
Modelos de Lenguaje Grande (LLMs) han revolucionado la forma en que accedemos y entendemos la información. Estos avanzados sistemas de IA están entrenados en vastas cantidades de datos, lo que les permite reconocer patrones y significados en el lenguaje. Al entender las palabras en contexto, facilitan la exploración de ideas, el aprendizaje de cosas nuevas y la búsqueda de respuestas de manera rápida y eficiente. LLM está moldeando una nueva era en cómo interactuamos y usamos la información en la vida cotidiana.
Los primeros LLM tradicionales dependían únicamente del conocimiento proporcionado por sus datos de entrenamiento estáticos. Esta limitación a menudo conduce a la alucinación, donde el modelo genera información incorrecta o fabricada debido a datos desactualizados o incompletos. Reconociendo estos problemas, se introdujo el concepto de Generación Aumentada por Recuperación (RAG).
# Generación Aumentada por Recuperación (RAG)
La idea detrás de Generación Aumentada por Recuperación (RAG) (opens new window) era proporcionar una base de datos confiable a los LLM para mejorar la calidad de sus respuestas. En lugar de depender únicamente de la información que aprendieron durante el entrenamiento, RAG permite a los LLM acceder a datos en tiempo real utilizando una base de datos vectorial (opens new window) como MyScale (opens new window) como base de conocimiento.
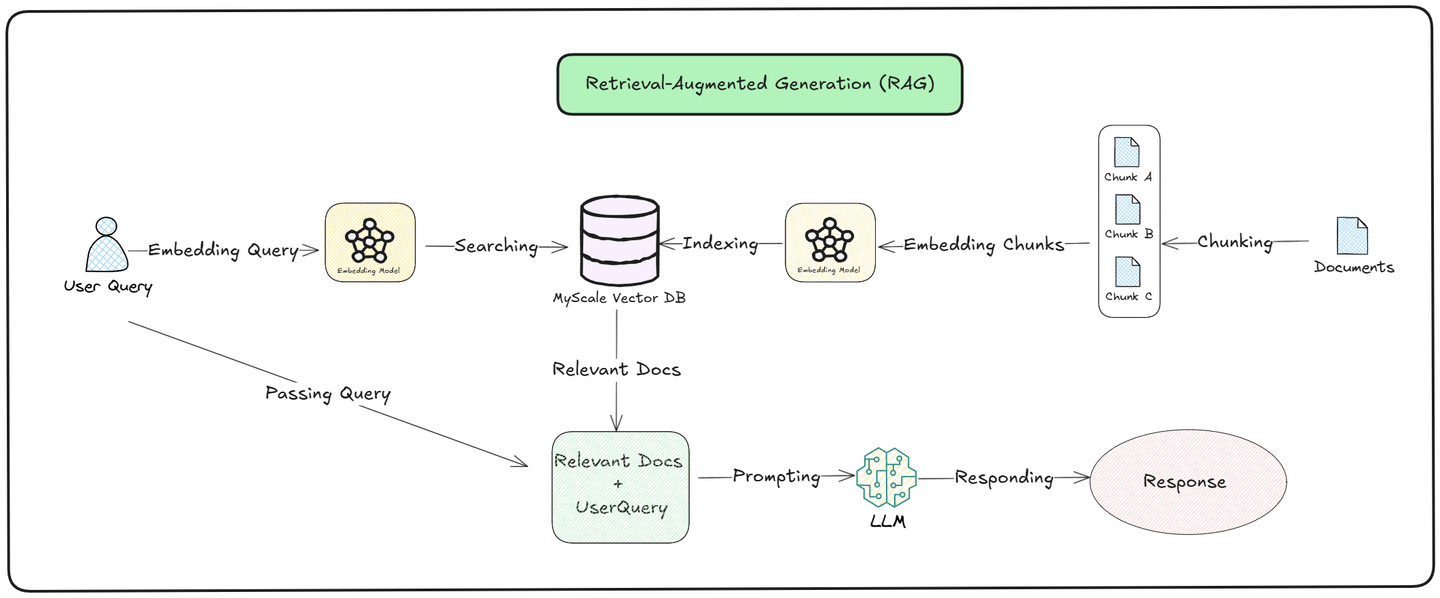
Como podemos ver en la ilustración anterior, el proceso de consulta se divide en dos partes, que son recuperación (opens new window) y generación: (opens new window)
Recuperación: El modelo busca en una Base de Conocimiento externa documentos relevantes. Convierte la consulta del usuario en un vector y lo compara con los datos almacenados. Se recuperan y clasifican los documentos más similares según su relevancia para la consulta, asegurando que el modelo obtenga información precisa y actualizada.
