
Este artículo se basa en el discurso principal pronunciado por el CEO de MyScale en The AI Conference 2023 (opens new window).
# Las bases de datos vectoriales + LLMs son una pila clave para construir aplicaciones GenAI
En un mundo de tecnologías de IA en constante avance, la fusión de los Modelos de Lenguaje Grande (LLMs, por sus siglas en inglés) como GPT y las bases de datos vectoriales ha surgido como una parte crítica de la pila de infraestructura utilizada para desarrollar aplicaciones de IA de vanguardia. Esta combinación innovadora permite el procesamiento de datos no estructurados, allanando el camino para obtener resultados más precisos y acceso en tiempo real a información actualizada. Muchos modelos, como el GPT de OpenAI, Bard, Anthropic y modelos de código abierto como LLaMA, han revolucionado la forma en que resolvemos problemas.
Sin embargo, los LLMs presentan limitaciones graves cuando se utilizan en casos de uso del mundo real. En primer lugar, pueden carecer de información específica o actualizada que no formaba parte de sus datos de entrenamiento, lo que lleva a un fenómeno conocido como alucinación o limitación de información, donde el modelo genera respuestas incorrectas o extrañas.
Si bien el ajuste fino mejora el comportamiento de los LLMs, las bases de datos vectoriales son clave para resolver la limitación de información (o alucinación) al mejorar el conocimiento del modelo. Es por eso que la combinación de LLMs y bases de datos vectoriales se ha convertido en la pila clave para construir aplicaciones de IA generativas.
# El Dilema: Comodidad vs. Rendimiento Vectorial
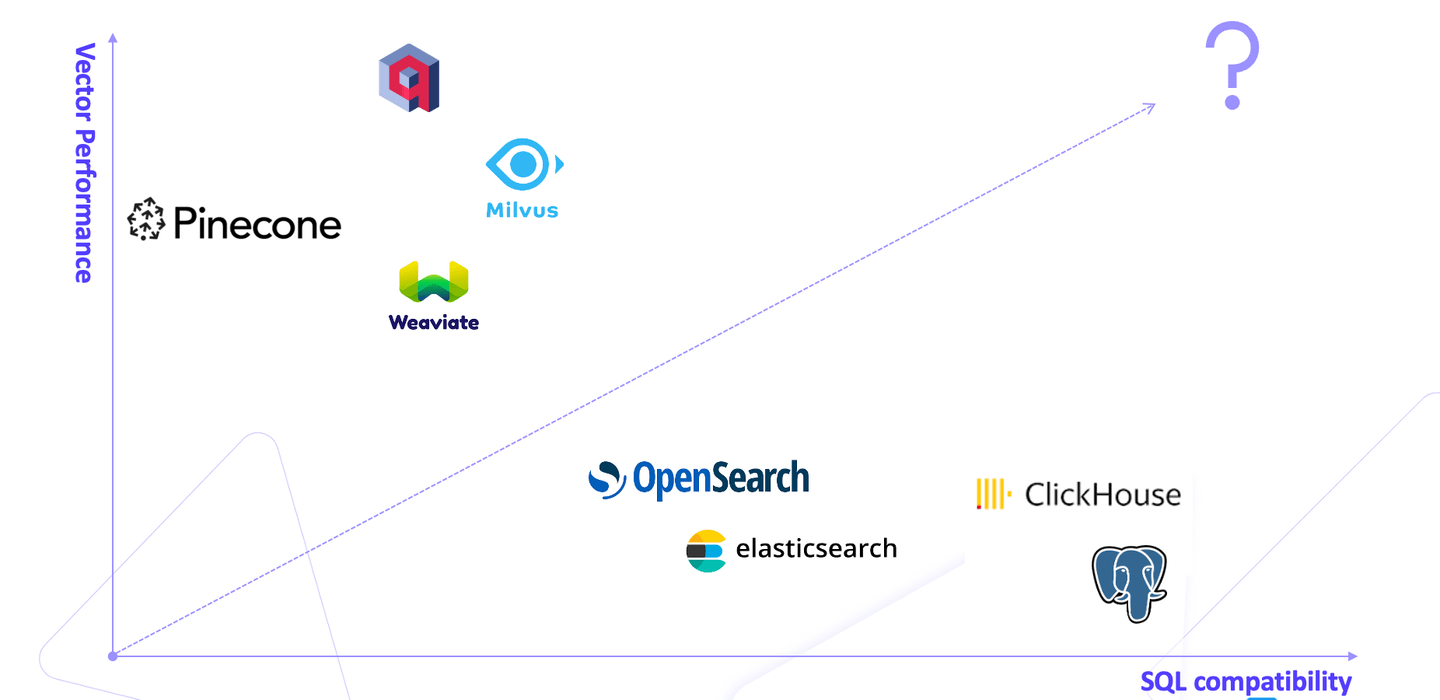
El mercado está repleto de bases de datos vectoriales, cada una de las cuales se clasifica en una de dos categorías: bases de datos vectoriales especializadas como Pinecone, que ofrecen un alto rendimiento vectorial, y bases de datos relacionales como PostgreSQL, que ofrecen comodidad. Esto sumerge a los usuarios en un dilema, una batalla entre la confiabilidad de las bases de datos relacionales y las operaciones vectoriales de alto rendimiento de las bases de datos especializadas.
