
En el mundo del aprendizaje automático, solía haber un límite en los modelos: solo podían manejar un tipo de datos a la vez. Sin embargo, la aspiración última del aprendizaje automático es rivalizar con la capacidad cognitiva de la mente humana, que comprende sin esfuerzo diversas modalidades de datos simultáneamente. Los avances recientes, ejemplificados por modelos como GPT-4V, han demostrado ahora la notable capacidad de manejar simultáneamente múltiples modalidades de datos. Esto abre emocionantes posibilidades para que los desarrolladores creen aplicaciones de IA capaces de gestionar sin problemas diversos tipos de datos, lo que se conoce como aplicaciones multi-modales.
Un caso de uso convincente que ha ganado gran popularidad es la búsqueda de imágenes multi-modal. Permite a los usuarios encontrar imágenes similares analizando características o contenido visual. Gracias a los rápidos avances en visión por computadora y aprendizaje profundo, la búsqueda de imágenes se ha vuelto increíblemente poderosa.
En este artículo, vamos a construir una aplicación de búsqueda de imágenes multi-modal utilizando un modelo de la biblioteca Hugging Face. Antes de sumergirnos en la implementación práctica, repasemos algunos conceptos básicos para preparar el terreno para nuestra exploración.
# ¿Qué es un Sistema Multi-Modal?
Un sistema multi-modal se refiere a cualquier sistema que pueda utilizar más de un modo de interacción o comunicación. Significa un sistema que puede procesar y comprender diferentes tipos de entradas al mismo tiempo, como texto, imágenes, voz y a veces incluso toque o gestos, y también puede devolver resultados de diversas formas.
Por ejemplo, GPT-4V (opens new window), desarrollado por OpenAI, es un modelo multimodal avanzado que puede manejar múltiples "modalidades" de entradas de texto e imagen al mismo tiempo. Cuando se le proporciona una imagen acompañada de una consulta descriptiva, el modelo puede analizar el contenido visual en función del texto proporcionado.
# ¿Qué son los Embeddings Multi-Modales?
El embedding multi-modal, una técnica avanzada de aprendizaje automático, es el proceso de generar una representación numérica de múltiples modalidades, como imágenes, texto y audio, en un formato vectorial. A diferencia de las técnicas de embedding básicas, que representan solo un solo tipo de datos en un espacio vectorial, el embedding multi-modal puede representar varios tipos de datos dentro de un espacio vectorial unificado. Esto permite, por ejemplo, correlacionar una descripción de texto con una imagen correspondiente. Con la ayuda de los embeddings multi-modales, un sistema podría analizar una imagen y relacionarla con descripciones textuales relevantes, o viceversa.
Ahora, discutamos cómo desarrollar este proyecto y las tecnologías que utilizaremos.
# Herramientas y Tecnologías
Utilizaremos CLIP (opens new window), MyScale (opens new window) y Unsplash-25k Dataset (opens new window) en este proyecto. Veámoslos en detalle.
- CLIP: Utilizaremos un modelo multi-modal pre-entrenado CLIP (opens new window) desarrollado por OpenAI de Hugging Face. Este modelo se utilizará para integrar texto e imágenes.
- MyScale: MyScale es una base de datos vectorial SQL que se utiliza para almacenar y procesar datos estructurados y no estructurados de manera optimizada. Utilizaremos MyScale para almacenar los embeddings vectoriales y consultar las imágenes relevantes.
- Unsplash-25k dataset: El conjunto de datos proporcionado por Unsplash contiene alrededor de 25 mil imágenes. Incluye escenas y objetos complicados.
# Cómo Configurar Hugging Face y MyScale
Para comenzar a utilizar Hugging Face y MyScale en el entorno local, debes instalar algunos paquetes de Python. Abre tu terminal e ingresa el siguiente comando pip:
pip install datasets clickhouse-connect requests transformers torch tqdm
Una vez finalizada la instalación, puedes verificar ingresando el siguiente comando en tu terminal.
pip freeze | egrep '(datasets|clickhouse-connect|requests|transformers|torch|tqdm)'
Esto imprimirá las dependencias recién instaladas con sus versiones.
# Descargar y Cargar el Conjunto de Datos
El primer paso es descargar el conjunto de datos y extraerlo localmente. Puedes hacerlo ingresando los siguientes comandos en tu terminal.
# Download the dataset
wget https://unsplash-datasets.s3.amazonaws.com/lite/latest/unsplash-research-dataset-lite-latest.zip
# unzip the downloaded files into a temporary directory
unzip unsplash-research-dataset-lite-latest.zip -d tmp
Carguemos los datos requeridos en marcos de datos de Python a partir de los archivos extraídos.
