
Retrieval-augmented generation (RAG) (opens new window) has revolutionized the way we interact with data, offering unparalleled performance in similarity searches. It excels at retrieving relevant information based on simple queries. However, RAG often falls short when handling more complex tasks, such as time-based queries or intricate relational database queries. This is because RAG is primarily designed for augmented text generation with relevant information from external sources, rather than performing exact, condition-based retrievals. These limitations restrict its application in scenarios requiring precise and conditional data retrieval.
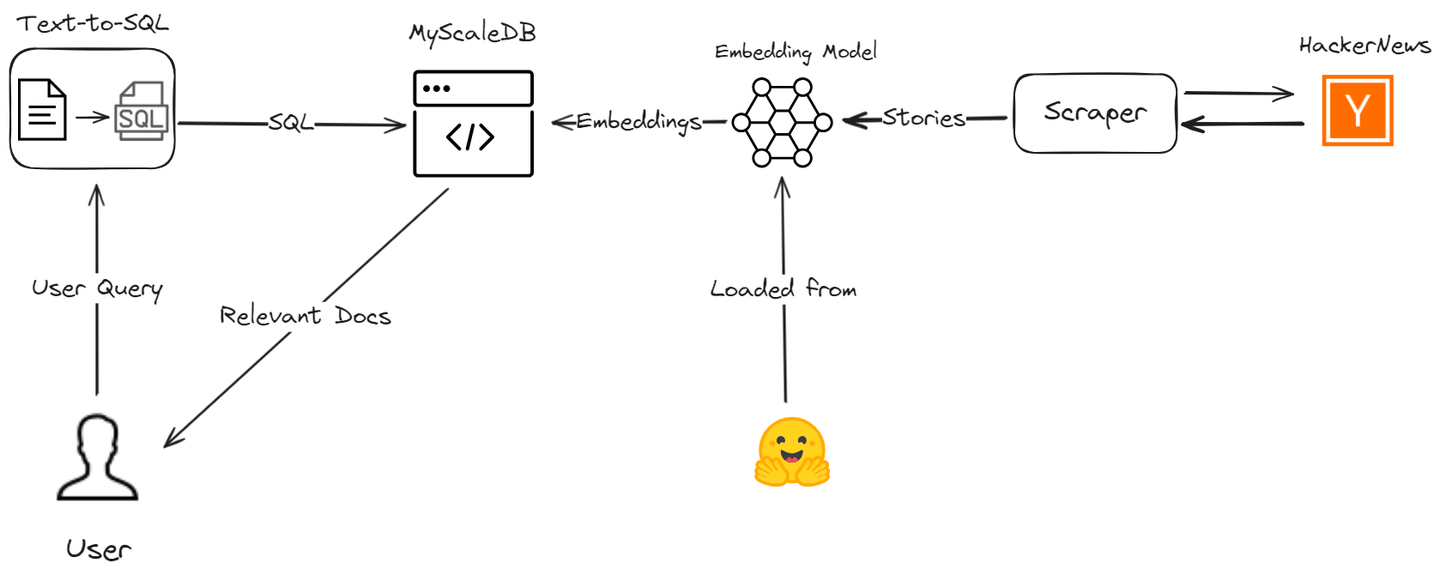
Our advanced RAG model, based on an SQL vector database, will efficiently manage various query types. It not only handles simple similarity searches but also excels in time-based queries and complex relational queries.
Let’s discuss how we overcome these RAG limitations by creating an AI assistant using MyScale (opens new window) and LangChain, enhancing both the accuracy and efficiency of the data retrieval process. We will scrape the latest stories from Hacker News and guide you through the process to demonstrate how your RAG application can be enhanced with advanced SQL vector queries.
# Tools and Technologies
We'll use several tools, including MyScaleDB, OpenAI, LangChain, Hugging Face and the HackerNews API to develop this useful application.
- MyScaleDB (opens new window): MyScale is a SQL vector database that stores and processes both structured and unstructured data efficiently.
- OpenAI (opens new window): We'll use OpenAI's chat model for generating text to SQL queries.
- LangChain: LangChain will help build the workflow and seamlessly integrate with MyScale and OpenAI.
- Hugging Face (opens new window): We'll use Hugging Face's embedding model to obtain text embeddings, which will be stored in MyScale for further analysis.
