
La generación con recuperación aumentada (RAG) (opens new window) se utiliza a menudo para desarrollar aplicaciones de IA personalizadas, como chatbots (opens new window), sistemas de recomendación y otras herramientas personalizadas. Este sistema utiliza las fortalezas de las bases de datos vectoriales y los modelos de lenguaje de gran tamaño (LLMs) para proporcionar resultados de alta calidad.
Seleccionar el LLM adecuado para cualquier modelo RAG es muy importante y requiere tener en cuenta factores como el costo, las preocupaciones de privacidad y la escalabilidad. Los LLM comerciales como GPT-4 de OpenAI (opens new window) y Gemini de Google (opens new window) son efectivos pero pueden ser costosos y plantear preocupaciones de privacidad de datos. Algunos usuarios prefieren los LLM de código abierto por su flexibilidad y ahorro de costos, pero requieren recursos sustanciales para el ajuste fino (opens new window) y la implementación, incluyendo GPUs e infraestructura especializada. Además, gestionar las actualizaciones del modelo y la escalabilidad puede ser un desafío con configuraciones locales.
Una mejor solución es seleccionar un LLM de código abierto y desplegarlo en la nube. Este enfoque proporciona la potencia informática y la escalabilidad necesarias sin los altos costos y las complejidades del alojamiento local. No solo ahorra en costos infraestructurales iniciales, sino que también minimiza las preocupaciones de mantenimiento.
Vamos a explorar un enfoque similar para desarrollar una aplicación utilizando LLMs de código abierto alojados en la nube y una base de datos vectorial escalable.
# Herramientas y tecnologías
Se requieren varias herramientas para desarrollar esta aplicación de IA basada en RAG. Estas incluyen:
- BentoML (opens new window): BentoML es una plataforma de código abierto que simplifica la implementación de modelos de aprendizaje automático en APIs listas para producción, garantizando la escalabilidad y facilidad de gestión.
- LangChain (opens new window): LangChain es un marco para construir aplicaciones utilizando LLMs. Ofrece componentes modulares para una fácil integración y personalización.
- MyScaleDB (opens new window): MyScaleDB es una base de datos escalable y de alto rendimiento optimizada para la recuperación y almacenamiento eficientes de datos, con capacidades avanzadas de consulta.
En este tutorial, extraeremos datos de Wikipedia utilizando el módulo WikipediaLoader de LangChain y construiremos un LLM basado en esos datos.
Nota:
Puedes encontrar el notebook completo de Python (opens new window) en el repositorio de ejemplos de MyScale.
# Preparación
# Configurar el entorno
Comienza configurando tu entorno para usar BentoML, MyScaleDB y LangChain en tu sistema abriendo tu terminal e ingresando:
pip install bentoml langchain clickhouse-connect
Esto instalará los tres paquetes en tu sistema. Después de esto, estarás listo para escribir código y desarrollar la aplicación RAG.
# Cargar los datos
Comienza importando el WikipediaLoader (opens new window) del módulo langchain_community.document_loaders.wikipedia. Utilizarás este cargador para obtener documentos relacionados con "Albert Einstein" de Wikipedia (opens new window).
from langchain_community.document_loaders.wikipedia import WikipediaLoader
loader = WikipediaLoader(query="Albert Einstein")
# Cargar los documentos
docs = loader.load()
# Mostrar el contenido del primer documento
print(docs[0].page_content)
Esto utiliza el método load para recuperar los documentos de "Albert Einstein" y el método print para imprimir el contenido del primer documento y verificar los datos cargados.
# Dividir el texto en fragmentos
Importa el CharacterTextSplitter (opens new window) de langchain_text_splitters, une el contenido de todas las páginas en una sola cadena y luego divide el texto en fragmentos manejables.
from langchain_text_splitters import CharacterTextSplitter
# Dividir el texto en fragmentos
text = ' '.join([page.page_content.replace('\\t', ' ') for page in docs])
text_splitter = CharacterTextSplitter(
separator="\\n",
chunk_size=400,
chunk_overlap=100,
length_function=len,
is_separator_regex=False,
)
texts = text_splitter.create_documents([text])
splits = [item.page_content for item in texts]
El CharacterTextSplitter está configurado para dividir este texto en fragmentos de 400 caracteres con una superposición de 100 caracteres para asegurar que no se pierda información entre los fragmentos. El contenido de la página o texto se almacena en la matriz splits, que contiene solo el contenido de texto. Utilizarás la matriz splits para obtener los embeddings (opens new window).
