
La generación aumentada por recuperación (RAG) (opens new window) ha revolucionado la forma en que interactuamos con los datos, ofreciendo un rendimiento sin igual en las búsquedas de similitud. Destaca en la recuperación de información relevante basada en consultas simples. Sin embargo, RAG a menudo se queda corto al manejar tareas más complejas, como consultas basadas en el tiempo o consultas intrincadas de bases de datos relacionales. Esto se debe a que RAG está diseñado principalmente para la generación de texto aumentada con información relevante de fuentes externas, en lugar de realizar recuperaciones exactas y basadas en condiciones. Estas limitaciones restringen su aplicación en escenarios que requieren una recuperación precisa y condicional de datos.
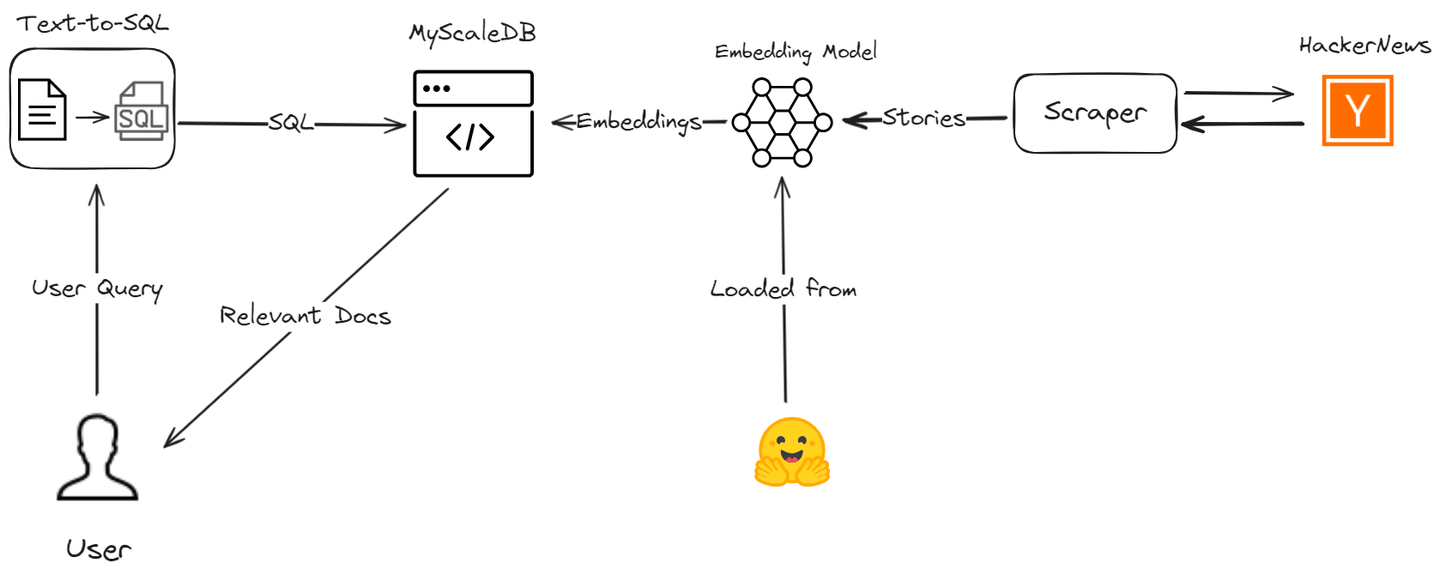
Nuestro modelo RAG avanzado, basado en una base de datos vectorial SQL, gestionará eficientemente varios tipos de consultas. No solo maneja búsquedas de similitud simples, sino que también sobresale en consultas basadas en el tiempo y consultas relacionales complejas.
Veamos cómo superamos estas limitaciones de RAG mediante la creación de un asistente de IA utilizando MyScale (opens new window) y LangChain, mejorando tanto la precisión como la eficiencia del proceso de recuperación de datos. Rastrearemos las últimas historias de Hacker News y te guiaremos a través del proceso para demostrar cómo puedes mejorar tu aplicación RAG con consultas vectoriales SQL avanzadas.
# Herramientas y tecnologías
Utilizaremos varias herramientas, incluyendo MyScaleDB, OpenAI, LangChain, Hugging Face y la API de HackerNews, para desarrollar esta aplicación útil.
