
Los modelos de lenguaje grandes (LLMs) han transformado el campo del Procesamiento del Lenguaje Natural (NLP) al generar texto similar al humano, responder preguntas complejas y analizar grandes cantidades de información con una precisión impresionante. Su capacidad para procesar consultas diversas y producir respuestas detalladas los hace invaluables en muchos campos, desde el servicio al cliente hasta la investigación médica. Sin embargo, a medida que los LLMs se escalan para manejar más datos, enfrentan desafíos en la gestión de documentos largos y en la recuperación eficiente de la información más relevante.
Aunque los LLMs son buenos para procesar y generar texto similar al humano, tienen una "ventana de contexto" limitada. Esto significa que solo pueden mantener cierta cantidad de información en memoria a la vez, lo que dificulta la gestión de documentos muy largos. También es un desafío para los LLMs encontrar rápidamente la información más relevante en conjuntos de datos grandes. Además, los LLMs se entrenan con datos fijos, por lo que pueden quedar desactualizados a medida que aparece nueva información. Para mantenerse precisos y útiles, necesitan actualizaciones regulares.
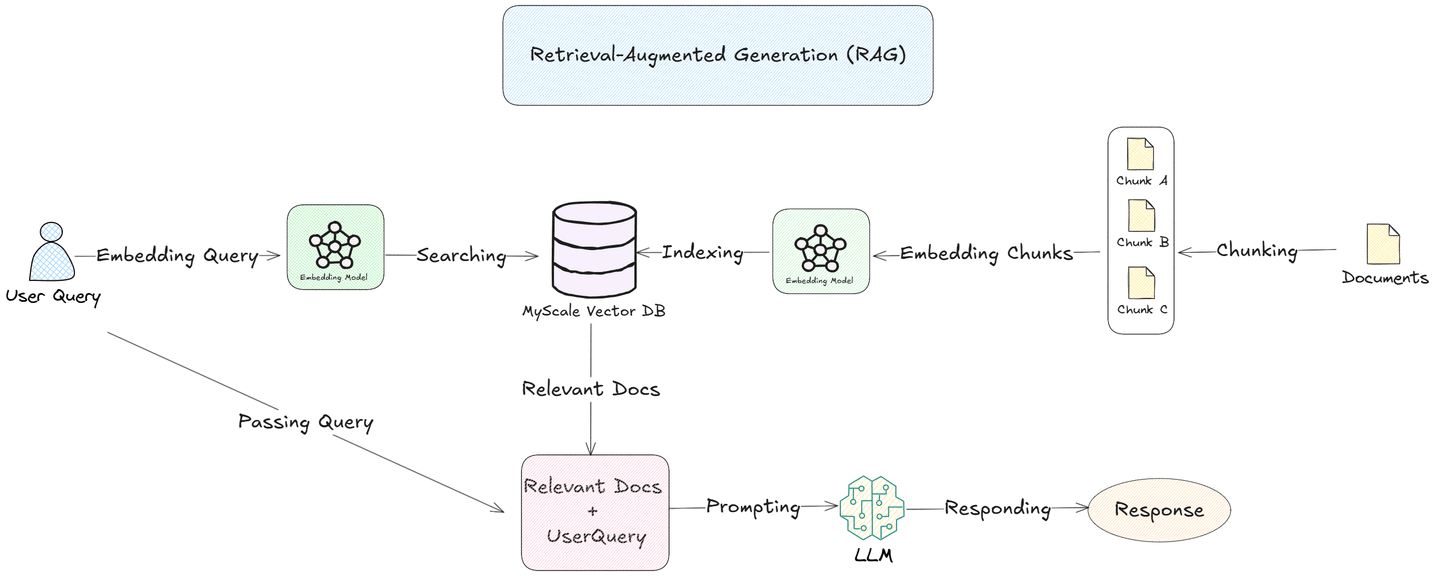
La Generación Mejorada por Recuperación (RAG) aborda estos desafíos. Al fragmentar documentos en segmentos más pequeños y significativos e incrustarlos en una base de datos vectorial como la base de datos de MyScale (opens new window), los sistemas RAG pueden buscar y recuperar solo los fragmentos más relevantes para cada consulta. Este enfoque permite que los LLMs se centren en información específica, mejorando la precisión y eficiencia de las respuestas.
En este blog, exploraremos la fragmentación y sus diferentes estrategias en más detalle y su papel en la optimización de los LLMs para aplicaciones del mundo real.
# ¿Qué es la fragmentación?
La fragmentación consiste en dividir fuentes de datos grandes en piezas más pequeñas y manejables, o "fragmentos". Estos fragmentos se almacenan en bases de datos vectoriales, lo que permite búsquedas rápidas y eficientes basadas en similitud. Cuando un usuario envía una consulta, la base de datos vectorial encuentra los fragmentos más relevantes y los envía al modelo de lenguaje. De esta manera, el modelo puede centrarse solo en la información más relevante, lo que hace que su respuesta sea más rápida y precisa. Al reducir los datos que necesita examinar, la fragmentación ayuda a los modelos de lenguaje a manejar conjuntos de datos grandes de manera más fluida y a ofrecer respuestas precisas.
