
Los modelos de lenguaje de gran tamaño (LLMs, por sus siglas en inglés) han aportado un valor inmenso con su capacidad para comprender y generar texto similar al humano. Sin embargo, estos modelos también presentan desafíos notables. Son entrenados en conjuntos de datos vastos que requieren un costo y tiempo extensos. El costo y tiempo extensos necesarios para entrenar estos modelos en grandes conjuntos de datos hacen que sea casi imposible volver a entrenarlos regularmente. Esta limitación significa que a menudo carecen de actualizaciones con los datos más recientes, lo que puede llevar a imprecisiones potenciales al consultar sobre temas desconocidos. Este fenómeno se conoce como "alucinación" y puede deteriorar el rendimiento de las aplicaciones y plantear preocupaciones sobre su confiabilidad y autenticidad.
Para superar la alucinación, se emplean varias técnicas, siendo la Generación con Recuperación Mejorada (RAG, por sus siglas en inglés) la más utilizada debido a su eficiencia y rendimiento.
Mostraré cómo diseñar un sistema RAG avanzado completo que se pueda utilizar en entornos de producción.
# ¿Qué es la Generación con Recuperación Mejorada?
RAG es la técnica más utilizada para superar la alucinación. Asegura que los LLMs se mantengan actualizados con la información más reciente y proporcionen mejores respuestas. Recupera de manera dinámica datos externos relevantes durante la fase de generación de respuestas del modelo. Este enfoque permite que los LLMs accedan a la información más actual sin necesidad de un entrenamiento frecuente. Esto hace que las respuestas del modelo sean más precisas y contextualmente apropiadas.
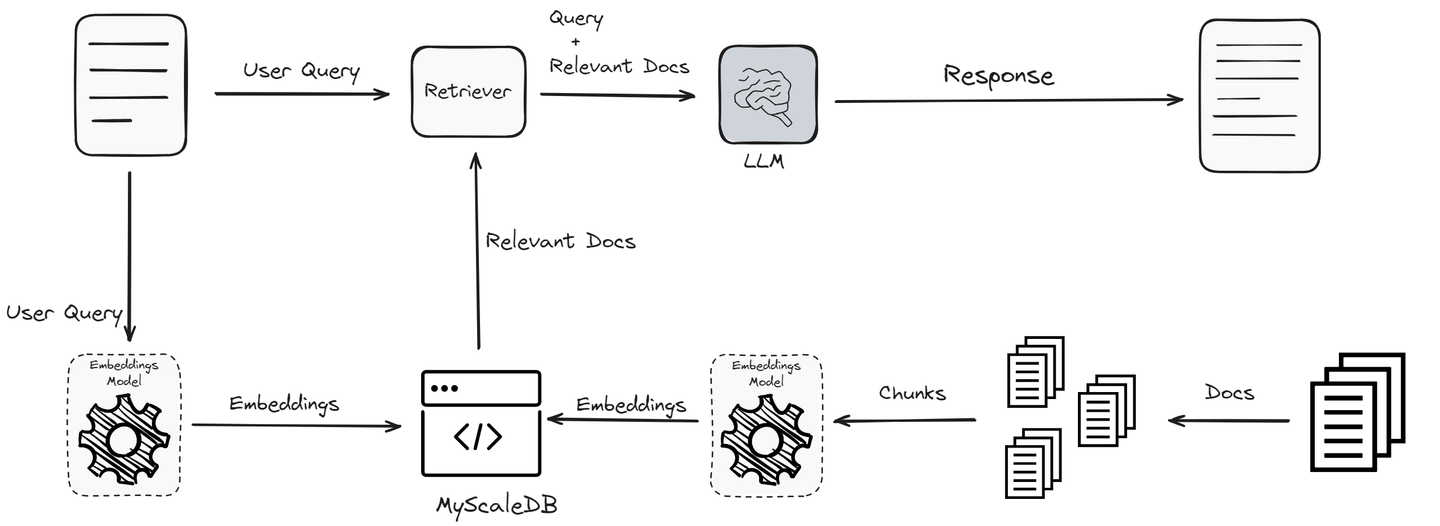
El proceso comienza con una consulta del usuario, que se transforma en incrustaciones a través de un modelo de incrustación para capturar su esencia semántica. Estas incrustaciones luego se someten a una búsqueda de similitud entre vectores en una base de conocimientos o base de datos vectorial para identificar la información más relevante. Los mejores "K" resultados de esta búsqueda se integran como contexto adicional en el LLM.