# Desplegar los modelos en BentoML
Tus datos están listos y el siguiente paso es desplegar los modelos en BentoML y utilizarlos en tu aplicación RAG. Primero, necesitarás una cuenta gratuita de BentoML, y si es necesario, regístrate en BentoCloud (opens new window). A continuación, ve a la sección de despliegues y haz clic en el botón "Crear despliegue" en la esquina superior derecha. Se abrirá una nueva página que se ve así:
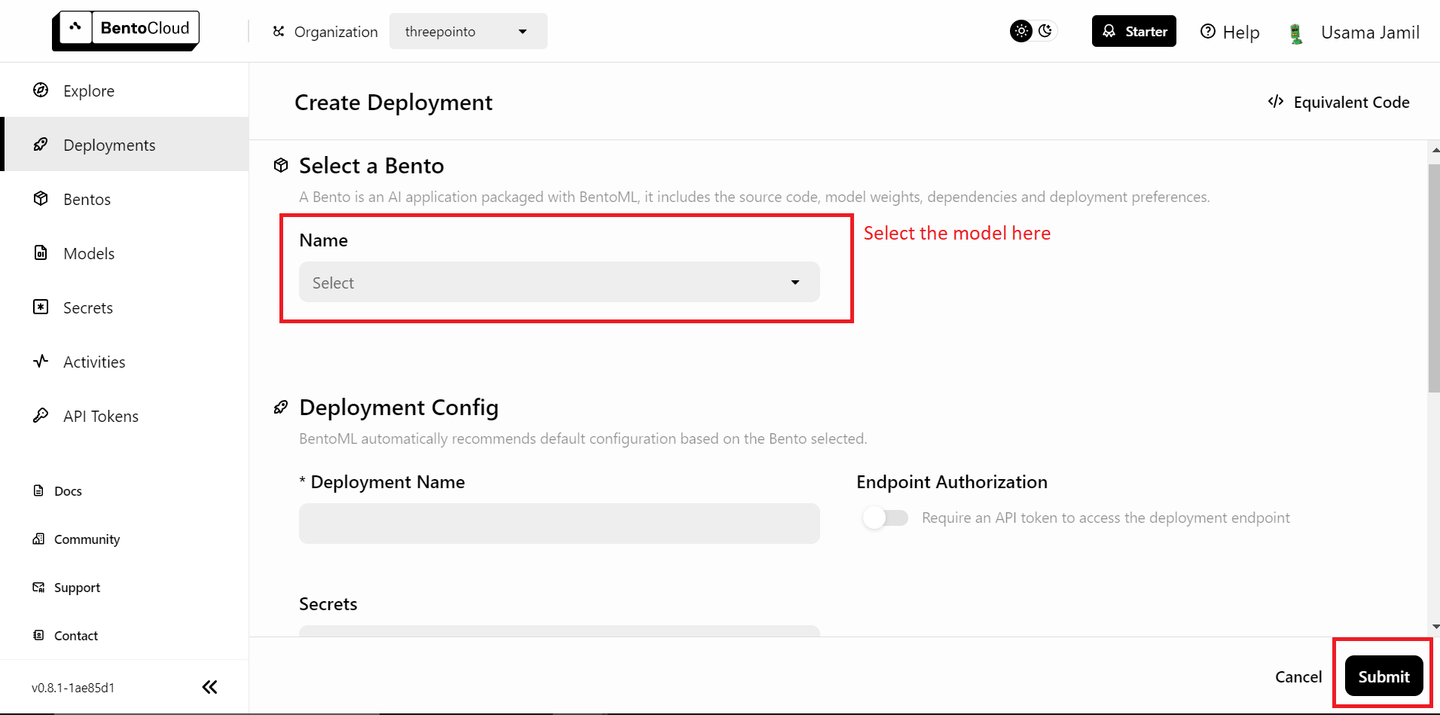
Selecciona el modelo "bentoml/bentovllm-llama3-8b-instruct-service (opens new window)" en el menú desplegable y haz clic en "Enviar" en la esquina inferior derecha. Esto comenzará a desplegar el modelo. Se abrirá una nueva página como esta:
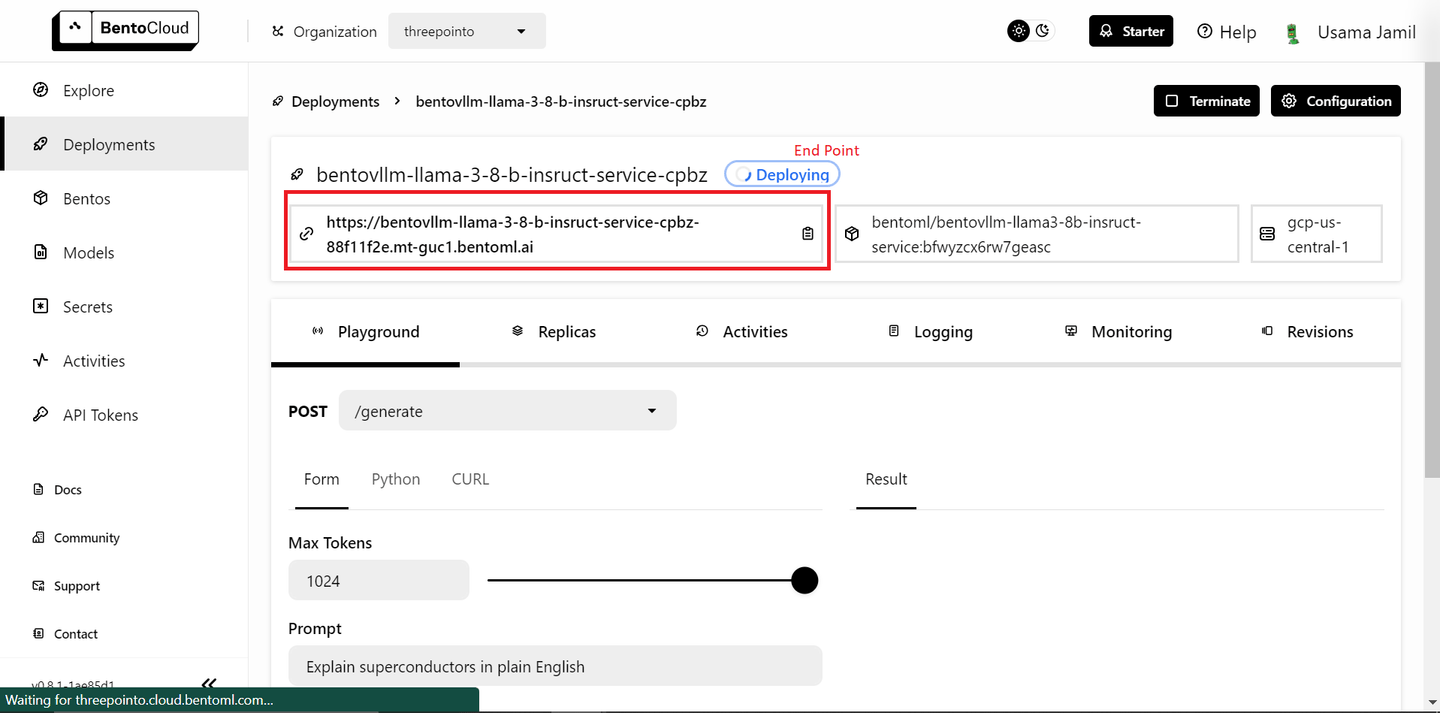
El despliegue puede llevar algún tiempo. Una vez desplegado, copia el punto final.
Nota:
La capa gratuita de BentoML solo permite el despliegue de un solo modelo. Si tienes un plan de pago y puedes desplegar más de un modelo, sigue los pasos a continuación. Si no, no te preocupes, utilizaremos un modelo de código abierto localmente para los embeddings.
Desplegar el modelo de embeddings es muy similar a los pasos que tomaste para desplegar el LLM:
- Ve a la página de Despliegues.
- Haz clic en el botón "Crear despliegue".
- Selecciona el modelo
sentence-transformersde la lista y haz clic en "Enviar". - Una vez que se complete el despliegue, copia el punto final.
A continuación, ve a la página de Tokens de API (opens new window) y genera una nueva clave de API. Ahora estás listo para utilizar los modelos desplegados en tu aplicación RAG.
# Definir el método de embeddings
Definirás una función llamada get_embeddings para generar embeddings para el texto proporcionado. Esta función toma tres argumentos. Si se proporciona el punto final de BentoML y el token de API, la función utiliza el servicio de embeddings de BentoML; de lo contrario, utiliza las bibliotecas locales transformers y torch para cargar el modelo sentence-transformers/all-MiniLM-L6-v2 y generar embeddings.
