
El primer paso de RAG es recuperar varios documentos por consulta y, a menudo, estos documentos no son relevantes para la consulta. Por lo tanto, necesitamos algunas técnicas externas para mejorar estos resultados. Al final, una búsqueda es tan poderosa como la relevancia de sus resultados.
Al aplicar la búsqueda vectorial, es común perder cierta información semántica por varias razones. Por ejemplo, los documentos deben descomponerse en subdocumentos más pequeños, lo que puede resultar en una pérdida de información contextual. En consecuencia, los modelos de RAG pueden tener dificultades para conectar eficazmente la información en varios documentos recuperados. [1]
Para abordar estos desafíos, empleamos técnicas de reordenamiento de documentos dentro del marco de RAG. Hay una variedad de métodos que se pueden utilizar para reordenar los documentos recuperados.
# ¿Qué es el reordenamiento de documentos?
A medida que el campo de RAG continúa evolucionando, el papel del reordenamiento ha surgido como un componente crítico para desbloquear todo el potencial de RAG. El reordenamiento es más que una simple reorganización de los resultados recuperados: es un proceso estratégico que puede mejorar significativamente la relevancia, diversidad y personalización de la información presentada a los usuarios.
Al aprovechar señales y heurísticas adicionales, la etapa de reordenamiento de RAG puede refinar la recuperación inicial de documentos, asegurando que los datos más pertinentes y valiosos se destaquen. Además, el reordenamiento permite un enfoque iterativo, refinando progresivamente los resultados para obtener salidas cada vez más precisas y contextuales.
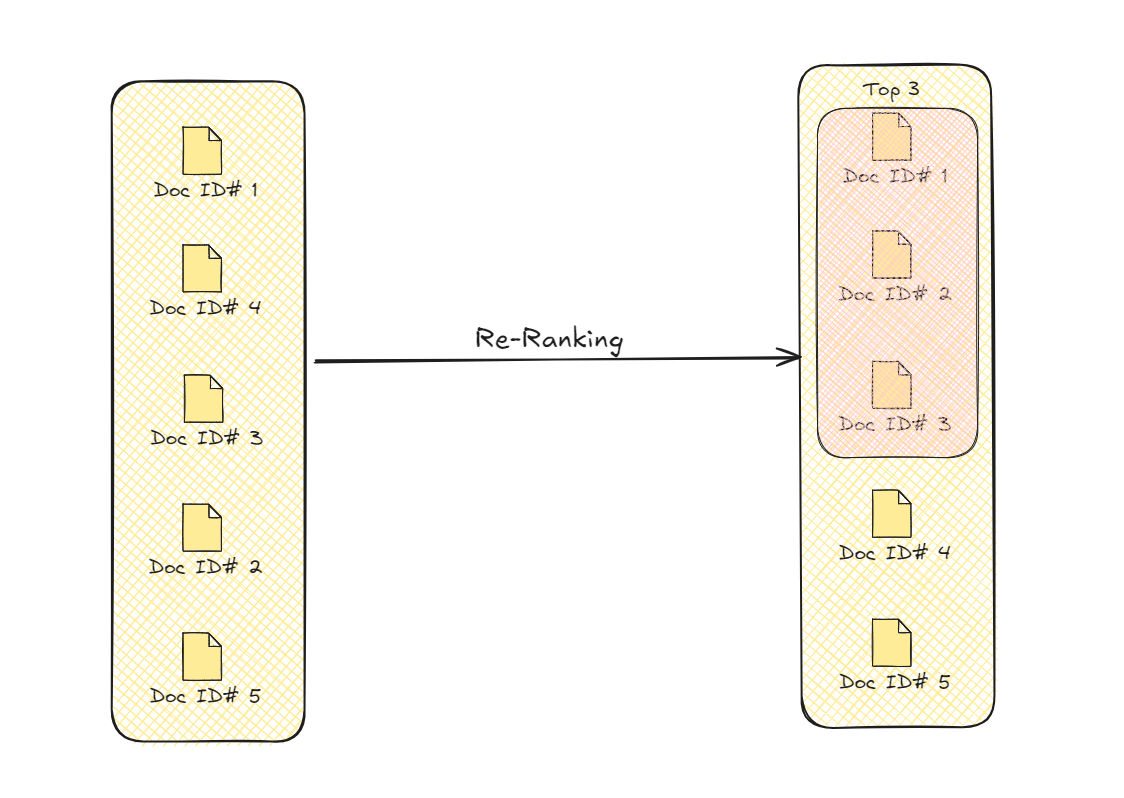
Reordenamiento de documentos
Este proceso mejora los resultados de recuperación al priorizar los documentos que son más apropiados contextualmente para la consulta. Esta selección mejorada mejora la calidad y precisión general de la información que el modelo utiliza para generar su salida final.
