
En el mundo actual, los sistemas de recomendación se han vuelto vitales para mejorar la experiencia del usuario en diversas plataformas, incluyendo comercio electrónico, servicios de transmisión, noticias, redes sociales y aprendizaje personalizado.
En el ámbito de los sistemas de recomendación, los enfoques convencionales se basaban en el análisis de las interacciones entre usuarios y elementos, y en la evaluación de las similitudes entre elementos. Sin embargo, con los avances en el campo de la Inteligencia Artificial, el área de los sistemas de recomendación también ha evolucionado, mejorando la precisión y adaptando las recomendaciones a las preferencias individuales.
# Enfoques de recomendación de contenido ampliamente adoptados
Existen tres tipos de filtrado utilizados en los sistemas de recomendación de contenido. Algunos utilizan el filtrado colaborativo (opens new window), otros utilizan el filtrado basado en contenido (opens new window), y otros utilizan una combinación de ambos métodos. Veamos cada uno de ellos en detalle.
# Filtrado basado en contenido
El filtrado basado en contenido se centra en las características de los elementos en sí mismos. Recomienda elementos similares a aquellos en los que un usuario ha mostrado interés anteriormente.
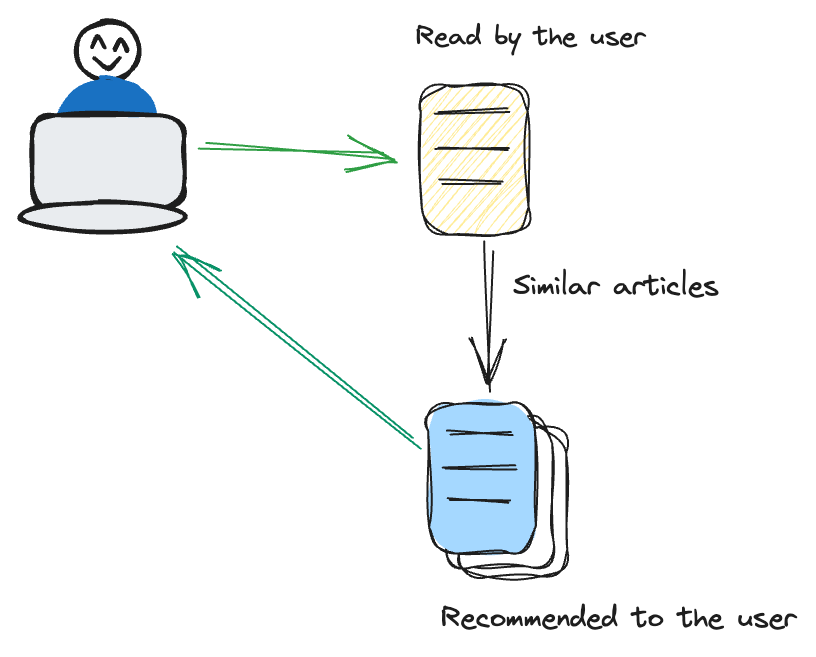
Por ejemplo, si un usuario ve con frecuencia películas de suspense, el sistema de recomendación adopta un enfoque personalizado sugiriendo películas adicionales dentro del género de suspense. Este método pone un énfasis significativo en las características inherentes de los elementos, como el género, el autor o el artista. Al centrarse en estos atributos, el sistema garantiza una estrategia de recomendación más específica y orientada al contenido, alineada estrechamente con las preferencias del usuario.
# Filtrado colaborativo
El filtrado colaborativo se centra en el usuario. Analiza los patrones y similitudes en el comportamiento del usuario para hacer recomendaciones.
