
Retrieval augmented generation (RAG) (opens new window) fue un gran avance en la IA que transformó la forma en que los chatbots (opens new window) interactúan con los usuarios. Al combinar métodos basados en recuperación con IA generativa, RAG permitió a los chatbots extraer datos en tiempo real de fuentes externas y generar respuestas precisas y relevantes. Esta innovación simplificó el desarrollo de chatbots y los hizo más eficientes al asegurar que puedan adaptarse a datos cambiantes, lo cual es crucial en áreas como el soporte al cliente (opens new window), donde la información oportuna y precisa es clave.
Sin embargo, los sistemas RAG tradicionales tenían dificultades para tomar decisiones rápidas en escenarios de ritmo rápido, como la programación de citas o el manejo de solicitudes en tiempo real. Aquí es donde entra en juego el RAG agente, que aborda esto al añadir agentes inteligentes (opens new window) que pueden recuperar, verificar y actuar sobre los datos de manera autónoma. A diferencia del RAG estándar, que principalmente recupera datos y genera respuestas, el RAG agente permite que la IA tome decisiones proactivas sobre la marcha, lo que lo hace perfecto para situaciones complejas como diagnósticos médicos o atención al cliente, donde la toma de decisiones rápida y precisa es esencial.
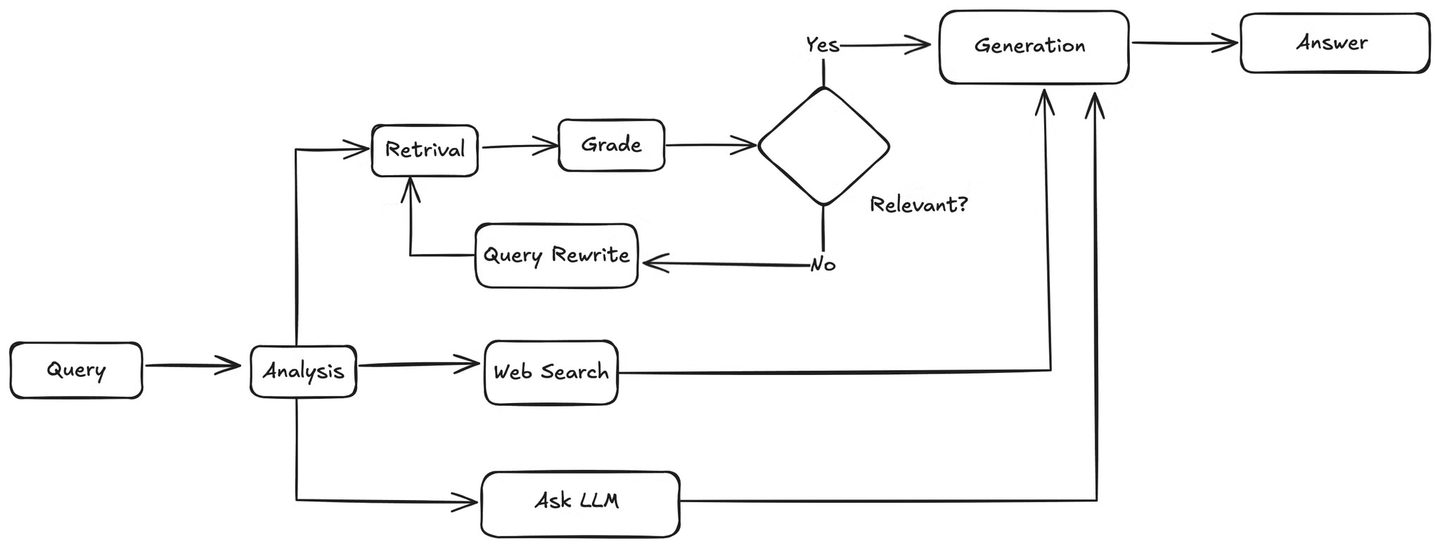
Esto es exactamente lo que implementaremos en este tutorial, un sistema inteligente de preguntas y respuestas (Q&A) agente que decide dinámicamente si utilizar una base de conocimiento (opens new window) o realizar una búsqueda en Internet en función de la consulta del usuario. Para lograr esto, debemos integrar varias herramientas:
- LangChain (opens new window): Esto gestionará cómo el sistema interactúa con el modelo de lenguaje y las demás herramientas. Según la consulta, ayudará al sistema a decidir si buscar en la base de conocimiento o en Internet.
