
Las bases de datos vectoriales están diseñadas específicamente para almacenar y gestionar datos vectoriales, desempeñando un papel crucial en muchas aplicaciones de IA, como la búsqueda semántica de texto y la búsqueda de imágenes. Si bien los algoritmos tradicionales de coincidencia de términos y BM25 siguen siendo importantes en la recuperación de texto, el sistema Elasticsearch ampliamente adoptado ha añadido recientemente capacidades de búsqueda vectorial. Es importante destacar que MyScaleDB, una base de datos vectorial SQL de código abierto y de alto rendimiento, también ha introducido recientemente la búsqueda de texto completo (opens new window) . En este artículo, demostramos que MyScaleDB rivaliza con Elasticsearch en el rendimiento de búsqueda de texto completo, al tiempo que logra una latencia más baja y utiliza un 40% menos de memoria. Además, al incorporar la búsqueda vectorial, MyScale logra un rendimiento hasta 10 veces mayor, consumiendo solo el 12% del costo. Con su alto rendimiento, bajo costo y un rico ecosistema SQL basado en ClickHouse, MyScaleDB se presenta como una actualización y alternativa eficiente y potente a Elasticsearch.
# ¿Qué es Elasticsearch?
Elasticsearch es un motor de búsqueda y análisis distribuido y RESTful construido sobre Apache Lucene. Puede almacenar, buscar y analizar rápidamente grandes cantidades de datos y se utiliza ampliamente en áreas como análisis de registros, búsquedas de aplicaciones, análisis de seguridad y análisis empresarial.
Elasticsearch tiene las siguientes ventajas:
- Potentes capacidades de búsqueda: Elasticsearch ofrece potentes capacidades de búsqueda de texto completo, incluyendo búsqueda de valores exactos, búsqueda de texto completo y búsqueda vectorial, así como operaciones de consulta, filtrado y agregación complejas, lo que permite a los usuarios recuperar la información deseada de forma rápida y precisa.
- Funciones avanzadas: Elasticsearch ofrece funciones avanzadas y opciones de configuración flexibles, como análisis de texto, análisis de agregación y búsqueda geoespacial, para satisfacer una amplia variedad de necesidades de búsqueda y análisis.
- Ecosistema rico: El ecosistema de Elasticsearch es vasto. Incluye varios complementos, herramientas e integraciones de terceros que amplían su funcionalidad y escenarios de aplicación, brindando a los usuarios más opciones y flexibilidad.
- Arquitectura distribuida: Como sistema distribuido, Elasticsearch puede escalar fácilmente a muchos nodos, logrando alta disponibilidad y escalabilidad horizontal, lo que lo hace adecuado para tareas de procesamiento y análisis de datos a gran escala.
- Procesamiento de datos en tiempo real: Elasticsearch admite la indexación y búsqueda de datos en tiempo real, lo que le permite procesar rápidamente grandes cantidades de datos en tiempo real y proporcionar resultados de consulta instantáneos.
Sin embargo, Elasticsearch todavía tiene algunas limitaciones, que incluyen:
- Curva de aprendizaje pronunciada: Elasticsearch tiene una curva de aprendizaje relativamente pronunciada, especialmente para principiantes, lo que requiere tiempo para comprender sus conceptos y métodos de uso complejos.
- Algoritmos de recuperación vectorial limitados: Hasta la versión 8.13, Elasticsearch tiene un soporte limitado para algoritmos de recuperación vectorial, como kNN por fuerza bruta y kNN aproximado basado en HNSW. Esto limita su aplicación en escenarios de recuperación vectorial complejos.
- Alto consumo de recursos: Debido a sus potentes características y arquitectura distribuida, Elasticsearch requiere recursos relativamente altos en tiempo de ejecución, incluyendo memoria, CPU y espacio de almacenamiento.
En resumen, Elasticsearch es una herramienta poderosa en el campo de la recuperación de texto. Sin embargo, tiene algunas limitaciones en cuanto a usabilidad, recuperación vectorial y utilización de recursos, lo que limita su aplicación en escenarios complejos de recuperación y análisis de IA.
# Alternativa preferida a Elasticsearch: MyScaleDB
MyScaleDB está construido sobre la base de datos de almacenamiento columnar SQL de código abierto ClickHouse. Cuenta con un algoritmo de indexación vectorial de alto rendimiento y alta densidad de datos desarrollado internamente. Hemos realizado una investigación profunda y optimización en sus capacidades de recuperación y motores de almacenamiento para consultas conjuntas de SQL y vectores, lo que hace que MyScaleDB sea el primer producto de base de datos vectorial SQL del mundo que supera significativamente a las bases de datos vectoriales dedicadas en términos de rendimiento integral y rentabilidad.
