
El auge de la inteligencia artificial ha generado una ola de desarrollo de aplicaciones basadas en LLM, y las bases de datos vectoriales desempeñan un papel crucial al manejar eficientemente datos estructurados y no estructurados a gran escala. Entre ellas, MyScaleDB, una base de datos vectorial SQL construida sobre ClickHouse, ha surgido como la opción preferida para los desarrolladores. Totalmente compatible con SQL, MyScaleDB permite a los desarrolladores construir aplicaciones de IA generativas con una curva de aprendizaje mínima, y cuando se combina con plataformas de bajo código, reduce aún más las barreras de desarrollo.
Recientemente, MyScaleDB se integró con DronaHQ, una plataforma líder de bajo código, para ofrecer una experiencia de desarrollo aún más accesible. Este blog demostrará cómo crear un sistema de recomendación inteligente para restaurantes en DronaHQ utilizando la potente búsqueda vectorial de MyScaleDB, brindando sugerencias personalizadas para mejorar la experiencia del usuario.
# ¿Qué es DronaHQ?
DronaHQ (opens new window) es una potente plataforma de desarrollo de aplicaciones de bajo código que unifica a desarrolladores de todos los niveles de habilidad para construir desde microherramientas simples hasta aplicaciones empresariales robustas como paneles de control, interfaces gráficas de usuario de bases de datos, paneles de administración, aplicaciones de aprobación, herramientas de soporte al cliente, etc., para ayudar a mejorar las operaciones comerciales. La plataforma permite a los desarrolladores construir aplicaciones de varias pantallas fácilmente, sobre diversas bases de datos e integrar APIs de terceros, y aprovechar características de seguridad sólidas, elementos de interfaz de usuario extensos y opciones flexibles de uso compartido después de la implementación. DronaHQ minimiza las horas de ingeniería necesarias para desarrollar una aplicación sin los problemas del backend. Si bien uno de los puntos clave de la plataforma es su función de arrastrar y soltar, los desarrolladores tienen libertad para escribir código y utilizar funciones de biblioteca para diseñar la interfaz de usuario y personalización, y escribir lógica y depurar.
Con la plataforma de bajo código de DronaHQ, puedes crear aplicaciones completas que integren capacidades avanzadas de datos como la búsqueda vectorial con herramientas de creación de aplicaciones fáciles de usar. Al final de este artículo, aprenderás cómo:
- Comprender los conceptos básicos de la búsqueda vectorial y sus aplicaciones.
- Preparar y gestionar datos en MyScaleDB para búsquedas más efectivas.
- Integrar MyScaleDB de forma transparente con DronaHQ para construir una aplicación de recomendación de restaurantes basada en la ubicación.
- Crear y desplegar rápidamente una aplicación potente que aproveche capacidades de búsqueda avanzadas, todo dentro de la plataforma de DronaHQ.
# ¿Qué es la búsqueda vectorial?
La búsqueda vectorial (opens new window) es una técnica avanzada que transforma los datos en vectores en un espacio multidimensional, donde cada vector representa las características clave de los datos. Utilizando la similitud del coseno, estos vectores se comparan en función de qué tan cerca están entre sí en este espacio. Esto ayuda a determinar qué tan similares son conceptual o contextualmente dos puntos de datos, incluso si no comparten las mismas palabras exactas. Este enfoque va más allá de las búsquedas de palabras clave tradicionales que coinciden con palabras clave específicas. La búsqueda vectorial es particularmente útil cuando se desea encontrar elementos que sean semánticamente similares, incluso si no son idénticos.
En un sistema de recomendación de restaurantes, la búsqueda vectorial puede analizar y comparar varios factores como el ambiente, las opiniones de los usuarios y las experiencias gastronómicas al convertir estos aspectos en representaciones vectoriales. Esto permite que el sistema identifique restaurantes que son similares en términos de la experiencia gastronómica general, en lugar de simplemente coincidir con criterios específicos como el tipo de cocina o el rango de precios.
# Preparación de datos en MyScaleDB
Para este blog, utilizaremos MyScaleDB (opens new window), una base de datos vectorial SQL de código abierto y alto rendimiento. Está diseñada para proporcionar capacidades avanzadas de búsqueda vectorial con el lenguaje de consulta SQL familiar. Construida sobre ClickHouse (opens new window), MyScaleDB puede gestionar eficientemente tanto datos estructurados como vectorizados en un sistema unificado, lo que la convierte en una elección ideal para aplicaciones de IA a gran escala.
Una de las principales razones para elegir MyScaleDB para este proyecto es su algoritmo de indexación Multi-Scale Tree Graph (MSTG) (opens new window). Este algoritmo ofrece operaciones vectoriales de alta velocidad junto con un almacenamiento eficiente de datos, superando a las bases de datos vectoriales especializadas en términos de costo y rendimiento. Lo más importante es que MyScaleDB permite a los nuevos usuarios guardar hasta 5 millones de vectores de forma gratuita, por lo que no tenemos que pagar nada por esta aplicación MVP.
# Crear un clúster de MyScaleDB
Para comenzar a utilizar MyScaleDB en nuestra aplicación de DronaHQ, lo primero que debemos hacer es crear un clúster en la nube de MyScaleDB para el almacenamiento de datos. Para ello, visita la consola de MyScaleDB (opens new window), regístrate, inicia sesión y haz clic en el botón "Nuevo clúster" en la esquina superior derecha para crear tu clúster de MyScale.
