
Las tuberías de datos de Recuperación-Aumentación Básica (RAG) (opens new window) a menudo dependen de pasos codificados en duro, siguiendo un camino predefinido cada vez que se ejecutan. En estos sistemas, no hay toma de decisiones en tiempo real y no se ajustan dinámicamente las acciones en función de los datos de entrada. Esta limitación puede reducir la flexibilidad y capacidad de respuesta en entornos complejos o cambiantes, lo que destaca una gran debilidad en los sistemas RAG tradicionales.
LlamaIndex resuelve esta limitación al introducir agentes (opens new window). Los agentes son un paso más allá de nuestros motores de consulta en el sentido de que no solo pueden "leer" de una fuente estática de datos, sino que también pueden ingerir y modificar dinámicamente datos de varias herramientas. Impulsados por un LLM, estos agentes están diseñados para realizar una serie de acciones para lograr una tarea específica eligiendo las herramientas más adecuadas de un conjunto proporcionado. Estas herramientas pueden ser tan simples como funciones básicas o tan complejas como motores de consulta LlamaIndex completos. Procesan las entradas o consultas de los usuarios, toman decisiones internas sobre cómo manejar estas entradas y deciden si son necesarios pasos adicionales o si se puede entregar un resultado final. Esta capacidad de realizar razonamiento y toma de decisiones automatizados hace que los agentes sean altamente adaptables y eficientes para tareas complejas de procesamiento de datos.
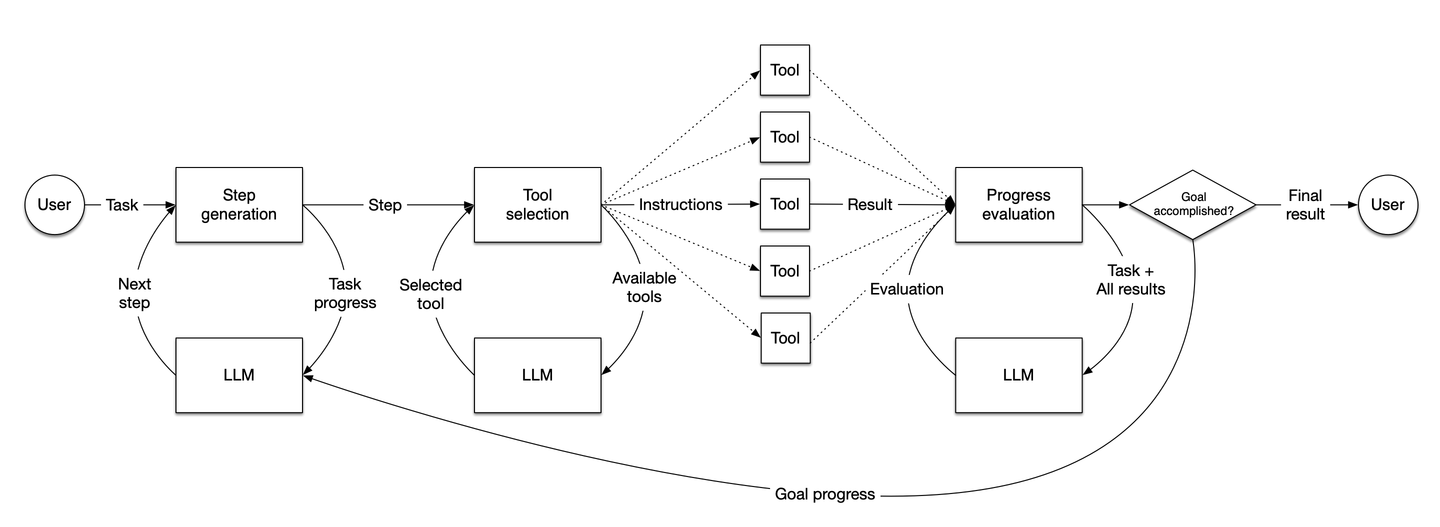
Fuente: LlamaIndex
El diagrama ilustra el flujo de trabajo de los agentes de LlamaIndex. Cómo generan pasos, toman decisiones, seleccionan herramientas y evalúan el progreso para lograr dinámicamente tareas basadas en las entradas del usuario.