- MyScaleDB (opens new window): MyScaleDB servirá como nuestra base de datos vectorial, almacenando incrustaciones (opens new window) que representan la base de conocimiento. Se utilizará para buscar eficientemente a través de los datos almacenados cuando la consulta esté relacionada con la base de conocimiento.
- VoyageAI (opens new window): Proporciona diferentes modelos de incrustaciones para generar incrustaciones a partir de texto, que se utilizan para codificar el conocimiento para una mejor búsqueda y coincidencia.
- Tavily (opens new window): Esto obtendrá información en tiempo real de Internet cuando la pregunta del usuario requiera datos actualizados o externos, asegurando que el sistema siempre proporcione respuestas precisas.
# Configuración del entorno
Primero, debe instalar las bibliotecas necesarias y obtener los paquetes que necesitamos para desarrollar esta aplicación de IA ejecutando el siguiente comando:
pip install -U langchain-google-genai langchain-voyageai langchain-core langchain-community
El siguiente paso es configurar las claves de API necesarias para usar Gemini (opens new window) (Google Generative AI) y Tavily search. (opens new window) Para MyScale, puede seguir esta guía de inicio rápido quickstart (opens new window).
import os
# Credenciales de API de MyScale
os.environ["MYSCALE_HOST"] = "msc-24862074.us-east-1.aws.myscale.com"
os.environ["MYSCALE_PORT"] = "443"
os.environ["MYSCALE_USERNAME"] = "su_nombre_de_usuario_de_myscale"
os.environ["MYSCALE_PASSWORD"] = "su_contraseña_de_myscale"
# Clave de API de Tavily
os.environ["TAVILY_API_KEY"] = "su_clave_de_api_de_tavily"
# Clave de API de Google para Gemini
os.environ["GOOGLE_API_KEY"] = "su_clave_de_api_de_google"
Reemplace los marcadores de posición en el código anterior con sus claves de API reales.
Nota: Todas estas herramientas ofrecen versiones gratuitas para probar las funcionalidades. Por lo tanto, siéntase libre de crear una cuenta en las respectivas plataformas y obtener la clave de API.
# Lectura y división del texto
El siguiente paso es preparar los datos para la base de conocimiento. Para este tutorial, utilizamos un conjunto de datos que contiene información primaria sobre MyScaleDB. Los datos se dividen en fragmentos manejables, lo que facilita el procesamiento y la recuperación eficiente de información relevante por parte del sistema.
from langchain_text_splitters import CharacterTextSplitter
with open("myscaledb_summary.txt") as f:
state_of_the_union = f.read()
text_splitter = CharacterTextSplitter(
separator="\\n\\n",
chunk_size=1000,
chunk_overlap=200,
length_function=len,
is_separator_regex=False,
)
texts = text_splitter.create_documents([state_of_the_union])
El CharacterTextSplitter divide el texto en fragmentos más pequeños y manejables según el recuento de caracteres.
Nota: Se utiliza un archivo txt sobre MyScale para este blog. Puede utilizar cualquier conjunto de datos de su elección.
# Agregar datos a la base de conocimiento
Después de dividir los datos, obtengamos las incrustaciones y guardemos esas incrustaciones en una base de conocimiento. Usamos VoyageAIEmbeddings para generar incrustaciones para los fragmentos de texto y almacenarlos en MyScaleDB.
from langchain_voyageai import VoyageAIEmbeddings
from langchain_community.vectorstores import MyScale
embeddings = VoyageAIEmbeddings(
voyage_api_key="su_clave_de_api_de_voyageai",
model="voyage-law-2"
)
vectorstore = MyScale.from_documents(
texts,
embeddings,
)
retriever = vectorstore.as_retriever()
El método .from_documents (opens new window) generalmente toma una lista de documentos y un modelo para transformar esos documentos en incrustaciones vectoriales. Este método guarda automáticamente esas incrustaciones en la base de conocimiento.
