
La Generación Aumentada de Recuperación (RAG, por sus siglas en inglés) mejora el rendimiento de los Modelos de Lenguaje de Aprendizaje a Gran Escala (LLM, por sus siglas en inglés) al conectarlos con bases de conocimientos externas. Tiene muchas ventajas, como un menor costo/recursos, la optimización de LLM en conocimientos específicos de dominio, la seguridad de los datos, etc. RAG es una tecnología relativamente nueva [1] en el contexto del aprendizaje profundo, pero su uso es inmenso y aumenta cada día.
A medida que aumenta el uso de RAG, también se está mejorando continuamente. A medida que se descubren limitaciones en los sistemas RAG, los investigadores han estado identificando formas de mejorar su rendimiento. Hoy hablaremos sobre la mejora de las consultas.
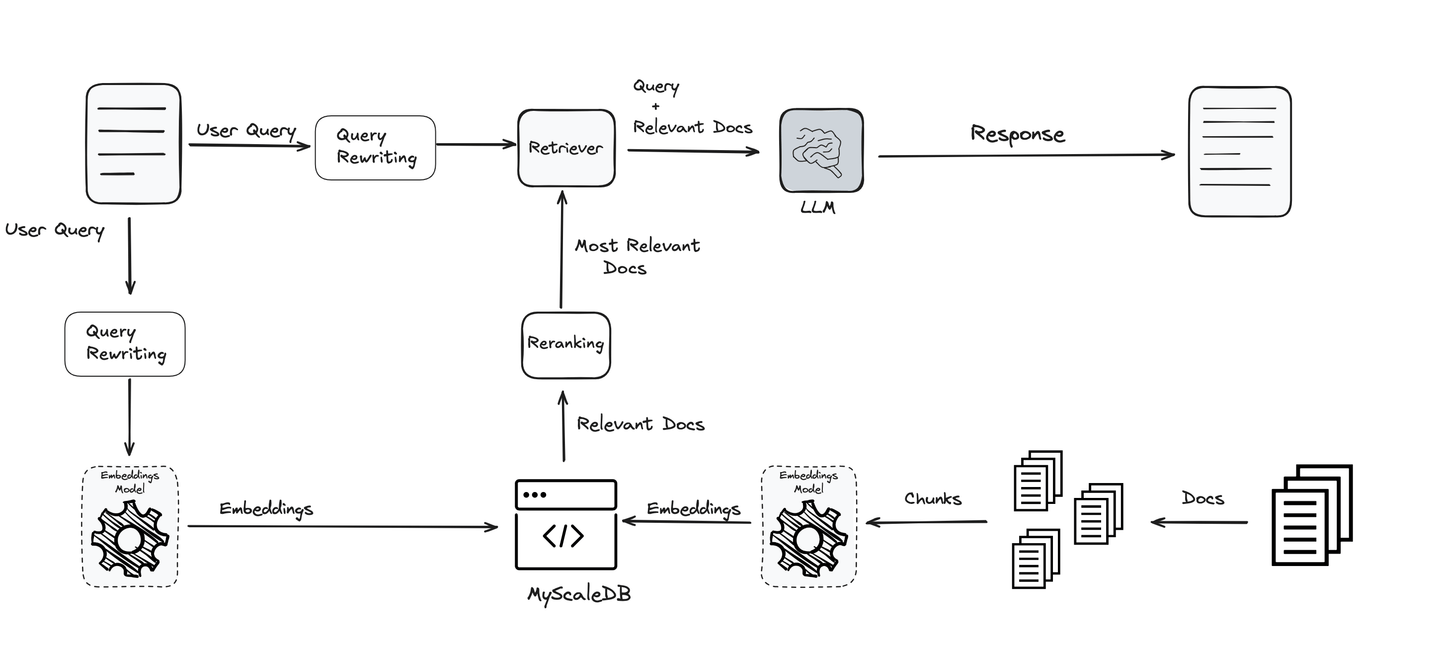
Agregar paso de reescritura de consultas
La consulta es una de las partes más importantes de todo el proceso de RAG. Lo que pregunte establece la dirección, y el LLM junto con todas las demás herramientas trabaja para brindarle información basada en eso. Si la consulta no es clara o está bien optimizada, incluso los mejores sistemas pueden quedarse cortos. Por eso, mejorar y refinar las consultas es clave para obtener resultados precisos y significativos.