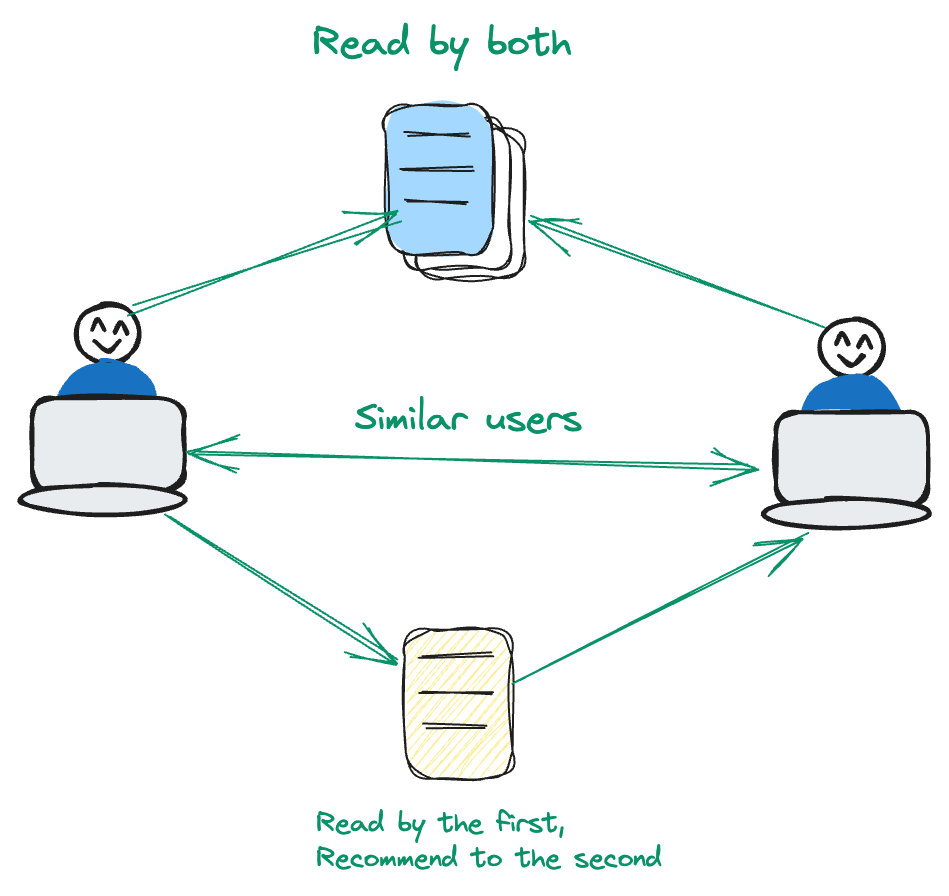
Consideremos un escenario en el que el Usuario A y el Usuario B comparten un interés común en un conjunto particular de películas. Ahora, si el Usuario B expresa su gusto por una película que el Usuario A aún no ha encontrado, el sistema de recomendación toma nota. En esta metodología, el énfasis se encuentra en aprovechar las interacciones y preferencias de los usuarios, alejándose de un enfoque centrado en el contenido. Al priorizar las relaciones dinámicas entre usuarios y elementos, el sistema perfecciona sus recomendaciones para ofrecer una experiencia de usuario más personalizada.
# Técnicas híbridas
Las técnicas híbridas integran ingeniosamente las fortalezas tanto del filtrado basado en contenido como del filtrado colaborativo para mejorar la precisión de las recomendaciones. Al aprovechar un enfoque dual que incorpora tanto las características de los elementos como los patrones de preferencia del usuario, este método aborda de manera hábil las limitaciones inherentes presentes al depender únicamente de cada enfoque de forma independiente. Las técnicas híbridas son particularmente efectivas para proporcionar recomendaciones refinadas y diversificadas.
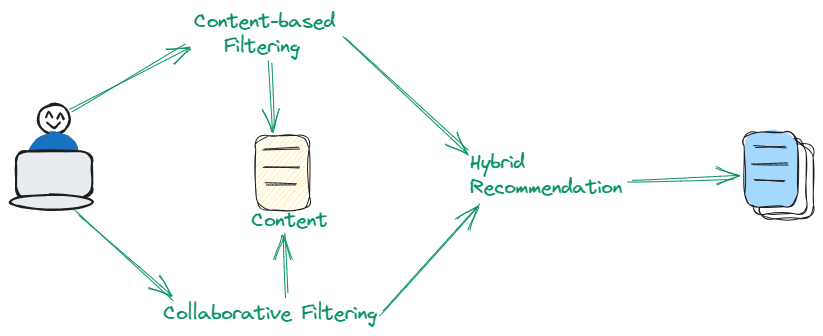
# Enfoque avanzado de recomendación de contenido
La aparición de los Modelos de Lenguaje Grande (LLMs, por sus siglas en inglés) ha simplificado significativamente diversas tareas, especialmente la evolución de los sistemas de recomendación. Para los sistemas de recomendación modernos, la dependencia convencional del filtrado de contenido o colaborativo ha dado paso a un enfoque más sofisticado. Aprovechando el poder de la semántica, los sistemas de recomendación modernos navegan y exploran el significado lingüístico para proponer elementos relacionados.
En este blog, te mostraré cómo construir un sistema de recomendación de contenido con este enfoque avanzado. Primero, echemos un vistazo a las herramientas necesarias para este sistema.