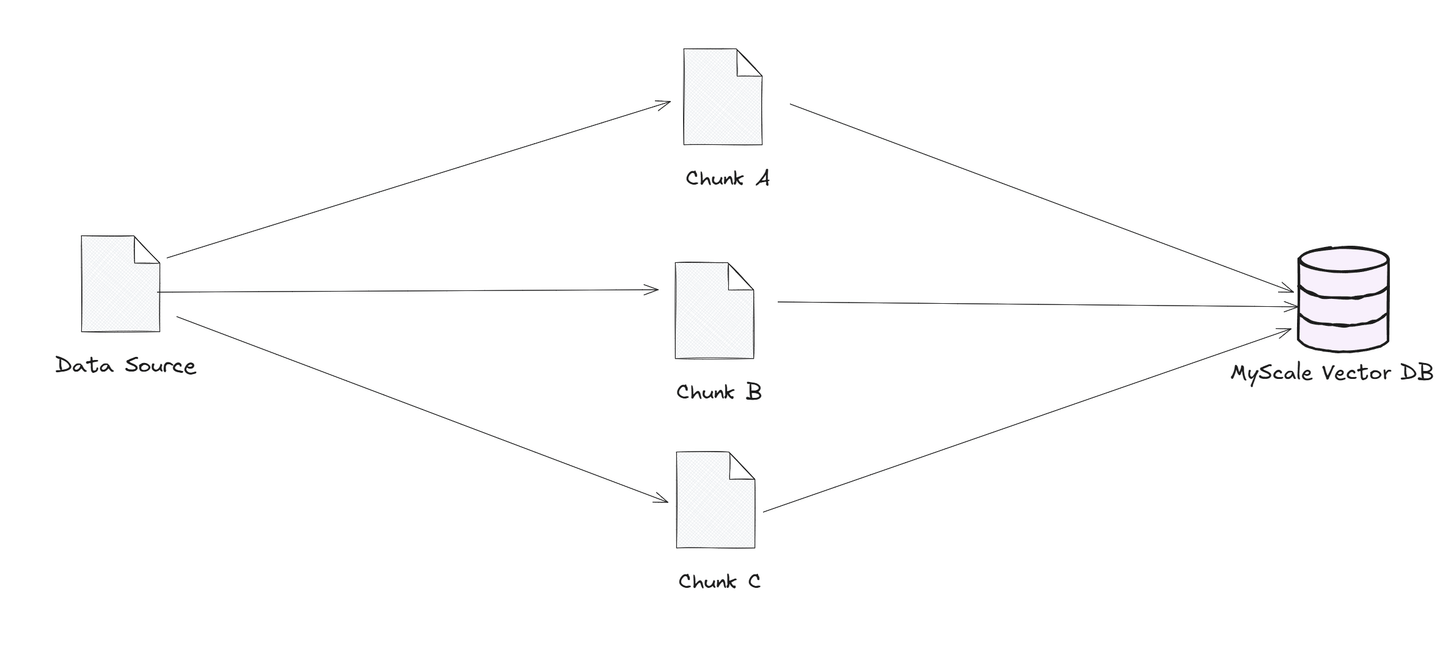
Para aplicaciones que requieren respuestas rápidas y precisas, como el soporte al cliente o la búsqueda de documentos legales, la fragmentación es una estrategia esencial que mejora tanto el rendimiento como la confiabilidad.
Aquí se presentan algunas de las principales estrategias de fragmentación que se utilizan en RAG:
- Fragmentación de tamaño fijo
- Fragmentación recursiva
- Fragmentación semántica
- Fragmentación agente
Ahora, profundicemos en cada estrategia de fragmentación en detalle.
# Fragmentación de tamaño fijo
La fragmentación de tamaño fijo implica dividir los datos en secciones de tamaño uniforme, lo que facilita el procesamiento de documentos grandes. A veces, los desarrolladores agregan una ligera superposición entre los fragmentos, donde una pequeña parte de un segmento se repite al comienzo del siguiente. Este enfoque de superposición ayuda al modelo a mantener el contexto a través de los límites de cada fragmento, asegurando que no se pierda información importante en los bordes. Esta estrategia es especialmente útil para tareas que requieren un flujo continuo de información, ya que permite que el modelo interprete el texto de manera más precisa y comprenda la relación entre los segmentos, lo que lleva a respuestas más coherentes y contextualmente conscientes.

La ilustración anterior es un ejemplo perfecto de fragmentación de tamaño fijo, donde cada fragmento está representado por un color único. La sección verde indica la parte de superposición entre los fragmentos, asegurando que el modelo tenga acceso al contexto relevante de un fragmento al procesar el siguiente.
Esta superposición mejora la capacidad del modelo para procesar y comprender el texto completo, lo que lleva a un mejor rendimiento en tareas como la resumen o la traducción, donde mantener el flujo de información a través de los límites de los fragmentos es fundamental.
