
Este artículo fue publicado originalmente en The New Stack (opens new window)
Los Modelos de Lenguaje Grandes (LLMs, por sus siglas en inglés) son lo suficientemente inteligentes como para entender el contexto. Pueden responder preguntas, aprovechando sus vastos datos de entrenamiento para proporcionar respuestas coherentes y contextualmente relevantes, sin importar si el tema es astronomía, historia o incluso física. Sin embargo, debido a su incapacidad para conectar los puntos y recordar todos los detalles, los LLMs, especialmente los modelos más pequeños como llama2-13b-chat, pueden alucinar incluso cuando el conocimiento solicitado está en los datos de entrenamiento.
Una nueva técnica, Generación Mejorada por Recuperación (RAG, por sus siglas en inglés), llena los vacíos de conocimiento, reduciendo las alucinaciones al agregar estímulos con datos externos. Combinado con una base de datos vectorial (como MyScale (opens new window)), aumenta sustancialmente la ganancia de rendimiento en sistemas de preguntas y respuestas extractivas, incluso con bases de conocimiento exhaustivas como Wikipedia en el conjunto de entrenamiento.
Con este fin, este artículo se centra en determinar la ganancia de rendimiento con RAG en el ampliamente utilizado conjunto de datos MMLU. Descubrimos que tanto el rendimiento de los LLMs comerciales como los de código abierto pueden mejorarse significativamente cuando se puede recuperar conocimiento de Wikipedia utilizando una base de datos vectorial. Más interesante aún, este resultado se logra incluso cuando Wikipedia ya está en el conjunto de entrenamiento de estos modelos.
Puedes encontrar el código del marco de referencia y este ejemplo aquí (opens new window).
# Generación Mejorada por Recuperación
Pero primero, describamos la Generación Mejorada por Recuperación (RAG).
Los proyectos de investigación tienen como objetivo mejorar los LLMs como gpt-3.5 acoplándolos con bases de conocimiento externas (como Wikipedia), bases de datos o Internet para crear sistemas más conocedores y contextualmente conscientes. Por ejemplo, supongamos que un usuario le pregunta a un LLM cuál es el resultado más importante de Newton. Para ayudar al LLM a recuperar la información correcta, podemos buscar la página de Wikipedia de Newton y proporcionarla como contexto al LLM.
Este método se llama Generación Mejorada por Recuperación (RAG). Lewis et al. en Retrieval Augmented Generation for Knowledge-Intensive NLP Tasks (opens new window) definen la Generación Mejorada por Recuperación de la siguiente manera:
"Un tipo de modelo de generación de lenguaje que combina memoria paramétrica y no paramétrica preentrenada para la generación de lenguaje."
Además, los autores de este artículo académico continúan afirmando que:
"Dotan a los modelos de generación con memoria paramétrica preentrenada de una memoria no paramétrica a través de un enfoque de ajuste fino de propósito general."
Nota:
Los LLMs con memoria paramétrica son repositorios de conocimiento masivos y autosuficientes como ChatGPT y PaLM de Google. Los LLMs con memoria no paramétrica aprovechan recursos externos que agregan contexto adicional a los LLMs con memoria paramétrica.
Combinar recursos externos con LLMs parece factible ya que los LLMs son buenos aprendices, y hacer referencia a dominios de conocimiento externos específicos puede mejorar la veracidad. Pero ¿cuánta mejora puede proporcionar esta combinación?
Dos factores principales afectan a un sistema RAG:
- Cuánto puede aprender un LLM del contexto externo
- Cuán precisa y relevante es la información externa
Ambos factores son difíciles de evaluar. El conocimiento adquirido por el LLM a partir del contexto es implícito, por lo que la forma más práctica de evaluar estos factores es examinar la respuesta del LLM. Sin embargo, la precisión del contexto recuperado también es difícil de evaluar.
Medir la relevancia entre párrafos, especialmente en preguntas y respuestas o recuperación de información, puede ser una tarea compleja. La evaluación de relevancia es crucial para determinar si una sección dada contiene información directamente relacionada con una pregunta específica. Esto es especialmente importante en tareas que implican extraer información de conjuntos de datos o documentos grandes, como el conjunto de datos WikiHop (opens new window).