- MyScaleDB (opens new window): MyScale es una base de datos vectorial SQL que almacena y procesa datos estructurados y no estructurados de manera eficiente.
- OpenAI (opens new window): Utilizaremos el modelo de chat de OpenAI para generar consultas de texto a SQL.
- LangChain: LangChain ayudará a construir el flujo de trabajo e integrarse sin problemas con MyScale y OpenAI.
- Hugging Face (opens new window): Utilizaremos el modelo de incrustación de Hugging Face para obtener incrustaciones de texto, que se almacenarán en MyScale para su posterior análisis.
- API de HackerNews (opens new window): Esta API obtendrá datos en tiempo real de HackerNews para su procesamiento y análisis.
# Preparación
# Configuración del entorno
Antes de comenzar a escribir el código, debemos asegurarnos de que todas las bibliotecas y dependencias necesarias estén instaladas. Puedes instalarlas usando pip:
pip install requests clickhouse-connect transformers openai langchain
Este comando de pip debería instalar todas las dependencias requeridas en este proyecto.
# Importar bibliotecas y definir funciones auxiliares
Primero, importamos las bibliotecas necesarias y definimos las funciones auxiliares que se utilizarán para obtener y procesar datos de Hacker News.
import requests
from datetime import datetime, timedelta
import pandas as pd
import numpy as np
# Obtener IDs de historias desde un punto final específico
def fetch_story_ids(endpoint):
url = f'https://hacker-news.firebaseio.com/v0/{endpoint}.json'
response = requests.get(url)
return response.json()
# Obtener detalles de un elemento específico por ID
def get_item_details(item_id):
item_url = f'https://hacker-news.firebaseio.com/v0/item/{item_id}.json'
item_response = requests.get(item_url)
return item_response.json()
# Obtener comentarios de forma recursiva para una historia
def fetch_comments(comment_ids, depth=0):
comments = []
for comment_id in comment_ids:
comment_details = get_item_details(comment_id)
if comment_details and comment_details.get('type') == 'comment':
comment_text = comment_details.get('text', '[deleted]')
comment_by = comment_details.get('by', 'Anónimo')
indent = ' ' * depth * 2
comments.append(f"{indent}Comentario de {comment_by}: {comment_text}")
if 'kids' in comment_details:
comments.extend(fetch_comments(comment_details['kids'], depth + 1))
return comments
# Convertir lista de comentarios en una sola cadena
def create_comment_string(comments):
return ' '.join(comments)
# Establecer el límite de tiempo en 12 horas atrás
time_limit = datetime.utcnow() - timedelta(hours=12)
unix_time_limit = int(time_limit.timestamp())
Estas funciones obtienen IDs de historias, obtienen detalles de elementos específicos, obtienen comentarios de forma recursiva y convierten comentarios en una sola cadena.
# Obtener y procesar historias
A continuación, obtenemos las últimas historias y las mejores historias de Hacker News y las procesamos para extraer datos relevantes.
# Obtener las últimas y las mejores historias
latest_stories_ids = fetch_story_ids('newstories')
top_stories_ids = fetch_story_ids('topstories')
# Obtener las 20 mejores historias
top_stories = [get_item_details(story_id) for story_id in top_stories_ids[:20]]
# Obtener todas las últimas historias de las últimas 12 horas
latest_stories = [get_item_details(story_id) for story_id in latest_stories_ids if get_item_details(story_id).get('time', 0) >= unix_time_limit]
# Preparar datos para DataFrame
data = []
def process_stories(stories):
for story in stories:
if story:
story_time = datetime.utcfromtimestamp(story.get('time', 0))
if story_time >= time_limit:
story_data = {
'Título': story.get('title', 'Sin título'),
'URL': story.get('url', 'Sin URL'),
'Puntuación': story.get('score', 0),
'Tiempo': convert_unix_to_datetime(story.get('time', 0)),
'Autor': story.get('by', 'Anónimo'),
'Comentarios': story.get('descendants', 0) # Manejar correctamente el número de comentarios
}
# Obtener comentarios si los hay
if 'kids' in story:
comments = fetch_comments(story['kids'])
story_data['Comentarios_Cadena'] = create_comment_string(comments)
else:
story_data['Comentarios_Cadena'] = ""
data.append(story_data)
# Procesar las últimas y las mejores historias
process_stories(latest_stories)
process_stories(top_stories)
# Crear DataFrame
df = pd.DataFrame(data)
# Asegurar tipos de datos correctos
df['Puntuación'] = df['Puntuación'].astype(np.uint64)
df['Comentarios'] = df['Comentarios'].astype(np.uint64)
df['Tiempo'] = pd.to_datetime(df['Tiempo'])
Obtenemos las últimas historias y las mejores historias de Hacker News utilizando las funciones auxiliares definidas anteriormente. Procesamos las historias obtenidas para extraer información relevante como título, URL, puntuación, tiempo, autor y comentarios. También convertimos la lista de comentarios en una sola cadena.