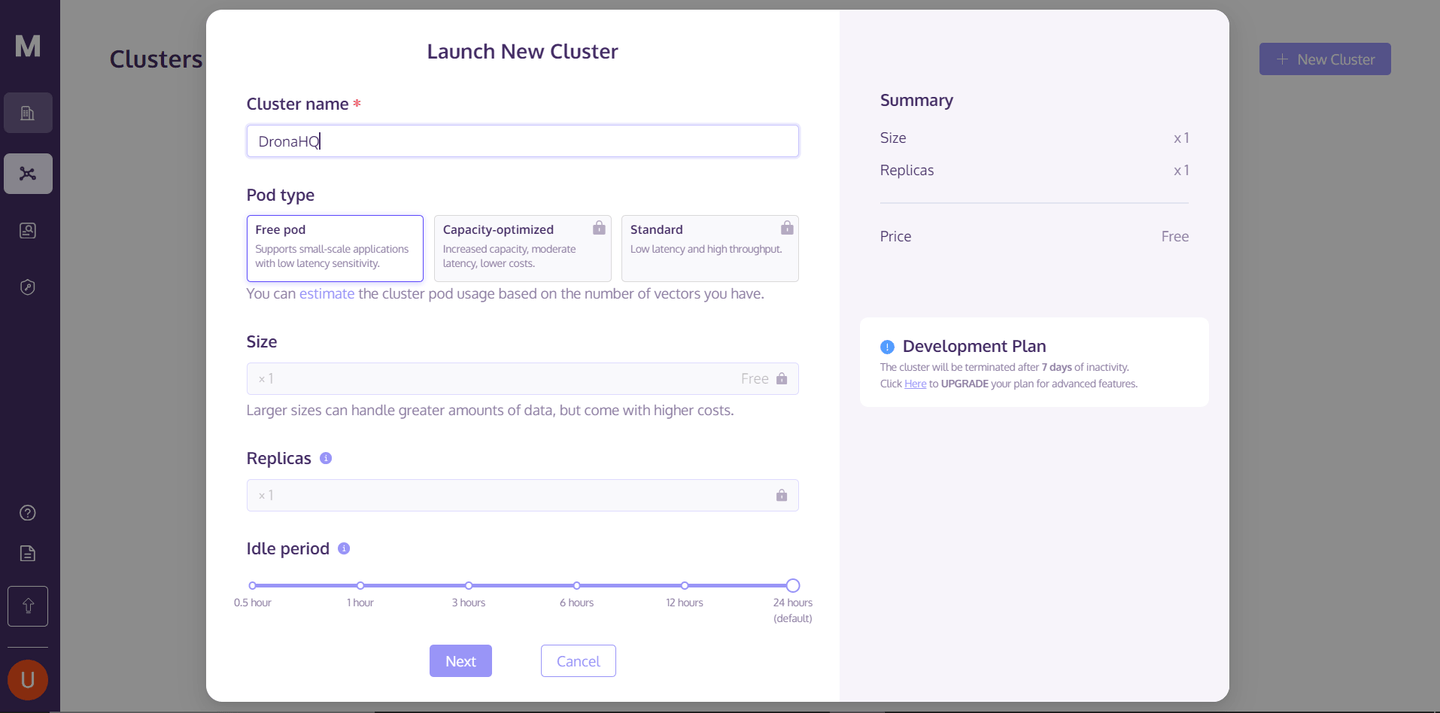
Después de ingresar el nombre del clúster, haz clic en el botón "Siguiente" y espera a que el clúster termine de iniciarse.
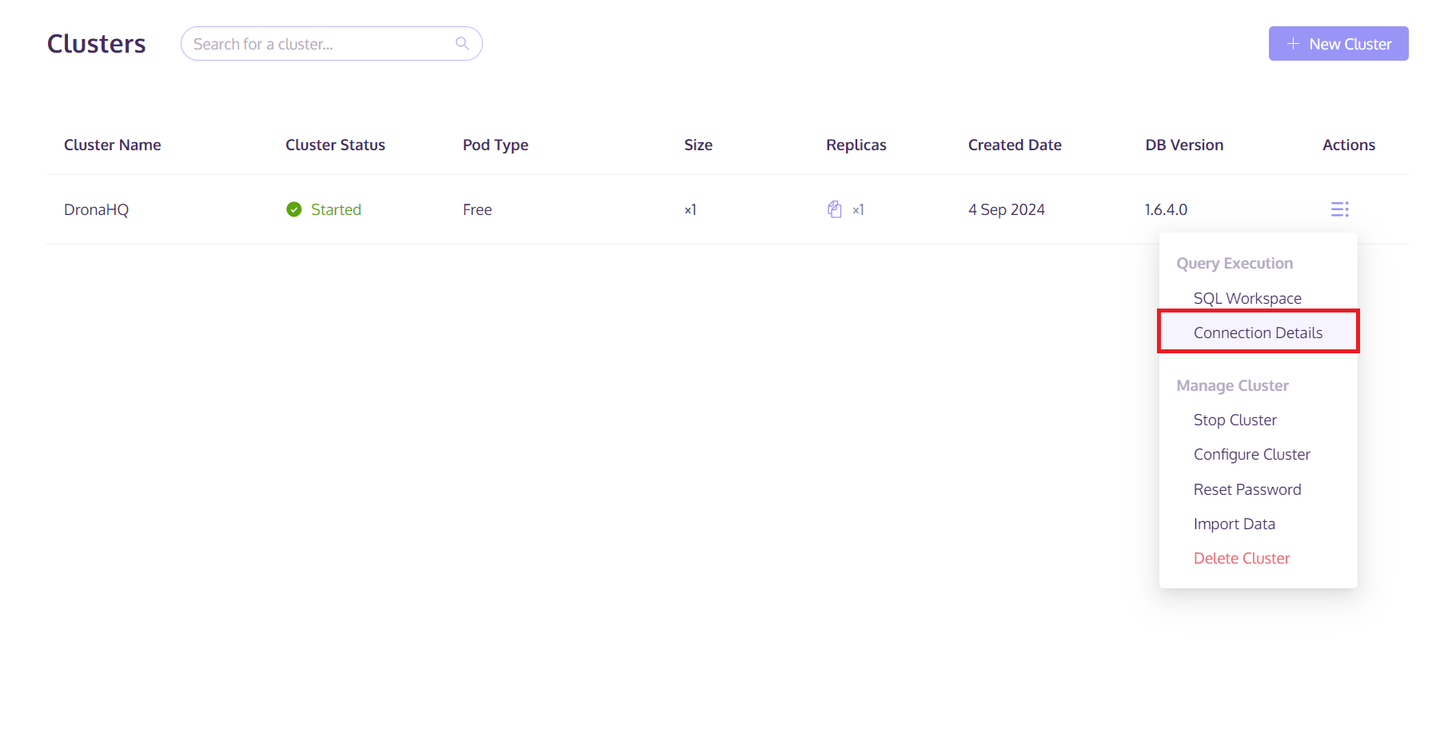
Una vez creado el clúster, haz clic en el botón "Acciones" en el lado derecho del clúster. Luego selecciona "Detalles de conexión" de la lista emergente. Guarda la información de host/puerto/usuario/contraseña de la pestaña "Python". Esta información se utilizará para acceder y guardar los datos en el clúster de MyScaleDB.