Teniendo en cuenta esta importancia, se utilizan diversas técnicas para optimizar y aclarar las consultas para garantizar que el usuario final reciba los mejores y más relevantes resultados. Estas técnicas hacen que el sistema sea más efectivo y confiable, y respaldan todas las etapas del proceso de RAG.
# Reformulación de consultas
Una consulta escrita por un usuario (generalmente ingenuo) difícilmente puede ser juzgada desde la perspectiva de un LLM y, como ha demostrado la experiencia, estas consultas tienen mucho margen de mejora. Los LLM o cualquier sistema de recuperación también pueden ser sensibles a palabras específicas, por lo que reformular las consultas puede optimizarlas para una mejor comprensión.
Ejemplo:
Para ilustrar esto aún más, citamos un ejemplo de [2]. La consulta original que proporcionaron fue:
Una fábrica de fabricación de automóviles está considerando un nuevo sitio para su próxima planta. ¿Con qué se preocuparían más los planificadores comunitarios antes de permitir que se construya la planta?
Esta consulta era demasiado compleja para ser comprendida con precisión por el LLM y no pudo responderla. Después de emplear el reescritor, la consulta reformulada es:
¿Con qué se preocuparían más los planificadores comunitarios antes de permitir que se construya una fábrica de fabricación de automóviles?
Funciona perfectamente y también devuelve la respuesta correcta.
Existen varias técnicas para reescribir una consulta. Algunas las reemplazan con sinónimos, algunas añaden metadatos (opens new window), algunas se centran en mejorar la gramática y otras expanden la consulta en una forma más significativa (incluso algunos métodos generan permutaciones de la consulta original (opens new window)), etc. Curiosamente, algunos de estos métodos involucran a LLMs (opens new window) en sí mismos. Por lo tanto, es un uso un tanto recursivo de LLMs donde los utilizamos para mejorar la entrada a otro (o al mismo) LLM.
# Normalización de consultas
La normalización de consultas se refiere a métodos simples para corregir la gramática y la ortografía de la consulta original, etc. Del mismo modo, se puede emplear algún preprocesamiento como convertir todo en minúsculas o eliminar palabras vacías para la normalización de consultas.
Por ejemplo, "¿Quién fue el autor de Los hermanos Karamazov?" es mucho más fácil de comprender que "quien escribió broter karamov" ya que se pueden notar los errores de ortografía en la última consulta.
Aquí, debe tenerse en cuenta que los LLMs son modelos transformadores potentes que suelen ser capaces de comprender oraciones sin mucha normalización. Por lo tanto, es necesario encontrar un equilibrio entre la normalización de las entradas y exagerarla.
# Expansión de consultas
Dado que no estamos seguros de si una consulta funcionará bien o no en la mayoría de los casos, un método común es crear múltiples permutaciones de una consulta y devolver resultados para todas ellas. Si bien tenemos varios métodos clásicos de parafraseo, los propios LLMs son muy buenos en ellos, como ya habrás notado.
Aquí tienes un ejemplo (tomado originalmente de LangChain (opens new window)) utilizando LangChain y el modelo GPT-4 de OpenAI.
from langchain_core.pydantic_v1 import BaseModel, Field
from langchain.output_parsers import PydanticToolsParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
class ParaphrasedQuery(BaseModel):
"""Has realizado una expansión de consulta para generar una reformulación de una pregunta."""
paraphrased_query: str = Field(
...,
description="Una reformulación única de la pregunta original.",
)
system = """Eres un experto en convertir preguntas de los usuarios en consultas de bases de datos. \
Tienes acceso a una base de datos de videos tutoriales sobre una biblioteca de software para construir aplicaciones con LLM. \
Realiza una expansión de consulta. Si hay varias formas comunes de formular una pregunta de usuario \
o sinónimos comunes para palabras clave en la pregunta, asegúrate de devolver múltiples versiones \
de la consulta con las diferentes formulaciones.