# Ejemplo de código
Ahora recreemos este ejemplo con la ayuda de un ejemplo de código donde utilizaremos LangChain (opens new window) que nos ayudará a implementar la fragmentación de tamaño fijo.
from langchain.text_splitter import RecursiveCharacterTextSplitter
# Función para dividir el texto en fragmentos de tamaño fijo y superposición
def split_text_with_overlap(text, chunk_size, overlap_size):
# Crear un separador de texto con superposición
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=overlap_size
)
# Dividir el texto
fragments = text_splitter.split_text(text)
return fragments
# Texto de ejemplo
text = """La inteligencia artificial (IA) simula la inteligencia humana en máquinas para tareas como la percepción visual, el reconocimiento de voz y la traducción de idiomas. Ha evolucionado desde sistemas basados en reglas hasta modelos basados en datos, mejorando el rendimiento a través del aprendizaje automático y el aprendizaje profundo."""
# Definir el tamaño del fragmento y el tamaño de superposición
chunk_size = 80 # 80 caracteres por fragmento
overlap_size = 10 # 10 caracteres de superposición entre fragmentos
# Obtener los fragmentos con superposición
fragments = split_text_with_overlap(text, chunk_size, overlap_size)
# Imprimir los fragmentos y las superposiciones
for i in range(len(fragments)):
print(f"Fragmento {i+1}:")
print(fragments[i]) # Imprimir el fragmento en sí
# Si hay un fragmento siguiente, imprimir la superposición entre el fragmento actual y el siguiente
if i < len(fragments) - 1:
superposicion = fragments[i][-overlap_size:] # Obtener la parte de superposición
print(f"Superposición con el Fragmento {i+2}:")
print(superposicion)
print("\n" + "="*50 + "\n")
Al ejecutar el código anterior, se generará la siguiente salida:
Fragmento 1:
La inteligencia artificial (IA) simula la inteligencia humana en máquinas para tareas
Superposición con el Fragmento 2:
para tareas
==================================================
Fragmento 2:
para tareas como la percepción visual, el reconocimiento de voz y la traducción de idiomas.
Superposición con el Fragmento 3:
de idiomas.
==================================================
Fragmento 3:
Ha evolucionado desde sistemas basados en reglas hasta modelos basados en datos, mejorando
Superposición con el Fragmento 4:
mejorando
==================================================
Fragmento 4:
mejorando el rendimiento a través del aprendizaje automático y el aprendizaje profundo.
# Fragmentación recursiva
La fragmentación recursiva es un método que divide sistemáticamente un texto extenso en secciones más pequeñas y manejables al descomponerlo repetidamente en subfragmentos. Este enfoque es particularmente efectivo para documentos complejos o jerárquicos, asegurando que cada segmento permanezca coherente y contextualmente intacto. El proceso continúa hasta que el texto alcanza un tamaño adecuado para su procesamiento eficiente.
Por ejemplo, consideremos un documento extenso que debe ser procesado por un modelo de lenguaje con una ventana de contexto limitada. La fragmentación recursiva primero dividiría el documento en secciones principales. Si estas secciones aún son demasiado grandes, el método las dividiría aún más en subsecciones y continuaría este proceso hasta que cada fragmento se ajuste a las capacidades de procesamiento del modelo. Esta descomposición jerárquica preserva el flujo lógico y el contexto del documento original, lo que permite que el modelo maneje textos largos de manera más efectiva.
En la práctica, la fragmentación recursiva se puede implementar utilizando diversas estrategias, como la división basada en encabezados, párrafos o frases, según la estructura del documento y los requisitos específicos de la tarea.

En la ilustración, el texto se divide en cuatro fragmentos, cada uno mostrado en un color diferente, utilizando la fragmentación recursiva. El texto se descompone en partes más pequeñas y manejables, con cada fragmento que contiene hasta 80 palabras. No hay superposición entre los fragmentos. La codificación de colores ayuda a mostrar cómo se divide el contenido en secciones lógicas, lo que facilita el procesamiento y la comprensión de textos largos por parte del modelo sin perder un contexto importante.
# Ejemplo de código
Ahora codifiquemos un ejemplo donde implementaremos la fragmentación recursiva.
from langchain.text_splitter import RecursiveCharacterTextSplitter
# Función para dividir el texto en fragmentos utilizando la fragmentación recursiva
def split_text_recursive(text, chunk_size=80):
# Inicializar RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size, # Tamaño máximo de cada fragmento (80 palabras)
chunk_overlap=0 # Sin superposición entre fragmentos
)
# Dividir el texto en fragmentos
fragments = text_splitter.split_text(text)
return fragments
# Texto de ejemplo
text = """La inteligencia artificial (IA) simula la inteligencia humana en máquinas para tareas como la percepción visual, el reconocimiento de voz y la traducción de idiomas. Ha evolucionado desde sistemas basados en reglas hasta modelos basados en datos, mejorando el rendimiento a través del aprendizaje automático y el aprendizaje profundo."""
# Dividir el texto utilizando la fragmentación recursiva
fragments = split_text_recursive(text, chunk_size=80)
# Imprimir los fragmentos resultantes
for i, fragment in enumerate(fragments):
print(f"Fragmento {i+1}:")
print(fragment)
print("="*50)
El código anterior generará la siguiente salida:
Fragmento 1:
La inteligencia artificial (IA) simula la inteligencia humana en máquinas para tareas
==================================================
Fragmento 2:
como la percepción visual, el reconocimiento de voz y la traducción de idiomas. Ha
==================================================
Fragmento 3:
evolucionado desde sistemas basados en reglas hasta modelos basados en datos,
==================================================
Fragmento 4:
mejorando el rendimiento a través del aprendizaje automático y el aprendizaje profundo.