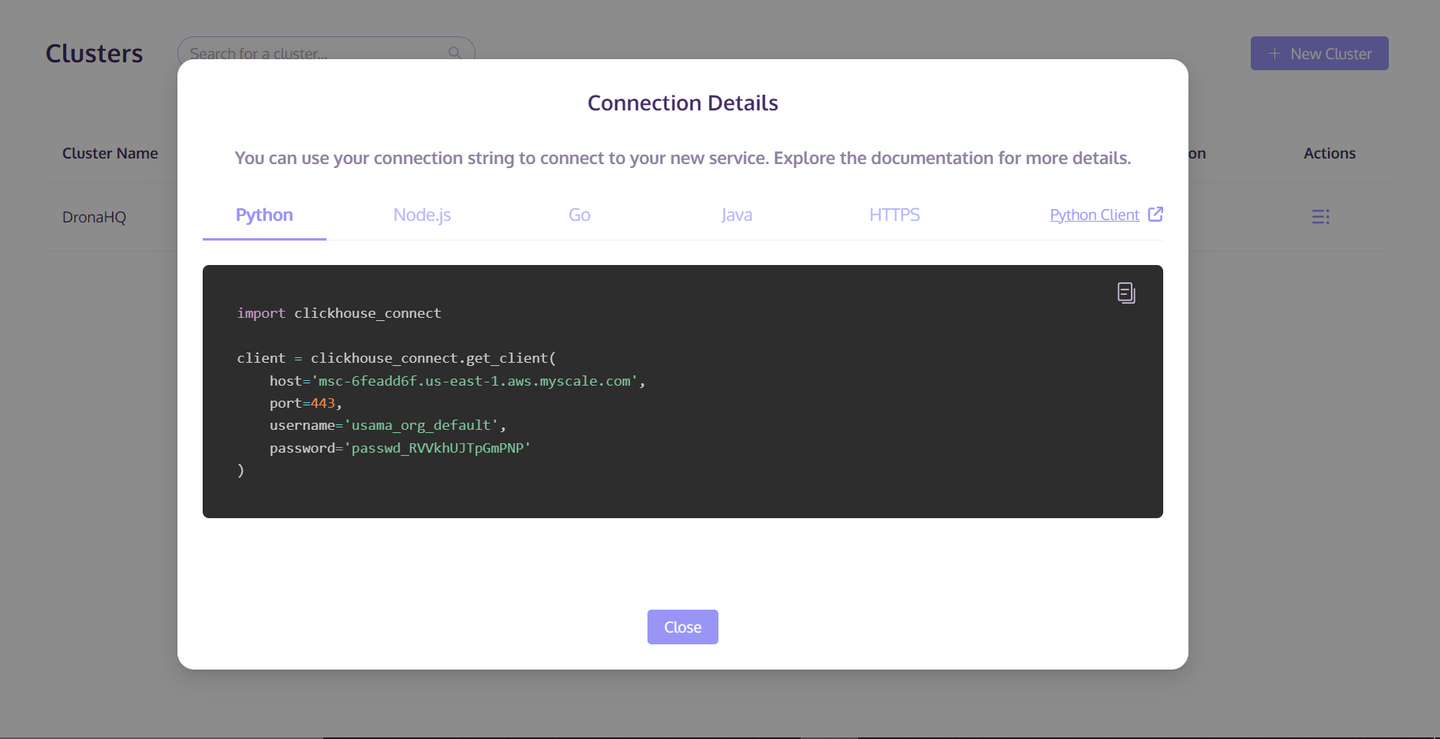
Ahora que ya estamos listos para las configuraciones de MyScaleDB, lo siguiente es preparar y guardar los datos en este clúster recién creado.
# Preparar y guardar los datos
Estamos utilizando datos generados sintéticamente, específicamente adaptados a nuestros requisitos, que fueron creados utilizando un modelo de lenguaje grande (LLM). Puedes acceder a este conjunto de datos a través del repositorio correspondiente en GitHub (opens new window).
# Instalar las dependencias
Primero, necesitamos instalar las bibliotecas necesarias. Descomenta la siguiente línea y ejecútala para instalar los paquetes requeridos. Si las bibliotecas ya están instaladas en tu sistema, puedes omitir este paso.
# pip install sentence-transformers clickhouse_connect
# Cargar los datos
Primero, debes cargar los datos que has obtenido de GitHub en tu directorio local. Asegúrate de que las rutas a tus archivos estén especificadas correctamente. Así es como puedes cargar los datos:
import pandas as pd
# Cargar datos desde archivos CSV
df_restaurants = pd.read_csv("restaurants.csv")
df_users = pd.read_csv("users.csv")
df_reviews = pd.read_csv("reviews.csv")
Aquí, tenemos tres archivos CSV:
restaurants.csv: Contiene detalles sobre los restaurantes, como el nombre, la calificación, la cocina, el precio promedio y la ubicación.reviews.csv: Incluye opiniones de los usuarios, especificando qué usuario dio qué calificación a qué restaurante.users.csv: Almacena las preferencias de los usuarios, incluyendo la cocina preferida, la calificación promedio y el gasto promedio.