# Componentes principales de un agente de LlamaIndex
Hay dos componentes principales de un agente en LlamaIndex: AgentRunner y AgentWorker.
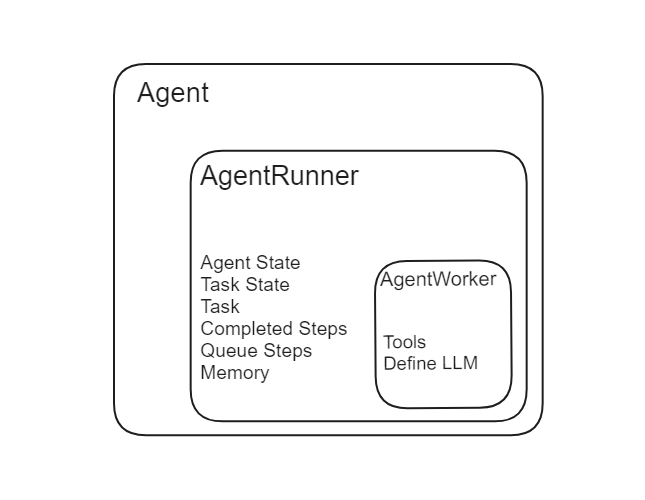
Fuente: LlamaIndex
# Agent Runner
El Agent Runner es el orquestador dentro de LlamaIndex. Gestiona el estado del agente, incluida la memoria de conversación, y proporciona una interfaz de alto nivel para la interacción del usuario. Crea y mantiene tareas y es responsable de ejecutar pasos en cada tarea. A continuación, se muestra un desglose detallado de sus funcionalidades:
- Creación de tareas: El Agent Runner crea tareas basadas en consultas o entradas del usuario.
- Gestión del estado: Almacena y mantiene el estado de la conversación y las tareas.
- Gestión de la memoria: Gestiona la memoria de conversación internamente, asegurando que se mantenga el contexto en las interacciones.
- Ejecución de tareas: Ejecuta pasos en cada tarea, coordinando con el Agente Worker.
A diferencia de los agentes de LangChain (opens new window), que requieren que los desarrolladores definan y pasen manualmente la memoria, los agentes de LlamaIndex manejan la gestión de la memoria internamente.
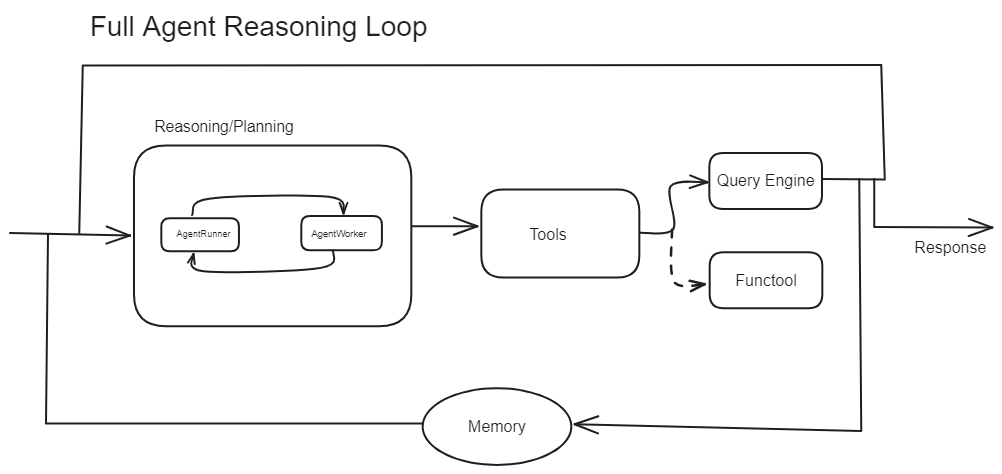
Fuente: LlamaIndex
# Agente Worker
El Agente Worker controla la ejecución paso a paso de una tarea dada por el Agente Runner. Es responsable de generar el siguiente paso en una tarea en función de la entrada actual. Los Agent Workers se pueden personalizar para incluir lógica de razonamiento específica, lo que los hace altamente adaptables a diferentes tareas. Los aspectos clave incluyen:
- Generación de pasos: Determina el siguiente paso en la tarea en función de los datos actuales.