# Inicializar el modelo Hugging Face para incrustación
Ahora generaremos incrustaciones para los títulos y comentarios de las historias utilizando un modelo pre-entrenado. Este paso es crucial para crear un sistema de generación aumentada por recuperación (RAG).
import torch
from transformers import AutoTokenizer, AutoModel
# Inicializar el tokenizador y el modelo para las incrustaciones
tokenizer = AutoTokenizer.from_pretrained("sentence-transformers/all-MiniLM-L6-v2")
model = AutoModel.from_pretrained("sentence-transformers/all-MiniLM-L6-v2")
# Generar incrustaciones después de crear el DataFrame
empty_embedding = np.zeros(384, dtype=np.float32) # Suponiendo que el tamaño de la incrustación es 384
def generate_embeddings(texts):
inputs = tokenizer(texts, padding=True, truncation=True, return_tensors="pt", max_length=512)
with torch.no_grad():
outputs = model(**inputs)
embeddings = outputs.last_hidden_state.mean(dim=1)
return embeddings.numpy().astype(np.float32).flatten()
Cargamos un modelo pre-entrenado para generar incrustaciones utilizando la biblioteca transformers de Hugging Face y generamos incrustaciones para los títulos y comentarios de las historias.
# Manejo de comentarios largos
Para manejar comentarios largos que exceden la longitud máxima de tokens del modelo, los dividimos en partes manejables.
# Función para manejar comentarios largos
def handle_long_comments(comments, max_length):
parts = [' '.join(comments[i:i + max_length]) for i in range(0, len(comments), max_length)]
return parts
Esta función divide comentarios largos en partes que se ajustan a la longitud máxima de tokens del modelo.
# Procesar historias para incrustaciones
Finalmente, procesamos cada historia para generar incrustaciones para los títulos y comentarios y creamos un DataFrame final.
# Procesar cada historia para incrustaciones
final_data = []
for story in data:
title_embedding = generate_embeddings([story['Título']]).tolist()
comments_string = story['Comentarios_Cadena']
if comments_string and isinstance(comments_string, str):
max_length = tokenizer.model_max_length # Usar la longitud máxima de tokens del modelo
if len(comments_string.split()) > max_length:
parts = handle_long_comments(comments_string.split(), max_length)
for part in parts:
part_comments_string = ' '.join(part)
comments_embeddings = generate_embeddings([part_comments_string]).tolist() if part_comments_string else empty_embedding.tolist()
final_data.append({
'Título': story['Título'],
'URL': story['URL'],
'Puntuación': story['Puntuación'],
'Tiempo': story['Tiempo'],
'Autor': story['Autor'],
'Comentarios': story['Comentarios'],
'Comentarios_Cadena': part_comments_string,
'Incrustación_Título': title_embedding,
'Incrustación_Comentarios': comments_embeddings
})
else:
comments_embeddings = generate_embeddings([comments_string]).tolist() if comments_string else empty_embedding.tolist()
final_data.append({
'Título': story['Título'],
'URL': story['URL'],
'Puntuación': story['Puntuación'],
'Tiempo': story['Tiempo'],
'Autor': story['Autor'],
'Comentarios': story['Comentarios'],
'Comentarios_Cadena': comments_string,
'Incrustación_Título': title_embedding,
'Incrustación_Comentarios': comments_embeddings
})
else:
story['Incrustación_Título'] = title_embedding
story['Incrustación_Comentarios'] = empty_embedding.tolist()
final_data.append(story)
# Crear DataFrame final
final_df = pd.DataFrame(final_data)
# Asegurar tipos de datos correctos en el DataFrame final
final_df['Puntuación'] = final_df['Puntuación'].astype(np.uint64)
final_df['Comentarios'] = final_df['Comentarios'].astype(np.uint64)
final_df['Tiempo'] = pd.to_datetime(final_df['Tiempo'])
En este paso, procesamos cada historia para generar incrustaciones para los títulos y comentarios, manejamos comentarios largos si es necesario y creamos un DataFrame final con todos los datos procesados.