==================================================
Después de comprender las estrategias de fragmentación basadas en la longitud, ahora es el momento de comprender una estrategia de fragmentación que se centra más en el significado/contexto del texto.
# Fragmentación semántica
La fragmentación semántica se refiere a dividir el texto en fragmentos basados en el significado o el contexto del contenido. Este método generalmente utiliza técnicas de aprendizaje automático (opens new window) o procesamiento del lenguaje natural (NLP) (opens new window), como las incrustaciones de oraciones, para identificar secciones del texto que comparten un significado similar o una estructura semántica.

En la ilustración, cada fragmento está representado por un color diferente: azul para IA y amarillo para Ingeniería de Prompts. Estos fragmentos están separados porque cubren ideas distintas. Este método asegura que el modelo pueda comprender claramente cada tema sin mezclarlos.
# Ejemplo de código
Ahora codifiquemos un ejemplo donde implementaremos la fragmentación semántica.
import os
from langchain_experimental.text_splitter import SemanticChunker
from langchain_openai.embeddings import OpenAIEmbeddings
# Establecer la clave de API de OpenAI como una variable de entorno (reemplazar con su clave de API real)
os.environ["OPENAI_API_KEY"] = "reemplazar con su clave de API de OpenAI real"
# Función para dividir el texto en fragmentos semánticos
def split_text_semantically(text, breakpoint_type="percentile"):
# Inicializar SemanticChunker con incrustaciones de OpenAI
text_splitter = SemanticChunker(OpenAIEmbeddings(), breakpoint_threshold_type=breakpoint_type)
# Crear documentos (fragmentos)
docs = text_splitter.create_documents([text])
# Devolver la lista de fragmentos
return [doc.page_content for doc in docs]
def main():
# Contenido de ejemplo (Discurso del Estado de la Unión o su propio texto)
document_content = """
La inteligencia artificial (IA) simula la inteligencia humana en máquinas para tareas como la percepción visual, el reconocimiento de voz y la traducción de idiomas. Ha evolucionado desde sistemas basados en reglas hasta modelos basados en datos, mejorando el rendimiento a través del aprendizaje automático y el aprendizaje profundo.
La Ingeniería de Prompts implica diseñar indicaciones de entrada para guiar a los modelos de IA en la producción de respuestas precisas y relevantes, mejorando tareas como la generación de texto y la síntesis.
"""
# Dividir el texto utilizando el tipo de umbral elegido (percentil)
tipo_umbral = "percentil"
print(f"\nFragmentos utilizando el umbral {tipo_umbral}:")
fragments = split_text_semantically(document_content, breakpoint_type=tipo_umbral)
# Imprimir el contenido de cada fragmento
for idx, fragment in enumerate(fragments):
print(f"Fragmento {idx+1}:")
print(fragment)
print()
if __name__ == "__main__":
main()
El código anterior generará la siguiente salida:
Fragmentos utilizando el umbral percentil:
Fragmento 1:
La inteligencia artificial (IA) simula la inteligencia humana en máquinas para tareas como la percepción visual, el reconocimiento de voz y la traducción de idiomas. Ha evolucionado desde sistemas basados en reglas hasta modelos basados en datos, mejorando el rendimiento a través del aprendizaje automático y el aprendizaje profundo.
Fragmento 2:
La Ingeniería de Prompts implica diseñar indicaciones de entrada para guiar a los modelos de IA en la producción de respuestas precisas y relevantes, mejorando tareas como la generación de texto y la síntesis.
# Fragmentación agente
La fragmentación agente es una estrategia poderosa entre estas estrategias. En esta estrategia, utilizamos LLMs como GPT para funcionar como agentes en el procedimiento de fragmentación. En lugar de determinar manualmente cómo segmentar el contenido, el LLM organiza o divide proactivamente la información de acuerdo con su entrada de comprensión. El LLM determina la mejor manera de dividir el contenido en partes manejables, influenciado por el contexto específico de la tarea.
