
Retrieval-Augmented Generation (RAG) (opens new window) es una técnica que mejora la salida de los modelos de lenguaje grandes mediante la referencia a fuentes de conocimiento externas. Este enfoque garantiza respuestas más precisas y contextualmente relevantes sin necesidad de volver a entrenar el modelo. Es una forma rentable de mejorar el rendimiento de los modelos de lenguaje en diversos dominios.
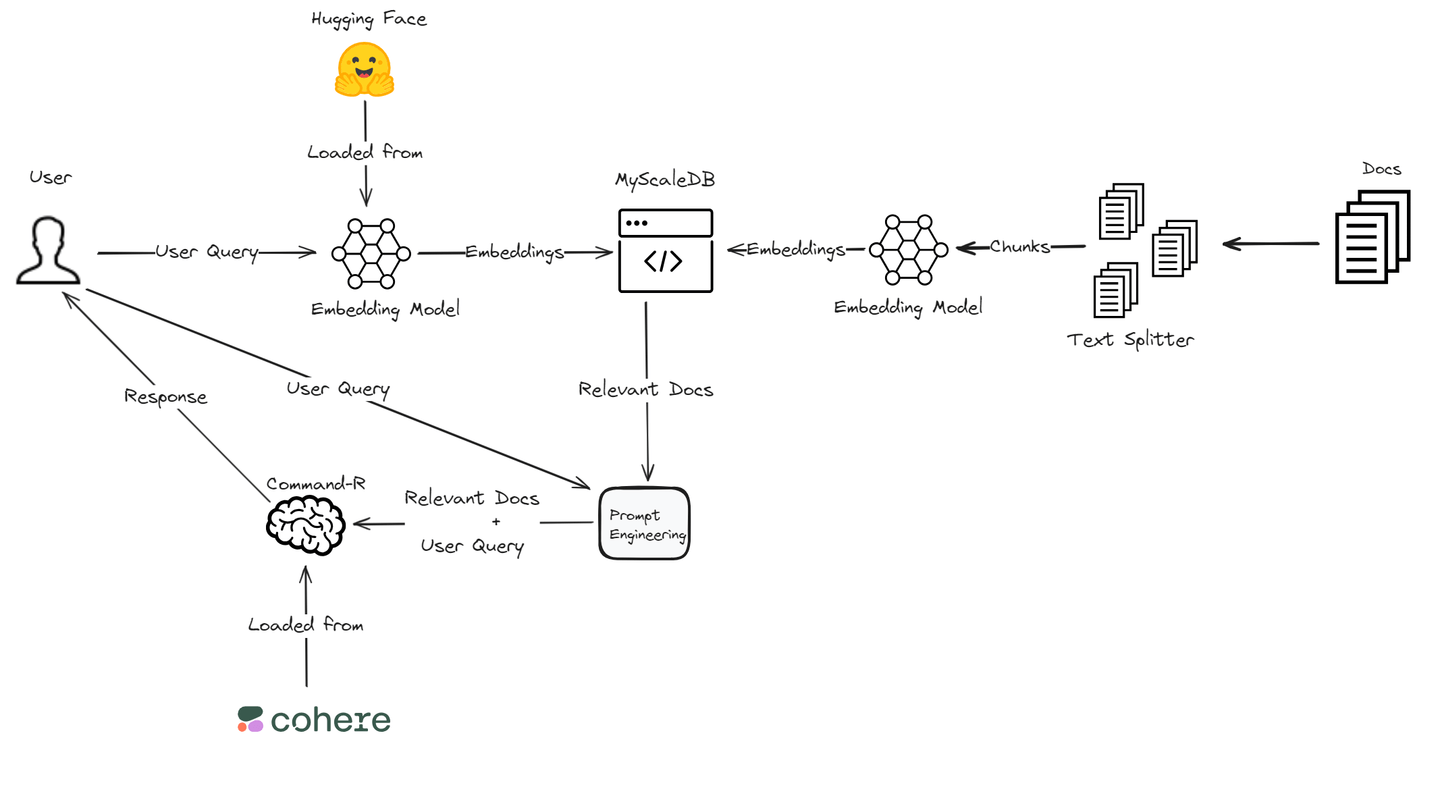
En este blog, construiremos una aplicación RAG utilizando el modelo Command R de Cohere (opens new window) debido a su rendimiento superior en RAG. Proporciona una alta precisión en la recuperación y generación de información relevante. Para las incrustaciones (opens new window) de vectores, confiaremos en la biblioteca Transformers de Hugging Face (opens new window), que ofrece un amplio soporte para diversas tareas de procesamiento del lenguaje natural (NLP) e integra bien con los marcos de aprendizaje profundo. Además, utilizaremos MyScaleDB, una base de datos de alto rendimiento y eficiente en costos, para almacenar las incrustaciones y fragmentos de texto. Esta combinación técnica garantiza un sistema RAG potente y eficiente, adaptado para satisfacer las necesidades específicas de nuestra aplicación.