Al procesar tanto la consulta original como estos datos complementarios, el LLM está equipado para generar respuestas más precisas y contextualmente relevantes. Esto no solo mitiga el problema de la alucinación, sino que también asegura que las salidas del modelo se mantengan actualizadas y sean confiables sin necesidad de un entrenamiento frecuente.
Artículos relacionados: ¿Cómo funciona RAG? (opens new window)
# ¿Qué es LlamaIndex?
LlamaIndex (opens new window), anteriormente conocido como GPT Index, actúa como un pegamento que te ayuda a conectar LLMs y bases de conocimientos. Proporciona algunos métodos integrados para obtener datos de diferentes fuentes y utilizarlos en tus aplicaciones RAG. Esto incluye una variedad de formatos de archivo, como PDF y PowerPoint, así como aplicaciones como Notion y Slack e incluso bases de datos como Postgres y MyScaleDB.
LlamaIndex proporciona herramientas importantes que ayudan a recopilar, organizar, recuperar e integrar datos con varios marcos de aplicación. Facilita el acceso y uso de tus datos, lo que te permite construir aplicaciones y flujos de trabajo LLM potentes y personalizados.
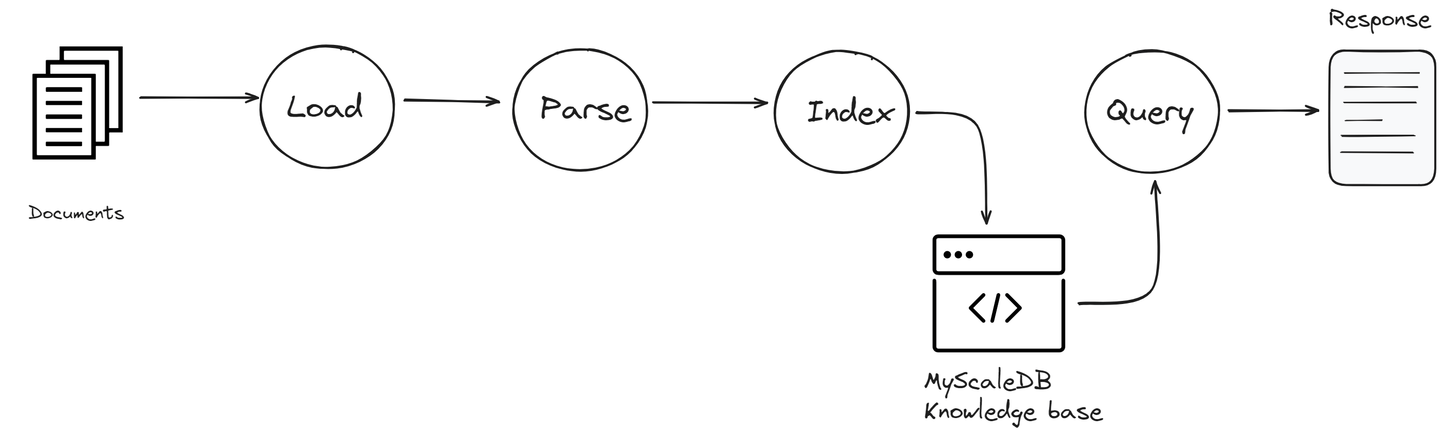
Algunos de los componentes principales de LlamaIndex incluyen:
- Conectores de datos: Estos permiten que LlamaIndex acceda a una variedad de fuentes de datos. Ya sea conectando a un sistema de archivos local, un servicio de almacenamiento en la nube o una base de datos, estos conectores facilitan la obtención de la información necesaria.