# Reordenamiento con Transformers
El uso de modelos de transformers para el reordenamiento de documentos tiene una historia que va más allá de los RAG. En 2020, los investigadores adaptaron un transformer preentrenado (seq2seq) para el reordenamiento de documentos. [2] Este sistema toma un documento como entrada y devuelve si es relevante o no. Después de filtrar los documentos relevantes (es decir, etiquetados como "verdaderos"), los reordenaron utilizando Softmax como función de probabilidad.
::: nota Nota: Dado que estos modelos de secuencia a secuencia también devuelven una secuencia, se modificaron para devolver solo "verdadero" o "falso". :::
# Uso de LLMs
El uso de las capacidades de LLMs para mejorar RAG se está volviendo común en estos días [4-7].
En un enfoque, los investigadores utilizaron GPT-3 [4] para realizar el reordenamiento utilizando solo indicaciones y lo llamaron LRL (Reordenador de lista utilizando LLM, por sus siglas en inglés) (https://github.com/gangiswag/llm-reranker). La indicación que utilizaron fue bastante simple.

Documentos reordenados y ordenados
Para aumentar la confianza en la relevancia del documento, también se utilizó una indicación para la clasificación y se llamó PRL (Reordenador de punto con un LLM) (https://github.com/ielab/llm-rankers/blob/main/llmrankers/pointwise.py).

Reordenamiento con LLMs
En un enfoque más metodológico [5], se utiliza LLaMA para el reordenamiento de documentos. Este método (RankLLaMA) (https://huggingface.co/castorini/rankllama-v1-7b-lora-doc) aplica la función de clasificación a los documentos recuperados de la siguiente manera:
Después de aplicar la función de reordenamiento, lo optimizamos aún más utilizando la pérdida de InfoNCE (que ya hemos visto antes en MoCo para el aprendizaje contrastivo (opens new window)).
# Uso de codificadores cruzados
Los codificadores cruzados son otro tipo de transformers que se utilizan comúnmente para el reordenamiento de documentos. Como su nombre indica, el codificador cruzado codifica tanto la consulta como (cada) documento y su salida muestra la similitud/relevancia cruzada entre los dos.

Reordenamiento con codificadores cruzados
Como se puede ver, no es factible hacer coincidir cada documento con la consulta, por lo que seleccionamos los documentos más relevantes para hacer coincidir cruzadamente. Hay dos métodos comúnmente utilizados para la preselección:
- Utilizando bi-codificadores
- Utilizando métodos de búsqueda dispersa (como BM25)
Los codificadores cruzados (opens new window) han demostrado un mejor rendimiento que los bi-codificadores (opens new window) incluso antes de ser utilizados en RAG debido a su mayor precisión y mejor comprensión contextual. [6] No es sorprendente que ahora se utilicen ampliamente en el reordenamiento de documentos para RAG. Aquí hay una implementación básica utilizando HuggingFace (opens new window) y PyTorch (opens new window).
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import torch
tokenizer = AutoTokenizer.from_pretrained("cross-encoder/ms-marco-TinyBERT-L-6")
model = AutoModelForSequenceClassification.from_pretrained("cross-encoder/ms-marco-TinyBERT-L-6")
def ReRank(query, documents):
scores = []
for doc in documents:
inputs = tokenizer(query, doc, return_tensors="pt", padding=True, truncation=True, max_length=512)
with torch.no_grad():
outputs = model(**inputs)
scores.append(outputs.logits.squeeze().item())
rankedDocs = [doc for _, doc in sorted(zip(scores, documents), reverse=True)]
return rankedDocs
Para una consulta de muestra, podemos usarlo de la siguiente manera:
query = "¿En qué mes es más adecuado visitar Bali?"
# Suponiendo que nuestros documentos están en la variable docs como una lista.
rankedDocs = ReRank(query, docs)
print(rankedDocs)
# Reordenamiento utilizando gráficos
Si eres un académico o investigador, es probable que hayas utilizado Litmaps (opens new window) y Connected Papers (opens new window), que son buenos ejemplos de gráficos para relaciones semánticas. En estos gráficos, los documentos se representan mediante nodos, mientras que las aristas representan sus relaciones semánticas.