# Cargar el modelo de embedding
A continuación, utilizaremos un modelo de embedding de Huggingface para generar embeddings para nuestros datos de texto. El modelo que utilizaremos es gratuito y se llama sentence-transformers/all-MiniLM-L6-v2.
import torch
from transformers import AutoTokenizer, AutoModel
# Inicializar el tokenizador y el modelo para los embeddings
tokenizer = AutoTokenizer.from_pretrained("sentence-transformers/all-MiniLM-L6-v2")
model = AutoModel.from_pretrained("sentence-transformers/all-MiniLM-L6-v2")
def get_embeddings(texts: list) -> list:
inputs = tokenizer(texts, padding=True, truncation=True, return_tensors="pt", max_length=512)
with torch.no_grad():
outputs = model(**inputs)
embeddings = outputs.last_hidden_state.mean(dim=1)
return embeddings.numpy().tolist()
El método get_embeddings tomará una lista de cadenas de texto y devolverá sus embeddings.
# Generar los embeddings
Ahora, generemos embeddings para campos específicos de nuestros datos: el tipo de cocina para los restaurantes, las cocinas preferidas para los usuarios y las opiniones para cada restaurante. Estos embeddings serán cruciales para realizar búsquedas de similitud más adelante.
# Generar embeddings para los tipos de cocina y las preferencias de los usuarios
df_restaurants["cuisine_embeddings"] = get_embeddings(df_restaurants["cuisine"].tolist())
df_users["cuisine_preference_embeddings"] = get_embeddings(df_users["cuisine_preference"].tolist())
# Generar embeddings para las opiniones
df_reviews["review_embeddings"] = get_embeddings(df_reviews["review"].tolist())
# Conectar con MyScaleDB
Para conectarte con tu clúster de MyScaleDB, utiliza los detalles de conexión que copiaste durante el proceso de creación del clúster. Esto te permitirá establecer una conexión con tu instancia de MyScaleDB.
import clickhouse_connect
# Conectar con MyScaleDB
client = clickhouse_connect.get_client(
host='tu_nombre_de_host_aquí',
port=443,
username='tu_nombre_de_usuario_aquí',
password='tu_contraseña_aquí'
)
# Crear tablas
El siguiente paso es crear tablas dentro de tu clúster de MyScaleDB donde puedas almacenar tus datos. Según las necesidades de tu aplicación, crearás tablas para usuarios, restaurantes y opiniones.
# Crear la tabla de usuarios
client.command("""
CREATE TABLE default.users (
userId Int64,
cuisine_preference String,
rating_preference Float32,
price_range Int64,
latitude Float32,
longitude Float32,
cuisine_preference_embeddings Array(Float32),
CONSTRAINT check_data_length CHECK length(cuisine_preference_embeddings) = 384
) ENGINE = MergeTree()
ORDER BY userId
""")
# Crear la tabla de opiniones
client.command("""
CREATE TABLE default.reviews (
userId Int64,
restaurantId Int64,
rating Float32,
review String,
review_embeddings Array(Float32),
CONSTRAINT check_data_length CHECK length(review_embeddings) = 384
) ENGINE = MergeTree()
ORDER BY userId
""")
# Crear la tabla de restaurantes
client.command("""
CREATE TABLE default.restaurants (
restaurantId Int64,
name String,
cuisine String,
rating Float32,
price_range Int64,
latitude Float32,
longitude Float32,
cuisine_embeddings Array(Float32),
CONSTRAINT check_data_length CHECK length(cuisine_embeddings) = 384
) ENGINE = MergeTree()
ORDER BY restaurantId
""")
# Insertar datos en las tablas
Con las tablas creadas, ahora puedes insertar los datos en estas tablas utilizando el método de inserción.
# Insertar datos en la tabla de usuarios
client.insert("default.users", df_users.to_records(index=False).tolist(), column_names=df_users.columns.tolist())
# Insertar datos en la tabla de opiniones
client.insert("default.reviews", df_reviews.to_records(index=False).tolist(), column_names=df_reviews.columns.tolist())
# Insertar datos en la tabla de restaurantes
client.insert("default.restaurants", df_restaurants.to_records(index=False).tolist(), column_names=df_restaurants.columns.tolist())
# Crear el índice MSTG
Finalmente, para permitir búsquedas eficientes en tus datos, crea un índice MSTG en cada una de las tablas.
# Crear el índice MSTG para los usuarios
client.command("""
ALTER TABLE default.users
ADD VECTOR INDEX user_index cuisine_preference_embeddings
TYPE MSTG
""")
# Crear el índice MSTG para los restaurantes
client.command("""
ALTER TABLE default.restaurants
ADD VECTOR INDEX restaurant_index cuisine_embeddings
TYPE MSTG
""")
# Crear el índice MSTG para las opiniones
client.command("""
ALTER TABLE default.reviews
ADD VECTOR INDEX reviews_index review_embeddings
TYPE MSTG
""")
Hasta ahora, hemos completado el backend de nuestra aplicación. Ahora es el momento de centrarnos en construir el frontend utilizando DronaHQ. Veamos cómo podemos hacer esto.
# Construyendo la aplicación en DronaHQ
DronaHQ es una plataforma de desarrollo de aplicaciones de bajo código diseñada para crear aplicaciones web y móviles personalizadas 10 veces más rápido. Con sus potentes bloques de construcción, como componentes de interfaz de usuario preconstruidos, conectores de datos y herramientas de automatización de flujos de trabajo, DronaHQ reduce significativamente el tiempo y el esfuerzo necesarios para el desarrollo, lo que te permite construir aplicaciones rápidamente sin lidiar con complejos frameworks de frontend.
Ya seas un desarrollador full-stack, enfocado en el backend o el frontend, o estés comenzando tu carrera como desarrollador, DronaHQ facilita el arrastrar y soltar elementos de interfaz de usuario, conectarse a diversas fuentes de datos y construir aplicaciones impresionantes.
Creemos una aplicación funcional que realice búsquedas vectoriales en la base de datos MyScale y construya una interfaz de recomendación para restaurantes.
# Integración de MyScale con DronaHQ
Para integrar MyScale con DronaHQ, puedes aprovechar el conector de ClickHouse, dado que MyScaleDB funciona sobre ClickHouse en su núcleo. Así es cómo puedes configurarlo:
- Elige el conector de ClickHouse: En DronaHQ, ve a la sección de conectores y selecciona el conector de ClickHouse. Este servirá como la interfaz para conectarse a MyScaleDB.