- Personalización: Se puede adaptar para manejar tipos específicos de razonamiento o procesamiento de datos.
El Agente Runner gestiona la creación y el estado de las tareas, mientras que el Agente Worker lleva a cabo los pasos de cada tarea, actuando como la unidad operativa bajo la dirección del Agente Runner.
# Tipos de agentes en LlamaIndex
LlamIndex ofrece diferentes tipos de agentes diseñados para tareas y funciones específicas.
# Agentes de datos
Agentes de datos (opens new window) son agentes especializados diseñados para manejar una variedad de tareas de datos, incluida la recuperación y manipulación. Pueden operar tanto en modo de lectura como de escritura e interactuar sin problemas con diferentes fuentes de datos.
Los agentes de datos pueden buscar, recuperar, actualizar y manipular datos en varias bases de datos y API. Admiten la interacción con plataformas como Slack, Shopify, Google y más, lo que permite una integración fácil con estos servicios. Los agentes de datos pueden manejar operaciones de datos complejas como consultas a bases de datos, llamadas a API, actualización de registros y realización de transformaciones de datos. Su diseño adaptable los hace adecuados para una amplia gama de aplicaciones, desde la simple recuperación de datos hasta las tuberías de procesamiento de datos intrincadas.
from llama_index.agent import OpenAIAgent, ReActAgent
from llama_index.llms import OpenAI
# importar y definir herramientas
...
# inicializar llm
llm = OpenAI(model="gpt-3.5-turbo")
# inicializar agente de OpenAI
agent = OpenAIAgent.from_tools(tools, llm=llm, verbose=True)
# inicializar agente ReAct
agent = ReActAgent.from_tools(tools, llm=llm, verbose=True)
# usar agente
response = agent.chat("¿Cuál es el precio de BOYS NIKE DF STOCK RECRUIT PANT DJ573?")
# Agentes personalizados
Los agentes personalizados te brindan mucha flexibilidad y opciones de personalización. Al subclasificar CustomSimpleAgentWorker, puedes definir lógica y comportamiento específicos para tus agentes. Esto incluye manejar consultas complejas, integrar múltiples herramientas e implementar mecanismos de manejo de errores.
Puedes adaptar los agentes personalizados para satisfacer necesidades específicas mediante la definición de lógica paso a paso, mecanismos de reintento e integración de varias herramientas. Esta personalización te permite crear agentes que gestionen tareas y flujos de trabajo sofisticados, lo que los hace altamente adaptables a diferentes escenarios. Ya sea que administres operaciones de datos intrincadas o te integres con servicios únicos, los agentes personalizados brindan las herramientas que necesitas para construir soluciones especializadas y eficientes.
# Herramientas y especificaciones de herramientas
Las herramientas (opens new window) son el componente más importante de cualquier agente. Permiten que el agente realice diversas tareas y amplíe su funcionalidad. Al utilizar diferentes tipos de herramientas, un agente puede ejecutar operaciones específicas según sea necesario. Esto hace que el agente sea altamente adaptable y eficiente.
# Herramientas de función
Las herramientas de función te permiten convertir cualquier función de Python en una herramienta que un agente puede utilizar. Esta función es útil para crear operaciones personalizadas, mejorando la capacidad del agente para realizar una amplia gama de tareas.
Puedes transformar funciones simples en herramientas que el agente incorpora en su flujo de trabajo. Esto puede incluir operaciones matemáticas, funciones de procesamiento de datos y otra lógica personalizada.
Puedes convertir tu función de Python en una herramienta de esta manera:
from llama_index.core.tools import FunctionTool
def multiply(a: int, b: int) -> int:
"""Multiplica dos enteros y devuelve el resultado entero"""
return a * b
multiply_tool = FunctionTool.from_defaults(fn=multiply)
El método FunctionTool en LlamaIndex te permite convertir cualquier función de Python en una herramienta que un agente puede utilizar. El nombre de la función se convierte en el nombre de la herramienta y la cadena de documentación de la función se utiliza como descripción de la herramienta.