# Compatibilidad nativa con SQL y Vector
Los usuarios interactúan con MyScaleDB utilizando SQL, lo que reduce las barreras de entrada y disminuye la curva de aprendizaje para que puedan comenzar rápidamente y aumentar fácilmente su conocimiento. MyScaleDB ofrece un modelo de datos y un lenguaje de consulta flexibles, lo que permite a los usuarios personalizar el procesamiento de datos y las estrategias de análisis según sus necesidades específicas, mejorando así la flexibilidad y la eficiencia de ejecución de la aplicación. La combinación de SQL y vectores en escenarios de aplicaciones de IA complejas brinda a los desarrolladores un método de desarrollo más intuitivo y eficiente, lo que aumenta significativamente la eficiencia de los desarrolladores.
A diferencia del Lenguaje Específico de Dominio (DSL) de Elasticsearch, que se basa en consultas JSON, los usuarios solo necesitan dominar la función de recuperación de vectores distance() para utilizar MyScaleDB. Pueden desarrollar consultas de recuperación de vectores complejas con esta información y su conocimiento existente de SQL. Además, también pueden realizar análisis y procesamiento de datos complejos a nivel de base de datos, acelerando la eficiencia de procesamiento general del sistema de aplicaciones.
Por ejemplo:
-- Realizar una búsqueda vectorial y devolver los 10 mejores resultados
SELECT
id, title, text
distance(vector, query_vector) as dist
FROM doc_table
ORDER BY
dist ASC
LIMIT 10;
# Reemplazando Elasticsearch con Capacidades de Búsqueda de Texto
En la última versión, MyScaleDB ha introducido funciones potentes como la búsqueda de texto completo y la búsqueda híbrida, proporcionando soluciones prácticas para manejar los requisitos complejos de IA y los desafíos de datos actuales y futuros. Incorpora la biblioteca de motores de búsqueda de texto completo Tantivy, que cuenta con una construcción de índices rápida, una búsqueda eficiente y soporte de multihilo. Además, es muy fácil de usar, extremadamente flexible y muy adecuada para buscar rápidamente datos de texto almacenados en la base de datos y devolver el conjunto de resultados que es la coincidencia más cercana, según las puntuaciones BM25.
Por ejemplo, la siguiente tabla contiene los resultados de una prueba de capacidades de búsqueda de texto que realizamos en el mismo conjunto de datos, "wiki" (560 millones de registros). La latencia de consulta P95 de MyScaleDB se reduce significativamente y también hay una disminución notable en el uso de memoria. Por lo tanto, en el contexto de la búsqueda de texto completo y en términos de funcionalidad, MyScaleDB puede reemplazar eficazmente a Elasticsearch.
| Motor | Función | QPS | Latencia p95 | Memoria máxima |
|---|---|---|---|---|
| MyScaleDB | TextSearch | 4099.16 | 4.563ms | 2.35GB |
| ElasticSearch | match | 3907 | 8.863ms | 3.7GB |
| ElasticSearch | wildcard | 4679.16 | 5.583ms | 3.7GB |
# Superando a Elasticsearch con Capacidades de Búsqueda Vectorial
MyScaleDB utiliza tecnología de recuperación vectorial y admite varios algoritmos de indexación vectorial, incluidos MTSG, SCANN, FLAT y las familias HNSW e IVF. Esto satisface mejor las necesidades de recuperación de varios escenarios de IA y tiene una ventaja absoluta en el procesamiento de datos de alta dimensión a gran escala.
Utilizando un conjunto de datos a gran escala (LAION 5M vectores, 768 dimensiones), se probó el rendimiento de MyScaleDB y Elasticsearch en la búsqueda vectorial bajo diferentes hilos de consulta concurrentes. Los resultados de las pruebas de precisión y rendimiento se muestran en la siguiente figura.