# Creación de herramientas para el modelo
En LangChain, las herramientas (opens new window) son funcionalidades que el agente puede utilizar para realizar tareas específicas más allá de la generación de texto. Al equipar el modelo con herramientas, se le permite interactuar con fuentes de datos externas, obtener información en tiempo real y proporcionar respuestas más precisas y relevantes a las consultas de los usuarios.
En esta aplicación, desarrollamos dos herramientas diferentes para que el agente decida qué herramienta utilizar en función de la consulta del usuario:
- Si la consulta está relacionada con MyScaleDB o MyScale, el agente utilizará la herramienta de recuperación para obtener información de nuestra base de conocimiento personalizada.
- Para otras consultas que requieran información actualizada, el agente utilizará la herramienta de búsqueda de Tavily para realizar búsquedas en Internet en tiempo real.
# Herramienta de recuperación para el contenido de MyScale
Utilicemos el recuperador de MyScaleDB creado anteriormente y utilicemos el método create_retriever_tool para convertir ese recuperador en una herramienta.
from langchain.tools.retriever import create_retriever_tool
retriever_tool = create_retriever_tool(
retriever,
"retrieve_myscale_content",
"Se utiliza para devolver información sobre MyScaleDB.",
)
# Herramienta de búsqueda de Tavily para datos en tiempo real de Internet
LangChain proporciona soporte incorporado para utilizar la herramienta de búsqueda de Tavily (opens new window) a través de su paquete de la comunidad.
from langchain_community.tools import TavilySearchResults
tool = TavilySearchResults(
max_results=5,
search_depth="advanced",
include_answer=True,
name="live_search",
description="Se utiliza para buscar las últimas noticias de Internet.",
)
tools = [retriever_tool, tool]
La herramienta TavilySearchResults está configurada para buscar las últimas noticias con un máximo de 5 resultados y una profundidad de búsqueda avanzada, incluyendo respuestas directas. Al final, ambas herramientas se agregan a una lista.
Nota: Las descripciones de cada herramienta son realmente importantes porque ayudan al agente a determinar qué herramienta utilizar y con qué propósito.
# Definir el flujo de trabajo de la aplicación
Ahora que se han definido las herramientas necesarias, el siguiente paso es establecer el flujo de trabajo completo de la aplicación RAG agente, incluidos los pasos involucrados y las verificaciones que realizará.
Primero, cuando llega una consulta de usuario, el agente la analizará para comprender la intención y el contexto. Luego, decidirá si utilizar la base de conocimiento o realizar una búsqueda en la web. Si se necesita una búsqueda en la web, utilizará la herramienta de búsqueda en la web para recopilar resultados y luego pasará los resultados al LLM, que generará una respuesta a la consulta del usuario en función de la información recuperada.