Imagina que un usuario depende de PostgreSQL por su comodidad y confiabilidad, pero necesita realizar búsquedas vectoriales. Sin embargo, resulta incómodo y engorroso interactuar entre PostgreSQL y Pinecone, lo que aumenta la complejidad y puede generar problemas de consistencia de datos.
# La Solución Ideal: MyScale - una Base de Datos Vectorial Relacional
Aquí es donde entra en juego MyScale (opens new window) como una solución que une el mundo de las bases de datos relacionales tradicionales y las bases de datos vectoriales de alto rendimiento. A diferencia de las bases de datos vectoriales propietarias como Milvus, Qdrant y Weaviate, MyScale se basa en la base de datos de código abierto compatible con SQL llamada ClickHouse, lo que permite a los usuarios realizar búsquedas vectoriales con SQL y eliminar la incomodidad de tener que cambiar entre diferentes tipos de bases de datos.
Se asume ampliamente que las bases de datos relacionales no pueden proporcionar un rendimiento que se equipare al de las bases de datos vectoriales. MyScale rompe este mito. Ofrece una solución equilibrada, optimizada y simplificada para los usuarios que enfrentan este dilema. Supera a las bases de datos vectoriales especializadas al tiempo que conserva todos los beneficios de las bases de datos relacionales.

¡Esto es solo el comienzo!
Bajo el capó, MyScale integra datos estructurados y vectores de manera fluida con una serie de innovaciones algorítmicas e ingeniería de sistemas. A diferencia de otras bases de datos vectoriales que se basan en IVF o HNSW como su algoritmo principal, hemos desarrollado nuestros propios algoritmos. Ayudamos a los usuarios a vectorizar y buscar tanto datos estructurados como incrustaciones vectoriales con un rendimiento muy alto.
# Casos de Uso: Desbloqueando el Potencial de MyScale
Ahora consideremos los siguientes dos casos de uso que describen los beneficios de SQL+vector:
# 1. BitCap: MyScale permite a los usuarios ejecutar consultas complejas
El primer caso de uso proviene de BitCap, una destacada empresa de gestión de activos digitales. Necesitaban realizar búsquedas vectoriales, filtrando por tipos de datos específicos, como marcas de tiempo, en una cantidad considerable de datos.
En este escenario, la escala de los datos era inmensa y BitCap necesitaba la capacidad de utilizar la sintaxis SQL para realizar búsquedas de filtrado precisas. Vale la pena señalar que, no solo la búsqueda vectorial, sino también el rendimiento de la búsqueda de filtrado es absolutamente crítico para muchas aplicaciones del mundo real. Además, BitCap necesitaba soporte para múltiples tipos de datos, incluyendo fechas y cadenas de texto, para cumplir eficazmente con sus requisitos.

Además, BitCap tenía requisitos adicionales:
- Integrar nuestra solución con Langchain
- Proporcionar consultas propias y otras aplicaciones exigentes
MyScale les permitió cumplir con todos sus requisitos en una sola consulta. Por lo tanto, en comparación con las otras alternativas, MyScale es la mejor opción para BitCap porque es muy fácil de usar y tiene un alto rendimiento.