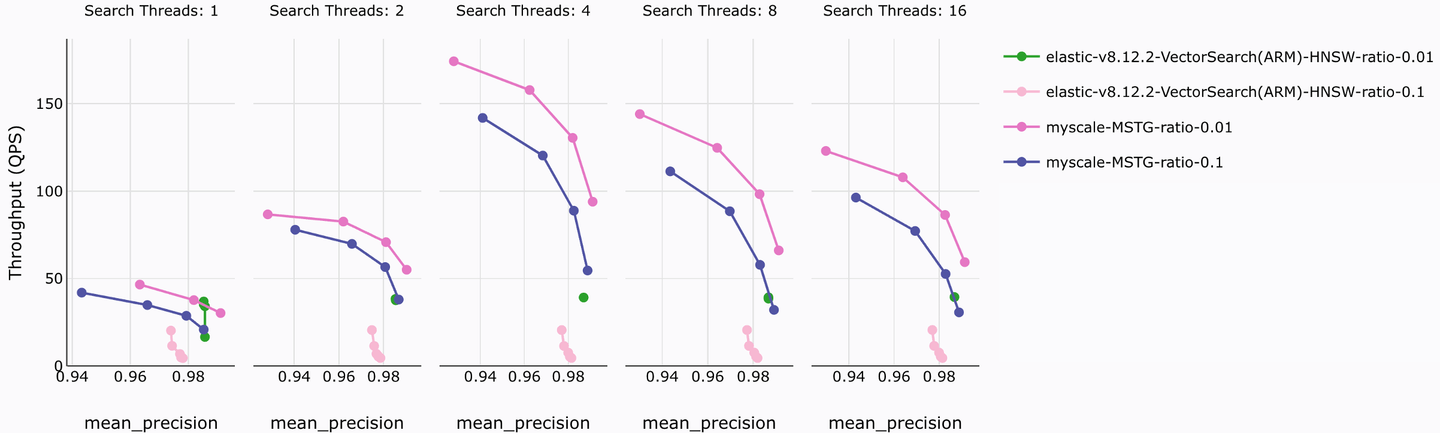
Esta prueba probó dos ratios de filtrado comunes, 0.1 y 0.01. Un análisis de los resultados muestra que, bajo una precisión similar, el índice MSTG de MyScaleDB demuestra una mejora de rendimiento de hasta 10 veces en QPS. MyScaleDB tiene ventajas similares en cuanto al consumo de recursos del índice, tiempo de creación, latencia de consulta y costo de consulta.
Es aún más notable que el servicio MyScaleDB SaaS solo cuesta $120 al mes para servir 5 millones de vectores, mientras que ElasticCloud es más de ocho veces más caro, con un costo de $982. Además, MyScaleDB admite múltiples tipos de índices vectoriales y, combinado con su potente rendimiento de recuperación y costos de uso rentables, es más adecuado para escenarios de consulta y análisis de recuperación vectorial que Elasticsearch.
Puede consultar el Banco de Pruebas de la Base de Datos Vectorial MyScaleDB (opens new window) para obtener más resultados de pruebas de rendimiento.
# Uso Rentable de Recursos
Como se describió anteriormente, MyScaleDB está construido sobre ClickHouse, la base de datos de código abierto más rápida y eficiente en términos de recursos para aplicaciones y análisis en tiempo real. Algunas de las características avanzadas de ClickHouse lo convirtieron en una buena elección, incluyendo un mecanismo de indexación eficiente, tecnología de compresión de datos, estructura de almacenamiento columnar, ejecución de consultas vectorizadas y capacidades de procesamiento distribuido.
Además, el motor de consultas de MyScaleDB está optimizado para CPUs y memoria modernas. Utiliza el procesamiento de consultas vectorizadas y técnicas de procesamiento paralelo de datos para aprovechar al máximo el rendimiento de los procesadores multinúcleo, acelerando los cálculos de datos. Heredando el modelo de almacenamiento columnar de ClickHouse, MyScaleDB logra una compresión eficiente de datos y operaciones rápidas a nivel de columna. Solo lee las columnas especificadas en la consulta, lo que reduce el volumen de lectura de datos, mejora las tasas de compresión de datos y reduce los costos de almacenamiento, lo que lo hace especialmente adecuado para analizar y procesar grandes cantidades de datos.
En resumen, al combinar la tecnología de recuperación vectorial, el motor de búsqueda de texto completo Tantivy, las características de alto rendimiento de ClickHouse, la arquitectura distribuida y el motor de consultas optimizado, MyScaleDB logra un procesamiento y análisis eficiente de conjuntos de datos a gran escala. Es especialmente adecuado para análisis de datos complejos, búsqueda híbrida, búsqueda de texto completo y escenarios de recuperación vectorial.