Ingresa las credenciales de MyScaleDB: Completa los detalles requeridos para tu instancia de MyScaleDB:
- URL de la base de datos: El punto final donde se aloja tu instancia de MyScaleDB.
- Nombre de usuario y contraseña: Tus credenciales de autenticación.
- Nombre de la base de datos: Establécelo en
defaulta menos que tu configuración especifique una base de datos diferente.
Prueba y guarda: Después de ingresar las credenciales, haz clic en "Probar" para asegurarte de que la conexión se establezca correctamente. Si la prueba es exitosa, guarda la configuración. Esto creará un conector en DronaHQ que está listo para interactuar con tu MyScaleDB.
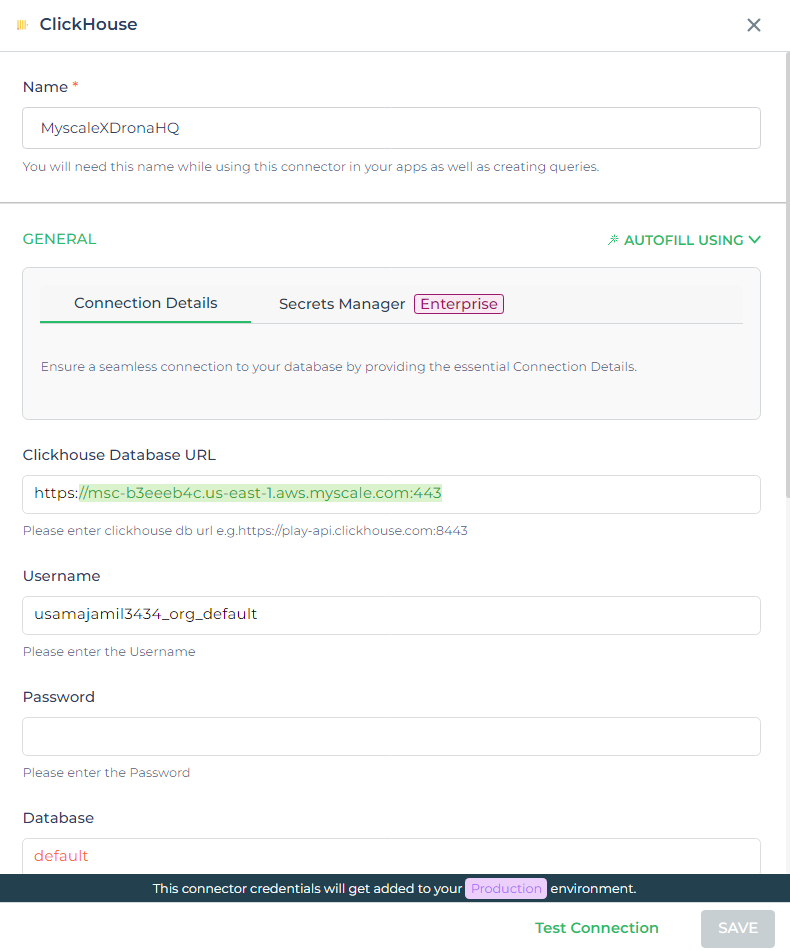
Siguiendo estos pasos, tendrás un conector completamente funcional en DronaHQ que puede comunicarse con MyScaleDB, lo que te permitirá ejecutar consultas, obtener datos y potenciar tus aplicaciones con capacidades avanzadas de bases de datos.
# Escribir consultas para el buscador de restaurantes
Con el conector de MyScaleDB configurado en DronaHQ, ahora podemos escribir consultas para obtener recomendaciones de restaurantes basadas en la entrada del usuario. Las consultas se ajustarán dinámicamente según las preferencias de cocina y el rango de precios del usuario.
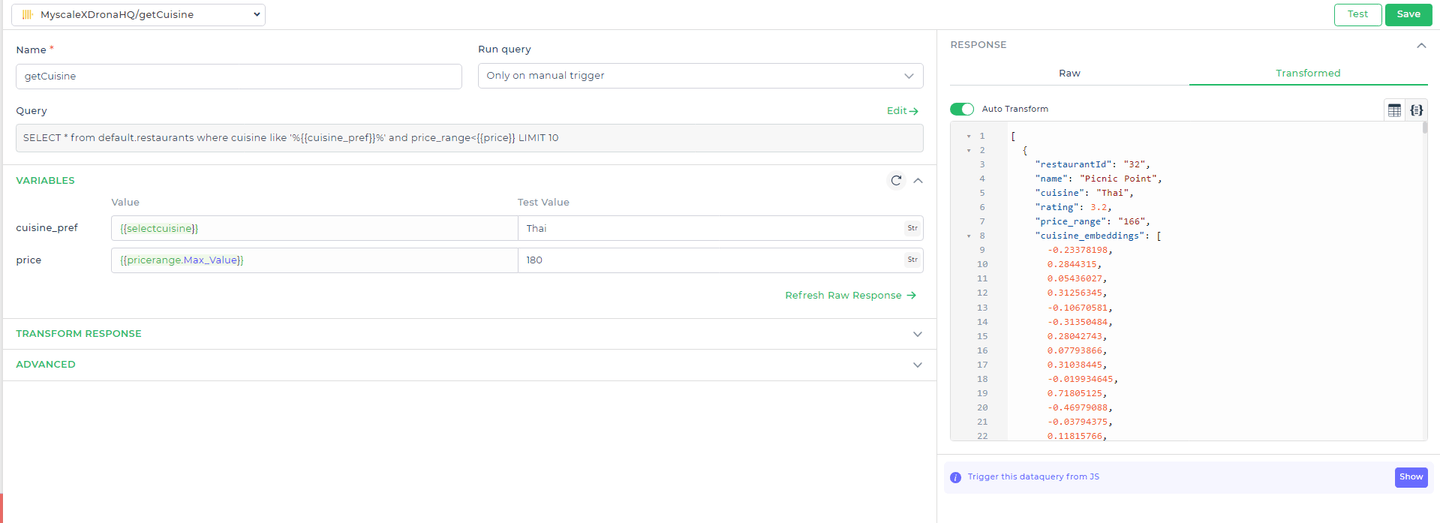
# Consulta 1: Obtener recomendaciones iniciales de restaurantes
Primero, necesitamos recuperar una lista de restaurantes que coincidan con el tipo de cocina preferido por el usuario y que estén dentro del rango de precios especificado. La siguiente consulta logra esto:
Consulta:
SELECT * FROM default.restaurants
WHERE cuisine LIKE '%{{cuisine_pref}}%'
AND price_range < {{price}}
LIMIT 10;
Explicación:
default.restaurants: Se refiere a la tabla en MyScaleDB donde se almacenan los datos de los restaurantes.cuisine LIKE '%{ { cuisine_pref } }%': Esta condición filtra los resultados en función de la preferencia de cocina del usuario. El{ { cuisine_pref } }es un marcador de posición que DronaHQ reemplaza dinámicamente por la entrada real del usuario.price_range < { { price } }: Filtra los restaurantes que tienen un precio menor al presupuesto especificado por el usuario, representado por el marcador de posición{ { price } }.LIMIT 10: Restringe los resultados a los 10 mejores restaurantes coincidentes para asegurarse de que la consulta devuelva un número manejable de recomendaciones.