Generación: Después de recuperar los documentos relevantes, el modelo utiliza tanto la información recuperada como su conocimiento preentrenado para crear una respuesta. Combina los nuevos datos encontrados con lo que ya sabe para generar una respuesta que sea contextualmente precisa y relevante para la pregunta del usuario.
Sin duda, RAG mejora la precisión y calidad de las respuestas. Sin embargo, su pipeline opera de manera estática. Cada vez que un usuario realiza una consulta, se sigue el mismo proceso: se recupera información relevante de la base de datos vectorial y se proporciona al LLM para generar una respuesta. Esta consistencia asegura fiabilidad, pero limita la capacidad del sistema para adaptarse dinámicamente a contextos o escenarios específicos.
Para superar los límites del pipeline estático de RAG, se han introducido nuevos métodos como ReACT (Razonamiento y Acción) (opens new window) y agentes (opens new window). Estas herramientas ayudan a los sistemas a responder mejor a las consultas de los usuarios al agregar:
- Razonamiento
- Toma de decisiones
- Ejecución de tareas.
Son los bloques de construcción para sistemas avanzados como Agentic RAG, que combinan el pensamiento lógico con acciones simples para hacer las cosas más precisas y flexibles.
# ¿Qué es ReACT?
ReACT, que significa "Razonamiento y Acción", es un avance en la forma en que funcionan los LLM. A diferencia de los modelos tradicionales que dan respuestas rápidas, ReACT ayuda a la IA a pensar en los problemas paso a paso. Este enfoque, llamado cadena de pensamiento (CoT), permite a los modelos resolver tareas complejas de manera más efectiva.
En un artículo de investigación de 2022, Yao y su equipo mostraron cómo combinar razonamiento con acción puede hacer que la IA sea más inteligente. Los modelos tradicionales a menudo luchan con problemas complicados, pero ReACT cambia eso. Ayuda a la IA a pausar, pensar críticamente y desarrollar mejores soluciones.
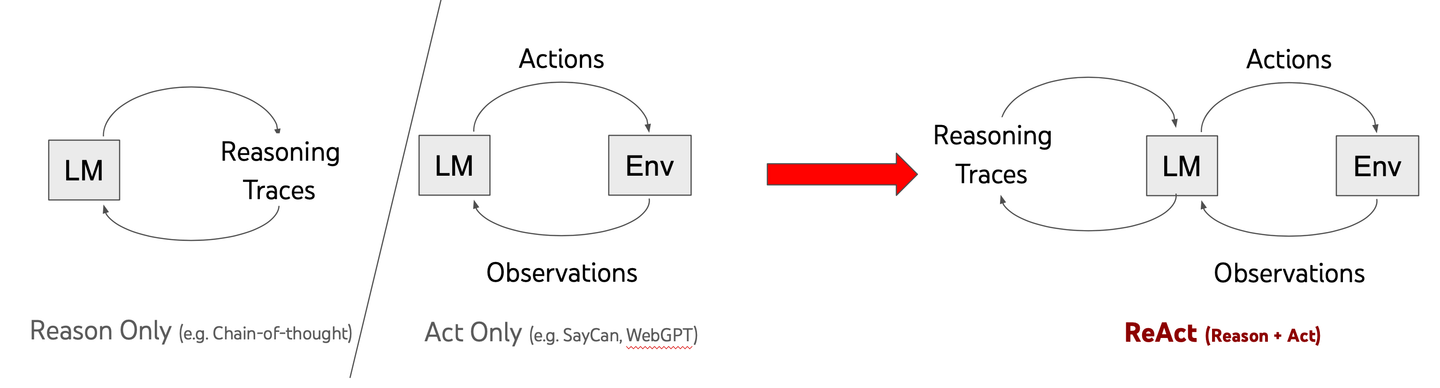
La diferencia clave está en el enfoque de resolución de problemas. En lugar de apresurarse a dar una respuesta, los modelos impulsados por ReACT descomponen los desafíos de manera metódica. Esto los hace más adaptables y fiables al abordar problemas del mundo real.
Al enseñar a la IA a razonar antes de actuar, ReACT está ampliando los límites de lo que la inteligencia artificial puede hacer. No se trata solo de tener información—se trata de usar esa información de manera inteligente.