# Importar las bibliotecas
import subprocess
import sys
import numpy as np
# Instalar los paquetes si no se proporciona la clave de API
def install(package):
subprocess.check_call([sys.executable, "-m", "pip", "install", package])
# Definir el método de embeddings
def get_embeddings(texts: list, BENTO_EMBEDDING_MODEL_END_POINT=None, BENTO_API_TOKEN=None) -> list:
# Si se proporciona la CLAVE de BentoML, el método utilizará el modelo de BENTOML para obtener los embeddings
if BENTO_EMBEDDING_MODEL_END_POINT and BENTO_API_TOKEN:
import bentoml
embedding_client = bentoml.SyncHTTPClient(BENTO_EMBEDDING_MODEL_END_POINT, token=BENTO_API_TOKEN)
return embedding_client.encode(sentences=texts).tolist()
# De lo contrario, utilizará la biblioteca transformers
else:
# Instalar transformers y torch si aún no están instalados
try:
import transformers
except ImportError:
install("transformers")
try:
import torch
except ImportError:
install("torch")
from transformers import AutoTokenizer, AutoModel
# Inicializar el tokenizador y el modelo para los embeddings
tokenizer = AutoTokenizer.from_pretrained("sentence-transformers/all-MiniLM-L6-v2")
model = AutoModel.from_pretrained("sentence-transformers/all-MiniLM-L6-v2")
inputs = tokenizer(texts, padding=True, truncation=True, return_tensors="pt", max_length=512)
with torch.no_grad():
outputs = model(**inputs)
embeddings = outputs.last_hidden_state.mean(dim=1)
return embeddings.numpy().tolist()
Esta configuración permite la flexibilidad para los usuarios de BentoML en la capa gratuita, que solo pueden desplegar un modelo a la vez. Si tienes una versión de pago de BentoML y puedes desplegar dos modelos, puedes pasar el punto final de BentoML y el token de API de Bento para utilizar el modelo de embeddings desplegado.
# Obtener los embeddings
Itera sobre los fragmentos de texto (splits) en lotes de 25 para generar embeddings utilizando la función get_embeddings definida anteriormente.
all_embeddings = []
# Pasar los fragmentos en un lote de 25
for i in range(0, len(splits), 25):
batch = splits[i:i+25]
# Pasar el lote al método get_embeddings
embeddings_batch = get_embeddings(batch)
# Agregar los embeddings a la lista all_embeddings que contiene los embeddings de todo el conjunto de datos
all_embeddings.extend(embeddings_batch)
Esto evita sobrecargar el modelo de embeddings con demasiados datos a la vez, lo cual puede ser especialmente útil para gestionar la memoria y los recursos computacionales.
# Crear un DataFrame
Ahora, crea un DataFrame de pandas (opens new window) para almacenar los fragmentos de texto y sus embeddings correspondientes.
import pandas as pd
df = pd.DataFrame({
'page_content': splits,
'embeddings': all_embeddings
})
Este formato estructurado facilita la manipulación y el almacenamiento de los datos en MyScaleDB.
# Conectar a MyScaleDB
La base de conocimientos está completa y ahora es el momento de guardar los datos en la base de datos vectorial. En esta demostración, utilizaremos MyScaleDB para el almacenamiento de vectores. Inicia un clúster de MyScaleDB en un entorno en la nube siguiendo la guía de inicio rápido (opens new window). Luego, puedes establecer una conexión con la base de datos MyScaleDB utilizando la biblioteca clickhouse_connect.
import clickhouse_connect
client = clickhouse_connect.get_client(
host='tu-nombre-de-host',
port=443,
username='tu-nombre-de-usuario',
password='tu-contraseña'
)
El objeto client creado aquí se utilizará para ejecutar comandos SQL e interactuar con la base de datos.
# Crear una tabla e insertar datos
Crea una tabla en MyScaleDB para almacenar los fragmentos de texto y los embeddings. El esquema de la tabla incluye un id, el page_content y los embeddings.
# Crear la tabla llamada RAG
client.command("""
CREATE TABLE IF NOT EXISTS default.RAG (
id Int64,
page_content String,
embeddings Array(Float32),
CONSTRAINT check_data_length CHECK length(embeddings) = 384
) ENGINE = MergeTree()
ORDER BY id
""")
# Insertar datos en la tabla
batch_size = 100
num_batches = (len(df) + batch_size - 1) // batch_size
for i in range(num_batches):
batch_data = df[i * batch_size: (i + 1) * batch_size]
client.insert('default.RAG', batch_data.values.tolist(), column_names=batch_data.columns.tolist())
print(f"Lote {i+1}/{num_batches} insertado.")
Esto asegura que los embeddings tengan una longitud fija de 384. Los datos del DataFrame se insertan en la tabla en lotes para gestionar eficientemente grandes cantidades de datos.