A veces, los conjuntos de datos emplean múltiples anotadores para evaluar la relevancia entre párrafos y preguntas. El uso de múltiples anotadores para votar sobre la relevancia ayuda a mitigar la subjetividad y los posibles sesgos que pueden surgir de los anotadores individuales. Este método también agrega una capa de consistencia y garantiza que el juicio de relevancia sea más confiable.
Como consecuencia de todas estas incertidumbres, hemos desarrollado una evaluación integral de extremo a extremo del sistema RAG de código abierto. Esta evaluación considera diferentes configuraciones de modelos, tuberías de recuperación, elecciones de bases de conocimiento y algoritmos de búsqueda.
Nuestro objetivo es proporcionar líneas de base valiosas para el diseño de sistemas RAG y esperamos que más desarrolladores e investigadores se unan a nosotros para construir un marco de referencia completo y sistemático. Más resultados nos ayudarán a desentrañar estos dos factores y crear un conjunto de datos más cercano a los sistemas RAG del mundo real.
Nota:
Comparte tus resultados de evaluación en GitHub (opens new window). ¡Se agradecen las solicitudes de extracción!
# Una Línea de Base Simple de Extremo a Extremo para un Sistema RAG
![]()
En este artículo, nos centramos en una línea de base simple evaluada en un Conjunto de Datos MMLU (Comprensión de Lenguaje Multitarea Masiva) (opens new window), un referente ampliamente utilizado para LLMs (opens new window), que contiene preguntas de opción múltiple con una sola respuesta sobre muchos temas como historia, astronomía y economía.
Nos propusimos descubrir si un LLM puede aprender de contextos adicionales al responder preguntas de opción múltiple.
Para lograr nuestro objetivo, elegimos Wikipedia como nuestra fuente de verdad porque cubre muchos temas y dominios de conocimiento. Y utilizamos la versión limpiada por Cohere.ai (opens new window) en Hugging Face, que incluye 34,879,571 párrafos pertenecientes a 5,745,033 títulos. Una búsqueda exhaustiva en estos párrafos llevaría bastante tiempo, por lo que necesitamos utilizar los algoritmos de búsqueda de vecinos más cercanos aproximados (ANNS, por sus siglas en inglés) adecuados para recuperar documentos relevantes. Además, utilizamos la base de datos MyScale con el índice vectorial MSTG para recuperar los documentos relevantes.
# Modelo de Búsqueda Semántica
La búsqueda semántica es un tema bien investigado con muchos modelos (opens new window) con detalladas comparativas (opens new window) disponibles. Cuando se incorpora con incrustaciones vectoriales, la búsqueda semántica adquiere la capacidad de reconocer expresiones parafraseadas, sinónimos y comprensión contextual.
Además, las incrustaciones proporcionan representaciones vectoriales densas y continuas que permiten el cálculo de métricas significativas de relevancia. Estas métricas densas capturan relaciones semánticas y contexto, lo que las hace valiosas para evaluar la relevancia en tareas de recuperación de información de LLMs.
Teniendo en cuenta los factores mencionados anteriormente, hemos decidido utilizar el modelo paraphrase-multilingual-mpnet-base-v2 (opens new window) de Hugging Face para extraer características para tareas de recuperación. Este modelo es parte de la familia MPNet, diseñada para generar incrustaciones de alta calidad adecuadas para varias tareas de procesamiento de lenguaje natural, incluyendo similitud semántica y recuperación.
# Modelos de Lenguaje Grandes (LLMs)
Para nuestros LLMs, elegimos gpt-3.5-turbo y llama2-13b-chat de OpenAI con cuantización en 6 bits. Estos modelos son los más populares en las tendencias comerciales y de código abierto. El modelo LLaMA2 está cuantizado por llama.cpp (opens new window). Elegimos esta configuración de cuantización de 6 bits porque es asequible sin sacrificar el rendimiento.