Si hay acrónimos o palabras con las que no estás familiarizado, no intentes reformularlas.
Devuelve al menos 3 versiones de la pregunta."""
prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "{question}"),
]
)
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0.25)
llm_with_tools = llm.bind_tools([ParaphrasedQuery])
query_analyzer = prompt | llm_with_tools | PydanticToolsParser(tools=[ParaphrasedQuery])
Habiendo construido el expansor de consultas, ahora podemos usarlo. Por ejemplo:

Resultados de la expansión de consultas
Como puedes ver, proporciona permutaciones útiles (podemos aumentar el número de permutaciones aún más si queremos) que pueden ser útiles al alimentar al LLM.
# Adaptación contextual
El proceso de adaptación contextual implica ajustar una consulta para que se adapte mejor al contexto específico en el que se realiza. Esto se logra a menudo mediante el uso del aprendizaje por refuerzo (RL, por sus siglas en inglés), que ayuda a optimizar la formulación de la consulta en función de la información contextual. Un método emplea un modelo de lenguaje pequeño (LM, por sus siglas en inglés) como reformulador de consultas, utilizando fuentes externas, como datos de Internet, para enriquecer el contexto de la consulta. El componente de RL luego ajusta esta adaptación mediante el aprendizaje a partir de la retroalimentación sobre qué tan bien funciona la consulta reformulada en el contexto dado. Este enfoque se ha explorado en varios estudios de investigación, como los referenciados en [2] y [3], demostrando su efectividad para mejorar la relevancia y el rendimiento de las consultas.
# Descomposición de consultas
Las consultas a menudo contienen dos (o más) consultas diversas, lo que dificulta que los LLM las comprendan. Además, los LLM son bastante propensos a un contexto irrelevante [4]. Por ejemplo, en el ejemplo clásico de la edad de Jessica, la introducción de una declaración no relacionada (en rojo) probablemente confundirá al LLM.

Un ejemplo de comprensión ineficiente de la consulta (tomado de [4]) lleva a la necesidad de descomponer la consulta. La declaración subrayada en rojo complica innecesariamente la consulta y la hace aún más difícil de entender para el LLM.
Una mejor solución aquí sería descomponer la consulta en algo como:
"Jessica es seis años mayor que Claire. En dos años, Claire tendrá 20 años." "Hace veinte años, la edad del padre de Claire es tres veces la edad de Jessica" "¿Cuántos años tiene Jessica ahora?"
Y probablemente incluso podamos eliminar la segunda declaración también.
# Desafíos en la descomposición de consultas
La descomposición de consultas tiene algunas ventajas, como una mayor claridad y ayudar a los LLM a razonar de manera paso a paso. Sin embargo, también existen algunos desafíos asociados con la descomposición de consultas, como:
- Sobredivisión: Descomponer demasiado las consultas puede diluir el contexto, lo que lleva a resultados menos relevantes.
- Combinación de resultados: Agregar resultados de subconsultas puede ser desafiante, especialmente si son contradictorios o incompletos.
- Dependencia de la consulta: Algunas consultas dependen de resultados de pasos anteriores, lo que requiere procesos iterativos.
- Costo y latencia: Dividir las consultas en varias partes aumenta el número de pasos de recuperación y cálculo, lo que puede ser computacionalmente costoso.
Aunque la descomposición de consultas es prometedora, como vimos en los desafíos que se enfrentan, aún tiene mucho margen de mejora. Si tienes dudas sobre si usarla o no, es mejor errar por el lado más seguro, especialmente para ahorrar costos.
# Optimización de incrustaciones
Las incrustaciones generalmente se generan utilizando modelos comunes de procesamiento del lenguaje natural (NLP, por sus siglas en inglés) como BERT (opens new window) o Titan (opens new window), etc. Estas incrustaciones son bastante buenas para muchas aplicaciones, pero a menudo necesitan ser optimizadas para una mejor comprensión. Por estas razones, también se han propuesto algunos puntos de referencia como Massive Text Embedding Benchmark, MTEB [5] para verificar qué tan bien funcionan las incrustaciones en 8 tareas diversas como clasificación, agrupación y resumen.