![]()
# Herramientas y tecnologías
Utilizaremos el modelo de incrustación de texto de OpenAI (opens new window), MyScale como base de datos vectorial (opens new window) y el conjunto de datos de películas TMDB 5000 (opens new window) en este proyecto.
- OpenAI: Utilizaremos el modelo de OpenAI
text-embedding-3-smallpara obtener las incrustaciones del texto y luego utilizaremos estas incrustaciones para desarrollar el modelo. - MyScale: MyScale es una base de datos vectorial SQL que utilizamos para almacenar y procesar datos estructurados y no estructurados de manera optimizada.
- Conjunto de datos de películas TMDB 5000: Este conjunto de datos contiene una colección de metadatos de películas, incluyendo el reparto, el equipo, el presupuesto y los detalles de ingresos.
# Cargando los datos
Tenemos dos archivos CSV clave: tmdb_5000_credits.csv y tmdb_5000_movies.csv. Estos archivos contienen información esencial sobre una variedad diversa de películas, que serán la base de nuestro sistema de recomendación.
import pandas as pd
credits = pd.read_csv("tmdb_5000_credits.csv")
movies = pd.read_csv("tmdb_5000_movies.csv")
# Preprocesamiento de datos
El preprocesamiento de datos es crucial para garantizar la calidad del sistema de recomendación. Combinaremos los dos archivos CSV y nos centraremos en las columnas más relevantes: title, overview, genres, cast y crew. Este paso consiste en refinar los datos para que sean adecuados para nuestro modelo.
credits.rename(columns = {'movie_id':'id'}, inplace = True)
df = credits.merge(movies, on = 'id')
df.dropna(subset = ['overview'], inplace=True)
df = df[['id', 'title_x', 'genres', 'overview', 'cast', 'crew']]
Al combinar y filtrar nuestros datos, hemos creado un conjunto de datos limpio y enfocado para el sistema.
# Generando el corpus
A continuación, generamos un corpus para cada película combinando su overview, genre, cast y crew en una sola cadena de texto. Esta información completa ayuda al sistema a realizar recomendaciones precisas.
import pandas as pd
# Suponiendo que 'df' es tu DataFrame y tiene las columnas 'overview', 'genres', 'cast' y 'crew'
def generate_corpus(row):
overview, genre, cast, crew = row['overview'], row['genres'], row['cast'], row['crew']
corpus = ""
genre = ','.join([i['name'] for i in eval(genre)])
cast = ','.join([i['name'] for i in eval(cast)[:3]])
crew = ','.join(list(set([i['name'] for i in eval(crew) if i['job'] == 'Director' or i['job'] == 'Producer'])))
corpus += overview + " " + genre + " " + cast + " " + crew
return pd.Series([corpus, crew, cast, genre], index=['corpus', 'crew', 'cast', 'genres'])
# Aplica la función a cada fila
df[['corpus', 'crew', 'cast', 'genres']] = df.apply(generate_corpus, axis=1)
# Obteniendo las incrustaciones
Luego utilizamos el modelo de incrustación de texto text-embedding-3-small de OpenAI para convertir nuestro corpus en incrustaciones, que son representaciones numéricas del contenido de la película.
import os
import numpy as np
import openai
os.environ["OPENAI_API_KEY"] = "tu-clave-de-API"
def get_embeddings(text):
response = openai.embeddings.create(
model="text-embedding-3-small",
input=text
)
return response.data
# Obtén las primeras 1000 entradas porque no podemos pasar las 5000 entradas completas al modelo de incrustaciones. Si deseas obtener las incrustaciones de todo el conjunto de datos, puedes aplicar un bucle
df=df[0:1000]
embeddings=get_embeddings(df["corpus"].tolist())
vectors = [embedding.embedding for embedding in embeddings]
array = np.array(vectors)
embeddings_series = pd.Series(list(array))
df['embeddings'] = embeddings_series
Al obtener la representación vectorial del texto, ahora podemos aplicar fácilmente la búsqueda semántica utilizando MyScale.
# Configurando MyScale
Como hemos discutido al principio, utilizaremos MyScale como una base de datos vectorial para almacenar y gestionar los datos. Aquí, nos conectaremos a MyScale para prepararnos para el almacenamiento de datos.
import clickhouse_connect
client = clickhouse_connect.get_client(
host='tu-nombre-de-host',
port=443,
username='tu-nombre-de-usuario',
password='tu-contraseña'
)
Nota: Consulta los Detalles de conexión (opens new window) para obtener más información sobre cómo conectarte al clúster de MyScale.