# Conexión a MyScaleDB y creación de la tabla
MyScaleDB es una base de datos vectorial SQL avanzada que mejora los modelos RAG mediante el manejo eficiente de consultas complejas (opens new window) y búsquedas de similitud como búsqueda de texto completo (opens new window) y búsqueda vectorial filtrada (opens new window).
Nos conectaremos a MyScaleDB utilizando clickhouse-connect y crearemos una tabla para almacenar las historias obtenidas.
import clickhouse_connect
client = clickhouse_connect.get_client(
host='tu-host',
port=443,
username='tu-usuario',
password='tu-contraseña'
)
client.command("DROP TABLE IF EXISTS default.posts")
client.command("""
CREATE TABLE default.posts (
id UInt64,
Título String,
URL String,
Puntuación UInt64,
Tiempo DateTime64,
Autor String,
Comentarios UInt64,
Incrustación_Título Array(Float32),
Incrustación_Comentarios Array(Float32),
CONSTRAINT check_data_length CHECK length(Incrustación_Título) = 384
) ENGINE = MergeTree()
ORDER BY id
""")
Este código importa la biblioteca clickhouse-connect y establece una conexión con MyScaleDB utilizando las credenciales proporcionadas. Elimina la tabla existente default.posts si existe y crea una nueva tabla con el esquema especificado.
Nota: MyScaleDB proporciona un pod gratuito para el almacenamiento vectorial de 5 millones de vectores. Por lo tanto, puedes comenzar a usar MyScaleDB en tu aplicación RAG sin ningún pago inicial.
# Inserción de datos y creación de un índice vectorial
Ahora, insertamos los datos procesados en la tabla de MyScaleDB y creamos un índice para permitir la recuperación eficiente de datos.
tamaño_lote = 20 # Ajustar según tus necesidades
num_lotes = len(final_df) // tamaño_lote
for i in range(num_lotes):
inicio = i * tamaño_lote
fin = inicio + tamaño_lote
datos_lote = final_df[inicio:fin]
client.insert("default.posts", datos_lote, column_names=['Título', 'URL', 'Puntuación', "Tiempo",'Autor', 'Comentarios','Incrustación_Título','Incrustación_Comentarios'])
print(f"Lote {i+1}/{num_lotes} insertado.")
client.command("""
ALTER TABLE default.posts
ADD VECTOR INDEX photo_embed_index Incrustación_Título
TYPE MSTG
('metric_type=Cosine')
""")
Este código inserta los datos en la tabla default.posts en lotes para gestionar grandes cantidades de datos de manera eficiente. Se crea un índice vectorial en la columna Incrustación_Título.
# Configuración de la plantilla de consulta para generación
Configuramos una plantilla de consulta para convertir consultas de lenguaje natural en consultas SQL de MyScaleDB.
plantilla_consulta = """
Eres un experto en MyScaleDB. Dada una pregunta de entrada, primero crea una consulta de MyScaleDB sintácticamente correcta para ejecutar, luego mira los resultados de la consulta y devuelve la respuesta a la pregunta de entrada.
Las consultas de MyScaleDB tienen una función de distancia vectorial llamada `DISTANCE(columna, array)` para calcular la relevancia con la pregunta del usuario y ordenar la columna de características por relevancia. La función `DISTANCE(columna, array)` solo acepta una columna de matriz como primer argumento y una `Incrustación(entidad)` como segundo argumento. También necesitas una función definida por el usuario llamada `Incrustación(entidad)` para obtener la matriz de la entidad.
Cuando la consulta pregunta por las filas más cercanas basadas en una palabra clave específica (por ejemplo, "campo de IA" o "criticar"), debes usar esta función de distancia para calcular la distancia a la matriz de la entidad en la columna vectorial y ordenar por la distancia para recuperar las filas relevantes. Si la pregunta implica restricciones de tiempo (por ejemplo, "últimas 7 horas"), usa la función `today()` para obtener la fecha y hora actual.