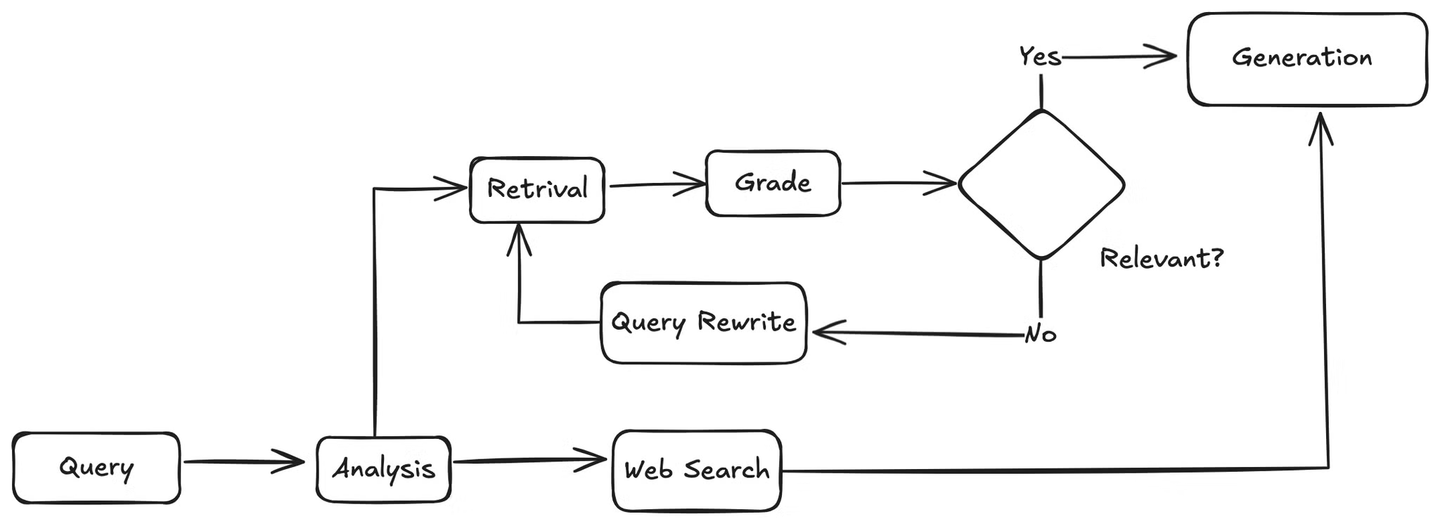
Si la consulta está relacionada con la base de conocimiento, el agente recuperará fragmentos relevantes de la base de conocimiento y los pasará a una función que coincida con estos documentos con la consulta del usuario para verificar su relevancia. Si los documentos son relevantes, el agente los enviará al LLM para generar respuestas. Si no son relevantes, invocará un método para reescribir la consulta del usuario. La consulta reescrita se envía nuevamente al recuperador y el proceso se repite hasta que se encuentre información relevante.
# Definir el agente y el estado
El primer paso es definir una clase AgentState que se utilizará para realizar un seguimiento del estado de la respuesta en todo el proceso.
# Importaciones de la biblioteca estándar
from typing import Literal, Annotated, Sequence, TypedDict
# Importaciones de Langchain Core
from langchain_core.messages import BaseMessage, HumanMessage
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_core.pydantic_v1 import BaseModel, Field
# Importaciones de Langchain y herramientas externas
from langchain import hub
from langchain_google_genai import ChatGoogleGenerativeAI
# Importaciones de LangGraph
from langgraph.graph.message import add_messages
class AgentState(TypedDict):
messages: Annotated[Sequence[BaseMessage], add_messages]
Ahora, definamos el agente que analizará la consulta del usuario y decidirá si utilizar la base de conocimiento o realizar una búsqueda en la web. El modelo Gemini se utiliza para seleccionar la herramienta adecuada y generar una respuesta en función de la consulta.
def agent(state):
messages = state["messages"]
model = ChatGoogleGenerativeAI(
model="gemini-1.5-pro",
temperature=0,
max_tokens=None,
timeout=None,
max_retries=2,
)
model = model.bind_tools(tools)
response = model.invoke(messages)
return {"messages": [response]}
# Calificación de los documentos recuperados
El agente se asegura de que los documentos recuperados sean relevantes para la consulta del usuario. La función grade_documents analizará los documentos recuperados para verificar su relevancia. Si los documentos recuperados son relevantes, el agente decidirá generar una respuesta; de lo contrario, reescribirá la consulta del usuario.
def grade_documents(state) -> Literal["generate", "rewrite"]:
# Modelo de datos para la calificación
class Grade(BaseModel):
"""Puntuación binaria para la verificación de relevancia."""
binary_score: str = Field(description="Puntuación de relevancia 'sí' o 'no'")
# LLM
model = ChatGoogleGenerativeAI(
model="gemini-1.5-pro",
temperature=0,
max_tokens=None,
timeout=None,
max_retries=2,
)
llm_with_tool = model.with_structured_output(Grade)
# Plantilla
prompt = PromptTemplate(
template="""Eres un evaluador que evalúa la relevancia de un documento recuperado para una pregunta de usuario.
