
La generación con recuperación aumentada (opens new window) (RAG, por sus siglas en inglés) fue un gran avance en el campo del procesamiento del lenguaje natural (NLP, por sus siglas en inglés), especialmente para el desarrollo de aplicaciones de inteligencia artificial (IA). RAG combina una gran base de conocimientos (opens new window) y las capacidades lingüísticas de los modelos de lenguaje grandes (opens new window) (LLMs, por sus siglas en inglés) con capacidades de recuperación de datos. La capacidad de recuperar y utilizar información en tiempo real hace que las interacciones de IA sean más auténticas e informadas.
RAG ha mejorado notablemente la forma en que los usuarios interactúan con la IA. Por ejemplo, los chatbots impulsados por LLM ya pueden manejar preguntas complicadas y adaptar sus respuestas a usuarios individuales. Las aplicaciones de RAG mejoran esto al no solo utilizar los datos de entrenamiento, sino también al buscar información actualizada durante la interacción.
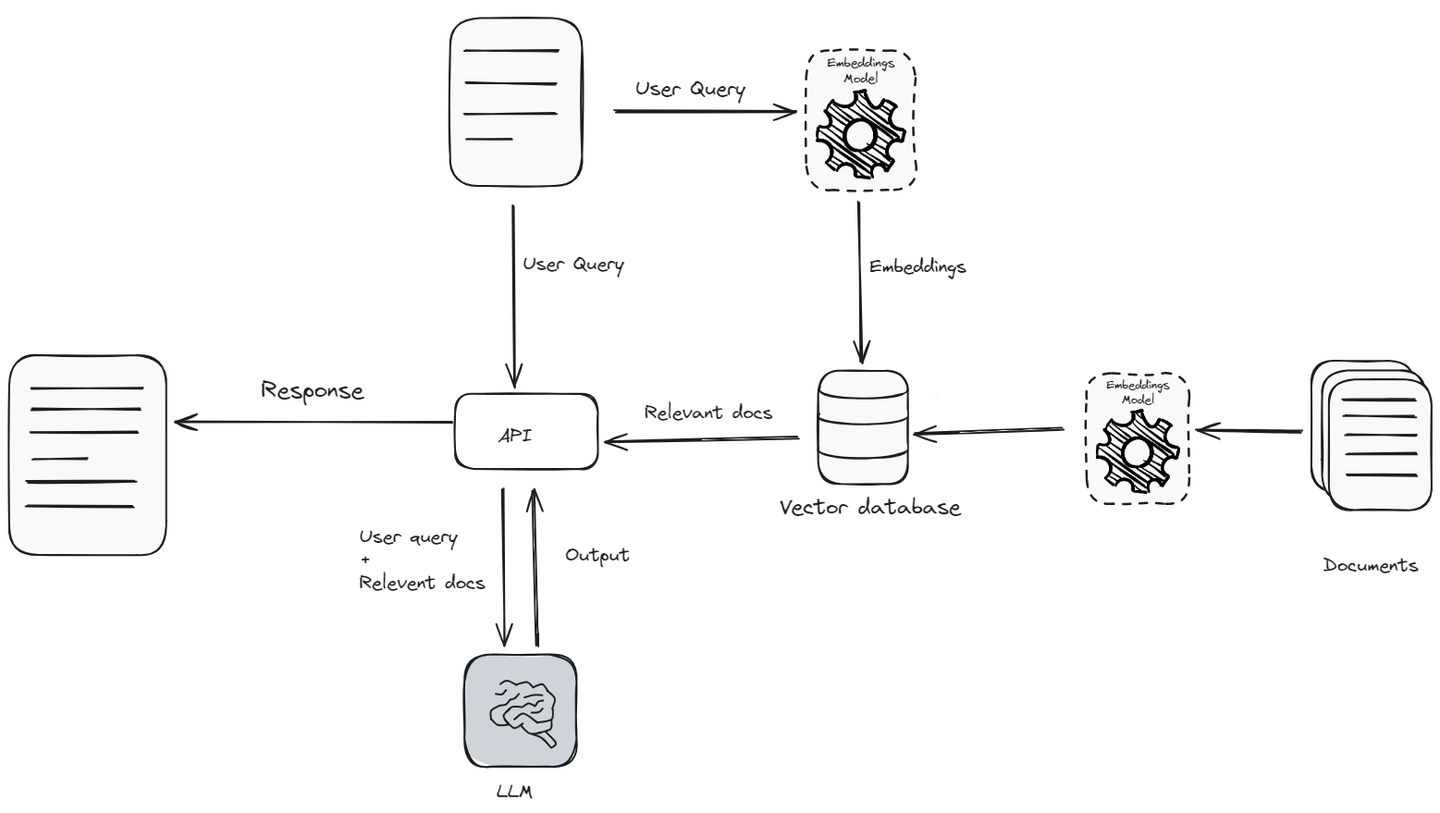
Sin embargo, las aplicaciones de RAG funcionan bastante bien cuando se utilizan a pequeña escala, pero plantean desafíos significativos cuando intentamos escalarlas, como gestionar los costos de la API y el almacenamiento de datos, reducir la latencia y aumentar el rendimiento, buscar eficientemente en bases de conocimientos extensas y garantizar la privacidad del usuario.