# Import pandas
import pandas as pd
# Load the photos file from the directory
df_photos = pd.read_csv("tmp/photos.tsv", sep='\t', header=0)
df_photos
Estamos cargando el archivo photos desde el directorio, que contiene información sobre las fotos en el conjunto de datos. Un perfil de foto se ve así:
| photo_id | photo_url | photo_image_url |
|---|---|---|
| xapxF7PcOzU | https://unsplash.com/photos/wud-eV6Vpwo | https://images.unsplash.com/photo-143924685475... |
| psIMdj26lgw | https://unsplash.com/photos/psIMdj26lgw | https://images.unsplash.com/photo-144077331099... |
La diferencia entre photo_url y photo_image_url es que photo_url contiene la URL de la página de descripción de una imagen, que muestra el autor y otra información meta de la foto. photo_image_url contiene solo la URL de la imagen y la utilizaremos para descargar la imagen.
# Cargar el Modelo y Obtener los Embeddings
Después de cargar el conjunto de datos, carguemos primero el modelo clip-vit-base-patch32 (opens new window) y escribamos una función en Python para transformar imágenes en embeddings vectoriales. Esta función utilizará el modelo CLIP para representar los embeddings.
# Import pytorch
import torch
# Import transformers to load the model and processor from Hugging Face
from transformers import CLIPProcessor, CLIPModel
# Load the CLIP model from Hugging Face
model = CLIPModel.from_pretrained('openai/clip-vit-base-patch32')
# Load the processor used to pre-process the images and make them compatible with the model
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
# Define the method
def create_embeddings(image=None, text=None):
# Initialize embeddings
image_embeddings = None
text_embeddings = None
# Process the image if provided
if image is not None:
image_embeddings = extract_image_features(image)
image_embeddings = torch.tensor(image_embeddings)
image_embeddings = image_embeddings / image_embeddings.norm(dim=-1, keepdim=True)
# Process the text if provided
if text is not None:
text_inputs = processor(text=[text], return_tensors="pt", padding=True)
with torch.no_grad():
text_outputs = model.get_text_features(**text_inputs)
text_embeddings = text_outputs / text_outputs.norm(dim=-1, keepdim=True)
text_embeddings = text_embeddings.squeeze(0).tolist()
# Combine the embeddings if both image and text are provided, and normalize
if image_embeddings is not None and text_embeddings is not None:
combined_embeddings = (image_embeddings + torch.tensor(text_embeddings)) / 2
combined_embeddings = combined_embeddings / combined_embeddings.norm(dim=-1, keepdim=True)
return combined_embeddings.tolist()
# Return only image or text embeddings if one of them is provided
return image_embeddings.tolist() if text_embeddings is None else text_embeddings
El código anterior está diseñado para procesar tanto entradas de texto como de imagen, ya sea por separado o simultáneamente, y devolver los embeddings correspondientes. Veamos cómo funcionan:
- Si proporcionas tanto una imagen como un texto, el código devuelve un solo vector, combinando los embeddings de ambos.
- Si proporcionas solo texto o solo imagen (pero no ambos), el código simplemente devuelve los embeddings del texto o la imagen proporcionada.
Nota:
Estamos utilizando una forma básica de combinar dos embeddings solo para centrarnos en el concepto multi-modal. Pero hay formas mejores de combinar embeddings, como la concatenación y los mecanismos de atención.
Cargaremos, descargaremos y pasaremos las primeras 1000 imágenes del conjunto de datos a la función create_embeddings mencionada anteriormente. Los embeddings devueltos se almacenarán en una nueva columna llamada photo_embed.
# Import the Image moduke for image processing
from PIL import Image
# Import the requests module for making HTTP requests
import requests
# Import tqdm for processing bar visualization
from tqdm.auto import tqdm
# Get the first 1000 images
photo_ids = df_photos['photo_id'][:1000]
# Filter the DataFrame to get the required columns
df_photos = df_photos.loc[photo_ids.index, ['photo_id', 'photo_image_url']]
# Create a session to make HTTP requests
session = requests.Session()
# Define the Python function to download and get embeddings
def process_image(url):
try:
# Make a GET request to download the image
response = session.get(url, stream=True)
response.raise_for_status()
image = Image.open(response.raw)
# Get the embeddings and return
return create_embeddings(image)
except requests.RequestException:
return None
# construct a URL to download the image with a smaller size
df_photos['photo_image_url'] = df_photos['photo_image_url'].apply(lambda x: x + "?q=75&fm=jpg&w=200&fit=max")
# Pass the images one by one to the 'process_image' and save the embeddings to the newly created column 'photo_embed'
df_photos['photo_embed'] = [process_image(url) for url in tqdm(df_photos['photo_image_url'], total=len(df_photos))]
# Remove rows where image processing failed
df_photos.dropna(subset=['photo_embed'], inplace=True)
# Reset the index and rename the 'id' column to 'index'
df_photos = df_photos[df_photos['photo_id'].isin(photo_ids)].reset_index().rename(columns={'index': 'id'})
# Close the session
session.close()
Nota:
Este proceso lleva tiempo y también depende de la velocidad de tu conexión a Internet.
