
En el siempre cambiante panorama de la inteligencia artificial, la búsqueda de chatbots más inteligentes, receptivos y conscientes del contexto nos ha llevado a la puerta de una nueva era. Bienvenido al mundo de RAG (Retrieval-Augmented Generation, Generación Mejorada por Recuperación) (opens new window), un enfoque innovador que combina el vasto conocimiento de los sistemas de recuperación con la destreza creativa de los modelos generativos. La tecnología RAG permite a los chatbots manejar cualquier tipo de consulta de usuario de manera efectiva accediendo a una base de conocimientos. Pero para aprovechar este poder de manera efectiva, necesitamos una solución de almacenamiento que pueda igualar su velocidad y eficiencia. Aquí es donde las bases de datos vectoriales brillan, ofreciendo un salto cuántico en la forma en que gestionamos y recuperamos grandes cantidades de datos.
En este blog, te mostraremos cómo construir un chatbot impulsado por RAG utilizando los modelos de Google Gemini y MyScaleDB (opens new window) en cuestión de minutos.
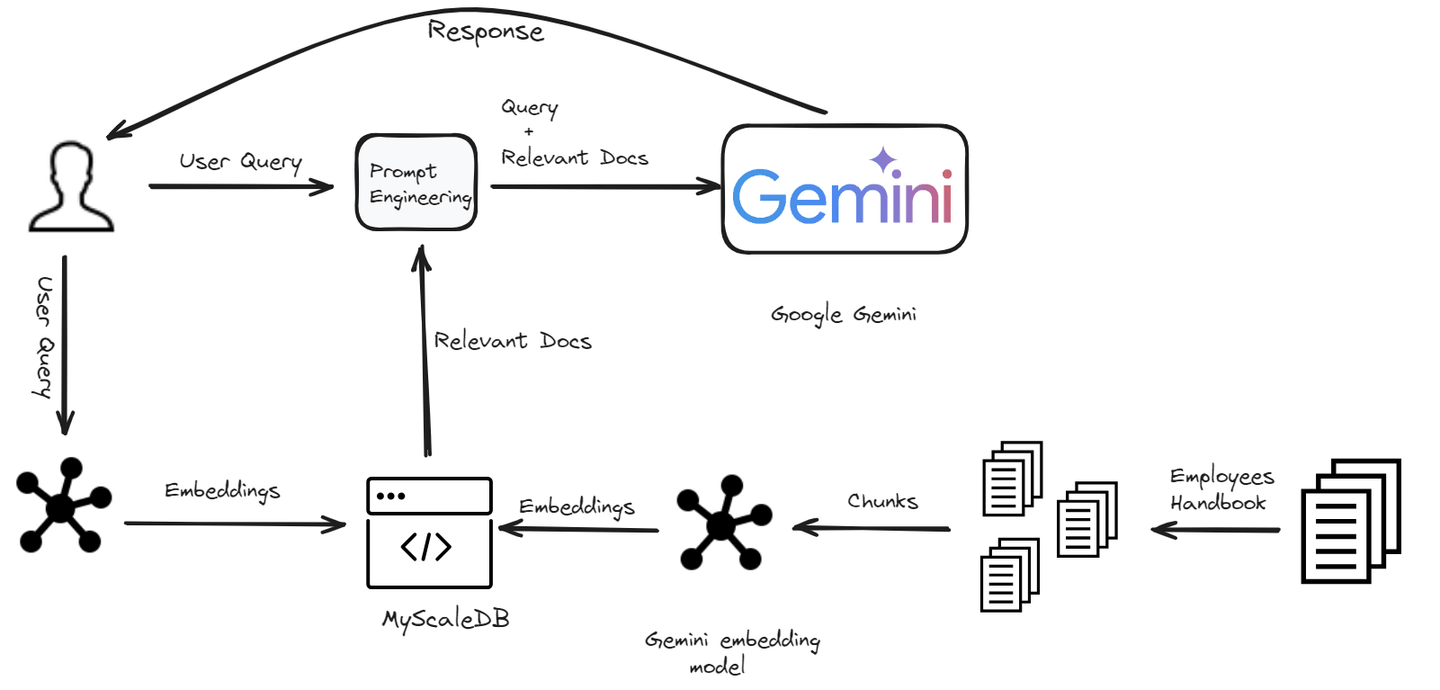
# Configuración del entorno
# Instalación del software necesario
Para comenzar nuestro viaje de desarrollo de chatbots, debemos asegurarnos de que las dependencias necesarias estén instaladas. Aquí tienes un desglose de las herramientas requeridas:
Python (opens new window): Utilizaremos Python como lenguaje de programación para construir este chatbot.
API de Gemini (opens new window): Utilizaremos la API de Gemini para acceder a Gemini LLM y utilizarlo en nuestro chatbot.
LangChain (opens new window): Es un marco de trabajo que permite a los desarrolladores integrar modelos de lenguaje grandes y bases de datos vectoriales para construir aplicaciones RAG escalables.
MyScaleDB (opens new window): Es una base de datos vectorial SQL especialmente diseñada para construir aplicaciones de IA.