Nota:
También puedes probar otros modelos para evaluar su rendimiento RAG.
# Nuestro Sistema RAG
La siguiente imagen describe cómo formular un sistema RAG simple:
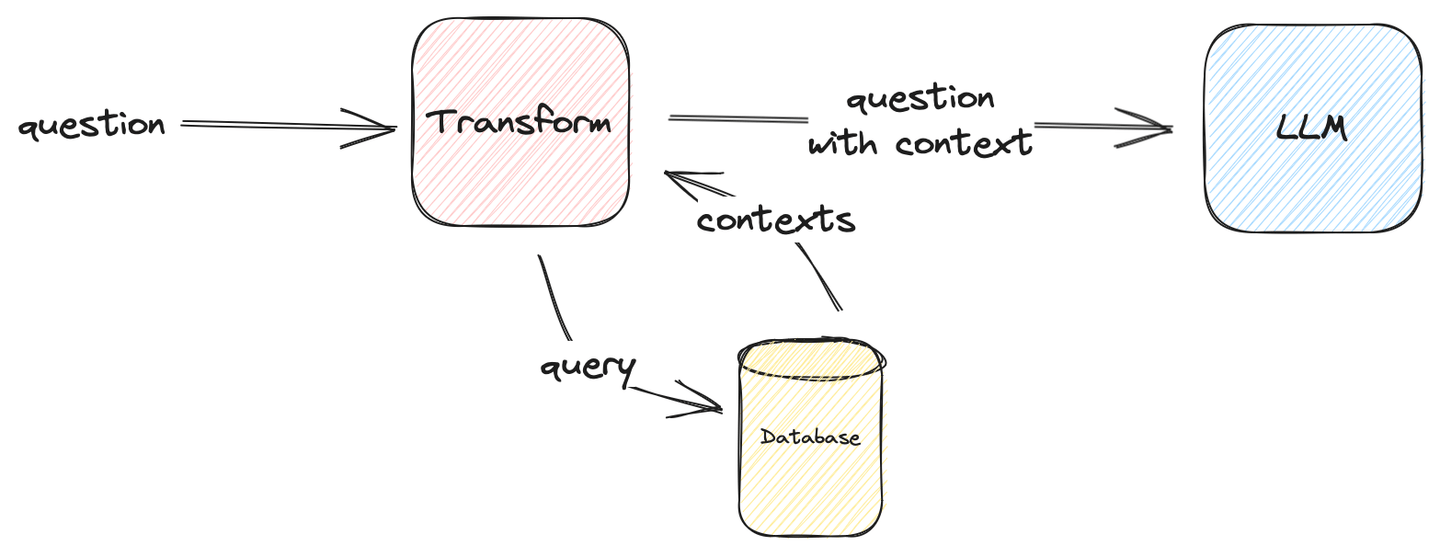
Figura 1: Evaluación simple de RAG
Nota:
La transformación puede ser cualquier cosa siempre que pueda ser alimentada al LLM y devuelva la respuesta correcta. En nuestro caso de uso, la transformación inyecta contexto a la pregunta.
Nuestro estímulo final del LLM es el siguiente:
template = \
("The following are multiple choice questions (with answers) with context:"
"\n\n{context}Question: {question}\n{choices}Answer: ")
¡Ahora pasemos al resultado!
# Varias Ideas de Evaluación
Nuestros resultados de prueba de referencia se recopilan en la Tabla 1 a continuación.
