark on a journey towards mastering this versatile machine learning tool.