# Instalación de Python
Si Python ya está instalado en tu sistema, puedes omitir este paso. De lo contrario, sigue los pasos a continuación.
Descargar Python: Ve al sitio web oficial de Python (opens new window) y descarga la última versión.
Instalar Python: Ejecuta el instalador descargado y sigue las instrucciones en pantalla. Asegúrate de marcar la casilla para agregar Python a la ruta del sistema.
# Instalación de Gemini, LangChain y MyScaleDB
Para instalar todas estas dependencias, ingresa el siguiente comando en tu terminal:
pip install gemini-api langchain clickhouse-client
El comando anterior debería instalar todos los paquetes necesarios para desarrollar un chatbot. Ahora, comencemos el proceso de desarrollo.
# Construcción del chatbot
Estamos construyendo un chatbot diseñado específicamente para los empleados de una empresa. Este chatbot ayudará a los empleados con cualquier pregunta relacionada con las políticas de la empresa. Desde comprender el código de vestimenta hasta aclarar las políticas de licencia, el chatbot proporcionará respuestas rápidas y precisas.
# Carga y división de documentos
El primer paso es cargar los datos y dividirlos utilizando el módulo PyPDFLoader de LangChain.
from langchain_community.document_loaders import PyPDFLoader
loader = PyPDFLoader("Employee_Handbook.pdf")
pages = loader.load_and_split()
pages = pages[4:] # Omitir las primeras páginas ya que no son necesarias
text = "\n".join([doc.page_content for doc in pages])
Cargamos el documento y lo dividimos en páginas, omitiendo las primeras páginas. Luego, concatenamos el texto de todas las páginas en una sola cadena.
Nota:
Estamos utilizando este manual de un repositorio de Kaggle (opens new window)
A continuación, dividimos este texto en fragmentos más pequeños para facilitar su manejo en el chatbot.
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=150,
length_function=len,
is_separator_regex=False,
)
docs = text_splitter.create_documents([text])
for i, d in enumerate(docs):
d.metadata = {"doc_id": i}
Aquí, utilizamos RecursiveCharacterTextSplitter para dividir el texto en fragmentos de 500 caracteres cada uno, con una superposición de 150 caracteres para garantizar la continuidad.
# Generación de embeddings
Para que nuestro chatbot sea capaz de comprender y recuperar información relevante, necesitamos generar embeddings para cada fragmento de texto. Estos embeddings son representaciones numéricas del texto que capturan los significados semánticos del mismo.
import os
import google.generativeai as genai
import pandas as pd
os.environ["GEMINI_API_KEY"] = "tu_clave_aquí"
# Esta función toma una oración como argumento y devuelve sus embeddings
def get_embeddings(text):
# Definir el modelo de embedding
model = 'models/embedding-001'
# Obtener los embeddings
embedding = genai.embed_content(model=model,
content=text,
task_type="retrieval_document")
return embedding['embedding']
# Obtener el contenido de la página de los documentos y crear una nueva lista
content_list = [doc.page_content for doc in docs]
# Enviar un contenido de página a la vez
embeddings = [get_embeddings(content) for content in content_list]
# Crear un dataframe para ingresarlo a la base de datos
dataframe = pd.DataFrame({
'page_content': content_list,
'embeddings': embeddings
})
Definimos una función get_embeddings que utiliza Google Gemini para generar embeddings para cada fragmento de texto. Estos embeddings se almacenan en un DataFrame para su posterior procesamiento.
Nota:
Estamos utilizando el modelo embedding-001 de los modelos de Gemini y puedes obtener la API de Gemini aquí (opens new window).
# Almacenamiento de datos en MyScaleDB
Con nuestros fragmentos de texto y sus embeddings correspondientes listos, el siguiente paso es almacenar estos datos en MyScaleDB. Esto nos permitirá realizar operaciones de recuperación eficientes más adelante. Primero, creemos una conexión con MyScaleDB.
import clickhouse_connect
client = clickhouse_connect.get_client(
host='tu_nombre_de_host',
port='número_de_puerto',
username='tu_nombre_de_usuario',
password='tu_contraseña'
)
Para obtener las credenciales de tu cuenta de MyScaleDB, sigue la guía de inicio rápido (opens new window).
# Crear una tabla e insertar los datos
Después de crear una conexión con la base de datos, el siguiente paso es crear una tabla (porque MyScaleDB es una base de datos vectorial SQL) e insertar los datos en ella.
# Crear una tabla con el nombre 'handbook'
client.command("""
CREATE TABLE default.handbook (
id Int64,
page_content String,
embeddings Array(Float32),
CONSTRAINT check_data_length CHECK length(embeddings) = 768
) ENGINE = MergeTree()
ORDER BY id
""")
# La CONSTRAINT asegurará que la longitud de cada vector de embedding sea de 768
# Insertar los datos en lotes
batch_size = 10
num_batches = len(dataframe) // batch_size
for i in range(num_batches):
start_idx = i * batch_size
end_idx = start_idx + batch_size
batch_data = dataframe[start_idx:end_idx]
# Insertar los datos
client.insert("default.handbook", batch_data.to_records(index=False).tolist(), column_names=batch_data.columns.tolist())
print(f"Lote {i+1}/{num_batches} insertado.")