Aquí está el documento recuperado:
{context}
Aquí está la pregunta del usuario: {question}
Si el documento contiene palabra(s) clave o significado semántico relacionado con la pregunta del usuario, califíquelo como relevante.
Asigne una puntuación binaria 'sí' o 'no' para indicar si el documento es relevante para la pregunta.""",
input_variables=["context", "question"],
)
# Cadena
chain = prompt | llm_with_tool
messages = state["messages"]
last_message = messages[-1]
question = messages[0].content
docs = last_message.content
scored_result = chain.invoke({"question": question, "context": docs})
score = scored_result.binary_score
if score == "yes":
return "generate"
else:
return "rewrite"
# Reescritura de las consultas de usuario
Si los documentos recuperados no son relevantes, el agente reescribirá la consulta del usuario para mejorar los resultados recuperados de la base de conocimiento.
def rewrite(state):
messages = state["messages"]
question = messages[0].content
msg = [
HumanMessage(
content=f"""
Analice la entrada y trate de razonar sobre la intención / significado semántico subyacente.
Aquí está la pregunta inicial:
-------
{question}
-------
Formule una pregunta mejorada:""",
)
]
# LLM
model = ChatGoogleGenerativeAI(
model="gemini-1.5-pro",
temperature=0,
max_tokens=None,
timeout=None,
max_retries=2,
)
response = model.invoke(msg)
return {"messages": [response]}
# Generación de la respuesta final
Una vez que se confirma que los documentos recuperados son relevantes, el agente enviará los documentos recuperados para generar la respuesta final.
def generate(state):
messages = state["messages"]
question = messages[0].content
last_message = messages[-1]
docs = last_message.content
# Plantilla
prompt = hub.pull("rlm/rag-prompt")
# LLM
llm = ChatGoogleGenerativeAI(
model="gemini-1.5-pro",
temperature=0,
max_tokens=None,
timeout=None,
max_retries=2,
)
# Cadena
rag_chain = prompt | llm | StrOutputParser()
# Ejecutar
response = rag_chain.invoke({"context": docs, "question": question})
return {"messages": [response]}
# Poner todo en LangGraph
Utilizamos LangGraph (opens new window) para agilizar el flujo de trabajo de la aplicación. Ayuda a gestionar los diferentes pasos que tomará el agente, como decidir si utilizar la base de conocimiento o la búsqueda en la web, recuperar información relevante y generar respuestas. Al organizar estas tareas en nodos y definir rutas claras entre ellos, LangGraph garantiza que todo funcione de manera fluida y eficiente. Simplifica el manejo de decisiones complejas y mantiene la aplicación estructurada y fácil de mantener.
Para crear un gráfico, especifiquemos los nodos (acciones) y cómo se conectan.
from langgraph.graph import END, StateGraph, START
from langgraph.prebuilt import ToolNode
# Definir un nuevo gráfico
workflow = StateGraph(AgentState)
# Definir los nodos entre los que ciclaremos
workflow.add_node("agent", agent) # Nodo del agente
retrieve = ToolNode([retriever_tool])
workflow.add_node("retrieve", retrieve) # Nodo de recuperación
search = ToolNode([tool])
workflow.add_node("search", search) # Nodo de búsqueda
workflow.add_node("rewrite", rewrite) # Nodo de reescritura
workflow.add_node("generate", generate) # Nodo de generación
La función add_node agrega nodos al gráfico. El primer argumento es el nombre del nodo y el segundo es la función que representa.
# Definir las aristas
Las aristas definen las transiciones entre los nodos en función de ciertas condiciones. Las aristas controlan el flujo completo de la aplicación.