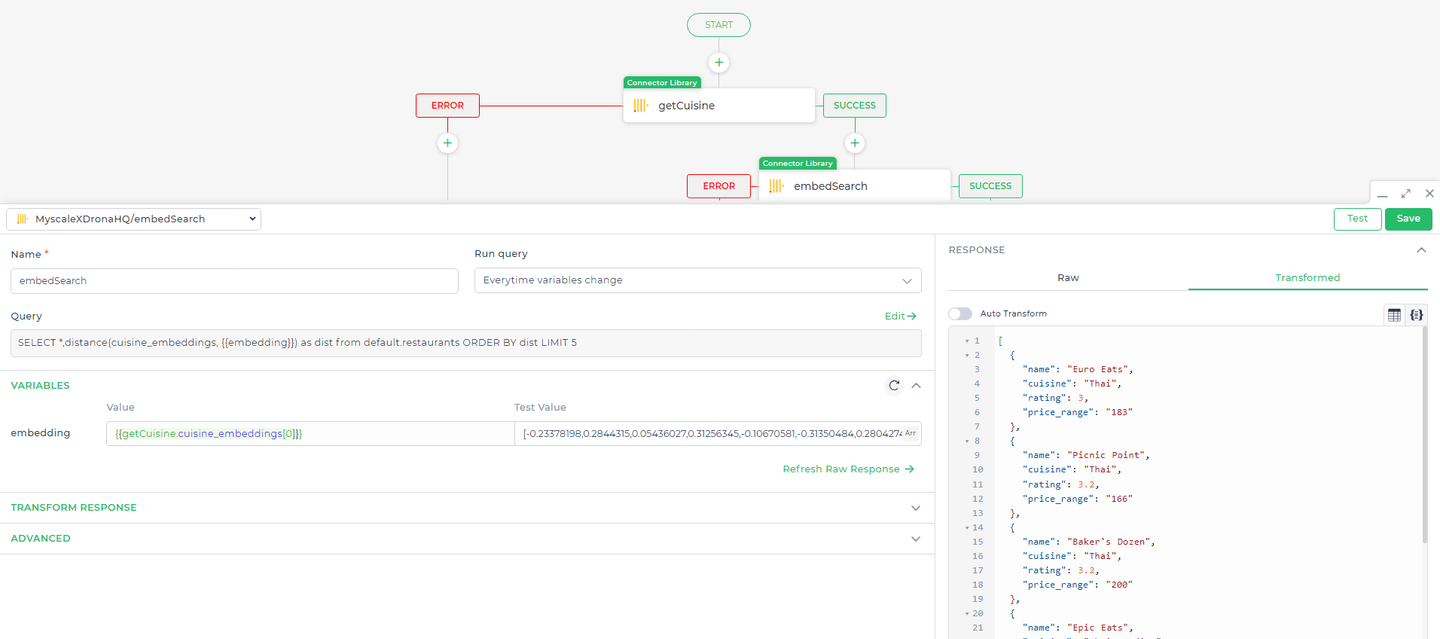
# Consulta 2: Realizar una búsqueda vectorial para recomendaciones mejoradas
Después de presentar la lista inicial de restaurantes, queremos utilizar la búsqueda vectorial para proporcionar recomendaciones adicionales basadas en las características de las opciones iniciales. Esto permite que la aplicación sugiera restaurantes que sean similares en concepto o experiencia, incluso si no coinciden exactamente en palabras clave.
Consulta:
SELECT *, distance(cuisine_embeddings, {{embedding}}) AS dist
FROM default.restaurants
ORDER BY dist
LIMIT 5;
Explicación:
distance(cuisine_embeddings, { { embedding } }) AS dist: Esta expresión calcula la distancia entre el embedding vectorial de la cocina de cada restaurante y el embedding de la cocina preferida del usuario. El marcador de posición{ { embedding } }representa la preferencia de cocina del usuario transformada en un vector, que luego se compara con loscuisine_embeddingsalmacenados en la base de datos.ORDER BY dist: Los resultados se ordenan según la distancia calculada, con las coincidencias más cercanas (es decir, las de menor distancia) que aparecen primero.LIMIT 5: Restringe los resultados a las 5 coincidencias más cercanas, asegurando que las recomendaciones sean altamente relevantes.
Esta combinación de filtrado estándar de SQL y búsqueda vectorial permite que la aplicación proporcione recomendaciones de restaurantes precisas y contextualmente relevantes, mejorando la experiencia general del usuario.