Pero primero, nuestros hallazgos resumidos son:
- El Contexto Adicional Ayuda en General
- A veces, Más Contexto Ayuda
- Los Modelos Más Pequeños Tienen Más Hambre de Conocimiento
Tabla 1: Precisión de Recuperación con Diferentes Contextos
| Configuración | Conjunto de Datos | Promedio | |||||
|---|---|---|---|---|---|---|---|
| LLM | Contextos | mmlu-astronomía | mmlu-prehistoria | mmlu-hechos-globales | mmlu-medicina-universitaria | mmlu-conocimiento-clínico | |
| gpt-3.5-turbo | ❌ | 71.71% | 70.37% | 38.00% | 67.63% | 74.72% | 68.05% |
| ✅ (Top-1) | 75.66% (+3.95%) | 78.40% (+8.03%) | 46.00% (+8.00%) | 67.05% (-0.58%) | 73.21% (-1.51%) | 71.50% (+3.45%) | |
| ✅ (Top-3) | 76.97% (+5.26%) | 81.79% (+11.42%) | 48.00% (+10.00%) | 65.90% (-1.73%) | 73.96% (-0.76%) | 72.98% (+4.93%) | |
| ✅ (Top-5) | 78.29% (+6.58%) | 79.63% (+9.26%) | 42.00% (+4.00%) | 68.21% (+0.58%) | 74.34% (-0.38%) | 72.39% (+4.34%) | |
| ✅ (Top-10) | 78.29% (+6.58%) | 79.32% (+8.95%) | 44.00% (+6.00%) | 71.10% (+3.47%) | 75.47% (+0.75%) | 73.27% (+5.22%) | |
| llama2-13b-chat-q6_0 | ❌ | 53.29% | 57.41% | 33.00% | 44.51% | 50.19% | 50.30% |
| ✅ (Top-1) | 58.55% (+5.26%) | 61.73% (+4.32%) | 45.00% (+12.00%) | 46.24% (+1.73%) | 54.72% (+4.53%) | 55.13% (+4.83%) | |
| ✅ (Top-3) | 63.16% (+9.87%) | 63.27% (+5.86%) | 49.00% (+16.00%) | 46.82% (+2.31%) | 55.85% (+5.66%) | 57.10% (+6.80%) | |
| ✅ (Top-5) | 63.82% (+10.53%) | 65.43% (+8.02%) | 51.00% (+18.00%) | 51.45% (+6.94%) | 57.74% (+7.55%) | 59.37% (+9.07%) | |
| ✅ (Top-10) | 65.13% (+11.84%) | 66.67% (+9.26%) | 46.00% (+13.00%) | 49.71% (+5.20%) | 57.36% (+7.17%) | 59.07% (+8.77%) | |
| * La evaluación utiliza MyScale MSTG como índice vectorial * Esta evaluación se puede reproducir con nuestro repositorio de GitHub retrieval-qa-benchmark | |||||||
# 1. El Contexto Adicional Ayuda en General
En estas pruebas de referencia, comparamos el rendimiento con y sin contexto. La prueba sin contexto representa cómo el conocimiento interno puede resolver preguntas. En segundo lugar, la prueba con contexto muestra cómo un LLM puede aprender del contexto.
Nota:
Tanto llama2-13b-chat como gpt-3.5-turbo mejoran en general alrededor del 3-5%, incluso con un solo contexto adicional.
La tabla informa que algunos números son negativos, por ejemplo, cuando insertamos contexto en conocimiento-clínico en gpt-3.5-turbo.
Esto podría estar relacionado con la base de conocimiento, diciendo que Wikipedia no tiene mucha información sobre conocimiento clínico o porque los términos de uso y las pautas de OpenAI son claros en que el uso de sus modelos de IA para consejos médicos está fuertemente desaconsejado e incluso puede estar prohibido. A pesar de esto, el aumento es bastante evidente para ambos modelos.
Es especialmente notable que los resultados de gpt-3.5-turbo sugieren que el sistema RAG podría ser lo suficientemente potente como para competir con otros modelos de lenguaje. Algunos de los números reportados, como los de prehistoria y astronomía, se acercan al rendimiento de gpt4 con tokens adicionales, lo que sugiere que RAG podría ser otra solución para la Inteligencia Artificial General (AGI) especializada en comparación con el ajuste fino.
Nota:
RAG es más práctico que los modelos de ajuste fino, ya que es una solución plug-in y funciona tanto con modelos autohospedados como remotos.