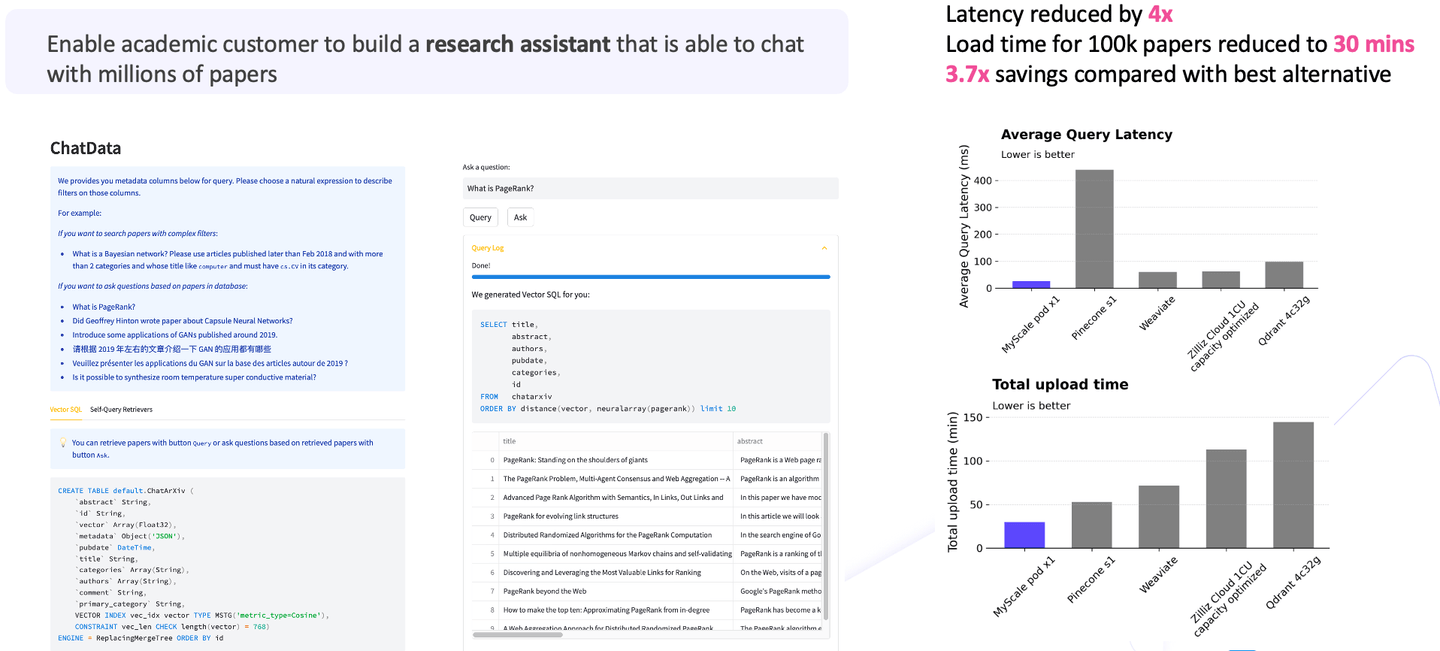
# 2. MyScale ayuda a los usuarios académicos a lograr la mejor relación costo-efectividad
En el segundo caso de uso, ayudamos a los usuarios académicos a crear un asistente de investigación para chatear con millones de artículos. El escenario implicaba la ingestión de un millón de artículos de investigación y habilitar capacidades de preguntas y respuestas utilizando estos artículos.
Dadas las grandes cantidades de datos, si se comparan los costos, se encontrará que los modelos de lenguaje grande constituyen aproximadamente el ochenta o noventa por ciento del costo total. Al mismo tiempo, la búsqueda vectorial forma una parte vital de los requisitos iniciales. Entonces, cuando se agrega la búsqueda vectorial a la ecuación, en comparación con otras opciones (opens new window), MyScale reduce la latencia en un 4x y el tiempo de carga a 30 minutos; en general, los ahorros totales de costos son más de 3x en comparación con las otras opciones.
Como se puede ver en el diagrama, MyScale ofrece un alto rendimiento, baja latencia y una excelente relación costo-efectividad. Estos logros son particularmente notables cuando se trata de aplicaciones a gran escala.
A partir de estos casos de uso, queda claro que se requiere una base de datos relacional para abordar este desafío de manera efectiva. Y dotarla de la mejor funcionalidad vectorial desbloquea un mundo de posibilidades.