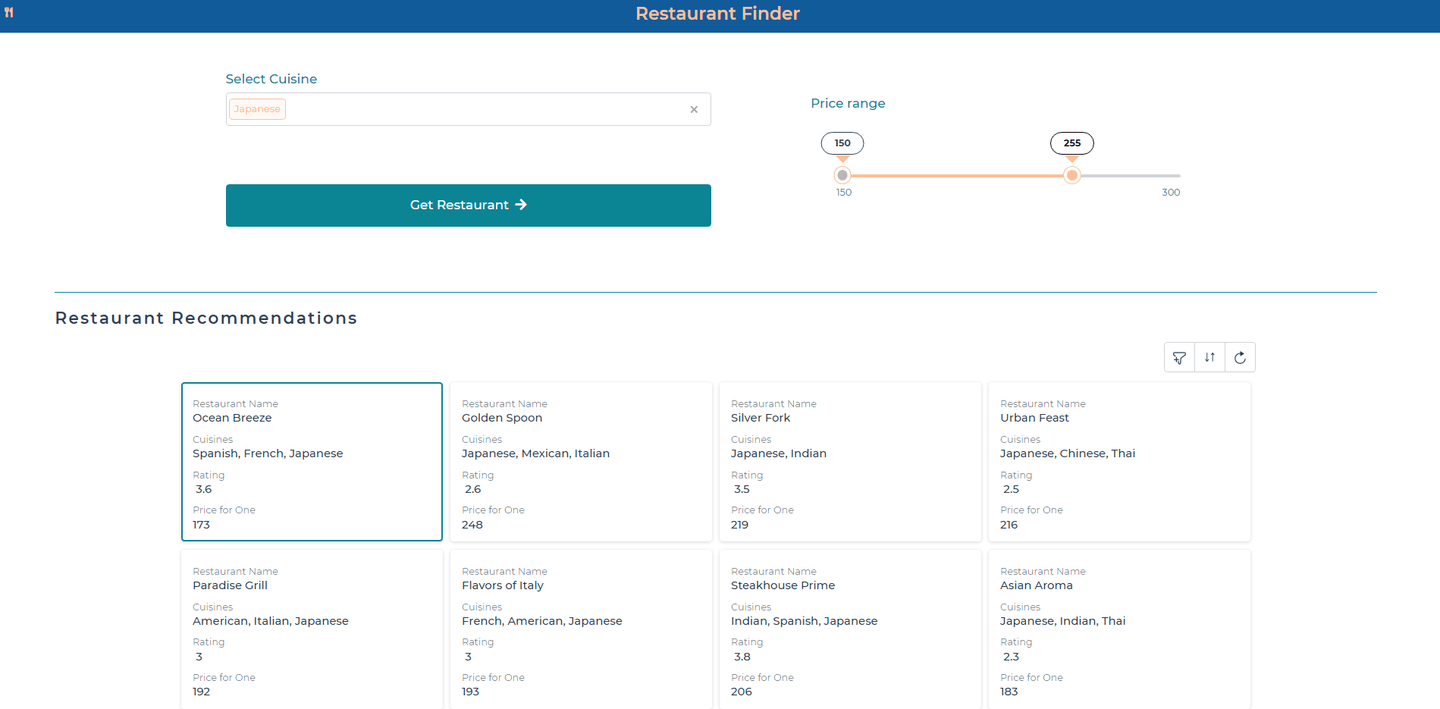
# Diseñar la interfaz
Cuando nos propusimos diseñar el buscador de restaurantes, nuestro enfoque principal fue crear una interfaz altamente funcional. La extensa biblioteca de componentes de DronaHQ hace posible lograr esto con un mínimo de programación.
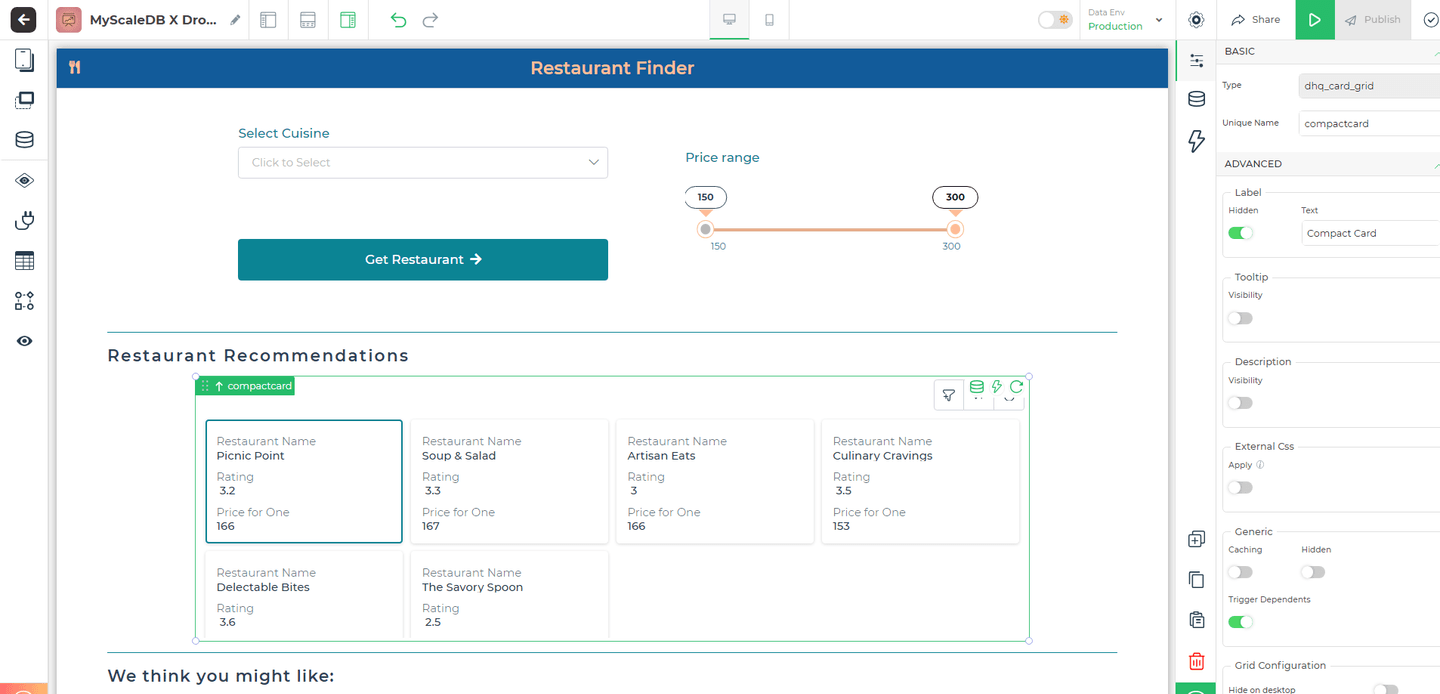
La aplicación comienza permitiendo a los usuarios seleccionar su cocina preferida desde un menú desplegable y ajustar un control deslizante de rango de precios para filtrar los restaurantes por presupuesto, con una retroalimentación inmediata para refinar su búsqueda. Las recomendaciones se muestran en tarjetas responsivas que muestran el nombre del restaurante, la calificación y el precio por comida, dispuestas utilizando el diseño de cuadrícula de DronaHQ. Para mejorar la experiencia del usuario, las recomendaciones se dividen en secciones de "Recomendaciones de restaurantes" y "Creemos que te podría gustar", proporcionando opciones tanto dirigidas como exploratorias.