# ¿Qué es Cohere?
Cohere (opens new window) es una plataforma especializada en el desarrollo de modelos de lenguaje avanzados para ayudar a las empresas a automatizar y mejorar las interacciones con los clientes. Ofrecen modelos de lenguaje grandes (LLMs) de última generación como Command, que admite aplicaciones como agentes conversacionales y resúmenes, y Rerank, que optimiza la relevancia de los resultados de búsqueda. Estas herramientas mejoran la eficiencia y precisión de la comunicación para las empresas.
Además de sus LLM principales, Cohere proporciona modelos como Embed para tareas como clasificación de texto y búsqueda semántica, y capacidades RAG para integrar y recuperar información de documentos y fuentes de datos empresariales. Estos modelos permiten a las empresas implementar soluciones de IA seguras y escalables, mejorando su eficiencia operativa y experiencia del cliente en general.
# ¿Qué es Hugging Face?
Hugging Face (opens new window) es una plataforma conocida por sus modelos de lenguaje avanzados, especializada en hacer que el aprendizaje automático de última generación sea accesible para una amplia audiencia. Su producto principal, la biblioteca Transformers, es de código abierto y admite tareas como generación de texto, resumen y traducción. Esta biblioteca es compatible con marcos populares de aprendizaje profundo como PyTorch y TensorFlow, lo que permite a los usuarios implementar fácilmente modelos de NLP de vanguardia como BERT y GPT-2.
Además de proporcionar herramientas de NLP potentes, Hugging Face ofrece diversas soluciones sin código y con bajo código para implementar modelos de IA generativos. Su plataforma incluye funciones como puntos finales de inferencia para facilitar la implementación de modelos y espacios para alojar aplicaciones de aprendizaje automático. Hugging Face también admite la colaboración a través de su Model Hub, donde los usuarios pueden compartir y acceder a miles de modelos, conjuntos de datos y aplicaciones. Este enfoque impulsado por la comunidad ayuda a democratizar el aprendizaje automático y fomentar la innovación en el campo de la IA.
# Componentes fundamentales de una aplicación RAG con Cohere y Hugging Face
Sumergámonos en los componentes esenciales para construir una sólida aplicación RAG utilizando Cohere y Hugging Face.
# Integración del modelo Command-R de Cohere
Cuando utilizas Cohere para tu aplicación RAG, una característica importante es el modelo Command-R. Este modelo mejora la generación con recuperación aumentada mediante la conexión con fuentes de datos externas para obtener información relevante, lo que aumenta la relevancia y precisión (opens new window) de las respuestas. Al utilizar esta función, tu aplicación puede proporcionar respuestas más perspicaces y contextualmente apropiadas.
# Acceso a modelos preentrenados con Hugging Face
Incorporar modelos preentrenados de Hugging Face en tu aplicación RAG proporciona una ventaja significativa en términos de eficiencia y precisión. Estos modelos están equipados con un amplio entrenamiento en diversos conjuntos de datos, lo que les permite generar respuestas de alta calidad en varios dominios. Al aprovechar estos modelos preentrenados, puedes acelerar el proceso de desarrollo manteniendo un alto estándar de calidad en la salida.
Nota:
Para utilizar modelos de Hugging Face en tu proyecto, primero crea una cuenta en Hugging Face y obtén el Token de Acceso (opens new window).
# Configuración de tu entorno
Para embarcarte en tu viaje de aplicación RAG, asegúrate de tener las herramientas y cuentas necesarias listas. Necesitarás acceso a plataformas como Cohere y Hugging Face, junto con cuentas en estas plataformas. Además, la instalación de bibliotecas esenciales como la API de Cohere y Transformers de Hugging Face será crucial para una integración sin problemas.
pip install cohere transformers clickhouse-connect
Utilizaremos MyScaleDB (opens new window) como la base de datos de vectores para esta aplicación RAG. MyScaleDB es una base de datos de vectores SQL que utiliza una sintaxis SQL familiar para recuperar eficientemente documentos relevantes para los LLM. Ofrece 5 millones de almacenamiento de vectores gratuito, lo que nos permite utilizar sus capacidades sin ningún costo.