En este blog, exploraremos los diversos desafíos encontrados al escalar aplicaciones de RAG, junto con soluciones efectivas para abordarlos.
# Gestión de costos: almacenamiento de datos y uso de API
Uno de los mayores obstáculos para expandir las aplicaciones de RAG es la gestión de costos, especialmente debido a la dependencia de las API de los modelos de lenguaje grandes (LLMs) como OpenAI (opens new window) o Gemini (opens new window). Al construir una aplicación de RAG, hay tres factores principales a considerar en cuanto a costos:
- API de LLM
- API de modelos de incrustaciones
- Base de datos vectorial
El costo de estas API es más alto porque los proveedores de servicios gestionan todo en su extremo, como los costos computacionales, el entrenamiento, etc. Esta configuración puede ser sostenible para proyectos más pequeños, pero a medida que aumenta el uso de su aplicación, los costos pueden convertirse rápidamente en una carga significativa.
Supongamos que está utilizando gpt-4 en su aplicación de RAG y su aplicación de RAG maneja más de 10 millones de tokens de entrada y 3 millones de tokens de salida diariamente, podría estar enfrentando costos de alrededor de $480 al día, lo cual es una cantidad significativa para ejecutar cualquier aplicación. Al mismo tiempo, las bases de datos vectoriales también necesitan actualizaciones regulares y deben escalarse a medida que crecen los datos, lo que agrega aún más a sus costos.
# Estrategias de reducción de costos
Como hemos discutido, ciertos componentes en la arquitectura de RAG pueden ser bastante costosos. Veamos algunas estrategias para reducir el costo de estos componentes.
- Afinar un LLM y un modelo de incrustaciones: Para minimizar los costos asociados con la API de LLM y el modelo de incrustaciones, el enfoque más efectivo es elegir un LLM de código abierto (opens new window) y un modelo de incrustaciones, y luego afinarlos utilizando sus propios datos. Sin embargo, esto requiere una gran cantidad de datos, experiencia técnica y recursos computacionales.
- Caché: Utilizar una caché (opens new window) para almacenar las respuestas de un LLM puede reducir el costo de las llamadas a la API y hacer que su aplicación sea más rápida y eficiente. Cuando una respuesta se guarda en la caché, se puede recuperar rápidamente si se necesita nuevamente, sin tener que solicitarla al LLM por segunda vez. El uso de una caché puede reducir el costo de las llamadas a la API hasta en un 10%. Puede utilizar diferentes técnicas de caché (opens new window) de langchain.
- Prompts de entrada concisos: Puede reducir el número de tokens de entrada requeridos al refinar y acortar los prompts de entrada. Esto no solo permite que el modelo comprenda mejor la consulta del usuario, sino que también reduce los costos al utilizar menos tokens.
- Limitar los tokens de salida: Establecer un límite en el número de tokens de salida puede evitar que el modelo genere respuestas innecesariamente largas, controlando así los costos y proporcionando información relevante.
# Reducción del costo de las bases de datos vectoriales
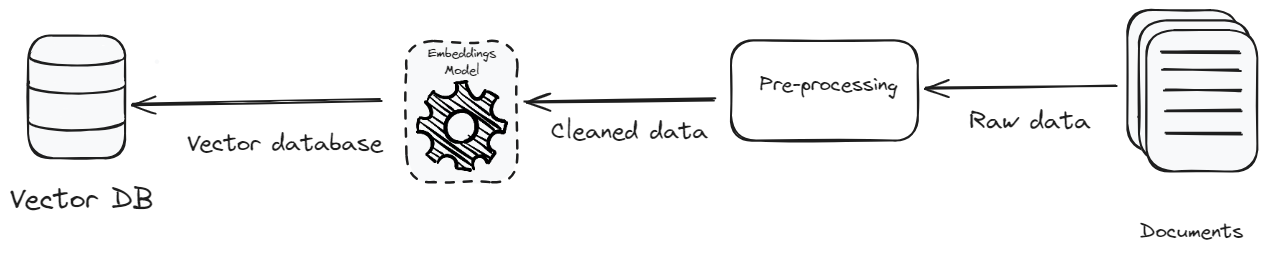
Una base de datos vectorial desempeña un papel crucial en una aplicación de RAG, y el tipo de datos que ingrese también es igualmente importante. Como dice el refrán, "basura entra, basura sale".