# Cómo Reemplazar Elasticsearch con MyScaleDB
Este proceso implica tareas como el diseño del modelo de datos, la migración de datos y la conversión de la lógica de consulta. Consulte la guía de Inicio Rápido (opens new window) para obtener más información sobre cómo configurar rápidamente un clúster de MyScaleDB, importar datos y ejecutar consultas SQL.
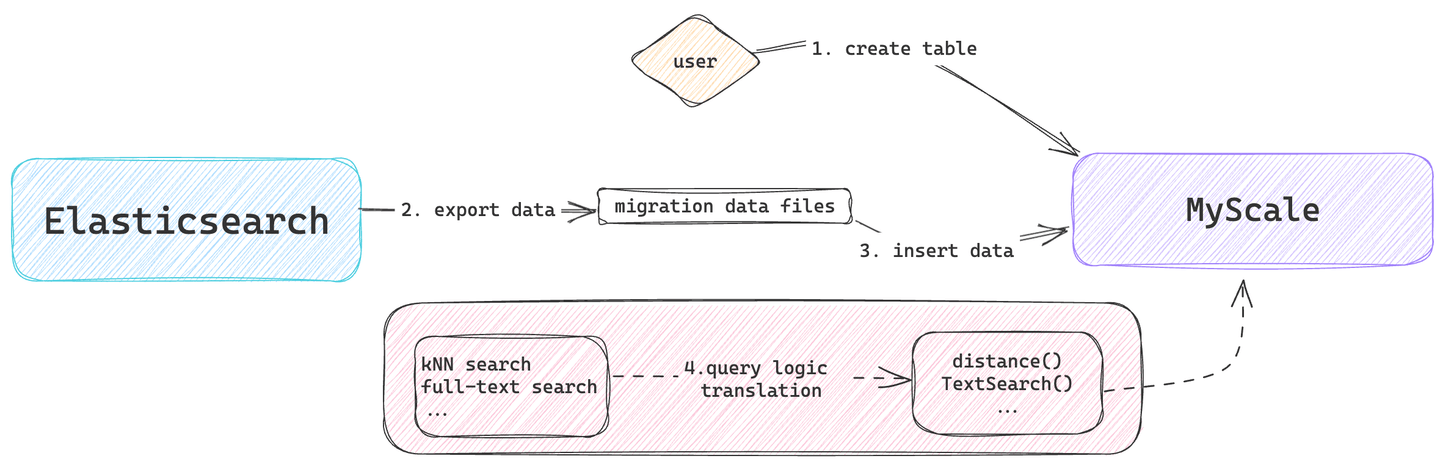
# Diseño del Modelo de Datos
La fase de diseño del modelo de datos implica determinar cómo mapear el modelo de documentos en Elasticsearch a la estructura de tabla en MyScaleDB. Principalmente define las columnas, los tipos de datos y los tipos de índice para las tablas de datos migradas en MyScaleDB.
# Conversión de Tipos de Datos
MyScaleDB es compatible con todos los tipos de datos de ClickHouse; por lo tanto, todos los tipos de datos de campo en Elasticsearch tienen tipos de datos correspondientes en MyScaleDB.
Nota:
El tipo dense_vector utilizado para la búsqueda vectorial en Elasticsearch debe mapearse a Array(Float32) o FixedString en MyScaleDB según el element_type. Además, se debe agregar la restricción de longitud correspondiente a la columna.
# Definición de Índice Vectorial
MyScaleDB admite varios tipos de índices vectoriales. Sin embargo, recomendamos encarecidamente utilizar índices MSTG para obtener un rendimiento óptimo.
Consulte el tutorial de consulta vectorial (opens new window) para obtener información sobre cómo crear y operar índices vectoriales para acelerar la búsqueda vectorial.