# Creando tu aplicación RAG
Una vez que hayas sentado las bases de tu aplicación RAG con Cohere y Hugging Face, es hora de poner a prueba tu creación y mejorar su rendimiento para obtener resultados óptimos.
# Cargar los datos
Primero, necesitamos cargar los datos utilizando el TextLoader del módulo langchain.document_loaders. Utilizaremos el Corpus WikiQA de Microsoft (opens new window) para este tutorial.
from langchain.document_loaders import TextLoader
loader = TextLoader('wikiQA-dev.txt', encoding='utf-8')
documents = loader.load()
text = documents[0].page_content
# Dividir el texto
A continuación, dividimos el texto cargado en fragmentos utilizando el CharacterTextSplitter. Esto ayuda a gestionar documentos grandes dividiéndolos en piezas más pequeñas y manejables. La división del texto es necesaria para procesar documentos grandes de manera eficiente y permite un mejor manejo y recuperación de secciones específicas.
from langchain_text_splitters import CharacterTextSplitter
# Dividir el texto en fragmentos
text_splitter = CharacterTextSplitter(
separator="\n",
chunk_size=400,
chunk_overlap=100,
length_function=len,
is_separator_regex=False,
)
texts = text_splitter.create_documents([text])
# Cargar el modelo y el tokenizador preentrenados
Utilizamos el modelo sentence-transformers/all-MiniLM-L6-v2 de Hugging Face para generar incrustaciones de texto. Se cargan el tokenizador y el modelo, y se define una función para obtener las incrustaciones de texto. Las incrustaciones son representaciones numéricas del texto que capturan su significado semántico, lo cual es esencial para búsquedas y comparaciones de similitud.
from transformers import AutoTokenizer, AutoModel
import torch
# Cargar el tokenizador y el modelo preentrenados
tokenizer = AutoTokenizer.from_pretrained("sentence-transformers/all-MiniLM-L6-v2")
model = AutoModel.from_pretrained("sentence-transformers/all-MiniLM-L6-v2")
# Función para obtener las incrustaciones de texto
def get_text_embeddings(text):
inputs = tokenizer(text, return_tensors='pt', truncation=True, padding=True)
with torch.no_grad():
embeddings = model(inputs).last_hidden_state.mean(dim=1)
return embeddings.numpy().flatten()
# Generar incrustaciones para los fragmentos de texto
Para cada fragmento de texto, generamos incrustaciones y las almacenamos en un DataFrame junto con el texto original. Este paso nos ayuda a gestionar los datos de manera más efectiva, lo que facilita su almacenamiento.
import pandas as pd
# Generar incrustaciones para cada fragmento de texto
page_contents = []
embeddings_list = []
for segment in texts:
embeddings_list.append(get_text_embeddings(segment.page_content))
page_contents.append(segment.page_content)
df = pd.DataFrame({
'page_content': page_contents,
'embeddings': embeddings_list
})
# Conectar a MyScaleDB
Nos conectamos a la base de datos MyScaleDB (opens new window) para almacenar las incrustaciones y fragmentos de texto. Sigue los pasos para obtener las credenciales de tu clúster MyScaleDB (opens new window).
import clickhouse_connect
# Conectar a ClickHouse
client = clickhouse_connect.get_client(
host='tu_host',
port=443,
username='tu_nombre_de_usuario',
password='tu_contraseña'
)
# Crear y poblar la tabla de MyScaleDB
Creamos una tabla en MyScale para almacenar los fragmentos de texto e incrustaciones, luego insertamos los datos en la tabla. Este paso estructura los datos dentro de la base de datos, preparándolos para consultas y recuperación eficientes.
# Crear la tabla
client.command("""
CREATE TABLE IF NOT EXISTS default.QnA (
id Int64,
page_content String,
embeddings Array(Float32),
CONSTRAINT check_data_length CHECK length(embeddings) = 384
) ENGINE = MergeTree() ORDER BY id
""")
# Insertar datos en la tabla
batch_size = 100
num_batches = (len(df) + batch_size - 1) // batch_size
for i in range(num_batches):
batch_data = df[i * batch_size: (i + 1) * batch_size]
client.insert('default.QnA', batch_data.values.tolist(), column_names=batch_data.columns.tolist())
print(f"Lote {i+1}/{num_batches} insertado.")