- Índice: El índice en LlamaIndex es un componente crucial que organiza los datos de manera que sea rápidamente accesible. Categoriza la información de todas las fuentes conectadas en un formato estructurado que es fácil de buscar. Esto ayuda a acelerar el proceso de recuperación y asegura que la información más relevante esté disponible para que el LLM la utilice cuando sea necesario.
- Motor de consulta: Este componente está diseñado para buscar eficientemente en las fuentes de datos conectadas. Procesa tus consultas, encuentra información relevante y la recupera para que el LLM la pueda utilizar para generar respuestas.
Cada componente de LlamaIndex desempeña un papel clave en mejorar las capacidades de las aplicaciones RAG al garantizar que puedan acceder y utilizar una amplia gama de datos de manera eficiente.
# Una visión general de MyScaleDB
MyScaleDB (opens new window) es una base de datos vectorial SQL de código abierto especialmente diseñada y optimizada para gestionar grandes volúmenes de datos para aplicaciones de IA. Está construida sobre ClickHouse (opens new window), una base de datos SQL, combinando la capacidad de búsqueda de similitud de vectores con el soporte completo de SQL.
A diferencia de las bases de datos vectoriales especializadas, MyScaleDB integra de manera transparente algoritmos de búsqueda de vectores con bases de datos estructuradas, lo que permite gestionar tanto vectores como datos estructurados en la