Si la pregunta especifica el número de ejemplos a obtener, usa ese número; de lo contrario, consulta como máximo {top_k} resultados utilizando la cláusula LIMIT según MyScale. Solo ordena según la función de distancia cuando sea necesario. Nunca consultes todas las columnas de una tabla; consulta solo las columnas necesarias para responder la pregunta y envuelve cada nombre de columna entre comillas dobles (") para denotarlos como identificadores delimitados.
Ten cuidado de usar solo los nombres de columna presentes en las tablas a continuación y asegúrate de saber a qué tabla pertenece cada columna. La cláusula `ORDER BY` siempre debe estar después de la cláusula `WHERE`. No agregues un punto y coma al final del SQL.
Presta atención a los siguientes pasos al construir la consulta:
1. Identifica las palabras clave en la pregunta de entrada (por ejemplo, "artículos más votados", "últimas 7 horas", "campo de IA").
2. Asocia las palabras clave con componentes de consulta específicos (por ejemplo, "más votados" se asocia con "Puntuación DESC").
3. Si la pregunta implica relevancia con una palabra clave (por ejemplo, "criticar"), usa la función de distancia. De lo contrario, usa cláusulas SQL estándar.
4. Si la pregunta menciona el título o los comentarios específicamente, calcula la distancia en consecuencia. Por defecto, calcula la distancia con el título.
5. Usa `Incrustación(palabra clave)` para obtener incrustaciones para palabras clave y úsalas en la función `DISTANCE` solo cuando la consulta involucre una búsqueda de relevancia de palabras clave.
6. Asegúrate de considerar la columna de comentarios si se menciona explícitamente en la pregunta.
7. No uses dist en una consulta donde no hayas encontrado ninguna distancia y asegúrate de usar order by dist con otras columnas también donde se calcule la distancia.
Preguntas de ejemplo y cómo manejarlas:
1. "¿Cuáles son los artículos más votados durante las últimas 7 horas en el campo de IA?"
- Extrae palabras clave: "artículos más votados", "últimas 7 horas", "campo de IA".
- Asocia "más votados" con "Puntuación DESC".
- Construye una consulta para los artículos más votados en las últimas 7 horas:
- `SELECT DISTINCT "Título", "URL", "Puntuación", DISTANCE("Incrustación_Título", Incrustación('campo de IA')) FROM posts1 WHERE Tiempo >= today() - INTERVAL 7 HOUR ORDER BY Puntuación DESC LIMIT {top_k}`
2. "Muéstrame algunos comentarios donde la gente está criticando el contenido."
- Extrae palabras clave: "comentarios", "criticando".
- Asocia "criticando" con la función DISTANCE.
- Construye una consulta para comentarios relevantes:
- `SELECT DISTINCT "Comentarios", "Puntuación", DISTANCE("Incrustación_Comentarios", Incrustación('criticando')) as dist FROM posts1 ORDER BY dist LIMIT {top_k}`
3. "¿Cuáles fueron las historias más votadas durante las últimas 6 horas?"
- Extrae palabras clave: "historias más votadas", "últimas 6 horas".
- Asocia "más votadas" con "Puntuación DESC".
- Construye una consulta simple para las historias más votadas en las últimas 6 horas:
- `SELECT DISTINCT "Título", "URL", "Puntuación" FROM posts1 WHERE Tiempo >= today() - INTERVAL 6 HOUR ORDER BY Puntuación DESC LIMIT {top_k}`
4. "¿Cuáles son las historias de tendencia en el campo de IA?"
- Extrae palabras clave: "historias de tendencia", "campo de IA".
- Asocia "tendencia" con "Puntuación DESC".
- Construye una consulta para las historias de tendencia en el campo de IA:
- `SELECT DISTINCT "Título", "URL", "Puntuación", DISTANCE("Incrustación_Título", Incrustación('campo de IA')) as dist FROM posts1 ORDER BY dist, Puntuación DESC LIMIT {top_k}`
5. "Muéstrame algunos comentarios que estén discutiendo las últimas tendencias de LLMs."
- Extrae palabras clave: "comentarios", "últimas tendencias de LLMs".
- Asocia "últimas tendencias de LLMs" con la función DISTANCE.
- Construye una consulta para comentarios que discutan las últimas tendencias de LLMs:
- `SELECT DISTINCT "Comentarios", "Puntuación", DISTANCE("Incrustación_Comentarios", Incrustación('últimas tendencias de LLMs')) as dist FROM posts1 ORDER BY dist LIMIT {top_k}`
Ahora, creemos la consulta en función de la entrada proporcionada.