# Crear un índice vectorial para una rápida recuperación de datos
client.command("""
ALTER TABLE default.handbook
ADD VECTOR INDEX vector_index embeddings
TYPE MSTG
""")
Los datos se insertan en lotes para mayor eficiencia, y se agrega un índice vectorial para permitir búsquedas rápidas de similitud.
# Recuperación de documentos relevantes
Una vez que los datos están almacenados, el siguiente paso es recuperar los documentos más relevantes para una consulta de usuario dada utilizando los embeddings.
def get_relevant_docs(user_query):
# Llamar nuevamente a la función get_embeddings para convertir la consulta del usuario en embeddings vectoriales
query_embeddings = get_embeddings(user_query)
# Realizar la consulta
results = client.query(f"""
SELECT page_content,
distance(embeddings, {query_embeddings}) as dist FROM default.handbook ORDER BY dist LIMIT 3
""")
relevant_docs = []
for row in results.named_results():
relevant_docs.append(row['page_content'])
return relevant_docs
Esta función primero genera embeddings para la consulta del usuario y luego recupera los 3 fragmentos de texto más relevantes de la base de datos en función de la similitud de sus embeddings.
# Generación de una respuesta
Finalmente, utilizamos los documentos recuperados para generar una respuesta a la consulta del usuario.
def make_rag_prompt(query, relevant_passage):
relevant_passage = ' '.join(relevant_passage)
prompt = (
f"Eres un chatbot útil e informativo que responde preguntas utilizando texto del fragmento de referencia incluido a continuación. "
f"Responde en una oración completa y asegúrate de que tu respuesta sea fácil de entender para todos. "
f"Mantén un tono amigable y conversacional. Si el fragmento es irrelevante, siéntete libre de ignorarlo.\n\n"
f"PREGUNTA: '{query}'\n"
f"FRAGMENTO: '{relevant_passage}'\n\n"
f"RESPUESTA:"
)
return prompt
import google.generativeai as genai
def generate_response(user_prompt):
model = genai.GenerativeModel('gemini-pro')
answer = model.generate_content(user_prompt)
return answer.text
def generate_answer(query):
relevant_text = get_relevant_docs(query)
text = " ".join(relevant_text)
prompt = make_rag_prompt(query, relevant_passage=relevant_text)
answer = generate_response(prompt)
return answer
answer = generate_answer(query="¿Cuál es el código de vestimenta laboral?")
print(answer)
La función make_rag_prompt crea un texto de inicio para el chatbot utilizando los documentos relevantes. La función generate_response utiliza Google Gemini para generar una respuesta basada en el texto de inicio y la función generate_answer une todo, recuperando los documentos relevantes y generando una respuesta a la consulta del usuario.
Nota: En este blog, estamos utilizando Gemini Pro 1.0 (opens new window) porque permite más solicitudes por minuto en la capa gratuita. Aunque Gemini ofrece modelos avanzados como Gemini 1.5 Pro (opens new window) y Gemini 1.5 Flash (opens new window), estos modelos tienen capas gratuitas más restrictivas y costos más altos para un uso extensivo.
Algunas de las salidas del chatbot se ven así:

Cuando se le preguntó al chatbot sobre la hora del almuerzo en la oficina:

Al integrar estos pasos en tu proceso de desarrollo de chatbots, puedes aprovechar el poder de Google Gemini y MyScaleDB para construir un chatbot sofisticado impulsado por IA. La experimentación es clave; ajusta tu chatbot para mejorar continuamente su rendimiento. Mantente curioso, mantente innovador y observa cómo tu chatbot se convierte en una maravilla conversacional.

# Conclusión
La llegada de RAG ha revolucionado el proceso de desarrollo de chatbots al integrar modelos de lenguaje grandes como Gemini o GPT. Estos LLM avanzados mejoran el rendimiento del chatbot al recuperar información relevante de una base de datos vectorial, generando respuestas más precisas, correctas desde el punto de vista factual y contextualmente apropiadas. Este cambio no solo reduce el tiempo y los costos de desarrollo, sino que también mejora significativamente la experiencia del usuario con chatbots más inteligentes y receptivos.
El rendimiento de un modelo RAG depende en gran medida de la eficiencia de su base de datos vectorial. La capacidad de una base de datos vectorial para recuperar rápidamente documentos relevantes es crucial para proporcionar respuestas rápidas a los usuarios. Al escalar un sistema RAG, mantener este alto nivel de rendimiento se vuelve aún más crítico. MyScaleDB es una excelente opción para este propósito debido a su alta escalabilidad heredada de ClickHouse y sus respuestas de consulta ultrarrápidas con una latencia mínima. No puedes perderte que también ofrece a los nuevos usuarios 5 millones de almacenamiento vectorial gratuito, que se puede utilizar fácilmente para desarrollar una aplicación a pequeña escala.
Si deseas discutir más con nosotros, te invitamos a unirte a Discord de MyScale (opens new window) para compartir tus ideas y comentarios.