Aquí hay un ejemplo que convierte el índice de imágenes en Elasticsearch a la tabla es_data_migration en MyScaleDB:
{
"image-index": {
"mappings": {
"properties": {
"file-type": {
"type": "keyword"
},
"image-vector": {
"type": "dense_vector",
"dims": 3,
"index": true,
"similarity": "l2_norm"
},
"title": {
"type": "text"
},
"title-vector": {
"type": "dense_vector",
"dims": 5,
"index": true,
"similarity": "l2_norm"
}
}
}
}
}
CREATE TABLE default.es_data_migration
(
`id` UInt32,
`file_type` String,
`image_vector` Array(Float32),
`title` String,
`title_vector` Array(Float32),
VECTOR INDEX vec_ind_image image_vector TYPE MSTG('metric_type=L2'),
VECTOR INDEX vec_ind_title title_vector TYPE MSTG('metric_type=L2'),
CONSTRAINT check_length_image CHECK length(image_vector) = 3,
CONSTRAINT check_length_title CHECK length(title_vector) = 5
)
ENGINE = MergeTree
PRIMARY KEY id;
# Migración de Datos
Esta fase implica principalmente exportar datos de Elasticsearch y su posterior importación en MyScaleDB.
- Exportar datos de Elasticsearch: Los usuarios pueden exportar datos en formatos comunes (como JSON o CSV) utilizando varios métodos, como la API de Elasticsearch, Logstash, la función de Informes CSV de Kibana y la herramienta Python es2csv.
- Importar datos en MyScaleDB: MyScaleDB admite diferentes métodos de importación de datos, incluyendo el cliente de Python (opens new window), la interfaz HTTPS (opens new window), etc.
Por ejemplo, aquí hay un ejemplo que utiliza el cliente de Python para migrar archivos de datos exportados de Elasticsearch a MyScaleDB:
import clickhouse_connect
import pandas as pd
# inicializar el cliente
# Para los usuarios de SaaS, vaya a la página de Clusters de MyScaleDB, haga clic en el enlace desplegable de Acción y seleccione Detalles de conexión.
client = clickhouse_connect.get_client(
host='127.0.0.1',
port=8123,
username='default',
password=''
)
def convert_vector(vector_str):
return list(map(float, vector_str.split(', ')))
# leer archivo de datos de migración
data = pd.read_csv('test.csv', usecols=['_id', 'image-vector', 'title', 'title-vector'], converters={'image-vector': convert_vector, 'title-vector': convert_vector})
# insertar datos en la tabla de migración
client.insert('default.es_data_migration', data.values.tolist(), ['id', 'image_vector', 'title', 'title_vector'])
# Traducción de la Lógica de Consulta
La lógica de consulta original de la aplicación, que inicialmente era manejada por Elasticsearch, se ha cambiado a una búsqueda de MyScaleDB y la lógica de procesamiento de datos correspondiente se ha actualizado en consecuencia.
{
"knn": {
"field": "image-vector",
"query_vector": [-5, 9, -12],
"k": 10,
"num_candidates": 100
},
"fields": [ "title", "file-type" ]
}
SELECT
id,
title,
file_type,
distance(image_vector, [-5.0, 9.0, -12.0]) AS l2_dist
FROM default.es_data_migration
ORDER BY l2_dist ASC
LIMIT 10

# Conclusión
A través de un análisis comparativo de la funcionalidad y el rendimiento entre MyScaleDB y Elasticsearch, se puede ver que MyScaleDB no solo es un reemplazo eficiente y una actualización de Elasticsearch, sino también una solución de datos avanzada que puede adaptarse a las necesidades futuras de datos y tendencias tecnológicas. Tiene ventajas significativas, especialmente en la búsqueda vectorial y los costos de recursos.
Además, basado en la potente arquitectura de almacenamiento y procesamiento distribuido de ClickHouse, MyScaleDB es altamente flexible en cuanto a escalabilidad, lo que le permite escalar a grandes clústeres para satisfacer fácilmente las crecientes demandas de datos.
Además, MyScaleDB es compatible con los componentes del ecosistema de ClickHouse, que incluyen abundantes recursos de documentación y un amplio soporte de la comunidad. También está integrado con herramientas de desarrollo populares en todo el mundo, como Python Client (opens new window), Node.js (opens new window) y el marco LLM, que incluye OpenAI (opens new window), LangChain (opens new window), LangChain JS/TS (opens new window) y LlamaIndex (opens new window), lo que brinda a los usuarios una mejor experiencia y soporte.
Por último, MyScaleDB admite una amplia gama de tipos de datos y sintaxis de consulta, lo que lo hace adaptable a diferentes requisitos de datos y escenarios de consulta. Con sus completas capacidades de gestión de datos SQL, almacenamiento de datos robusto y capacidades de consulta, MyScaleDB desempeñará un papel cada vez más importante en el almacenamiento y procesamiento de datos en el futuro, brindando a los usuarios servicios más ricos y eficientes.