# Definir la arista condicional para las herramientas
Primero, definamos una condición que determine si utilizar el recuperador o la herramienta de búsqueda en función de la consulta del usuario. Si la consulta menciona "myscaledb" o "myscale", el agente utilizará el recuperador; de lo contrario, utilizará la herramienta de búsqueda.
def tools_condition(state) -> Literal["retrieve", "search"]:
messages = state["messages"]
question = messages[0].content.lower()
if "myscaledb" in question or "myscale" in question:
return "retrieve"
else:
return "search"
# Agregar las aristas
Ahora, agreguemos las aristas al gráfico de flujo de trabajo.
workflow.add_edge(START, "agent")
workflow.add_conditional_edges(
"agent",
tools_condition,
{
"search": "search",
"retrieve": "retrieve",
},
)
workflow.add_conditional_edges(
"retrieve",
grade_documents,
)
workflow.add_edge("retrieve", "generate")
workflow.add_edge("search", "generate")
workflow.add_edge("generate", END)
workflow.add_edge("rewrite", "agent")
# Compilar el gráfico
graph = workflow.compile()
La función add_edge define una transición directa de un nodo a otro. La función add_conditional_edges nos permite especificar transiciones basadas en condiciones. El primer argumento es el nodo de origen, el segundo es la función de condición y el tercero es un diccionario que asigna los posibles resultados de la condición a los nodos de destino.
# Visualizar el gráfico final
Visualicemos el gráfico final para ver cómo se conectan los nodos y las aristas.
from IPython.display import Image, display
try:
display(Image(graph.get_graph(xray=True).draw_mermaid_png()))
except Exception:
# Esto requiere algunas dependencias adicionales y es opcional
pass
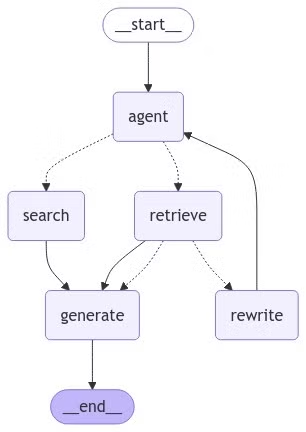
# Ejecutar el gráfico
Finalmente, ejecutemos el gráfico para ver nuestro sistema de preguntas y respuestas en acción.
inputs = {
"messages": [
("user", "¿Qué modelo lanzó OpenAI recientemente?"),
]
}
for output in graph.stream(inputs):
for value in output.items():
print(value["messages"][0], indent=2, width=80, depth=None)
Generará una salida como esta:
OpenAI lanzó recientemente un nuevo modelo de IA generativa llamado OpenAI o1.
Este modelo destaca en habilidades de "razonamiento", lo que le permite verificar sus propias afirmaciones y abordar problemas complejos como la codificación y las matemáticas. Fue lanzado el 12 de septiembre de 2024 y está disponible para los usuarios de ChatGPT Plus y Team.
Cuando se realiza la consulta sobre MyScaleDB de esta manera:
inputs = {
"messages": [
("user", "¿Qué es MyScaleDB?"),
]
}
for output in graph.stream(inputs):
for key, value in output.items():
print(value["messages"][0], indent=2, width=80, depth=None)
La salida sería algo como esto:
"MyScaleDB es una base de datos en la nube de alto rendimiento basada en ClickHouse de código abierto, diseñada específicamente para aplicaciones de IA y aprendizaje automático. Admite tanto datos estructurados como no estructurados, lo que la hace ideal para administrar grandes volúmenes de datos y realizar tareas analíticas complejas."

# Conclusión
Al completar este tutorial, ha construido con éxito un sistema de preguntas y respuestas dinámico que elige inteligentemente entre utilizar una base de conocimiento o realizar búsquedas en Internet en función de las consultas de los usuarios. Al integrar herramientas como LangChain, MyScaleDB, VoyageAI y Tavily, ha creado un agente de IA adaptable capaz de manejar eficientemente preguntas complejas. ¡Siga explorando estas herramientas para mejorar aún más sus aplicaciones de IA!