# Cómo Funciona ReACT
ReACT mejora las capacidades de los LLM al integrar un proceso de razonamiento sistemático con pasos accionables. El marco opera a través de las siguientes etapas:

Análisis de Consulta: El modelo comienza descomponiendo la consulta del usuario en componentes manejables.
Razonamiento en Cadena de Pensamiento: El LLM razona paso a paso, analizando cada componente y determinando las acciones requeridas. Por ejemplo, puede recuperar información, verificar datos o combinar múltiples fuentes lógicamente.
Ejecución de Acción: Basado en su razonamiento, el modelo toma acciones como interactuar con herramientas externas, recuperar datos específicos o reevaluar la consulta a medida que se dispone de nueva información.
Mejora Iterativa: ReACT puede refinar su razonamiento a medida que avanza a través de los pasos, ajustándose dinámicamente según los resultados intermedios.
Este razonamiento paso a paso es similar a cómo los humanos resuelven problemas complejos, asegurando que la respuesta final esté bien pensada y sea contextualmente relevante. Por ejemplo, si una consulta pregunta: "¿Cuáles son las principales diferencias entre ReACT y los agentes?", el modelo primero identifica los componentes (por ejemplo, definir ReACT, definir agentes) y luego razona a través de ellos secuencialmente antes de sintetizar una respuesta completa.
# Introduciendo Agentes
Mientras que ReACT se centra en el razonamiento dentro del LLM, los agentes asumen el papel de ejecutar tareas específicas fuera del modelo. Los agentes son entidades autónomas que actúan según las instrucciones proporcionadas por el LLM, lo que permite al sistema interactuar con herramientas externas, APIs, bases de datos o incluso realizar flujos de trabajo complejos de múltiples pasos.
# Cómo Funcionan los Agentes
- Identificación de Tareas: El LLM, a menudo guiado por el razonamiento de ReACT, determina qué agente se necesita para una tarea dada. Por ejemplo, una consulta sobre las condiciones climáticas recientes podría activar un agente de recuperación de datos para obtener actualizaciones meteorológicas en tiempo real.
- Ejecución: El agente seleccionado lleva a cabo la tarea. Esto podría implicar consultar una base de datos, raspar contenido web, llamar a una API o realizar cálculos.
- Bucle de Retroalimentación: Una vez que se completa la tarea, el agente devuelve el resultado al LLM para un razonamiento adicional o generación de respuesta.
- Cadena de Múltiples Agentes: En escenarios más complejos, se pueden orquestar múltiples agentes en una secuencia. Por ejemplo, un agente recupera datos en bruto, otro agente los procesa y un tercer agente visualiza o formatea la salida final.
# Agentes y Modularidad
Los agentes son modulares por diseño, lo que significa que pueden personalizarse para diferentes aplicaciones. Ejemplos incluyen:
- Agentes de Recuperación: Recuperan datos de bases de datos vectoriales o gráficos de conocimiento.
- Agentes de Resumen: Condensan la información recuperada en puntos clave.
- Agentes de Cálculo: Manejan tareas que requieren cálculos o transformaciones de datos.
- Agentes de Interacción con API: Se integran con servicios externos para obtener actualizaciones en tiempo real.
Este enfoque modular permite flexibilidad y escalabilidad, ya que se pueden agregar nuevos agentes para satisfacer requisitos específicos.
# ¿Qué es Agentic RAG?
Agentic RAG combina las capacidades de razonamiento de ReACT con el poder de ejecución de tareas de los agentes, creando un sistema dinámico y adaptativo. A diferencia del RAG tradicional, que sigue un pipeline fijo, Agentic RAG introduce flexibilidad al usar ReACT para orquestar agentes dinámicamente según el contexto de la consulta del usuario. Esto permite al sistema no solo recuperar y generar información, sino también tomar acciones informadas basadas en el contexto, los objetivos en evolución y los datos con los que interactúa.