# 2. A veces, Más Contexto Ayuda
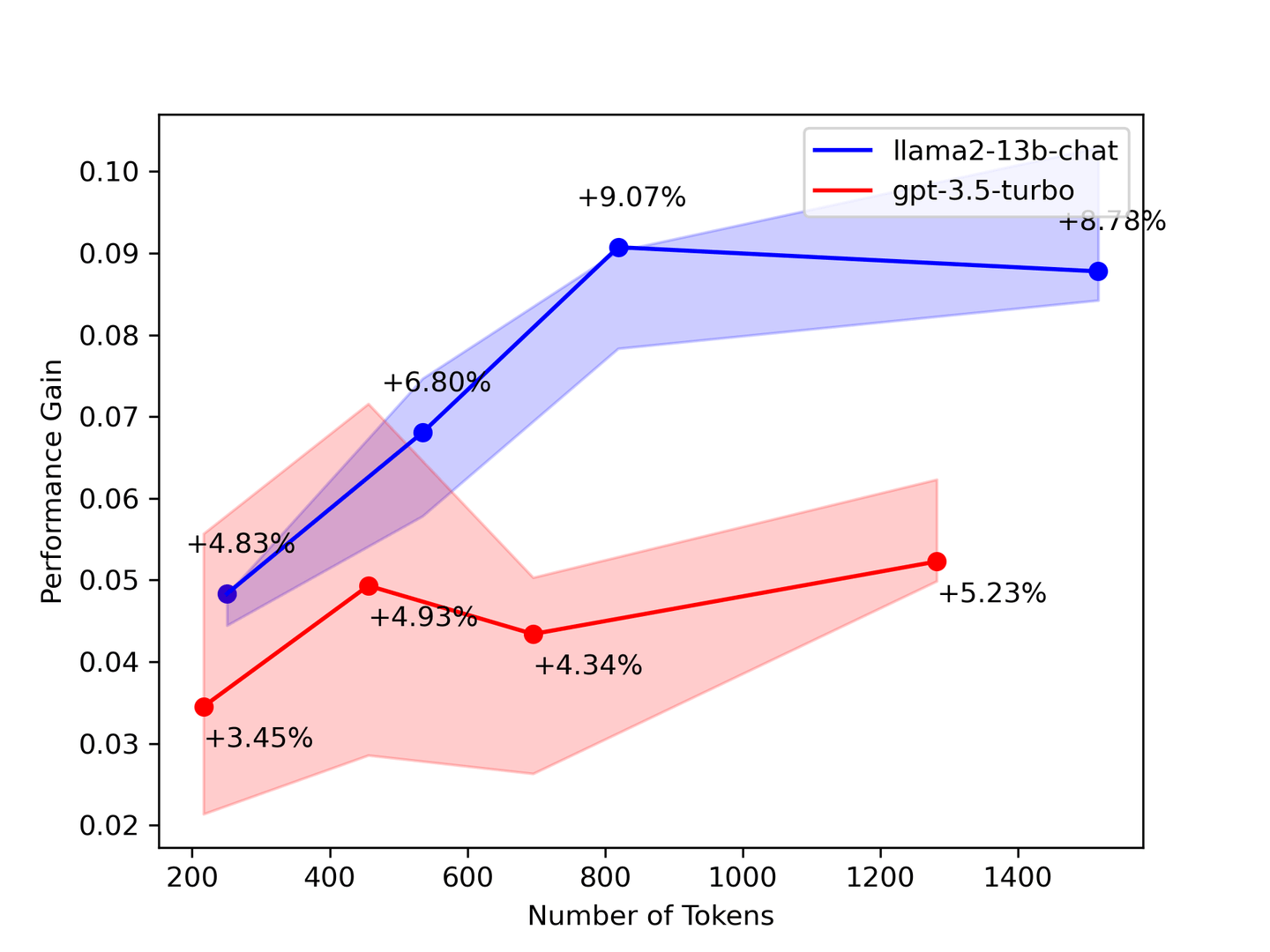
Figura 2: Aumento de Rendimiento vs. Número de Contextos
La prueba de referencia anterior sugiere que necesitas tanto contexto como sea posible. En la mayoría de los casos, los LLMs aprenderán de todos los contextos proporcionados. Teóricamente, el modelo proporciona mejores respuestas a medida que se aumenta el número de documentos recuperados. Sin embargo, nuestra prueba de referencia muestra que algunos números disminuyeron a medida que se recuperaron más contextos.