"Encontramos que no hay una mejor solución única, con diferentes modelos dominando diferentes tareas." - Documento MTEB
Como también descubre MTEB correctamente, no hay una mejor solución única para todas las tareas: algunos modelos son buenos para el resumen, otros para la clasificación, etc. Y tampoco es universal en todos los conjuntos de datos, ya que los modelos funcionan mejor en algunos conjuntos de datos para la misma tarea, mientras que muestran resultados mediocres en otros.
# Incrustación hipotética de documentos (HyDE)
En 2022, los investigadores propusieron un método novedoso de cero disparos. [6] Este método único se basa en el concepto de crear un documento falso y luego utilizar sus incrustaciones para encontrar documentos similares (reales) en el espacio de incrustación. HyDE está ganando popularidad como una herramienta para la optimización de consultas en RAG. La metodología de HyDE se puede resumir de la siguiente manera:
- Generar un documento hipotético
- Calcular su incrustación
- Utilizar la incrustación para consultar la base de datos de vectores
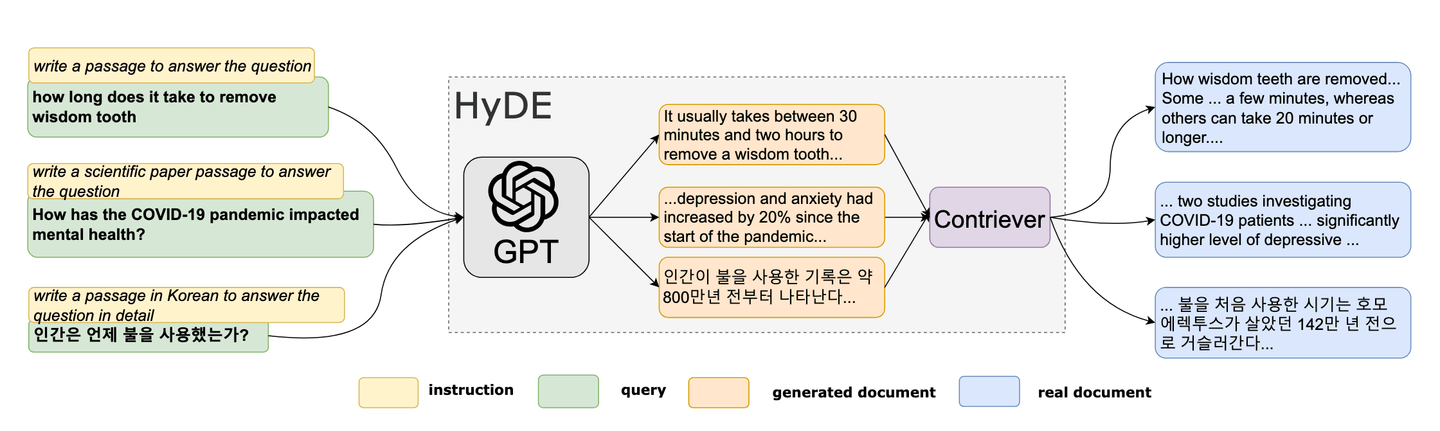
Referencia: Documento HyDE [6]
# Creación de documentos hipotéticos
Como primer paso, tomamos una consulta y la utilizamos para generar un documento hipotético. Se podría generar simplemente solicitando al LLM que "Cree un documento que responda a esta pregunta", como veremos en breve en el ejemplo.
# Cálculo de incrustaciones
Podemos utilizar cualquier modelo o servicio: MyScale también proporciona su propio método EmbedText() para calcular estas incrustaciones. Una vez que tengamos estas incrustaciones (consulta hipotética), podemos utilizarlas para consultar la base de datos de vectores.
Una vez que obtengamos el texto más similar a la consulta hipotética, lo pasamos junto con la consulta (original) al LLM para generar la respuesta.