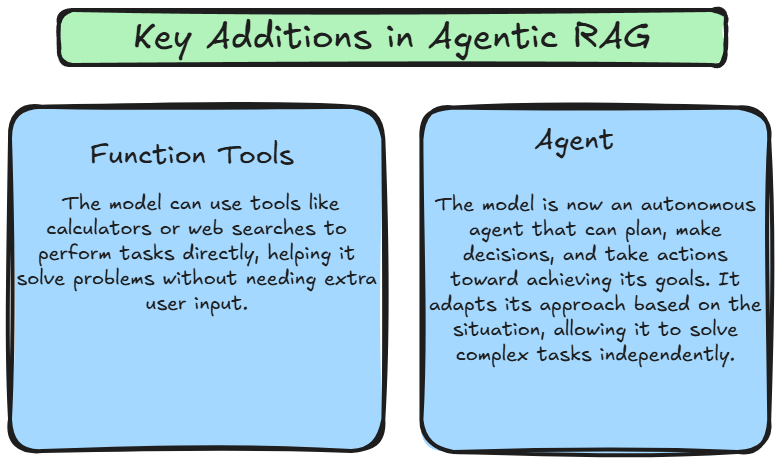
Estos avances hacen que Agentic RAG sea un marco mucho más poderoso y flexible. El modelo ya no está limitado a reaccionar pasivamente a las consultas de los usuarios; en su lugar, puede planificar, ejecutar y adaptar su enfoque para resolver problemas de manera independiente. Esto permite al sistema manejar tareas más intrincadas, ajustarse dinámicamente a nuevos desafíos y ofrecer respuestas más contextualmente precisas.
# Cómo Funciona Agentic RAG
La innovación clave en Agentic RAG radica en su capacidad para usar herramientas de manera autónoma, tomar decisiones y planificar sus próximos pasos. El pipeline sigue estas etapas fundamentales:
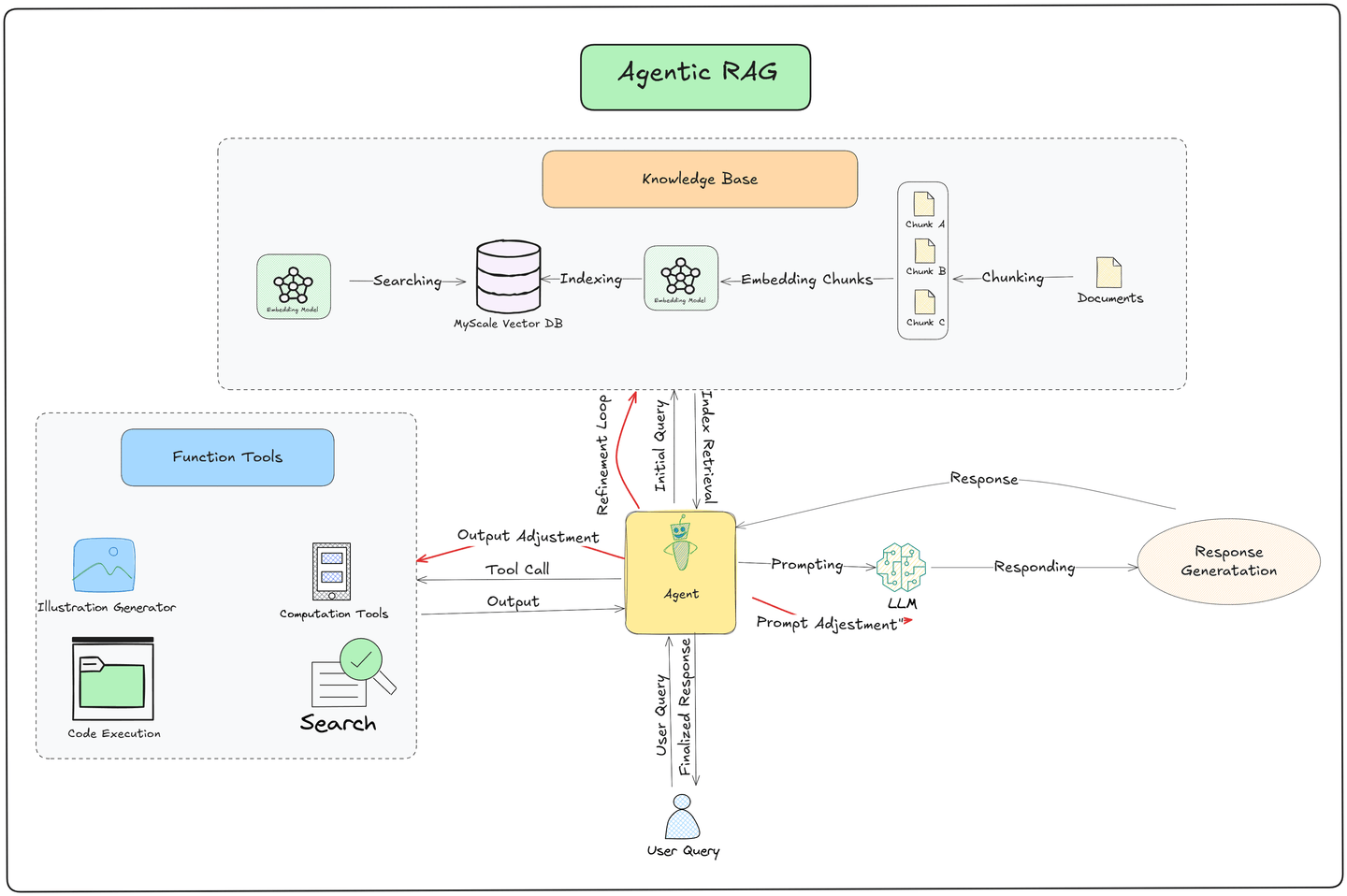
- Envío de Consulta del Usuario:
- El proceso comienza con el usuario enviando una consulta al sistema. Esta consulta actúa como un desencadenante para el pipeline.