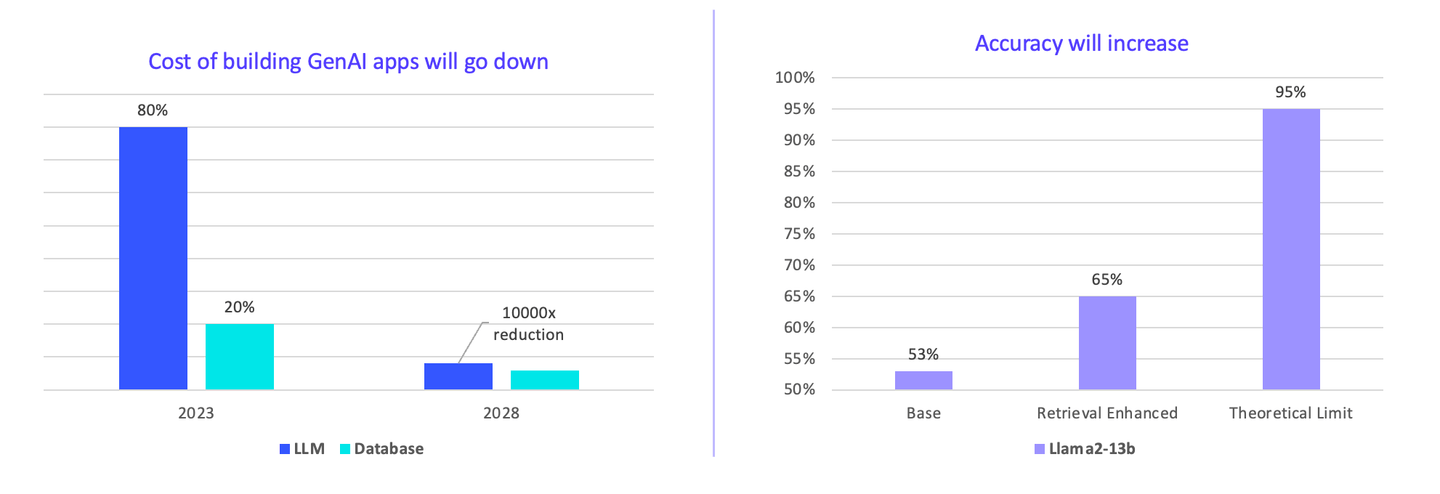
# El Potencial de Optimización de Rendimiento, Costo y Calidad es Enorme
Creo que las empresas pagan demasiado por la IA en la actualidad. Los LLMs constituyen el 80-90% del costo total. Sin embargo, en el futuro, el costo de construir aplicaciones disminuirá. Podemos reducir el precio más rápidamente mediante consenso. Se puede ver que hay un margen de 10000x para reducir los costos.
¿Cómo es esto posible?
- Alojar tus propios modelos en lugar de utilizar APIs comercializadas reduce los costos en un 10x,
- Los sistemas avanzados de almacenamiento en caché contribuyen con otros 10x,
- Otras técnicas contribuyen conjuntamente con 100x.
No todos conocen estas técnicas.
Además, la precisión de la búsqueda vectorial puede aumentar. Actualmente, el modelo base es Llama2, y con un complemento de base de datos vectorial, la precisión aumenta significativamente del 53% al 65%.
Nota:
La base de datos ya está en el conjunto de entrenamiento, pero el uso de una base de datos vectorial aumenta drásticamente el rendimiento.
El límite teórico es mucho mayor si utilizamos bases de datos vectoriales más grandes. El costo es mucho menor en comparación con el uso de GPUs para servir solo LLMs. Creemos que esta es una dirección futura a seguir.
# El Futuro
Miremos hacia el futuro:
Las bases de datos relacionales vectoriales con SQL representan un enfoque innovador para potenciar aplicaciones GenAI. MyScale une el mundo de las bases de datos relacionales y vectoriales, ofreciendo comodidad y capacidades de alto rendimiento, y demuestra que las bases de datos relacionales pueden superar a las bases de datos especializadas en términos de rendimiento vectorial al tiempo que conservan todos los beneficios de SQL. Al redefinir las posibilidades y reducir los costos, MyScale allana el camino para un futuro en el que las aplicaciones de IA sean más accesibles y poderosas que nunca. Y hay un amplio margen para reducir los costos y mejorar la precisión, que es la dirección que debemos seguir. Si tienes más preguntas o estás interesado en nuestra oferta, no dudes en contactarnos en Discord (opens new window) o seguir a MyScale en Twitter (opens new window).
¡Gracias!