Después de este proceso, nuestro conjunto de datos está completo. El siguiente paso es crear una nueva tabla y almacenar los datos en MyScale.
# Conectar con MyScale
Para conectar la aplicación con MyScale, deberás completar algunos pasos de configuración y establecimiento.
- Creación de una cuenta: Comienza creando una cuenta en MyScale (opens new window).
- Creación de un clúster: A continuación, debes crear un clúster. Para ello, puedes consultar la documentación "Crear un clúster (opens new window)" proporcionada por MyScale con instrucciones detalladas.
- Obtener detalles de conexión: Una vez que hayas configurado tu clúster, el siguiente paso es obtener los detalles de conexión (opens new window) para establecer una conexión entre tu aplicación y el clúster de MyScale.
Una vez que tengas los detalles de conexión, puedes reemplazar los valores en el siguiente código:
import clickhouse_connect
client = clickhouse_connect.get_client(
host='tu-direccion-de-host',
port=443,
username='tu-nombre-de-usuario',
password='tu-contraseña'
)
# Crear una Tabla
Una vez establecida la conexión, el siguiente paso es crear una tabla. Ahora, veamos primero nuestro marco de datos con este comando:
df_photos
El marco de datos se ve así:
| photo_id | photo_image_url | photo_embed |
|---|---|---|
| wud-eV6Vpwo | https://images.unsplash.com/uploads/1411949294... | [0.0028754104860126972, 0.02760922536253929, 0... |
| psIMdj26lgw | https://images.unsplash.com/photo-141633941111... | [0.019032524898648262, -0.04198262840509415, 0... |
| 2EDjes2hlZo | https://images.unsplash.com/photo-142014251503... | [-0.015412664040923119, 0.01923416182398796, 0... |
Creemos una tabla en función del marco de datos.
# Check if a table with the same name exists or not. If exists, drop that table
client.command("DROP TABLE IF EXISTS default.myscale_photos")
# create a table for photos
client.command("""
CREATE TABLE default.myscale_photos
(
id UInt64,
photo_id String,
photo_image_url String,
photo_embed Array(Float32),
CONSTRAINT vector_len CHECK length(photo_embed) = 512
)
ORDER BY id
""")
Los comandos anteriores crearán una tabla en tu clúster de MyScale.
# Insertar los Datos
Insertemos los datos en la tabla recién creada:
# upload data from datasets
client.insert("default.myscale_photos", df_photos.to_records(index=False).tolist(),
column_names=df_photos.columns.tolist())
# check count of inserted data
print(f"photos count: {client.command('SELECT count(*) FROM default.myscale_photos')}")
# create vector index with cosine
client.command("""
ALTER TABLE default.myscale_photos
ADD VECTOR INDEX photo_embed_index photo_embed
TYPE MSTG
('metric_type=Cosine')
""")
# check the status of the vector index, make sure vector index is ready with 'Built' status
get_index_status="SELECT status FROM system.vector_indices WHERE name='photo_embed_index'"
print(f"index build status: {client.command(get_index_status)}")
El código anterior insertará los datos en la tabla y creará un índice utilizando el algoritmo MSTG. Los índices se crean para una recuperación rápida de datos de la tabla. El último comando se utiliza para asegurarse de que el índice se haya creado correctamente. Si es así, verás "Estado de construcción del índice: Built".
Nota:
El algoritmo MSTG ha sido creado por MyScale y es mucho más rápido que otros algoritmos de indexación como IVF y HNSW.

# Cómo Consultar MyScale
Una vez que los datos se hayan insertado, estamos listos para utilizar MyScale para consultar datos y utilizar el modelo multi-modal para obtener imágenes. Entonces, intentemos primero obtener una imagen aleatoria de la tabla.
import requests
import matplotlib.pyplot as plt
from PIL import Image
from io import BytesIO
# download image with its url
def download(url):
response = requests.get(url)
return Image.open(BytesIO(response.content))
def show_image(url, title=None):
img = download(url)
fig = plt.figure(figsize=(4, 4))
plt.imshow(img)
plt.show()
random_image = client.query("SELECT * FROM default.myscale_photos ORDER BY rand() LIMIT 1")
target_image_url = random_image.first_item["photo_image_url"]
print("Cargando imagen objetivo...")
show_image(target_image_url)
El código anterior debería buscar aleatoriamente una imagen de la tabla y mostrarla en tu editor de código.