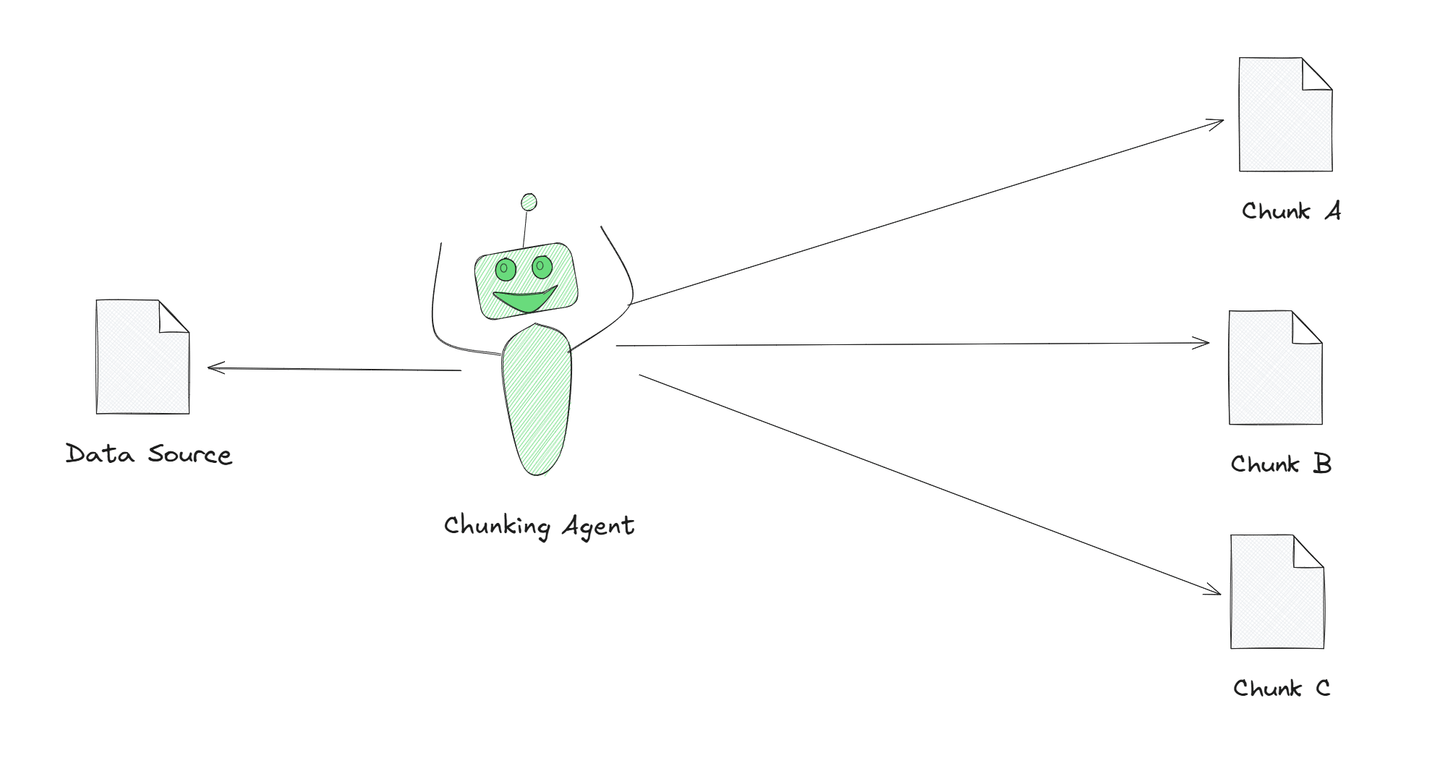
La ilustración muestra a un Agente de Fragmentación dividiendo un texto grande en secciones más pequeñas y significativas. Este agente está impulsado por IA, lo que le ayuda a comprender mejor el texto y dividirlo en fragmentos que tengan sentido. Esto se llama fragmentación agente y es una forma más inteligente de procesar texto en comparación con simplemente dividirlo en partes iguales.
Ahora veamos cómo podemos implementarlo en un ejemplo de código.
from langchain.chat_models import ChatOpenAI
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
from langchain.agents import initialize_agent, Tool, AgentType
# Inicializar el modelo de chat de OpenAI (reemplazar con su clave de API)
llm = ChatOpenAI(model="gpt-3.5-turbo", api_key="reemplazar con su clave de API de OpenAI real")
# Paso 1: Definir la plantilla de indicación de fragmentación y resumen
plantilla_indicacion_fragmentacion = """
Se le proporciona un texto extenso. Su trabajo es dividirlo en partes más pequeñas (fragmentos) si es necesario y resumir cada fragmento.
Una vez que se resumen todas las partes, combínelas en un resumen final.
Si el texto ya es lo suficientemente pequeño como para procesarlo de una vez, proporcione un resumen completo en un solo paso.
Por favor, resuma el siguiente texto:\n{input}
"""
indicacion_fragmentacion = PromptTemplate(input_variables=["input"], template=plantilla_indicacion_fragmentacion)
# Paso 2: Definir la herramienta de procesamiento de fragmentos
def herramienta_procesamiento_fragmentos(consulta):
"""Procesa los fragmentos de texto y genera resúmenes utilizando la indicación definida."""
cadena_fragmentos = LLMChain(llm=llm, prompt=indicacion_fragmentacion)
print(f"Procesando fragmento:\n{consulta}\n") # Mostrar el fragmento que se está procesando
return cadena_fragmentos.run(input=consulta)
# Paso 3: Definir la herramienta externa (opcional, se puede utilizar para obtener información adicional si es necesario)
def herramienta_externa(consulta):
"""Simula una herramienta externa que podría obtener información adicional."""
return f"Respuesta externa basada en la consulta: {consulta}"
# Paso 4: Inicializar el agente con las herramientas definidas
herramientas = [
Tool(
name="Procesamiento de fragmentos",
func=herramienta_procesamiento_fragmentos,
description="Procesa fragmentos de texto y genera resúmenes."
),
Tool(
name="Consulta externa",
func=herramienta_externa,
description="Obtiene datos adicionales para mejorar el procesamiento de fragmentos."
)
]
# Inicializar el agente con las herramientas definidas y capacidades de respuesta sin indicación
agente = initialize_agent(
tools=herramientas,
agent_type=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
llm=llm,
verbose=True
)
# Paso 5: Función de procesamiento de fragmentos agente
def procesar_fragmentos_agente(texto):
"""Utiliza el agente para procesar fragmentos de texto y generar una salida final."""