misma base de datos. Esta integración ofrece ventajas como una comunicación simplificada, filtrado flexible de metadatos, soporte para consultas conjuntas SQL y vectoriales (opens new window), y compatibilidad con herramientas establecidas que se utilizan típicamente con bases de datos versátiles de propósito general.
La integración de MyScaleDB en aplicaciones RAG mejora estas aplicaciones al permitir interacciones de datos más complejas, lo que influye directamente en la calidad del contenido generado.
# RAG con LlamaIndex y MyScaleDB: una guía paso a paso
Para construir la aplicación RAG, primero necesitamos crear una cuenta (opens new window) en MyScaleDB que se utilizará como base de conocimientos. MyScaleDB ofrece a cada usuario nuevo almacenamiento gratuito para hasta 5 millones de vectores, por lo que no se requiere un pago inicial.
Una vez que hayas creado tu cuenta, ve a la página de inicio y haz clic en "+ Nuevo clúster" en la esquina superior derecha. Esto abrirá un cuadro de diálogo como este:
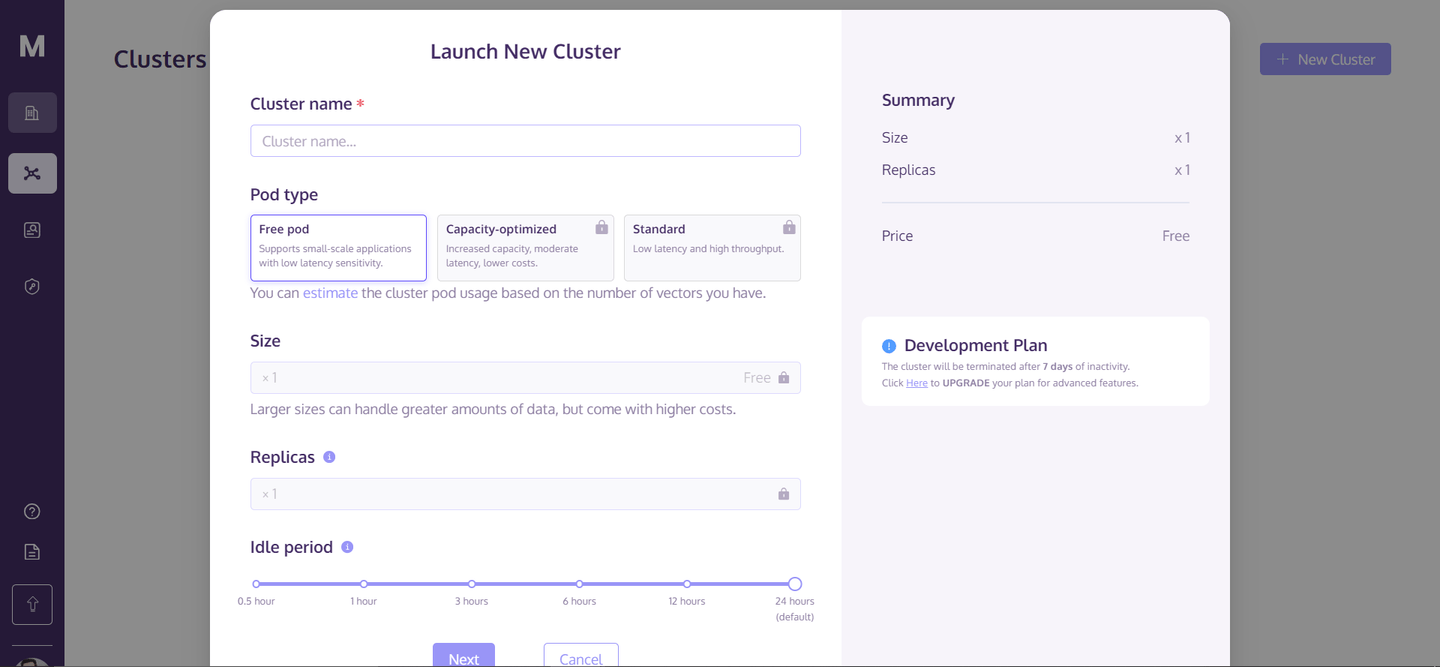
Ingresa el nombre del clúster y haz clic en "Siguiente". Tomará unos segundos inicializar tu clúster y después de eso, podrás acceder a él.
Para acceder al clúster, puedes volver a tu perfil de MyScaleDB y pasar el cursor sobre los tres puntos alineados verticalmente debajo del texto "Acciones" y hacer clic en los detalles de conexión.
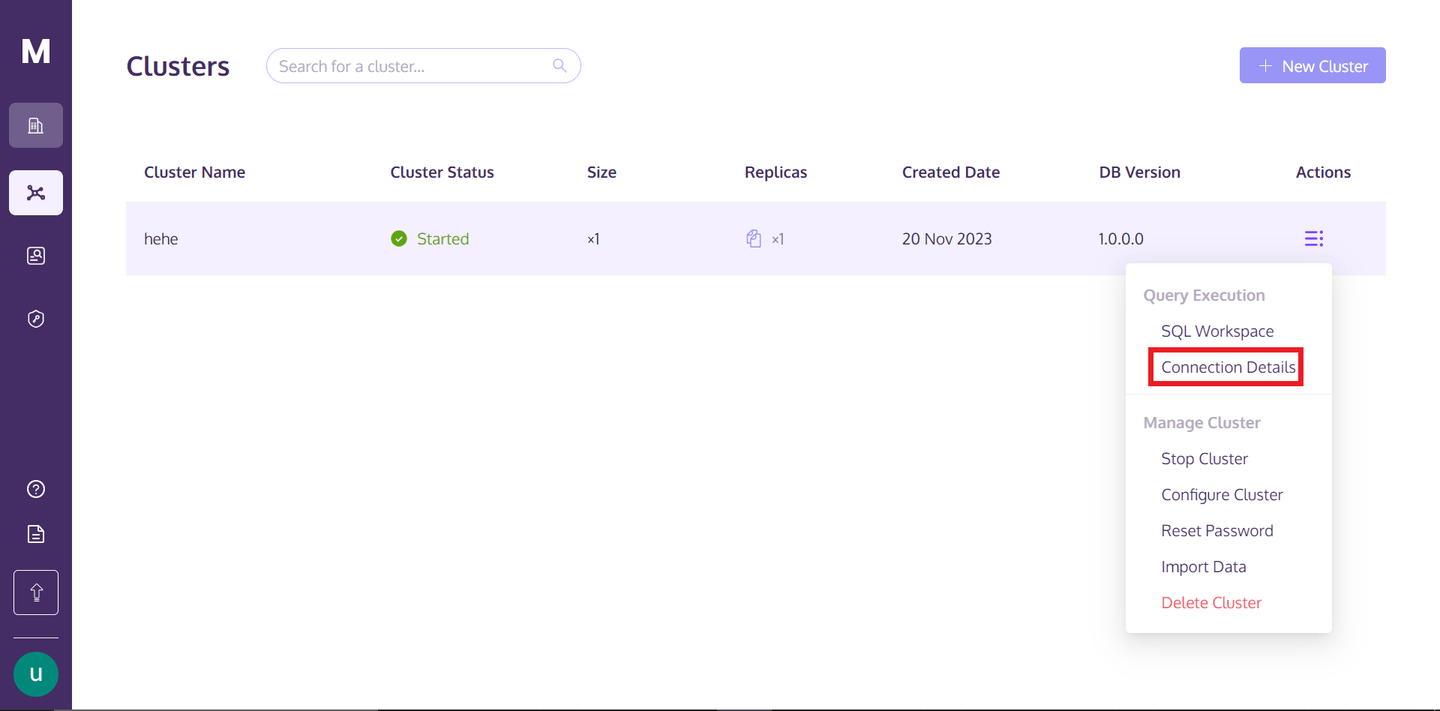