Litmaps y Connected Papers
Después de construir este gráfico de documentos, utilizamos GNN (redes neuronales gráficas) para el paso de mensajes para actualizar las características de los nodos en función de los nodos vecinos. Esto permite que el modelo aprenda del contexto proporcionado por los documentos relacionados, mejorando su capacidad para identificar contenido relevante incluso cuando las conexiones directas con la consulta son débiles.
# Representación de significado abstracto (AMR)
Si bien la construcción del gráfico de documentos y el mecanismo de paso de mensajes no son ajenos a los usuarios de GNN, la Representación de Significado Abstracto (AMR) merece cierta cobertura.
AMR es una representación gráfica semántica de una oración que captura su significado de manera abstracta, centrándose en los conceptos expresados y sus relaciones, en lugar de en los detalles sintácticos. Los gráficos AMR tienen información semántica más estructurada en comparación con la forma general del lenguaje natural. Es particularmente útil en el reordenamiento de documentos basado en gráficos para la Generación con Recuperación Mejorada (RAG) porque permite la codificación de información semántica y estructural rica en el proceso de reordenamiento.
# G-RAG
Recientemente se ha propuesto un método que utiliza AMR para el reordenamiento en RAG. G-RAG [1] En su configuración, los investigadores construyen AMR, toman los 100 mejores documentos y los utilizan para construir el gráfico de documentos. En lugar de la pérdida de entropía cruzada tradicional, G-RAG utiliza la pérdida de clasificación por pares para optimizar directamente la clasificación de relevancia, lo cual se alinea mejor con los objetivos del reordenamiento.
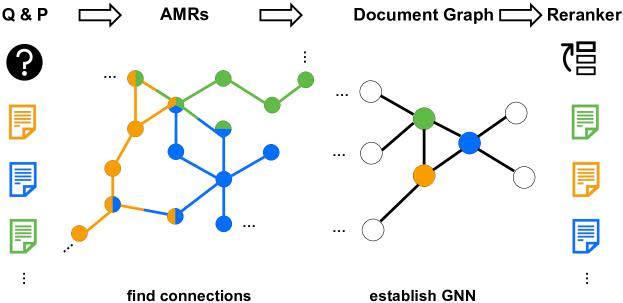
G-RAG
# Búsqueda en dos etapas de MyScale
MyScaleDB utiliza un proceso de búsqueda en dos etapas para optimizar la recuperación de información. Este proceso consta de:
Recuperación inicial: se recuperan rápidamente un conjunto amplio de documentos potencialmente relevantes utilizando métodos como la búsqueda vectorial, que encuentra documentos similares en función de representaciones numéricas (vectores).
Reordenamiento: los documentos recuperados se refinan y clasifican utilizando técnicas avanzadas como los codificadores cruzados para garantizar que se presenten los resultados más relevantes según la consulta del usuario.
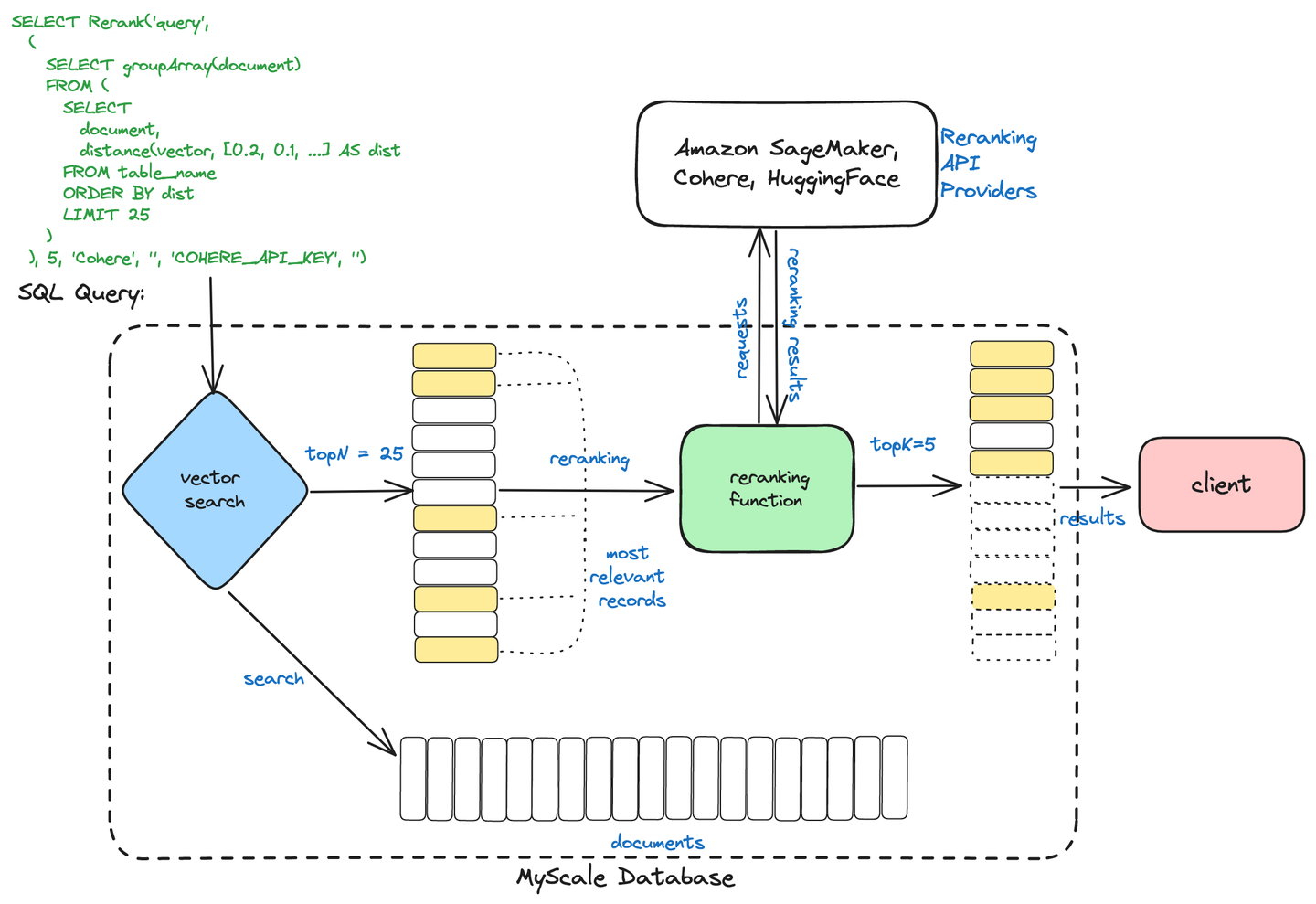
Búsqueda en dos etapas