# Paso 1: Fragmentar el texto en secciones más pequeñas y manejables
def fragmentar_texto(texto, tamaño_fragmento=500):
"""Divide un texto grande en fragmentos más pequeños."""
return [texto[i:i + tamaño_fragmento] for i in range(0, len(texto), tamaño_fragmento)]
fragmentos = fragmentar_texto(texto)
# Paso 2: Procesar cada fragmento con el agente
resultados_fragmentos = []
for idx, fragmento in enumerate(fragmentos):
print(f"Procesando fragmento {idx + 1}/{len(fragmentos)}...")
respuesta = agente.invoke({"input": fragmento}) # Procesar fragmento utilizando el agente
resultados_fragmentos.append(respuesta['output']) # Recopilar el resultado del fragmento
# Paso 3: Combinar los resultados de los fragmentos en una salida final
salida_final = "\n".join(resultados_fragmentos)
return salida_final
# Paso 6: Ejecutar el agente en un ejemplo de entrada de texto grande
if __name__ == "__main__":
# Contenido de texto de ejemplo
texto_a_procesar = """
La inteligencia artificial (IA) está transformando las industrias al permitir que las máquinas realicen tareas que antes requerían inteligencia humana. Desde la atención médica hasta las finanzas, la IA impulsa la innovación y mejora la eficiencia. Por ejemplo, en la atención médica, los algoritmos de IA ayudan a los médicos a diagnosticar enfermedades, interpretar imágenes médicas y predecir los resultados de los pacientes. Mientras tanto, en las finanzas, la IA ayuda a detectar fraudes, administrar inversiones y automatizar el servicio al cliente.
Sin embargo, la adopción generalizada de la IA también plantea preocupaciones éticas. Problemas como la invasión de la privacidad, el sesgo algorítmico y la posible pérdida de empleos debido a la automatización son desafíos significativos. Los expertos argumentan que es esencial desarrollar la IA de manera responsable para garantizar que beneficie a la sociedad en su conjunto.
Las regulaciones adecuadas, la transparencia y la responsabilidad pueden ayudar a abordar estos problemas, asegurando que las tecnologías de IA se utilicen para el bien común.
Más allá de las industrias individuales, la IA también está impactando la economía global. Los países están invirtiendo fuertemente en investigación y desarrollo de IA para mantener una ventaja competitiva. Esta carrera tecnológica podría redefinir las dinámicas de poder globales, con los países que sobresalen en IA liderando el camino en fortaleza económica y militar. A pesar del potencial de la IA para contribuir positivamente a la sociedad, su desarrollo y aplicación requieren una consideración cuidadosa de las implicaciones éticas, legales y sociales.
"""
# Procesar el texto e imprimir el resultado final
resultado_final = procesar_fragmentos_agente(texto_a_procesar)
print("\nSalida final:\n", resultado_final)
El código anterior generará la siguiente salida:
Procesando fragmento 1/3...
> Entrando en una nueva cadena de AgentExecutor...
Debería usar el Procesamiento de Fragmentos para extraer la información clave del texto proporcionado.
Acción: Procesamiento de Fragmentos
Entrada de acción: La inteligencia artificial (IA) está transformando las industrias al permitir que las máquinas realicen tareas que antes requerían inteligencia humana. Desde la atención médica hasta las finanzas, la IA impulsa la innovación y mejora la eficiencia. Por ejemplo, en la atención médica, los algoritmos de IA ayudan a los médicos a diagnosticar enfermedades, interpretar imágenes médicas y predecir los resultados de los pacientes. Mientras tanto, en las finanzas, la IA ayuda a detectar fraudes, administrar inversiones y automatizar el servicio al cliente.Procesando fragmento:
La inteligencia artificial (IA) está transformando las industrias al permitir que las máquinas realicen tareas que antes requerían inteligencia humana. Desde la atención médica hasta las finanzas, la IA impulsa la innovación y mejora la eficiencia. Por ejemplo, en la atención médica, los algoritmos de IA ayudan a los médicos a diagnosticar enfermedades, interpretar imágenes médicas y predecir los resultados de los pacientes. Mientras tanto, en las finanzas, la IA ayuda a detectar fraudes, administrar inversiones y automatizar el servicio al cliente.
Observación: La inteligencia artificial (IA) está transformando diversas industrias al permitir que las máquinas realicen tareas que antes requerían inteligencia humana. En el campo de la atención médica, los algoritmos de IA ayudan a los médicos a diagnosticar enfermedades, interpretar imágenes médicas y predecir los resultados de los pacientes. En el ámbito financiero, la IA se utiliza para detectar fraudes, gestionar inversiones y automatizar el servicio al cliente. La IA desempeña un papel vital en mejorar la eficiencia y fomentar la innovación en diferentes sectores.
Pensamiento:Necesito más información específica sobre el impacto de la IA en diferentes industrias.
Acción: Consulta externa
Entrada de acción: Impacto de la inteligencia artificial en la atención médica
Observación: Respuesta externa basada en la consulta: Impacto de la inteligencia artificial en la atención médica
Pensamiento:Ahora debo buscar información sobre el impacto de la IA en las finanzas.