# Ejemplo de HyDE
Por ejemplo, algunas incrustaciones se almacenan en la tabla DocEmbeddings en MyScale. Podemos consultarlas utilizando, por ejemplo, la similitud del coseno, para obtener los 10 documentos más similares de la siguiente manera:
Paso 1: Generación de documento hipotético
Como primer paso, tomamos la consulta y la utilizamos para generar el documento hipotético utilizando el modelo GPT-4 (mini) de OpenAI (para la mayoría de las tareas, GPT4-mini es lo suficientemente bueno y ahorra dinero).
from openai import OpenAI
openai_client = OpenAI(api_key='sk-xxxxx')
def Make_HyDoc(query):
response = openai_client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "system", "content": "Crea un documento que responda a la pregunta:"},
{"role": "user", "content": f"{query}"}],
max_tokens=100
)
return response.choices[0].message
Ahora, tenemos esta función para que podamos usarla para generar documentos hipotéticos basados en nuestras consultas.
Paso 2: Cálculo de incrustaciones
Para calcular las incrustaciones, utilizaremos el método EmbedText() incorporado de MyScale para calcular directamente las incrustaciones.
service_provider = 'OpenAI'
hypoDoc = Make_HyDoc("¿Cuál fue la solución propuesta para el problema de los agricultores por Levin?")
parameters = {'sampleString': hypoDoc, 'serviceProvider': service_provider}
x = client.query("""
SELECT EmbedText({sampleString:String}, {serviceProvider:String}, '', 'sk-*****', '{"model":"text-embedding-3-small", "batch_size":"50"}')
""", parameters=parameters)
input_embedding = x.result_rows[0][0]
Paso 3: Uso de la incrustación para consultar la base de datos de vectores
Ahora, tenemos la incrustación en input_embedding, podemos compararla con los vectores ya almacenados en una tabla (DocEmbeddings en este caso) utilizando una simple consulta SQL.
SELECT
id,
title,
content,
cosineDistance(embedding, input_embedding) AS similarity
FROM
DocEmbeddings
ORDER BY
similarity ASC
LIMIT
10;
Podemos ejecutarlo en Python y mostrarlo como un dataframe.
import pandas as pd
query = f"""
SELECT
id,
sentences,
cosineDistance(embeddings, {input_embedding}) AS similarity
FROM
DocEmbeddings
LIMIT
10
"""
df = pd.DataFrame(client.query(query).result_rows)
Y devuelve los documentos más relevantes:

Resultados de HyDE

# Conclusión
RAG es una herramienta poderosa y rentable que mejora las capacidades de los LLM, pero también tiene sus limitaciones. En esta publicación del blog, nos centramos en mejorar las consultas como parte del proceso de RAG. Exploramos diversas técnicas como la reformulación (a menudo utilizando LLMs), la descomposición de consultas, la optimización de la calidad de las incrustaciones y HyDE. Si bien estos métodos son valiosos, representan solo un aspecto del proceso de generación de RAG. Hay formas adicionales de mejorar todo el proceso de generación de RAG. En la próxima publicación, profundizaremos en las estrategias de fragmentación y discutiremos cómo se puede fragmentar los datos en diferentes tipos según el caso de uso.
# Referencias
- Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., Küttler, H., Lewis, M., Yih, W., Rocktäschel, T., Riedel, S., & Kiela, D. (2020). Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. NeurIPS. https://arxiv.org/abs/2005.11401
- Ma, X., Gong, Y., He, P., Zhao, H., & Duan, N. (2023). Query Rewriting for Retrieval-Augmented Large Language Models. EMNLP. https://arxiv.org/abs/2305.14283
- Anand, A., V, V., Setty, V., & Anand, A. (2023). Context Aware Query Rewriting for Text Rankers using LLM. ArXiv. https://arxiv.org/abs/2308.16753
- Freda Shi, Xinyun Chen, Kanishka Misra, Nathan Scales, David Dohan, Ed H. Chi, Nathanael Schärli, and Denny Zhou. Large language models can be easily distracted by irrelevant context. ICML, 2023.
- Muennighoff, N., Tazi, N., Magne, L., & Reimers, N. (2022). MTEB: Massive Text Embedding Benchmark. ArXiv. https://arxiv.org/abs/2210.07316
- Gao, L., Ma, X., Lin, J., & Callan, J. (2022). Precise Zero-Shot Dense Retrieval without Relevance Labels. ArXiv. https://arxiv.org/abs/2212.10496