# Herramientas de QueryEngine
Las herramientas de QueryEngine envuelven motores de consulta existentes, lo que permite que los agentes realicen consultas complejas en fuentes de datos. Estas herramientas se integran con varias bases de datos y API, lo que permite que el agente recupere y manipule datos de manera eficiente.
Estas herramientas permiten que los agentes interactúen con fuentes de datos específicas, realicen consultas complejas y recuperen información relevante. Esta integración permite que el agente utilice los datos de manera efectiva en sus procesos de toma de decisiones.
Para convertir cualquier motor de consulta en una herramienta de motor de consulta, puedes utilizar el siguiente código:
from llama_index.core.tools import QueryEngineTool
from llama_index.core.tools import ToolMetadata
query_engine_tools = QueryEngineTool(
query_engine="tu_indice_como_motor_de_consulta_aquí",
metadata=ToolMetadata(
name="nombre_tu_herramienta",
description="Proporciona la descripción",
),
)
El método QueryEngineTool te permite convertir un motor de consulta en una herramienta que un agente puede utilizar. La clase ToolMetadata ayuda a definir el nombre y la descripción de esta herramienta. El nombre de la herramienta se establece mediante el atributo name y la descripción se establece mediante el atributo description.
Nota: La descripción de la herramienta es extremadamente importante porque ayuda al LLM a decidir cuándo usar esa herramienta.

# Construyendo un agente de IA usando MyScaleDB y LlamaIndex
Construyamos un agente de IA (opens new window) utilizando tanto una herramienta de motor de consulta como una herramienta de función para demostrar cómo se pueden integrar y utilizar estas herramientas de manera efectiva.
# Instalar las bibliotecas necesarias
Primero, instala las bibliotecas requeridas ejecutando el siguiente comando en tu terminal:
pip install myscale-client llama-index
Utilizaremos MyScaleDB (opens new window) como un motor de búsqueda vectorial para desarrollar el motor de consulta. Es una base de datos vectorial SQL avanzada diseñada especialmente para aplicaciones escalables.
# Obtener los datos para el motor de consulta
Utilizaremos el conjunto de datos del catálogo de Nike Nike catalog dataset (opens new window) para este ejemplo. Descarga y prepara los datos utilizando el siguiente código:
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
import requests
url = 'https://niketeam-asset-download.nike.net/catalogs/2024/2024_Nike%20Kids_02_09_24.pdf?cb=09302022'
response = requests.get(url)
with open('Nike_Catalog.pdf', 'wb') as f:
f.write(response.content)
reader = SimpleDirectoryReader(input_files=["Nike_Catalog.pdf"])
documents = reader.load_data()
Este código descargará el catálogo de Nike en formato PDF y cargará los datos para su uso en el motor de consulta.
# Conexión con MyScaleDB
Antes de usar MyScaleDB, necesitamos establecer una conexión:
import clickhouse_connect
client = clickhouse_connect.get_client(
host='tu_host_aquí',
port=443,
username='tu_nombre_de_usuario_aquí',
password='tu_contraseña_aquí'
)
Para obtener más información sobre cómo obtener los detalles del clúster y leer más sobre MyScale, puedes consultar la guía de inicio rápido de MyScaleDB (opens new window).
# Crear la herramienta del motor de consulta
Primero, construyamos la primera herramienta para nuestro agente, que es la herramienta del motor de consulta. Para ello, primero desarrollaremos el motor de consulta utilizando MyScaleDB y agregaremos los datos del catálogo de Nike al vector store.
from llama_index.vector_stores.myscale import MyScaleVectorStore
from llama_index.core import StorageContext
vector_store = MyScaleVectorStore(myscale_client=client)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
index = VectorStoreIndex.from_documents(
documents, storage_context=storage_context
)
query_engine = index.as_query_engine()
Una vez que los datos se hayan ingresado en el vector store y se haya creado un índice. El siguiente paso es transformar el motor de consulta en una herramienta. Para ello, utilizaremos el método QueryEngineTool de LlamaIndex.
from llama_index.core.tools import QueryEngineTool
from llama_index.core.tools import ToolMetadata
query_engine_tool = QueryEngineTool(
query_engine=index,
metadata=ToolMetadata(
name="nike_data",
description="Proporciona información sobre los productos de Nike. Utiliza una pregunta detallada en texto plano como entrada para la herramienta."