# Cómo Obtener Imágenes Relevantes Utilizando Texto e Imagen
Como has aprendido, un modelo multi-modal puede procesar múltiples modalidades de datos al mismo tiempo. De manera similar, nuestro modelo puede procesar simultáneamente tanto imágenes como texto, proporcionando imágenes relevantes. Proporcionaremos la siguiente imagen junto con el texto: 'Un hombre de pie en la playa'.

Pasemos la URL de la imagen con el texto a la función create_embeddings.
image_url="https://images.unsplash.com/photo-1701443478334-c1a4bfda91ff?q=80&w=1936&auto=format&fit=crop&ixlib=rb-4.0.3&ixid=M3wxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8fA%3D%3D"
query_text="Un hombre de pie en la playa"
embeddings=create_embeddings(download(url),query_text)
El siguiente paso es escribir una consulta para obtener los resultados relevantes top_k del conjunto de datos.
top_k = 5
# Query to get the relevant results from the database
results = client.query(f"""
SELECT photo_id, photo_image_url, distance(photo_embed, {embeddings}) as dist
FROM default.myscale_photos
ORDER BY dist ASC
LIMIT {top_k}
""")
# Download the relevant images
images_url = []
for r in results.named_results():
# construct a URL to download an image with a smaller size by modifying the image URL
url = r['photo_image_url'] + "?q=75&fm=jpg&w=200&fit=max"
images_url.append(download(url))
# display the images
print("Cargando imágenes candidatas...")
for row in range(int(top_k / 5)):
fig, axs = plt.subplots(1, 5, figsize=(20, 4))
for i, img in enumerate(images_url[row * 5:row * 5 + 5]):
axs[i % 5].imshow(img)
plt.show()
Nota:
La función de distancia encuentra la distancia euclidiana entre el vector de consulta y todos los vectores relevantes.
El código anterior generará resultados similares a estos:
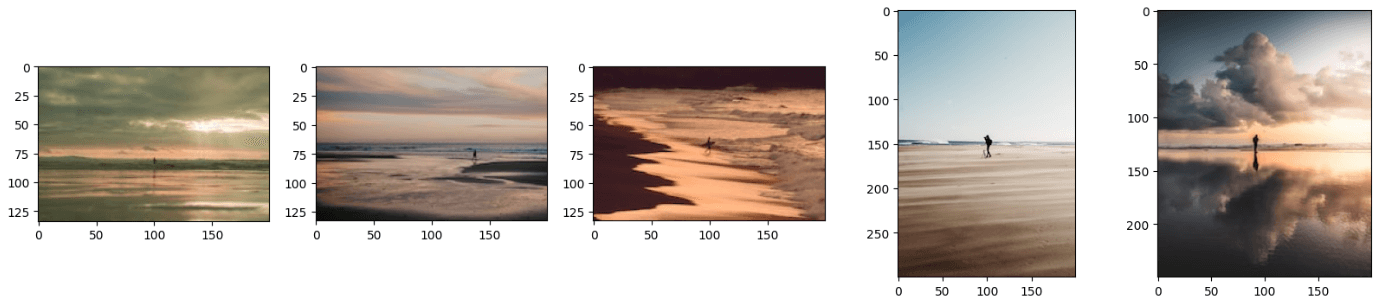
Nota:
Puedes mejorar aún más los resultados utilizando técnicas mejores para combinar los embeddings.
Es posible que hayas notado que las imágenes resultantes parecen una combinación tanto del texto como de la imagen. También puedes obtener los resultados proporcionando solo una imagen o solo texto a este modelo y funcionará perfectamente bien. Para ello, simplemente debes comentar la línea de código image_url o query_text.
# Conclusión
Los modelos tradicionales se utilizan para obtener las representaciones vectoriales de un solo tipo de datos, pero los modelos más recientes se entrenan con muchos más datos y ahora pueden representar diferentes tipos de datos en un espacio vectorial unificado. Hemos utilizado las capacidades de un modelo más reciente, CLIP, para desarrollar una aplicación que toma tanto texto como imágenes como entrada y devuelve las imágenes relevantes.
Las capacidades de los embeddings multi-modales no se limitan a las aplicaciones de búsqueda de imágenes, sino que también puedes utilizar esta técnica de vanguardia para desarrollar sistemas de recomendación de última generación, aplicaciones de respuesta a preguntas visuales donde los usuarios pueden hacer preguntas relacionadas con imágenes y muchos más. Al desarrollar estas aplicaciones, considera utilizar MyScale (opens new window), una base de datos vectorial SQL integrada que te permite almacenar embeddings vectoriales y datos tabulares de tu conjunto de datos con capacidades de recuperación de datos súper rápidas.
Si estás construyendo una aplicación de búsqueda de imágenes, te invitamos a intercambiar tus ideas o comentarios en el Discord de MyScale (opens new window).