Una vez que hagas clic en "Detalles de conexión", verás el siguiente cuadro:
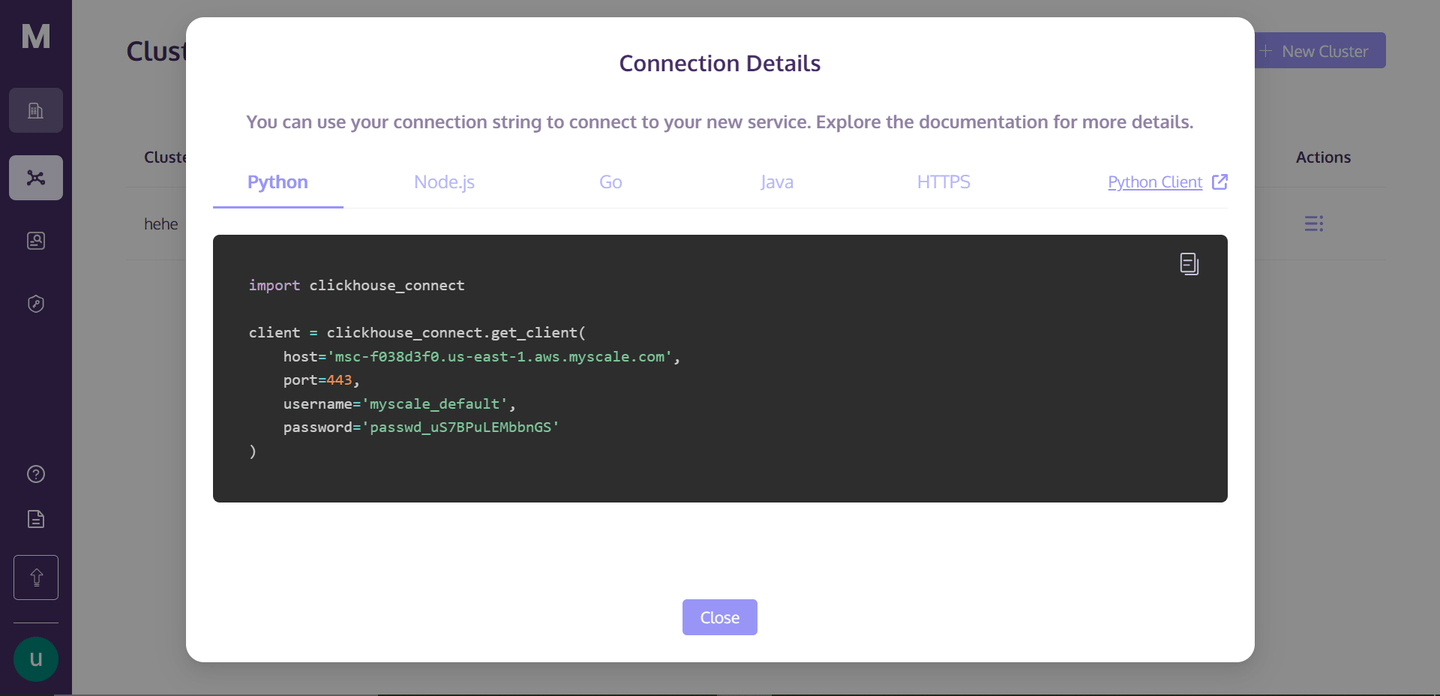
Estos son los detalles de conexión que necesitas para conectarte al clúster. Simplemente crea un archivo de cuaderno de Python en tu directorio y comenzaremos a construir nuestra aplicación RAG.

# Configuración del entorno
Para instalar las dependencias, abre tu terminal y ejecuta el siguiente comando:
pip install -U llama-index clickhouse-connect llama-index-postprocessor-jinaai-rerank llama-index-vector-stores-myscale
Este comando instalará todas las dependencias necesarias. Aquí utilizamos Jina Reranker (opens new window), cuyo algoritmo mejora significativamente los resultados de búsqueda, con un aumento de más del 8% en la tasa de aciertos y un aumento del 33% en el rango recíproco medio.
# Establecer una conexión con la base de conocimientos
Primero, necesitas establecer una conexión con MyScale vector DB. Para ello, puedes copiar los detalles de la página "Detalles de conexión" y pegarlos de la siguiente manera:
import clickhouse_connect
client = clickhouse_connect.get_client(
host='tu-host',
port=443,
username='tu-nombre-de-usuario',
password='tu-contraseña-aquí'
)
Esto establecerá una conexión con tu base de conocimientos y creará un objeto.
# Descargar y cargar datos
Aquí, utilizaremos un conjunto de datos de catálogo de productos de Nike. Este código primero descargará el archivo .pdf y lo guardará localmente. Luego, cargará el archivo .pdf utilizando el lector de LlamaIndex.