- Preprocesamiento: El objetivo del preprocesamiento de los datos es lograr una estandarización y consistencia del texto. La estandarización del texto elimina detalles irrelevantes y caracteres especiales, lo que hace que los datos sean ricos en contexto y consistentes. Centrarse en la claridad, el contexto y la corrección no solo mejora la eficiencia del sistema, sino que también reduce el volumen de datos. La reducción en el volumen de datos significa que hay menos que almacenar, lo que reduce los costos de almacenamiento y mejora la eficiencia de la recuperación de datos.
- Base de datos vectorial rentable: Otro método para reducir los costos es seleccionar una base de datos vectorial menos costosa. Actualmente, hay muchas opciones disponibles en el mercado, pero es crucial elegir una que no solo sea asequible, sino también escalable. MyScaleDB (opens new window) es una base de datos vectorial especialmente diseñada para desarrollar aplicaciones de RAG escalables, teniendo en cuenta varios factores, especialmente el costo. Es una de las bases de datos vectoriales más económicas disponibles en el mercado y tiene un rendimiento mucho mejor que sus competidores.
Artículo relacionado: Primeros pasos con MyScale (opens new window)
# El gran número de usuarios afecta el rendimiento
A medida que una aplicación de RAG se escala, no solo debe admitir un número creciente de usuarios, sino también mantener su velocidad, eficiencia y confiabilidad. Esto implica optimizar el sistema para garantizar un rendimiento óptimo, incluso con un alto número de usuarios simultáneos.
Latencia: Para aplicaciones en tiempo real como los chatbots, mantener una baja latencia (opens new window) es crucial. La latencia se refiere al retraso antes de que comience una transferencia de datos después de recibir una instrucción para su transferencia. Las técnicas para minimizar la latencia incluyen optimizar las rutas de red, reducir la complejidad del manejo de datos y utilizar hardware de procesamiento más rápido. Una forma de gestionar eficazmente la latencia es limitar el tamaño de los prompts a la información esencial, evitando instrucciones demasiado complejas que puedan ralentizar el procesamiento.
Rendimiento: Durante períodos de alta demanda, la capacidad de procesar un gran número de solicitudes simultáneamente sin ralentizaciones se conoce como rendimiento. Esto se puede mejorar significativamente mediante el uso de técnicas como el agrupamiento continuo, donde las solicitudes se agrupan dinámicamente a medida que llegan, en lugar de esperar a que se complete un grupo.
# Sugerencias para mejorar el rendimiento:
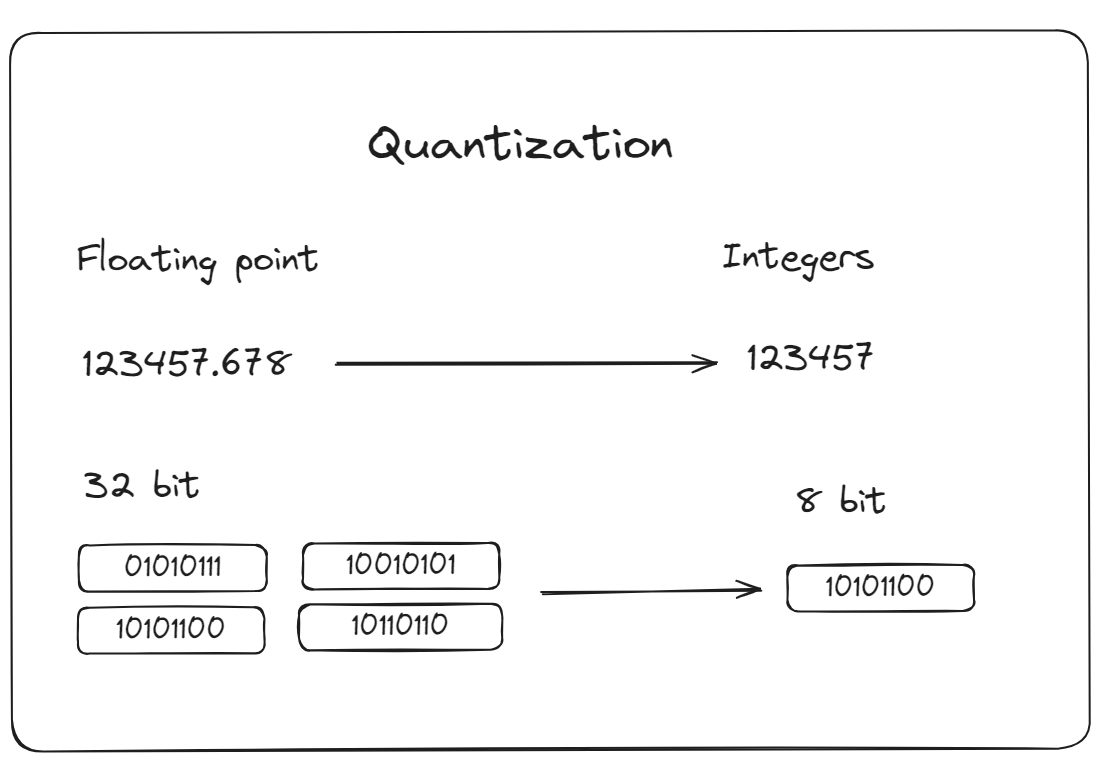
- Cuantización: Es un proceso de reducir la precisión de los números utilizados para representar los parámetros del modelo. Esto reduce los cálculos del modelo, lo que puede disminuir los recursos computacionales requeridos y, por lo tanto, acelerar los tiempos de inferencia. MyScaleDB proporciona opciones avanzadas de indexación de vectores, como IVFPQ (Inverted File Partitioning and Quantization) o HNSWSQ (Hierarchical Navigable Small World Quantization). Estas metodologías están diseñadas para mejorar el rendimiento de su aplicación mediante la optimización de los procesos de recuperación de datos.