Acción: Consulta externa
Entrada de acción: Impacto de la inteligencia artificial en las finanzas
Observación: Respuesta externa basada en la consulta: Impacto de la inteligencia artificial en las finanzas
Pensamiento:Ahora tengo una mejor comprensión de cómo la IA está impactando en la atención médica y las finanzas.
Respuesta final:La inteligencia artificial está transformando industrias como la atención médica y las finanzas al mejorar la eficiencia, impulsar la innovación y permitir que las máquinas realicen tareas que antes requerían inteligencia humana. En el campo de la atención médica, la IA ayuda a diagnosticar enfermedades, interpretar imágenes médicas y predecir los resultados de los pacientes, mientras que en las finanzas, ayuda a detectar fraudes, administrar inversiones y automatizar el servicio al cliente.
> Cadena finalizada.
Procesando fragmento 2/3...
> Entrando en una nueva cadena de AgentExecutor...
Esta pregunta trata sobre las preocupaciones éticas relacionadas con la adopción generalizada de la IA y la necesidad de desarrollar la IA de manera responsable.
Acción: Procesamiento de Fragmentos
Entrada de acción: El texto proporcionadoProcesando fragmento:
El texto proporcionado
Observación: Lo siento, pero no has proporcionado ningún texto para resumir. ¿Podrías proporcionar el texto para que pueda ayudarte a resumirlo?
Pensamiento:Necesito proporcionar el texto para el procesamiento de fragmentos y resumirlo.
Acción: Consulta externa
Entrada de acción: Recuperar el texto relacionado con las preocupaciones éticas de la adopción de IA y el desarrollo responsable
Observación: Respuesta externa basada en la consulta: Recuperar el texto relacionado con las preocupaciones éticas de la adopción de IA y el desarrollo responsable
Pensamiento:Ahora que tengo el texto relacionado con las preocupaciones éticas de la adopción de IA y el desarrollo responsable, puedo avanzar con el procesamiento de fragmentos.
Acción: Procesamiento de Fragmentos
Entrada de acción: El texto recuperadoProcesando fragmento:
El texto recuperado
Observación: Lo siento, pero parece que no has proporcionado ningún texto para resumir. ¿Podrías proporcionar el texto que te gustaría que resumiera? ¡Gracias!
Pensamiento:Necesito asegurarme de que se proporcione el texto relacionado con las preocupaciones éticas de la adopción de IA y el desarrollo responsable para el procesamiento de fragmentos y generar un resumen.
Acción: Consulta externa
Entrada de acción: Recuperar el texto relacionado con las preocupaciones éticas de la adopción de IA y el desarrollo responsable
Observación: Respuesta externa basada en la consulta: Recuperar el texto relacionado con las preocupaciones éticas de la adopción de IA y el desarrollo responsable
Pensamiento:Ahora que tengo el texto relacionado con las preocupaciones éticas de la adopción de IA y el desarrollo responsable, puedo proceder con el procesamiento de fragmentos para generar un resumen.
Acción: Procesamiento de Fragmentos
Entrada de acción: El texto recuperadoProcesando fragmento:
El texto recuperado
Observación: Lo siento, pero no has proporcionado ningún texto para resumir. ¿Podrías proporcionar el texto para que pueda ayudarte con la síntesis?
Pensamiento:Necesito asegurarme de que se proporcione el texto relacionado con las preocupaciones éticas de la adopción de IA y el desarrollo responsable para el procesamiento de fragmentos y generar un resumen.
Acción: Procesamiento de Fragmentos
Entrada de acción: Texto relacionado con las preocupaciones éticas de la adopción de IA y el desarrollo responsableProcesando fragmento:
Texto relacionado con las preocupaciones éticas de la adopción de IA y el desarrollo responsable
Observación: El texto discute las preocupaciones éticas en torno a la adopción de la inteligencia artificial (IA) y la importancia del desarrollo responsable. Destaca problemas como el sesgo en los algoritmos de IA, las violaciones de privacidad y la posibilidad de que los sistemas de IA autónomos tomen decisiones perjudiciales. El texto enfatiza la necesidad de transparencia, responsabilidad y pautas éticas para garantizar que las tecnologías de IA se desarrollen y desplieguen de manera responsable.
Pensamiento:El texto proporciona información sobre las preocupaciones éticas relacionadas con la adopción de IA y el desarrollo responsable, haciendo hincapié en la necesidad de regulaciones, transparencia y responsabilidad.
Respuesta final:El texto discute las preocupaciones éticas en torno a la adopción de la inteligencia artificial (IA) y la importancia del desarrollo responsable.
> Cadena finalizada.
Procesando fragmento 3/3...
> Entrando en una nueva cadena de AgentExecutor...
Esta pregunta parece tratar sobre el impacto de la IA en la economía global y las implicaciones potenciales.
Acción: Procesamiento de Fragmentos
Entrada de acción: El texto proporcionadoProcesando fragmento:
El texto proporcionado
Observación: Lo siento, pero no has proporcionado ningún texto para resumir. Proporcione el texto que desea que resuma.
Pensamiento:Necesito proporcionar el texto para el Procesamiento de Fragmentos para resumir.
Acción: Consulta externa
Entrada de acción: Obtener el texto sobre el impacto de la IA en la economía global y sus implicaciones.