# Agregar un índice de vectores a la tabla
Agregamos un índice de vectores a la tabla para facilitar búsquedas de similitud eficientes. El índice de vectores mejora el proceso de recuperación al permitir búsquedas rápidas de incrustaciones, lo cual es crucial para encontrar documentos similares en función de su contenido semántico.
# Agregar un índice de vectores a la tabla
client.command("""
ALTER TABLE default.QnA
ADD VECTOR INDEX vector_index embeddings
TYPE MSTG
""")
# Recuperar documentos relevantes
Definimos una función para recuperar los documentos más relevantes en función de la consulta del usuario. La función calcula la distancia entre las incrustaciones de la consulta y las incrustaciones almacenadas para encontrar los documentos más relevantes.
# Función para recuperar documentos relevantes
def get_relevant_docs(user_query, top_k):
query_embeddings = get_text_embeddings(user_query).tolist()
results = client.query(f"""
SELECT page_content,
distance(embeddings, {query_embeddings}) as dist FROM default.QnA ORDER BY dist LIMIT {top_k}
""")
relevant_docs = []
doc_counter = 1
for row in results.named_results():
doc_key = f"doc{doc_counter}"
relevant_docs.append({doc_key: row['page_content']})
doc_counter += 1
return relevant_docs
# Ejemplo de consulta
consulta = "¿Cómo se unen los tejidos epiteliales?"
documentos_relevantes = get_relevant_docs(consulta, 8)
print(documentos_relevantes)
# Utilizar Cohere para respuestas mejoradas
Utilizamos la API de Cohere para mejorar las respuestas consultando los documentos recuperados. El modelo de lenguaje de Cohere procesa la consulta y los documentos recuperados para generar una respuesta más completa y precisa. Este paso integra el poder de los modelos de lenguaje avanzados con nuestro sistema de recuperación.
import cohere
# Conectar a Cohere
co = cohere.Client('tu-api-de-cliente-de-cohere')
# Consultar los documentos relevantes utilizando Cohere
respuesta = co.chat(
model='command-r-plus',
message="¿Cómo se unen los tejidos epiteliales?",
documents=documentos_relevantes
)
print(respuesta.text)
# Conclusión y próximos pasos
Al concluir nuestro viaje de exploración de las aplicaciones RAG con Cohere y Hugging Face, es esencial reflexionar sobre los desafíos encontrados y el crecimiento experimentado a lo largo de este proceso.
Embarcarse en el desarrollo de un pipeline RAG (opens new window) puede presentar obstáculos inesperados, lo que plantea preguntas sobre las disparidades de rendimiento. Sin embargo, al aprovechar herramientas como el modelo Command-R de Cohere y los modelos preentrenados de Hugging Face, los desarrolladores pueden superar estos desafíos de manera efectiva. La integración de métodos de recuperación y generación requiere un ajuste fino meticuloso para lograr resultados óptimos, una tarea que requiere perseverancia y ajustes estratégicos.
Otro componente importante que afecta directamente el rendimiento de cualquier sistema RAG es la base de datos de vectores, que determina qué tan rápido se pueden recuperar tus datos y qué tan rápidamente los usuarios reciben respuestas. Por lo tanto, la elección de la base de datos de vectores adecuada es extremadamente importante al diseñar un sistema RAG.
Sin embargo, muchas bases de datos se vuelven más lentas durante la escalabilidad. MyScaleDB (opens new window) es una base de datos de vectores SQL de código abierto construida sobre ClickHouse. Su alta escalabilidad heredada de ClickHouse gestiona sin esfuerzo datos a gran escala, proporcionando a los usuarios una solución de gestión de datos potente y flexible para construir sistemas RAG escalables. Además, ha demostrado un mejor rendimiento (opens new window) que la mayoría de sus competidores en términos de velocidad y precisión.
Profundizando en las características avanzadas ofrecidas por Cohere y Hugging Face, los desarrolladores pueden desbloquear nuevas dimensiones de eficiencia y rendimiento en sus aplicaciones RAG. Desde la optimización de los mecanismos de recuperación hasta la personalización de los procesos de generación, estas plataformas ofrecen una amplia gama de herramientas para mejorar aún más las capacidades de la aplicación.