# Crear un índice vectorial
El siguiente paso es agregar un índice vectorial a la columna embeddings en la tabla RAG. El índice vectorial permite búsquedas de similitud eficientes, que son esenciales para las tareas de generación con recuperación aumentada.
client.command("""
ALTER TABLE default.RAG
ADD VECTOR INDEX vector_index embeddings
TYPE MSTG
""")
# Recuperar vectores relevantes
Define una función para recuperar documentos relevantes basados en una consulta del usuario. Los embeddings de la consulta se generan utilizando la función get_embeddings, y se ejecuta una consulta SQL vectorial avanzada para encontrar las coincidencias más cercanas en la base de datos.
def get_relevant_docs(user_query, top_k):
query_embeddings = get_embeddings(user_query)[0]
results = client.query(f"""
SELECT page_content,
distance(embeddings, {query_embeddings}) as dist FROM default.RAG ORDER BY dist LIMIT {top_k}
""")
relevant_docs = " "
for row in results.named_results():
relevant_docs=relevant_docs + row["page_content"]
return relevant_docs
# Ejemplo de consulta
message="¿Quién es Albert Einstein?"
relevant_docs = get_relevant_docs(message, 8)
print(relevant_docs)
Los resultados se ordenan por distancia y se devuelven las mejores k coincidencias. Esta configuración encuentra los documentos más relevantes para una consulta dada.
Nota:
El método distance toma una columna de embeddings y el vector de embeddings de la consulta del usuario para encontrar documentos similares aplicando la similitud del coseno.
# Conectar al LLM de BentoML
Establece una conexión con tu LLM alojado en BentoML. El objeto llm_client se utilizará para interactuar con el LLM y generar respuestas basadas en los documentos recuperados.
import bentoml
BENTO_LLM_END_POINT = "agrega-tu-punto-final-aquí"
llm_client = bentoml.SyncHTTPClient(BENTO_LLM_END_POINT, token="tu-token-aquí")
Reemplaza BENTO_LLM_END_POINT y token con los valores que copiaste anteriormente durante el despliegue del LLM.
# Realizar RAG
Define una función para realizar RAG. La función toma una pregunta del usuario y el contexto recuperado como entrada. Construye una indicación para el LLM, indicándole que responda la pregunta basándose en el contexto proporcionado. Luego, devuelve la respuesta del LLM como respuesta.
def dorag(question: str, context: str):
# Define la plantilla de la indicación
prompt = (f"Eres un asistente útil. El usuario tiene una pregunta. Responde la pregunta del usuario basándote solo en el contexto: {context}. \\n"
f"La pregunta del usuario es {question}")
# Llama al punto final del LLM con la indicación definida anteriormente
results = llm_client.generate(
max_tokens=1024,
prompt=prompt,
)
res = ""
for result in results:
res += result
return res

# Realizar una consulta
Finalmente, puedes probarlo haciendo una consulta a la aplicación RAG. Haz la pregunta "¿Quién es Albert Einstein?" y utiliza la función dorag para obtener la respuesta basada en los documentos relevantes recuperados anteriormente.
query = "¿Quién es Albert Einstein?"
dorag(question=query, context=relevant_docs)
La salida proporciona una respuesta detallada a la pregunta, demostrando la efectividad de la configuración de RAG.

Si le preguntas al modelo RAG sobre la muerte de Albert Einstein, la respuesta debería verse así:

# Conclusión
BentoML se destaca como una excelente plataforma para implementar modelos de aprendizaje automático, incluidos los LLMs, sin la molestia de gestionar recursos. Con BentoML, puedes implementar y escalar rápidamente tus aplicaciones de IA en la nube, asegurándote de que estén listas para producción y altamente accesibles. Su simplicidad y flexibilidad lo convierten en una opción ideal para los desarrolladores, lo que les permite centrarse más en la innovación y menos en las complejidades de la implementación.
Por otro lado, MyScaleDB está desarrollado específicamente para aplicaciones RAG, ofreciendo una base de datos vectorial SQL de alto rendimiento. Su sintaxis SQL familiar facilita la integración y el uso de MyScaleDB en las aplicaciones, ya que la curva de aprendizaje es mínima. El algoritmo Multi-Scale Tree Graph (MSTG) (opens new window) de MyScaleDB supera significativamente a otras bases de datos vectoriales en términos de velocidad y precisión. Además, para los nuevos usuarios, MyScaleDB incluye acceso a 5 millones de vectores de 768D de almacenamiento, lo que lo convierte en una opción deseable para los desarrolladores que buscan implementar soluciones de IA eficientes y escalables.
¿Qué opinas sobre este proyecto? Comparte tus pensamientos en Twitter (opens new window) y Discord (opens new window).
Este artículo fue publicado originalmente en The New Stack. (opens new window)