# Creando una tabla
Ahora creamos una tabla de acuerdo con nuestro DataFrame. Todos los datos se almacenarán en esta tabla, incluyendo las incrustaciones.
client.command("""
CREATE TABLE default.movies (
id Int64,
title_x String,
genres String,
overview String,
cast String,
crew String,
corpus String,
embeddings Array(Float32),
CONSTRAINT check_data_length CHECK length(embeddings) = 1536
) ENGINE = MergeTree()
ORDER BY id
""")
Las declaraciones SQL anteriores crean una tabla llamada movies en el clúster. La CONSTRAINT se asegura de que todas las incrustaciones vectoriales tengan la misma longitud 1536.
# Almacenando los datos y creando un índice en MyScale
En este paso, insertamos los datos procesados en MyScale. Esto implica la inserción por lotes de los datos para garantizar un almacenamiento y recuperación eficientes.
tamaño_lote = 100 # Ajusta según tus necesidades
num_lotes = len(df) // tamaño_lote
for i in range(num_lotes):
índice_inicial = i * tamaño_lote
índice_final = índice_inicial + tamaño_lote
datos_lote = df[índice_inicial:índice_final]
client.insert("default.movies", datos_lote.to_records(index=False).tolist(), column_names=datos_lote.columns.tolist())
print(f"Lote {i+1}/{num_lotes} insertado.")
client.command("""
ALTER TABLE default.movies
ADD VECTOR INDEX vector_index embeddings
TYPE MSTG
""")
# Generando recomendaciones de películas
Finalmente, creamos una función que genera recomendaciones de películas en función de la entrada del usuario. Esta función utiliza un factor de decaimiento exponencial para dar más relevancia a las películas vistas recientemente, mejorando la calidad de las recomendaciones.
import numpy as np
from IPython.display import clear_output
géneros = []
for i in range(3):
género = input("Ingresa un género: ")
géneros.append(género)
cadena_géneros = ', '.join(géneros)
incrustaciones_género=get_embeddings(cadena_géneros)
incrustaciones=incrustaciones_género[0].embedding
incrustaciones = np.array(incrustaciones_género[0].embedding) # Convertir a matriz numpy
factor_de_decaimiento = 0.9 # Ajustar según sea necesario para el decaimiento exponencial
while True:
clear_output(wait=True)
# Utilizar las incrustaciones combinadas para consultar la base de datos
resultados = client.query(f"""
SELECT title_x, genres,
distance(embeddings, {incrustaciones.tolist()}) as dist FROM default.movies ORDER BY dist LIMIT 10
""")
# Mostrar los resultados
print("Películas recomendadas:")
películas = []
for fila in resultados.named_results():
print(fila["title_x"])
películas.append(fila['title_x'])
# Pedir al usuario que seleccione una película
selección = int(input("Selecciona una película (o ingresa 0 para salir): "))
if selección == 0:
break
película_seleccionada = películas[selección - 1]
# Obtener las incrustaciones del título de la película seleccionada
incrustaciones_película_seleccionada = get_embeddings(película_seleccionada)[0].embedding
incrustaciones_película_seleccionada_array = np.array(incrustaciones_película_seleccionada)
# Aplicar el decaimiento exponencial y actualizar las incrustaciones combinadas
incrustaciones = factor_de_decaimiento * incrustaciones + (1 - factor_de_decaimiento) * incrustaciones_película_seleccionada_array
# Normalizar las incrustaciones combinadas
incrustaciones = incrustaciones / np.linalg.norm(incrustaciones)
Ahora hemos construido un sistema de recomendación de películas completamente funcional utilizando MyScale e incrustaciones vectoriales. Siéntete libre de experimentar con este tutorial o crear el tuyo propio según tus necesidades.

# Resumen
En este tutorial, hemos explorado cómo combinar LLMs con una base de datos vectorial como MyScale para crear un sistema de recomendación de contenido. La elección de la base de datos vectorial adecuada es crucial para desarrollar cualquier aplicación eficiente. MyScale se destaca en el manejo de datos vectoriales y metadatos estructurados, garantizando respuestas rápidas y precisas a las consultas. Su capacidad para escalar eficientemente garantiza un rendimiento sólido, incluso a medida que los conjuntos de datos se expanden. Con funciones avanzadas de indexación y consulta, MyScale mejora significativamente el rendimiento y la precisión de tu aplicación.
¿Tienes planes de construir una aplicación de IA con MyScale? Únete a nosotros para compartir tus ideas en Twitter (opens new window) y Discord (opens new window).