- HackerNews (opens new window) API: This API will fetch real-time data from HackerNews for processing and analysis.
# Preparation
# Setting Up the Environment
Before we start writing the code, we must ensure all the necessary libraries and dependencies are installed. You can install these using pip:
pip install requests clickhouse-connect transformers openai langchain
This pip command should install all the dependencies required in this project.
# Import Libraries and Define Helper Functions
First, we import the necessary libraries and define the helper functions that will be used to fetch and process data from Hacker News.
import requests
from datetime import datetime, timedelta
import pandas as pd
import numpy as np
# Fetch story IDs from a specific endpoint
def fetch_story_ids(endpoint):
url = f'https://hacker-news.firebaseio.com/v0/{endpoint}.json'
response = requests.get(url)
return response.json()
# Get details of a specific item by ID
def get_item_details(item_id):
item_url = f'https://hacker-news.firebaseio.com/v0/item/{item_id}.json'
item_response = requests.get(item_url)
return item_response.json()
# Recursively fetch comments for a story
def fetch_comments(comment_ids, depth=0):
comments = []
for comment_id in comment_ids:
comment_details = get_item_details(comment_id)
if comment_details and comment_details.get('type') == 'comment':
comment_text = comment_details.get('text', '[deleted]')
comment_by = comment_details.get('by', 'Anonymous')
indent = ' ' * depth * 2
comments.append(f"{indent}Comment by {comment_by}: {comment_text}")
if 'kids' in comment_details:
comments.extend(fetch_comments(comment_details['kids'], depth + 1))
return comments
# Convert list of comments to a single string
def create_comment_string(comments):
return ' '.join(comments)
# Set the time limit to 12 hours ago
time_limit = datetime.utcnow() - timedelta(hours=12)
unix_time_limit = int(time_limit.timestamp())
These functions fetch story IDs, get details of specific items, fetch comments recursively and convert comments into a single string.
# Fetch and Process Stories
Next, we fetch the latest and top stories from Hacker News and process them to extract relevant data.
# Fetch latest and top stories
latest_stories_ids = fetch_story_ids('newstories')
top_stories_ids = fetch_story_ids('topstories')
# Fetch top 20 stories
top_stories = [get_item_details(story_id) for story_id in top_stories_ids[:20]]
# Fetch all latest stories from the last 12 hours
latest_stories = [get_item_details(story_id) for story_id in latest_stories_ids if get_item_details(story_id).get('time', 0) >= unix_time_limit]
# Prepare data for DataFrame
data = []
def process_stories(stories):
for story in stories:
if story:
story_time = datetime.utcfromtimestamp(story.get('time', 0))
if story_time >= time_limit:
story_data = {
'Title': story.get('title', 'No Title'),
'URL': story.get('url', 'No URL'),
'Score': story.get('score', 0),
'Time': convert_unix_to_datetime(story.get('time', 0)),
'Writer': story.get('by', 'Anonymous'),
'Comments': story.get('descendants', 0) # Correctly handle the number of comments
}
# Fetch comments if any
if 'kids' in story:
comments = fetch_comments(story['kids'])
story_data['Comments_String'] = create_comment_string(comments)
else:
story_data['Comments_String'] = ""
data.append(story_data)
# Process latest and top stories
process_stories(latest_stories)
process_stories(top_stories)
# Create DataFrame
df = pd.DataFrame(data)
# Ensure correct data types
df['Score'] = df['Score'].astype(np.uint64)
df['Comments'] = df['Comments'].astype(np.uint64)
df['Time'] = pd.to_datetime(df['Time'])
We fetch the latest and top stories from Hacker News using the above-defined helper functions. We process the fetched stories to extract relevant information like title, URL, score, time, writer and comments. We also convert the list of comments into a single string.