# Crear un flujo de acción para mostrar los resultados
Con tus consultas de base de datos en su lugar y la interfaz de usuario lista, el último paso es establecer un flujo de acción (opens new window) que active estas consultas y muestre los resultados a los usuarios en tiempo real.
Comienza navegando a la configuración del flujo de acción del componente de botón dentro de tu aplicación. Aquí es donde agregarás las acciones de conector necesarias que interactuarán con tus consultas.
- Vincular la consulta a la entrada del usuario
Selecciona la consulta diseñada para obtener los detalles de los restaurantes según la entrada del usuario. En la sección de variables, vincula los campos de entrada, como el tipo de cocina y el rango de precios, a los componentes apropiados en tu interfaz de usuario. Esto asegura que la consulta utilice los datos proporcionados por el usuario. Después de vincularlos, prueba el flujo de acción para asegurarte de que funcione correctamente y luego guarda la configuración.
- Utilizar embeddings para encontrar opciones similares Una vez que la primera consulta recupere los datos, configura otra acción de conector que active una búsqueda basada en embeddings. Esta búsqueda utiliza los datos de embedding del resultado de la consulta anterior (específicamente el índice 0 del array de embeddings) para encontrar opciones similares. Este paso mejora la relevancia de los resultados que se muestran al usuario.
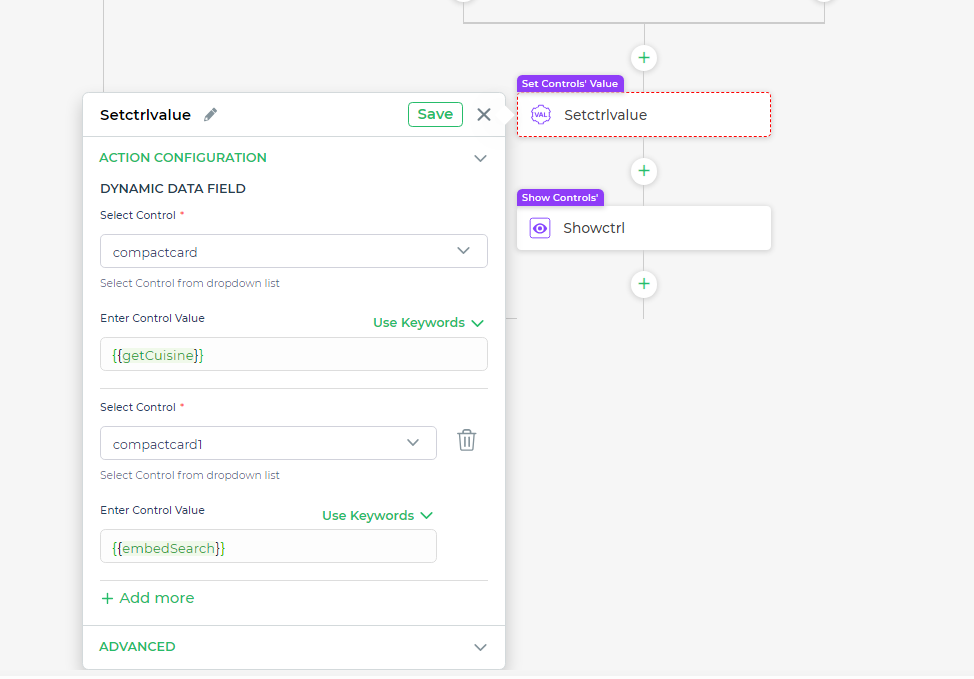
- Mostrar los resultados en la interfaz de usuario El último paso implica establecer los valores de control. Este paso asegura que los datos recuperados de tus consultas se muestren correctamente dentro de los componentes de la interfaz de usuario, como listas o tarjetas, con los que los usuarios interactuarán. Al establecer los valores de control correctamente, habilitas una visualización dinámica que se actualiza según la entrada del usuario.

# Conclusión
Al combinar el poder de la búsqueda vectorial de MyScaleDB con el entorno de bajo código de DronaHQ, hemos creado un sofisticado buscador de restaurantes (opens new window) que ofrece recomendaciones altamente personalizadas. Esta integración no solo permite un filtrado preciso basado en las preferencias del usuario, sino que también mejora la experiencia al sugerir opciones de restaurantes similares a través de técnicas avanzadas de embedding. El resultado es una aplicación más inteligente e intuitiva que eleva la participación del usuario al ofrecer opciones relevantes y contextualmente conscientes.
Más allá de los buscadores de restaurantes, la combinación de MyScaleDB y DronaHQ se puede aplicar a una variedad de otros escenarios, como la construcción de chatbots inteligentes o incluso sistemas de observación para modelos de lenguaje grandes (LLMs). La flexibilidad de una base de datos vectorial, combinada con una plataforma de bajo código, acelera el desarrollo sin sacrificar la complejidad necesaria para las aplicaciones de IA modernas. Esto resulta en una prototipación más rápida, escalabilidad y la capacidad de integrar de manera transparente características avanzadas en aplicaciones cotidianas, todo mientras se ahorra tiempo de desarrollo.
El artículo original fue publicado en DronaHQ (opens new window).