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
import requests
url = '<https://niketeam-asset-download.nike.net/catalogs/2024/2024_Nike%20Kids_02_09_24.pdf?cb=09302022>'
response = requests.get(url)
with open('Nike_Catalog.pdf', 'wb') as f:
f.write(response.content)
reader = SimpleDirectoryReader(
input_files=["Nike_Catalog.pdf"]
)
documents = reader.load_data()
# Categorizar los datos
Esta función categoriza los documentos en diferentes categorías. La utilizaremos al escribir algunas consultas filtradas en toda la base de conocimientos. Al categorizar los documentos, se pueden realizar búsquedas dirigidas, lo que mejora significativamente la eficiencia y relevancia de la recuperación en el sistema RAG.
def analizar_y_asignar_categoria(texto):
if "fútbol" in texto.lower():
return "Fútbol"
elif "baloncesto" in texto.lower():
return "Baloncesto"
elif "correr" in texto.lower():
return "Correr"
else:
return "Sin categorizar"
# Crear un índice
Aquí cargaremos los datos en un vector store proporcionado por MyScaleVectorStore. Primero se agrega la metadatos para cada documento y luego se agrega al vector store. La creación de un índice facilita las operaciones de búsqueda rápidas y eficientes. Al indexar los datos, el sistema puede realizar búsquedas rápidas basadas en vectores, que son esenciales para recuperar documentos relevantes según medidas de similitud en aplicaciones RAG.