),
)
El QueryEngineTool toma query_engine y meta_data como argumentos. En los metadatos, definimos el nombre de la herramienta con la descripción.
# Crear la herramienta de función
Nuestra siguiente herramienta es una simple función de Python que multiplica dos números. Esta función se transformará en una herramienta utilizando el FunctionTool de LlamaIndex.
from llama_index.core.tools import FunctionTool
# Define una función simple de Python
def multiply(a: int, b: int) -> int:
"""Multiplica dos enteros y devuelve el resultado."""
return a * b
# Cambia la función a una herramienta
multiply_tool = FunctionTool.from_defaults(fn=multiply)
Después de esto, hemos terminado con las herramientas. Los agentes de LlamaIndex toman herramientas como una lista de Python. Entonces, agreguemos las herramientas a una lista.
tools = [multiply_tool, query_engine_tool]
# Definir el LLM
Definamos el LLM, el corazón de cualquier agente de LlamaIndex. La elección del LLM es crucial porque cuanto mejor sea la comprensión y el rendimiento del LLM, más efectivamente puede actuar como un tomador de decisiones y manejar problemas complejos. Utilizaremos el modelo gpt-3.5-turbo de OpenAI.
from llama_index.llms.openai import OpenAI
llm = OpenAI(model="gpt-3.5-turbo")
# Inicializar el agente
Como vimos anteriormente, un agente consta de un Agente Runner y un Agente Worker. Estos son dos componentes fundamentales de un agente. Ahora, exploraremos cómo funcionan en la práctica. Hemos implementado el código a continuación de dos maneras:
- Agente personalizado: El primer método es inicializar primero el Agente Worker con las herramientas y el llm. Luego, pasar el Agente Worker al Agente Runner para manejar el agente completo. Aquí, importas los módulos necesarios y compones tu propio agente.
from llama_index.core.agent import AgentRunner
from llama_index.agent.openai import OpenAIAgentWorker
# Método 2: Inicializar AgentRunner con OpenAIAgentWorker
openai_step_engine = OpenAIAgentWorker.from_tools(tools, llm=llm, verbose=True)
agent1 = AgentRunner(openai_step_engine)
- Usar agente predefinido: El segundo método es utilizar los Agentes que son la subclase de
AgentRunnerque agrupa elOpenAIAgentWorkeren el backend. Por lo tanto, no necesitamos definir el AgentRunner o AgentWorkers nosotros mismos, ya que están implementados en el backend.
from llama_index.agent.openai import OpenAIAgent
# Inicializar OpenAIAgent
agent = OpenAIAgent.from_tools(tools, llm=llm, verbose=True)
Nota: Cuando verbose=true se establece en LLMs, obtenemos información sobre el proceso de pensamiento del modelo, lo que nos permite comprender cómo llega a sus respuestas al proporcionar explicaciones y razonamientos detallados.
Independientemente del método de inicialización, puedes probar los agentes utilizando el mismo método. Probemos el primero:
# Llama al agente personalizado
agent = agent.chat("¿Cuál es el precio de BOYS NIKE DF STOCK RECRUIT PANT DJ573?")
Deberías obtener un resultado similar a este:
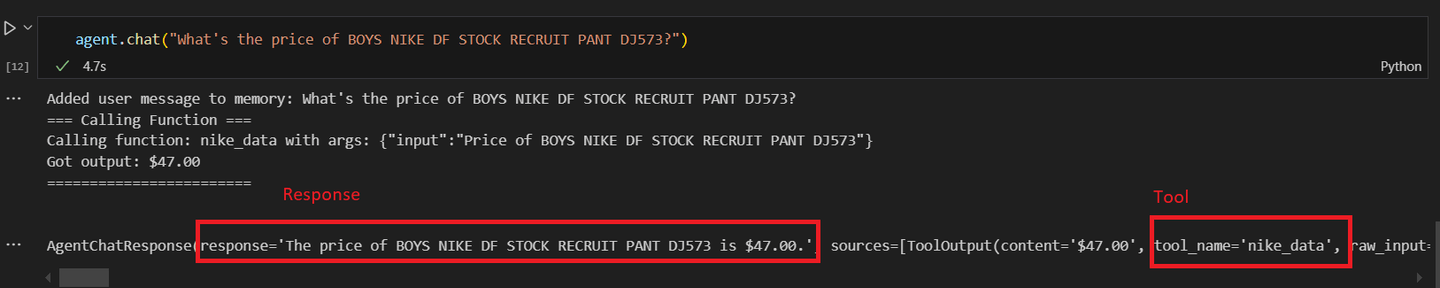
Ahora, llamemos al primer agente personalizado con la operación matemática.