Este enfoque ayuda a MyScaleDB a ofrecer resultados de búsqueda más rápidos y precisos al combinar una recuperación eficiente con una clasificación precisa.
::: nota Nota: Puedes leer más sobre Búsqueda en dos etapas de MyScale (opens new window) en nuestro blog. :::
# Reordenamiento utilizando MyScale y Cohere
Terminaremos con un ejemplo completo. En este ejemplo, utilizaremos la base de datos vectorial de MyScale para reordenar los documentos en el proceso de RAG. Para los embeddings, estamos utilizando Cohere aquí, pero podría ser cualquier otro servicio como OpenAI o BedRock.
from langchain_community.vectorstores import MyScale, MyScaleSettings
from langchain_cohere import CohereEmbeddings
config = MyScaleSettings(host='nombre-del-host', port=443, username='tu-nombre-de-usuario', password='tu-contraseña')
index = MyScale(CohereEmbeddings(), config)
Ahora agregaremos los documentos a MyScale. Antes de agregarlos a la base de datos, es necesario dividirlos.
from langchain_community.document_loaders import TextLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
documents = TextLoader("../../archivo.txt").load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=100)
texts = text_splitter.split_documents(documents)
index.add_documents(texts)
Como hemos visto antes, necesitamos un subconjunto de documentos antes de aplicar el reordenamiento, así que obtenemos un subconjunto de x documentos.
retriever = index.as_retriever(search_kwargs={"k": 20})
query = "¿Cuál es el lugar más alejado de su centro en la Tierra?"
docs = retriever.invoke(query)
Ahora estamos listos para el reordenamiento. Inicializaremos un modelo de lenguaje con Cohere, estableceremos el reordenador con CohereRerank y lo combinaremos con el recuperador base en un ContextualCompressionRetriever. Esta configuración comprime y reordena los resultados de recuperación, refinando la salida en función de la relevancia contextual.
from langchain.retrievers.contextual_compression import ContextualCompressionRetriever
from langchain_cohere import CohereRerank
from langchain_community.llms import Cohere
llm = Cohere(temperature=0)
compressor = CohereRerank()
compression_retriever = ContextualCompressionRetriever(
base_compressor=compressor, base_retriever=retriever
)
compressed_docs = compression_retriever.invoke(
"Tu-consulta-aquí"
)
Después de agregar el reordenador, la respuesta de tu sistema RAG será más refinada, lo que no solo mejorará la experiencia del usuario, sino que también reducirá el número de tokens utilizados.