from llama_index.vector_stores.myscale import MyScaleVectorStore
from llama_index.core import StorageContext
for documento in documentos:
categoria = analizar_y_asignar_categoria(documento.text)
documento.metadata = {"Categoría": categoria}
vector_store = MyScaleVectorStore(myscale_client=client)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
index = VectorStoreIndex.from_documents(
documentos, storage_context=storage_context
)
Nota: Al crear un índice con MyScaleDB, utiliza modelos de incrustación de OpenAI. Para habilitar esto, debes agregar tu clave de OpenAI como una variable de entorno.
# Consulta simple
Para ejecutar una consulta simple, necesitamos convertir nuestro índice existente en un motor de consulta. El motor de consulta es una herramienta especializada que puede manejar e interpretar consultas de búsqueda.
query_engine = index.as_query_engine()
response = query_engine.query("Quiero unos zapatos para correr")
print(response.source_nodes[0].text)
Utilizando el motor de consulta, ejecutamos una consulta para encontrar "Quiero unos zapatos para correr". El motor procesa esta consulta y luego busca en los documentos indexados las coincidencias que mejor satisfacen los términos de la consulta.
# Consulta filtrada
Aquí, el motor de consulta se configura con filtros de metadatos utilizando las clases MetadataFilters y ExactMatchFilter. Se aplica el ExactMatchFilter al campo de metadatos "Categoría" para incluir solo los documentos que están categorizados explícitamente como "Correr". Este filtro asegura que el motor de consulta solo considere documentos relacionados con correr, lo que puede llevar a resultados más relevantes y enfocados. La configuración similarity_top_k=2 limita la búsqueda a los dos documentos más similares, y vector_store_query_mode="hybrid sugiere una combinación de métodos de búsqueda vectorial y tradicional para obtener resultados óptimos.
from llama_index.core.vector_stores import ExactMatchFilter, MetadataFilters
query_engine = index.as_query_engine(
filters=MetadataFilters(
filters=[
ExactMatchFilter(key="Categoría", value="Correr"),
]
),
similarity_top_k=2,
vector_store_query_mode="hybrid",
)
response = query_engine.query("Quiero unos zapatos para correr?")
print(response.source_nodes[0].text)