Además de estos algoritmos populares, MyScaleDB ha desarrollado Multi-Scale Tree Graph (MSTG) (una función empresarial), que presenta estrategias novedosas en torno a la cuantización y el almacenamiento en niveles. Este algoritmo se recomienda para lograr tanto un bajo costo como una alta precisión, en contraste con IVFPQ o HNSWSQ. Al utilizar la memoria combinada con unidades de estado sólido NVMe rápidas, MSTG reduce significativamente el consumo de recursos en comparación con los algoritmos IVF y HNSW, al tiempo que mantiene un rendimiento y una precisión excepcionales.
Multi-threading: Multi-threading (opens new window) permitirá que su aplicación maneje múltiples solicitudes al mismo tiempo utilizando las capacidades de los procesadores multinúcleo. Al hacerlo, se minimizan los retrasos y se aumenta la velocidad general del sistema, especialmente al manejar muchos usuarios o consultas complejas.
Agrupamiento dinámico: En lugar de procesar las solicitudes a los modelos de lenguaje grandes (LLMs) de manera secuencial, el agrupamiento dinámico agrupa inteligentemente varias solicitudes para enviarlas como un solo lote. Este método mejora la eficiencia, especialmente al tratar con proveedores de servicios como OpenAI y Gemini, que imponen limitaciones en la tasa de la API. El uso del agrupamiento dinámico le permite manejar un mayor número de solicitudes dentro de estos límites de tasa, lo que hace que su servicio sea más confiable y optimiza el uso de la API.
# Búsqueda eficiente en los espacios de incrustación masivos
La recuperación eficiente depende principalmente de qué tan bien una base de datos vectorial indexa los datos y qué tan rápido y efectivamente recupera información relevante. Cada base de datos vectorial funciona bastante bien cuando el conjunto de datos es pequeño, pero surgen problemas a medida que aumenta el volumen de datos. La complejidad de indexar y recuperar información relevante aumenta. Esto puede llevar a un proceso de recuperación más lento, lo cual es crítico en entornos donde se requieren respuestas en tiempo real o casi en tiempo real. Además, cuanto más grande sea la base de datos, más difícil será mantener su precisión y consistencia. Los errores, duplicaciones e información desactualizada pueden infiltrarse fácilmente, lo que puede comprometer la calidad de las salidas proporcionadas por la aplicación de LLM.
Además, la naturaleza de los sistemas de RAG, que dependen de recuperar las piezas más relevantes de información de conjuntos de datos vastos, significa que cualquier degradación en la calidad de los datos afecta directamente el rendimiento y la confiabilidad de la aplicación. A medida que los conjuntos de datos crecen, garantizar que cada consulta reciba la respuesta más precisa y contextualmente apropiada se vuelve cada vez más difícil.