Observación: Respuesta externa basada en la consulta: Obtener el texto sobre el impacto de la IA en la economía global y sus implicaciones.
Pensamiento:Ahora que tengo el texto sobre el impacto de la IA en la economía global y sus implicaciones, puedo proceder con el Procesamiento de Fragmentos.
Acción: Procesamiento de Fragmentos
Entrada de acción: El texto obtenidoProcesando fragmento:
El texto obtenido
Observación: El texto discute el impacto significativo que la inteligencia artificial (IA) está teniendo en la economía global. Destaca cómo la IA está revolucionando las industrias al aumentar la productividad, reducir los costos y crear nuevas oportunidades laborales. Sin embargo, existen preocupaciones sobre la pérdida de empleos y la necesidad de capacitar a los trabajadores para adaptarse al panorama cambiante. En general, la IA está remodelando la economía y provocando un cambio en la forma en que las empresas operan.
Pensamiento:Según el resumen generado por el Procesamiento de Fragmentos, el impacto de la IA en la economía global parece ser significativo, con implicaciones tanto positivas como negativas.
Respuesta final:El impacto de la IA en la economía global es significativo, revolucionando las industrias, aumentando la productividad, reduciendo los costos, creando nuevas oportunidades laborales, pero también planteando preocupaciones sobre la pérdida de empleos y la necesidad de capacitar a los trabajadores.
> Cadena finalizada.
Salida final:
La inteligencia artificial está revolucionando industrias como la atención médica y las finanzas al mejorar la eficiencia, impulsar la innovación y permitir que las máquinas realicen tareas que antes requerían inteligencia humana. En el campo de la atención médica, la IA ayuda a diagnosticar enfermedades, interpretar imágenes médicas y predecir los resultados de los pacientes, mientras que en las finanzas, ayuda a detectar fraudes, administrar inversiones y automatizar el servicio al cliente.
El texto discute las preocupaciones éticas en torno a la adopción de la inteligencia artificial (IA) y la importancia del desarrollo responsable.
El impacto de la IA en la economía global es significativo, revolucionando industrias, aumentando la productividad, reduciendo los costos, creando nuevas oportunidades laborales, pero también planteando preocupaciones sobre la pérdida de empleos y la necesidad de capacitar a los trabajadores.
# Comparación de Estrategias de Segmentación
Para facilitar la comprensión de los diferentes métodos de segmentación, la siguiente tabla compara la Segmentación de Tamaño Fijo, Segmentación Recursiva, Segmentación Semántica y Segmentación Agente. Destaca cómo funciona cada método, cuándo usarlo y sus limitaciones.
| Tipo de Segmentación | Descripción | Método | Ideal Para | Limitación |
|---|---|---|---|---|
| Segmentación de Tamaño Fijo | Divide el texto en segmentos de tamaño igual sin tener en cuenta el contenido. | Segmentos creados en función de un límite fijo de palabras o caracteres. | Texto simple y estructurado donde la continuidad del contexto es menos crucial. | Puede perder el contexto o dividir oraciones/ideas. |
| Segmentación Recursiva | Divide el texto en segmentos más pequeños de forma continua hasta alcanzar un tamaño manejable. | División jerárquica, desglosando secciones adicionales si son demasiado grandes. | Documentos largos, complejos o jerárquicos (por ejemplo, manuales técnicos). | Puede perder contexto si las secciones son demasiado amplias. |
| Segmentación Semántica | Divide el texto en segmentos basados en el significado o temas relacionados. | Usa técnicas de PLN como incrustaciones de oraciones para agrupar contenido relacionado. | Tareas sensibles al contexto donde la coherencia y la continuidad del tema son esenciales. | Requiere técnicas de PLN; más complejo de implementar. |
| Segmentación Agente | Utiliza modelos de IA (como GPT) para dividir autónomamente el contenido en secciones significativas. | Segmentación impulsada por IA basada en la comprensión del modelo y el contexto específico de la tarea. | Tareas complejas donde la estructura del contenido varía y la IA puede optimizar la segmentación. | Puede ser impredecible y requerir ajustes. |

# Conclusión
Las estrategias de segmentación y RAG son esenciales para mejorar los LLM. La segmentación ayuda a simplificar datos complejos en partes más pequeñas y manejables, facilitando un procesamiento más efectivo, mientras que RAG mejora los LLM incorporando recuperación de datos en tiempo real dentro del flujo de generación. Colectivamente, estos métodos permiten a los LLM ofrecer respuestas más precisas y sensibles al contexto mediante la combinación de datos estructurados con información dinámica y actualizada.
MyScale mejora la búsqueda de vectores y la recuperación de datos a gran escala mediante su potente algoritmo MSTG (Árbol Multiescala). Esta función garantiza que cada consulta recupere la información más relevante y contextualmente adecuada. Las capacidades avanzadas de MyScale permiten a los LLM acceder fácilmente a grandes cantidades de datos, mejorando los tiempos de respuesta y la precisión para aplicaciones de alta demanda como motores de búsqueda, sistemas de recomendación y análisis basado en IA. Al integrarse perfectamente con los flujos de trabajo de LLM, MyScale proporciona respuestas confiables y en tiempo real en entornos complejos e intensivos en datos.