Esta salida debería coincidir estrechamente con la consulta del usuario, mostrando cómo los filtros de metadatos pueden mejorar la precisión de los resultados de búsqueda.
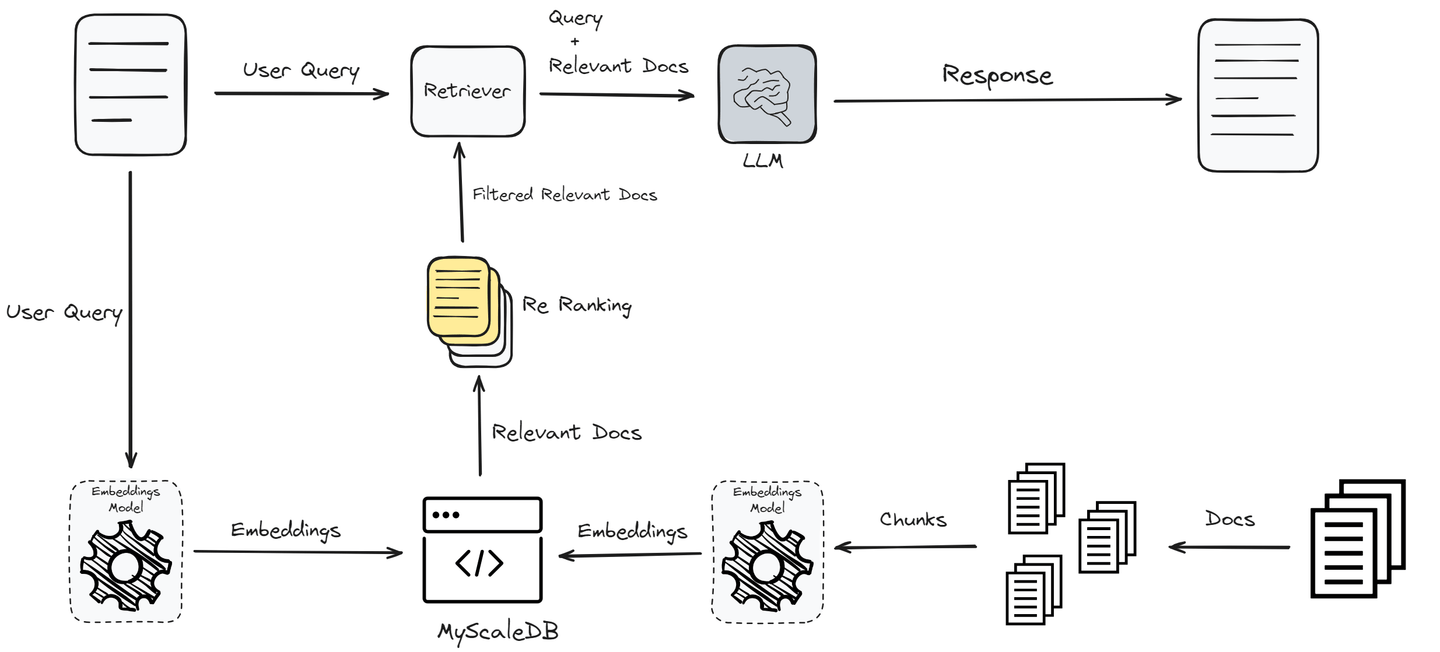
Hasta ahora, hemos implementado RAG en su forma más simple, que puede no ofrecer el mejor rendimiento. Para mejorar el rendimiento y proporcionar a los usuarios las respuestas exactas, ahora implementaremos un reordenador que filtrará aún más los documentos recuperados.
# Agregar un reordenador para mejorar la recuperación de documentos
Este código integra un mecanismo de reordenamiento utilizando Jina AI para refinar los documentos recuperados por la consulta inicial.
from llama_index.postprocessor.jinaai_rerank import JinaRerank
jina_rerank = JinaRerank(api_key="clave-de-api-aquí", top_n=2)
from llama_index.llms.openai import OpenAI
llm = OpenAI(model="gpt-4", temperature=0)
query_engine = index.as_query_engine(
similarity_top_k=10, llm=llm, node_postprocessors=[jina_rerank]
)
response = query_engine.query("Quiero unos zapatos para correr?")
print(response.source_nodes[0].text)
Nota: Puedes encontrar la clave de Jina Reranker aquí (opens new window). Haz clic en la API y desplázate hacia abajo en la página recién abierta; encontrarás la clave de la API justo debajo de la sección API de Reranker.
# Conclusión
RAG ayuda significativamente a que los LLMs se mantengan actualizados y garantiza que sus respuestas sean precisas y relevantes. Sin embargo, los sistemas RAG simples a menudo no se utilizan en aplicaciones listas para producción debido a su rendimiento. Para mejorar el rendimiento, utilizamos técnicas avanzadas como el reordenamiento, el preprocesamiento y las consultas filtradas.
La elección de la base de datos vectorial es otro factor que afecta el rendimiento de los sistemas RAG.
Es crucial seleccionar una base de datos vectorial adaptada a las necesidades de tu aplicación. MyScaleDB, al ser una base de datos vectorial SQL, es una buena opción para los desarrolladores debido a su interfaz SQL familiar, además de ser asequible, rápida y optimizada para aplicaciones a nivel de producción.
Si tienes alguna sugerencia, por favor contáctanos a través de Twitter (opens new window) o Discord (opens new window).