# Initialize the Hugging Face Model for Embedding
We will now generate embeddings for the story titles and comments using a pre-trained model. This step is crucial for creating a retrieval-augmented generation (RAG) system.
import torch
from transformers import AutoTokenizer, AutoModel
# Initialize the tokenizer and model for embeddings
tokenizer = AutoTokenizer.from_pretrained("sentence-transformers/all-MiniLM-L6-v2")
model = AutoModel.from_pretrained("sentence-transformers/all-MiniLM-L6-v2")
# Generate embeddings after DataFrame is created
empty_embedding = np.zeros(384, dtype=np.float32) # Assuming the embedding size is 384
def generate_embeddings(texts):
inputs = tokenizer(texts, padding=True, truncation=True, return_tensors="pt", max_length=512)
with torch.no_grad():
outputs = model(**inputs)
embeddings = outputs.last_hidden_state.mean(dim=1)
return embeddings.numpy().astype(np.float32).flatten()
We load a pre-trained model for generating embeddings using the Hugging Face transformers library and generate embeddings for the story titles and comments.
# Handling Long Comments
To handle long comments that exceed the model's maximum token length, we split them into manageable parts.
# Function to handle long comments
def handle_long_comments(comments, max_length):
parts = [' '.join(comments[i:i + max_length]) for i in range(0, len(comments), max_length)]
return parts
This function splits long comments into parts that fit within the model's maximum token length.
# Process Stories for Embeddings
Finally, we process each story to generate embeddings for titles and comments and create a final DataFrame.
# Process each story for embeddings
final_data = []
for story in data:
title_embedding = generate_embeddings([story['Title']]).tolist()
comments_string = story['Comments_String']
if comments_string and isinstance(comments_string, str):
max_length = tokenizer.model_max_length # Use the model's max token length
if len(comments_string.split()) > max_length:
parts = handle_long_comments(comments_string.split(), max_length)
for part in parts:
part_comments_string = ' '.join(part)
comments_embeddings = generate_embeddings([part_comments_string]).tolist() if part_comments_string else empty_embedding.tolist()
final_data.append({
'Title': story['Title'],
'URL': story['URL'],
'Score': story['Score'],
'Time': story['Time'],
'Writer': story['Writer'],
'Comments': story['Comments'],
'Comments_String': part_comments_string,
'Title_Embedding': title_embedding,
'Comments_Embedding': comments_embeddings
})
else:
comments_embeddings = generate_embeddings([comments_string]).tolist() if comments_string else empty_embedding.tolist()
final_data.append({
'Title': story['Title'],
'URL': story['URL'],
'Score': story['Score'],
'Time': story['Time'],
'Writer': story['Writer'],
'Comments': story['Comments'],
'Comments_String': comments_string,
'Title_Embedding': title_embedding,
'Comments_Embedding': comments_embeddings
})
else:
story['Title_Embedding'] = title_embedding
story['Comments_Embedding'] = empty_embedding.tolist()
final_data.append(story)
# Create final DataFrame
final_df = pd.DataFrame(final_data)
# Ensure correct data types in the final DataFrame
final_df['Score'] = final_df['Score'].astype(np.uint64)
final_df['Comments'] = final_df['Comments'].astype(np.uint64)
final_df['Time'] = pd.to_datetime(final_df['Time'])
In this step, we process each story to generate embeddings for titles and comments, handle long comments if necessary and create a final DataFrame with all the processed data.
# Connecting to MyScaleDB And Creating the Table
MyScaleDB is an advanced SQL vector database that enhances RAG models by efficiently handling complex queries (opens new window) and similarity searches such as full-text search (opens new window) and filtered vector search (opens new window).
We will connect to MyScaleDB using clickhouse-connect and create a table to store the scraped stories.
import clickhouse_connect
client = clickhouse_connect.get_client(
host='your-host',
port=443,
username='your-username',
password='your-password'
)
client.command("DROP TABLE IF EXISTS default.posts")
client.command("""
CREATE TABLE default.posts (
id UInt64,
Title String,
URL String,
Score UInt64,
Time DateTime64,
Writer String,
Comments UInt64,
Title_Embedding Array(Float32),
Comments_Embedding Array(Float32),
CONSTRAINT check_data_length CHECK length(Title_Embedding) = 384
) ENGINE = MergeTree()
ORDER BY id
""")
This code imports the clickhouse-connect library and establishes a connection to MyScaleDB using the provided credentials. It drops the existing table default.posts if it exists, and creates a new table with the specified schema.
Note: MyScaleDB provides a free pod for vector storage of 5 million vectors. So, you can start using MyScaleDB in your RAG application without any initial payments.