- Recuperación de Datos de una Base de Datos Vectorial:
- Un Agente busca en una Base de Datos Vectorial, donde los documentos se almacenan como embeddings, asegurando una recuperación eficiente y rápida de información relevante.
- Si los datos recuperados son insuficientes, el agente refina la consulta y realiza intentos de recuperación adicionales para extraer mejores resultados.
- Obtención de Datos Externos con Herramientas Funcionales:
- Si la Base de Datos Vectorial carece de la información necesaria, el agente utiliza Herramientas Funcionales para recopilar datos en tiempo real de fuentes externas como APIs, motores de búsqueda web o flujos de datos propietarios. Esto asegura que el sistema proporcione información actualizada y contextualmente relevante.
- Generación de Respuesta del Modelo de Lenguaje Grande (LLM):
- Los datos recuperados se pasan al LLM, que los sintetiza para generar una respuesta detallada y consciente del contexto adaptada a la consulta.
- Refinamiento Impulsado por el Agente:
- Después de que el LLM produce una respuesta, el agente la refina aún más para precisión, relevancia y coherencia antes de entregarla al usuario.
# Comparación: Agentic RAG vs RAG
Aquí está la tabla de comparación.
| Característica | RAG (Generación Aumentada por Recuperación) | Agentic RAG |
|---|---|---|
| Manejo de Tareas | Recupera información relevante de fuentes externas (por ejemplo, bases de datos, documentos) antes de generar respuestas. | Extiende RAG al agregar capacidades de razonamiento y acción, permitiendo interacción activa con el entorno y aprendizaje por retroalimentación. |
| Interacción con el Entorno | Recupera datos de fuentes externas. | Interactúa activamente con entornos externos (APIs, fuentes de datos) y se adapta según la retroalimentación. |
| Razonamiento | No hay razonamiento explícito; se basa en la recuperación para proporcionar contexto. | El razonamiento explícito guía la toma de decisiones y la finalización de tareas. |
| Bucle de Retroalimentación | No incorpora bucles de retroalimentación para el aprendizaje. | Incorpora retroalimentación del entorno para refinar el razonamiento y las acciones. |
| Autonomía | Pasiva; el sistema solo responde después de recuperar datos. | Autonomía activa en razonamiento y acción, tomando decisiones y aprendiendo dinámicamente. |
| Caso de Uso | Ideal para tareas que requieren recuperación contextual (por ejemplo, respuesta a preguntas). | Adecuado para tareas que requieren tanto razonamiento como interacción con sistemas externos (por ejemplo, toma de decisiones, planificación). |
# Conclusión
En conclusión, Agentic RAG representa un avance significativo en el campo de la IA. Al combinar el poder de los modelos de lenguaje grandes con la capacidad de razonar y recuperar información de manera autónoma, los Agentic RAG ofrecen un nuevo nivel de inteligencia y adaptabilidad. A medida que la IA continúa evolucionando, los Agentic RAG desempeñarán un papel cada vez más importante en diversas industrias, transformando la forma en que trabajamos e interactuamos con la tecnología.
Para realizar plenamente el potencial de la IA Agentic, es esencial contar con una base de datos vectorial robusta y eficiente como la Base de Datos Vectorial MyScale (opens new window), que está diseñada principalmente para satisfacer las exigentes necesidades de aplicaciones de IA a gran escala. Con sus técnicas avanzadas de indexación y capacidades optimizadas de procesamiento de consultas, MyScale permite a los sistemas Agentic RAG recuperar información relevante y generar respuestas de alta calidad rápidamente. Aprovechar el poder de MyScale puede desbloquear el potencial completo de la IA Agentic y fomentar la innovación.