Para validar nuestros resultados de prueba de referencia, un artículo de la Universidad de Stanford titulado: "Lost in the Middle: How Language Models Use Long Contexts" (opens new window) sugiere que el LLM solo mira la cabeza y la cola del contexto. Por lo tanto, elige menos contextos pero más precisos del sistema de recuperación para mejorar tu LLM.
# 3. Los Modelos Más Pequeños Tienen Más Hambre de Conocimiento
Cuanto más grande sea el LLM, más conocimiento almacenará. Los LLMs más grandes tienden a tener una mayor capacidad para almacenar y comprender información, lo que a menudo se traduce en una base de conocimiento más amplia de hechos generalmente entendidos. Nuestras pruebas de referencia cuentan la misma historia: los LLMs más pequeños carecen de conocimiento y tienen más hambre de conocimiento.
Nuestros resultados informan que llama2-13b-chat muestra un aumento de conocimiento más significativo que gpt-3.5-turbo, lo que sugiere que el contexto inyecta más conocimiento en un LLM para la recuperación de información. Además, estos resultados implican que gpt-3.5-turbo recibió información que ya conocía mientras que llama2-13b-chat todavía está aprendiendo del contexto.
# Por Último, Pero No Menos Importante...
Casi todos los LLMs utilizan el corpus de Wikipedia como conjunto de datos de entrenamiento, lo que significa que tanto gpt-3.5-turbo como llama2-13b-chat deberían estar familiarizados con los contextos agregados al estímulo. Por lo tanto, las preguntas que surgen son:
- ¿Cuál es la razón de los aumentos en esta prueba de referencia?
- ¿El LLM realmente está aprendiendo utilizando los contextos suministrados?
- ¿O estos contextos adicionales ayudan a recordar los recuerdos aprendidos de los datos del conjunto de entrenamiento?
Actualmente no tenemos respuestas a estas preguntas. Como resultado, todavía se necesita investigación.

# Contribuyendo a Construir un Marco de Referencia RAG Juntos
Contribuye a la investigación para ayudar a los demás.
Solo podemos cubrir un conjunto limitado de evaluaciones en este blog. Pero sabemos que se necesita más. Los resultados de cada prueba de referencia son importantes, independientemente de si son réplicas de pruebas existentes o nuevos hallazgos basados en RAGs novedosos.
Con el objetivo de ayudar a todos a crear pruebas de referencia para probar sus sistemas RAG, hemos abierto el código fuente de nuestro marco de referencia de evaluación de extremo a extremo (opens new window). ¡Puedes bifurcar nuestro repositorio, echa un vistazo a nuestra página de GitHub!
Este marco de referencia incluye las siguientes herramientas:
- Un perfilador universal que puede medir el consumo de tiempo de tu recuperación y generación de LLM.
- Un motor de ejecución de gráficos que te permite construir una tubería de recuperación compleja.
- Una configuración unificada donde puedes escribir todas tus configuraciones de experimentos en un solo lugar.
Depende de ti crear tu propia prueba de referencia. Creemos que RAG puede ser una solución posible para AGI. Por lo tanto, construimos este marco de referencia para que la comunidad pueda hacer que todo sea rastreable y reproducible.
¡Se agradecen las solicitudes de extracción!
# En Conclusión
Hemos evaluado un pequeño subconjunto de MMLU con un sistema RAG simple construido con diferentes LLMs y algoritmos de búsqueda vectorial, y hemos descrito nuestro proceso y resultados en este artículo. También hemos donado el marco de referencia de evaluación a la comunidad y hemos llamado a más pruebas de referencia de RAG. Continuaremos realizando pruebas de referencia y actualizando los últimos resultados en GitHub y en el blog de MyScale, así que síguenos en Twitter (opens new window) o únete a nosotros en Discord (opens new window) para mantenerte actualizado.