# Inserting Data and Creating a Vector Index
Now, we insert the processed data into the MyScaleDB table and create an index to enable efficient retrieval of data.
batch_size = 20 # Adjust based on your needs
num_batches = len(final_df) // batch_size
for i in range(num_batches):
start_idx = i * batch_size
end_idx = start_idx + batch_size
batch_data = final_df[start_idx:end_idx]
client.insert("default.posts", batch_data, column_names=['Title', 'URL', 'Score', "Time",'Writer', 'Comments','Title_Embedding','Comments_Embedding'])
print(f"Batch {i+1}/{num_batches} inserted.")
client.command("""
ALTER TABLE default.posts
ADD VECTOR INDEX photo_embed_index Title_Embedding
TYPE MSTG
('metric_type=Cosine')
""")
This code inserts the data into the default.posts table in batches to manage large amounts of data efficiently. The vector index is created on the Title_Embedding column.
# Setting Up the Prompt Template for Query Generation
We set up a prompt template to convert natural language queries into MyScaleDB SQL queries.
prompt_template = """
You are a MyScaleDB expert. Given an input question, first create a syntactically correct MyScaleDB query to run, then look at the results of the query and return the answer to the input question.
MyScaleDB queries have a vector distance function called `DISTANCE(column, array)` to compute relevance to the user's question and sort the feature array column by relevance. The `DISTANCE(column, array)` function only accepts an array column as its first argument and a `Embeddings(entity)` as its second argument. You also need a user-defined function called `Embeddings(entity)` to retrieve the entity's array.
When the query is asking for the closest rows based on a certain keyword (e.g., "AI field" or "criticizing"), you have to use this distance function to calculate the distance to the entity's array in the vector column and order by the distance to retrieve relevant rows. If the question involves time constraints (e.g., "last 7 hours"), use the `today()` function to get the current date and time.
If the question specifies the number of examples to obtain, use that number; otherwise, query for at most {top_k} results using the LIMIT clause as per MyScale. Only order according to the distance function when necessary. Never query for all columns from a table; query only the columns needed to answer the question, and wrap each column name in double quotes (") to denote them as delimited identifiers.
Be careful to use only the column names present in the tables below and ensure you know which column belongs to which table. The `ORDER BY` clause should always be after the `WHERE` clause. Do not add a semicolon to the end of the SQL.
Pay attention to the following steps when constructing the query:
1. Identify keywords in the input question (e.g., "most voted articles," "last 7 hours," "AI field").
2. Map keywords to specific query components (e.g., "most voted" maps to "Score DESC").
3. If the question involves relevance to a keyword (e.g., "criticizing"), use the distance function. Otherwise, use standard SQL clauses.
4. If the question mentions the title or comments specifically, calculate the distance accordingly. By default, calculate distance with the title.
5. Use `Embeddings(keyword)` to get embeddings for keywords and use them in the `DISTANCE` function only when the query involves a keyword relevance search.
6. Ensure to consider the comments column if explicitly mentioned in the question.
7. Don't use dist in a query where you haven't found any distance and make sure to use order by dist with other columns as well where the distance is calculated
Example questions and how to handle them:
1. "What are the most voted articles during the last 7 hours in the AI field?"
- Extract keywords: "most voted articles," "last 7 hours," "AI field."
- Map "most voted" to "Score DESC."
- Construct query for the most voted articles in the last 7 hours:
- `SELECT DISTINCT "Title", "URL", "Score", DISTANCE("Title_Embedding", Embeddings('AI field')) FROM posts1 WHERE Time >= today() - INTERVAL 7 HOUR ORDER BY Score DESC LIMIT {top_k}`
2. "Give me some comments where people are criticizing the content?"
- Extract keywords: "comments," "criticizing."
- Map "criticizing" to DISTANCE function.
- Construct query for relevant comments:
- `SELECT DISTINCT "Comments", "Score", DISTANCE("Comments_Embedding", Embeddings('criticizing')) as dist FROM posts1 ORDER BY dist LIMIT {top_k}`
3. "What were the top voted stories during the last 6 hours?"
- Extract keywords: "top voted stories," "last 6 hours."
- Map "top voted" to "Score DESC."
- Construct a simple query for the top voted stories in the last 6 hours:
- `SELECT DISTINCT "Title", "URL", "Score" FROM posts1 WHERE Time >= today() - INTERVAL 6 HOUR ORDER BY Score DESC LIMIT {top_k}`
4. "What are the trending stories in the AI field?"