# Conclusión
La importancia de RAG y sus inmensas aplicaciones son un secreto a voces. Al concluir nuestra exploración en profundidad de las técnicas avanzadas que impulsan la Generación con Recuperación Mejorada (RAG), queda claro que este campo está evolucionando rápidamente, empujando los límites de lo que es posible con la inteligencia basada en datos. A lo largo de esta serie de blogs, hemos profundizado en las complejidades de la optimización de consultas, la búsqueda vectorial, las estrategias de fragmentación, los métodos de reordenamiento y una serie de otros componentes esenciales que forman la base de los sistemas RAG modernos.
Al dominar estos conceptos avanzados, has adquirido el conocimiento y las herramientas para desbloquear todo el potencial de tus iniciativas de RAG. Desde optimizar tus consultas para ofrecer una recuperación ultrarrápida de información relevante, hasta aprovechar las capacidades de indexación y búsqueda vectorial de vanguardia, ahora estás equipado para construir sistemas RAG que realmente puedan transformar tus procesos de toma de decisiones.
A medida que avanzas, recuerda que el campo de la Generación con Recuperación Mejorada está en constante evolución. Mantente vigilante, continúa aprendiendo y explora soluciones innovadoras como MyScale que pueden ayudarte a mantenerte a la vanguardia. El futuro de la inteligencia basada en datos es brillante y, con el conocimiento que has adquirido a través de esta serie de blogs, estás preparado para estar a la vanguardia de esta emocionante frontera.
Si deseas discutir más sobre las técnicas avanzadas de RAG, te invitamos a unirte a nuestro Discord (opens new window) para comunicarte con nosotros.
# Referencias
- Dong, J., Fatemi, B., Perozzi, B., Yang, L. F., & Tsitsulin, A. (2024). ¡No olvides conectar! Mejorando RAG con reordenamiento basado en gráficos. ArXiv. https://arxiv.org/abs/2405.18414
- Nogueira, R., Jiang, Z., & Lin, J. (2020). Document Ranking with a Pretrained Sequence-to-Sequence Model. ArXiv. https://arxiv.org/abs/2003.06713
- Dengrong Huang, Zizhong Wei, Aizhen Yue, Xuan Zhao, Zhaoliang Chen, Rui Li, Kai Jiang, Bingxin Chang, Qilai Zhang, Sijia Zhang, et al. Dsqa-llm: Domain-specific intelligent question answering based on large language model. In International Conference on AI-generated Content, pages 170–180. Springer, 2023.
- Xueguang Ma, Xinyu Zhang, Ronak Pradeep, and Jimmy Lin. Zero-shot listwise document reranking with a large language model. arXiv preprint arXiv:2305.02156, 2023
- Xueguang Ma, Liang Wang, Nan Yang, Furu Wei, and Jimmy Lin. Fine-tuning llama for multi-stage text retrieval. arXiv preprint arXiv:2310.08319, 2023.
- Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., Küttler, H., Lewis, M., Yih, W., Rocktäschel, T., Riedel, S., & Kiela, D. (2020). Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. NeurIPS. https://arxiv.org/abs/2005.11401
- Zhang, L., Zhang, Y., Long, D., Xie, P., Zhang, M., & Zhang, M. (2023). A Two-Stage Adaptation of Large Language Models for Text Ranking. ArXiv. https://arxiv.org/abs/2311.16720
- Cunxiang Wang, Zhikun Xu, Qipeng Guo, Xiangkun Hu, Xuefeng Bai, Zheng Zhang, and Yue Zhang. Exploiting Abstract Meaning Representation for open-domain question answering. In Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki, editors, Findings of the Association for Computational Linguistics: ACL 2023, pages 2083–2096, Toronto, Canada, July 2023b. Association for Computational Linguistics. doi: 10.18653/v1/2023.findings-acl.131.