# Soluciones para una búsqueda optimizada:
Para garantizar que el crecimiento en el volumen de datos no comprometa el rendimiento del sistema ni la calidad de sus salidas, se deben considerar varios factores:
- Indexación eficiente: Se necesita el uso de métodos de indexación más sofisticados o soluciones de bases de datos vectoriales más eficientes para manejar conjuntos de datos grandes sin comprometer la velocidad. MyScaleDB (opens new window) proporciona un método de indexación de vectores avanzado de última generación, MSTG (opens new window), diseñado para manejar conjuntos de datos muy grandes. También ha superado a otros métodos de indexación con 390 QPS (consultas por segundo) en el conjunto de datos LAION 5M, logrando una tasa de recuperación del 95% y manteniendo una latencia promedio de consulta de 18 ms con el pod s1.x1.
- Datos de mejor calidad: Para mejorar la calidad de los datos, que es muy importante para la precisión y confiabilidad de los sistemas de RAG, se requiere implementar varias técnicas de preprocesamiento. Esto nos ayudaría a refinar el conjunto de datos, reducir el ruido y aumentar la precisión de la información recuperada. Esto impactará directamente en la efectividad de la aplicación de RAG.
- Poda y optimización de datos: Puede revisar y podar regularmente el conjunto de datos para eliminar vectores desactualizados o irrelevantes y mantener la base de datos ágil y eficiente.
Además, MyScaleDB también ha superado a otras bases de datos vectoriales en tiempo de ingestión de datos al completar tareas en casi 30 minutos para 5 millones de puntos de datos. Si se registra, puede usar un pod x1 de forma gratuita, que puede manejar hasta 5 millones de vectores.

# El riesgo de una violación de datos siempre está presente
En las aplicaciones de RAG, las preocupaciones de privacidad son notablemente significativas debido a dos aspectos principales: el uso de una API de LLM y el almacenamiento de datos en una base de datos vectorial. Al pasar datos privados a través de una API de LLM, existe el riesgo de que los datos puedan ser expuestos a servidores de terceros, lo que podría llevar a violaciones de información confidencial. Además, almacenar datos en una base de datos vectorial que puede no ser completamente segura también puede plantear riesgos para la privacidad de los datos.
# Soluciones para mejorar la privacidad:
Para hacer frente a estos riesgos, especialmente al tratar con datos sensibles o altamente confidenciales, considere las siguientes estrategias:
Desarrollo interno de LLM: En lugar de depender de API de LLM de terceros, puede elegir cualquier LLM de código abierto y afinarlo con sus propios datos internamente (opens new window). Este enfoque garantiza que todos los datos sensibles permanezcan dentro del entorno controlado de su organización, reduciendo significativamente la probabilidad de violaciones de datos.
Base de datos vectorial segura: Asegúrese de que su base de datos vectorial esté protegida con los últimos estándares de cifrado y controles de acceso. MyScaleDB es confiable para equipos y organizaciones debido a sus sólidas características de seguridad. Opera en un clúster de Kubernetes multiinquilino que se aloja en una infraestructura de AWS segura y completamente administrada. MyScaleDB protege los datos del cliente almacenándolos en contenedores aislados y monitorea continuamente las métricas operativas para mantener la salud y el rendimiento del sistema. Además, ha completado con éxito la auditoría SOC 2 Tipo 1, cumpliendo con los más altos estándares globales de seguridad de datos. Con MyScaleDB, puede estar seguro de que sus datos permanecen estrictamente suyos.
Artículo relacionado: Superando a las bases de datos vectoriales especializadas con MyScale (opens new window)
# Conclusión
Si bien la generación con recuperación aumentada (RAG) es un gran avance en la IA, también tiene sus desafíos. Estos incluyen altos costos de API y almacenamiento de datos, aumento de la latencia y la necesidad de un rendimiento eficiente a medida que se suman más usuarios. La privacidad y la seguridad de los datos también se vuelven críticas a medida que aumenta la cantidad de datos almacenados.
Podemos abordar estos problemas con varias estrategias. La reducción de costos es posible mediante el uso de LLM de código abierto afinados internamente y mediante el almacenamiento en caché para reducir el uso de la API. Para mejorar la latencia y el rendimiento, podemos utilizar técnicas como el agrupamiento dinámico y la cuantización avanzada para acelerar el procesamiento y hacerlo más eficiente. Para una mejor seguridad, desarrollar LLM propietarios y utilizar una base de datos vectorial como MyScaleDB es una excelente opción.
Si tiene alguna sugerencia, comuníquese con nosotros a través de Twitter (opens new window) o Discord (opens new window).