- Extract keywords: "trending stories," "AI field."
- Map "trending" to "Score DESC."
- Construct query for trending stories in the AI field:
- `SELECT DISTINCT "Title", "URL", "Score", DISTANCE("Title_Embedding", Embeddings('AI field')) as dist FROM posts1 ORDER BY dist,Score DESC LIMIT {top_k}`
5. "Give me some comments that are discussing about latest trends of LLMs?"
- Extract keywords: "comments," "latest trends of LLMs."
- Map "latest trends of LLMs" to DISTANCE function.
- Construct query for comments discussing latest trends of LLMs:
- `SELECT DISTINCT "Comments", "Score", DISTANCE("Comments_Embedding", Embeddings('latest trends of LLMs')) as dist FROM posts1 ORDER BY dist LIMIT {top_k}`
Now, let's create the query based on the provided input.
======== table info ========
{table_info}
Question: {input}
SQLQuery: "
Remove \n,\, " or any kind of redundant letter from the query and Be careful to not query for columns that do not exist.
"""
def generate_final_prompt(input, table_info, top_k=5):
final_prompt = prompt_template.format(input=input, table_info=table_info, top_k=top_k)
return final_prompt
This code sets up a prompt template that guides the LLM to generate correct MyScaleDB queries based on the input questions.
# Setting Query Parameters
We set up the parameters for the query generation.
top_k = 5
table_info = """
posts1 (
id UInt64,
Title String,
URL String,
Score UInt64,
Time DateTime64,
Writer String,
Comments UInt64,
Title_Embedding Array(Float32),
Comments_Embedding Array(Float32)
)
"""
This code sets the number of top results to retrieve (top_k), defines the table information (table_info) and sets an empty input string (input) for the question.
# Setting Up the model
In this step, we will set up the OpenAI model for converting user inputs into SQL queries.
from langchain.chat_models import ChatOpenAI
model = ChatOpenAI(openai_api_key="open-ai-api-key")
# Convert Text to SQL
This method first generates a final prompt based on user input and table information, then uses the OpenAI model to convert the text to SQL vector query.
def get_query(user_input):
final_prompt = generate_final_prompt(user_input, table_info, top_k)
response_text = model.predict(final_prompt)
return response_text
user_input="What are the most voted stories?"
response=get_query(user_input)
After this step, we will get a query like this:
'SELECT DISTINCT "Title", "URL", "Score", DISTANCE("Title_Embedding", Embeddings(\'AI domain\')) as dist FROM posts1 ORDER BY dist, Score DESC LIMIT 5'
But MyScaleDB DISTANCE expects DISTANCE(column, array) . So, we need to convert the Embeddings(\'AI domain\') part to vector embeddings.
# Processing and Replacing Embeddings in a Query String
This method will be used to replace Embeddings(“Extracted keywords”) with an array of float32.
import re
def process_query(query):
pattern = re.compile(r'Embeddings\(([^)]+)\)')
matches = pattern.findall(query)
for match in matches:
processed_embedding = str(list(generate_embeddings(match)))
query = query.replace(f'Embeddings({match})', processed_embedding)
return query
query=process_query1(f"""{response}""")
This method takes the query as input and returns the updated query if there is any Embeddings method present in the query string.

# Executing a Query
Finally, we execute a query to retrieve the relevant stories from the vector database.
query=query.replace("\n","")
results = client.query(f"""{query}""")
for row in results.named_results():
print("Title ", row["Title"])
Furthermore, you can take the query returned by the model, extract the specified columns and use them to fetch columns as shown above. These results can then be passed back to a chat model, creating a complete AI chat assistant. This way, the assistant can dynamically respond to user queries with relevant data extracted directly from the results, ensuring a seamless and interactive experience.
# Conclusion
Simple RAG has limited usage due to its focus on straightforward similarity searches. However, when combined with advanced tools like MyScaleDB, LangChain, etc., the RAG applications can not only meet but exceed the demands of large-scale big data management. They can handle a broader range of queries, including time-based and complex relational queries, significantly improving the performance and efficiency of your current systems.
If you have any suggestions, please reach out to us through Twitter (opens new window) or Discord (opens new window).
This article is originally published on The New Stack. (opens new window)