# Llama al segundo agente
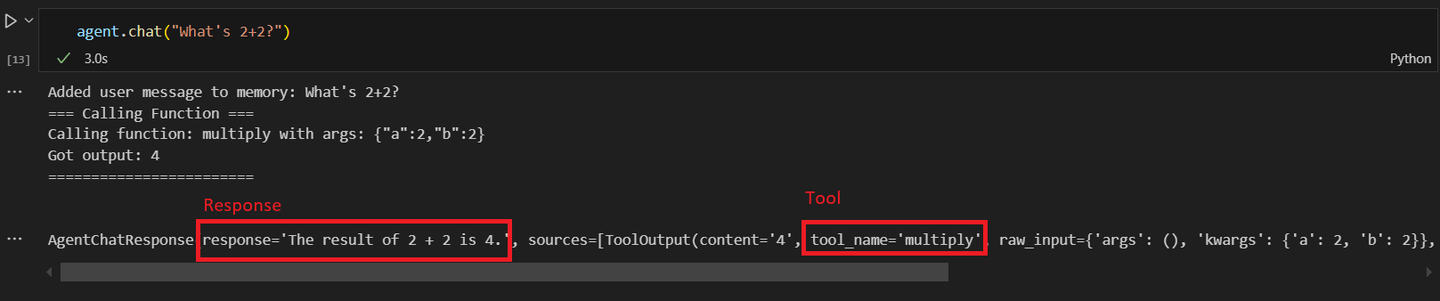
response = agent1.chat("¿Cuánto es 2+2?")
Al llamar al segundo agente y preguntar por una operación matemática. Obtendrás una respuesta similar a esta:
El potencial de los agentes de IA para manejar tareas complejas de manera autónoma está en expansión, lo que los hace invaluables en entornos empresariales donde pueden gestionar tareas rutinarias y liberar a los trabajadores humanos para actividades de mayor valor. A medida que avanzamos, se espera que la adopción de agentes de IA crezca, revolucionando aún más cómo interactuamos con la tecnología y optimizamos nuestros flujos de trabajo.
# Conclusión
Los agentes de LlamaIndex ofrecen una forma inteligente de gestionar y procesar datos, y van más allá de los sistemas RAG tradicionales. A diferencia de las tuberías de datos estáticas, estos agentes toman decisiones en tiempo real, ajustando sus acciones en función de los datos entrantes. Este razonamiento automatizado los hace altamente adaptables y eficientes para tareas complejas. Integran varias herramientas, desde funciones básicas hasta motores de consulta avanzados, para procesar inteligentemente las entradas y ofrecer resultados optimizados.
MyScaleDB es una base de datos vectorial de primer nivel, especialmente adecuada para aplicaciones de IA a gran escala. Su algoritmo MSTG (opens new window) supera a otros en escalabilidad y eficiencia, lo que la hace ideal para entornos de alta demanda. Diseñada para manejar conjuntos de datos grandes y consultas complejas de manera rápida, MyScaleDB garantiza una recuperación de datos rápida y precisa. Esto la convierte en una herramienta esencial para crear aplicaciones de IA robustas y escalables, ofreciendo una integración perfecta y un rendimiento superior en comparación con otras bases de datos vectoriales.
Si estás interesado en discutir más sobre la construcción de agentes de IA con MyScaleDB, síguenos en Twitter (opens new window) o únete a nuestra comunidad de Discord (opens new window). ¡Construyamos juntos el futuro de los datos y la IA!