======== información de la tabla ========
{table_info}
Pregunta: {input}
Consulta SQL: "
Elimina \n,\, " o cualquier tipo de letra redundante de la consulta y ten cuidado de no consultar columnas que no existen.
"""
def generar_prompt_final(input, table_info, top_k=5):
prompt_final = plantilla_consulta.format(input=input, table_info=table_info, top_k=top_k)
return prompt_final
Este código configura una plantilla de consulta que guía al modelo de lenguaje para generar consultas SQL correctas de MyScaleDB basadas en las preguntas de entrada.
# Configuración de los parámetros de la consulta
Configuramos los parámetros para la generación de consultas.
top_k = 5
table_info = """
posts1 (
id UInt64,
Título String,
URL String,
Puntuación UInt64,
Tiempo DateTime64,
Autor String,
Comentarios UInt64,
Incrustación_Título Array(Float32),
Incrustación_Comentarios Array(Float32)
)
"""
Este código establece el número de principales resultados a recuperar (top_k), define la información de la tabla (table_info) y establece una cadena de entrada vacía (input) para la pregunta.
# Configuración del modelo
En este paso, configuraremos el modelo de OpenAI para convertir las entradas de usuario en consultas SQL.
from langchain.chat_models import ChatOpenAI
modelo = ChatOpenAI(openai_api_key="clave-api-de-open-ai")
# Convertir texto a SQL
Este método primero genera un prompt final basado en la entrada del usuario y la información de la tabla, luego utiliza el modelo de OpenAI para convertir el texto en una consulta vectorial SQL.
def obtener_consulta(entrada_usuario):
prompt_final = generar_prompt_final(entrada_usuario, table_info, top_k)
texto_respuesta = modelo.predecir(prompt_final)
return texto_respuesta
entrada_usuario="¿Cuáles son las historias más votadas?"
respuesta=obtener_consulta(entrada_usuario)
Después de este paso, obtendremos una consulta como esta:
'SELECT DISTINCT "Título", "URL", "Puntuación", DISTANCE("Incrustación_Título", Incrustación(\'campo de IA\')) as dist FROM posts1 ORDER BY dist, Puntuación DESC LIMIT 5'
Pero MyScaleDB DISTANCE espera DISTANCE(columna, array). Por lo tanto, necesitamos convertir la parte Incrustación(\'campo de IA\') a incrustaciones vectoriales.
# Procesamiento y reemplazo de incrustaciones en una cadena de consulta
Este método se utilizará para reemplazar Incrustación("Palabras clave extraídas") por una matriz de float32.
import re
def procesar_consulta(consulta):
patrón = re.compile(r'Incrustación\(([^)]+)\)')
coincidencias = patrón.findall(consulta)
for coincidencia in coincidencias:
incrustación_procesada = str(list(generate_embeddings(coincidencia)))
consulta = consulta.replace(f'Incrustación({coincidencia})', incrustación_procesada)
return consulta
consulta=procesar_consulta(f"""{respuesta}""")
Este método toma la consulta como entrada y devuelve la consulta actualizada si hay algún método Incrustación presente en la cadena de consulta.

# Ejecución de una consulta
Finalmente, ejecutamos una consulta para recuperar las historias relevantes de la base de datos vectorial.
consulta=consulta.replace("\n","")
resultados = client.query(f"""{consulta}""")
for fila in resultados.named_results():
print("Título ", fila["Título"])
Además, puedes tomar la consulta devuelta por el modelo, extraer las columnas especificadas y usarlas para obtener las columnas como se muestra arriba. Estos resultados luego se pueden pasar a un modelo de chat, creando un asistente de chat de IA completo. De esta manera, el asistente puede responder dinámicamente a las consultas de los usuarios con datos relevantes extraídos directamente de los resultados, asegurando una experiencia fluida e interactiva.
# Conclusión
RAG simple tiene un uso limitado debido a su enfoque en búsquedas de similitud sencillas. Sin embargo, cuando se combina con herramientas avanzadas como MyScaleDB, LangChain, etc., las aplicaciones RAG no solo pueden cumplir, sino superar las demandas de gestión de grandes volúmenes de datos. Pueden manejar una gama más amplia de consultas, incluidas consultas basadas en el tiempo y consultas relacionales complejas, mejorando significativamente el rendimiento y la eficiencia de tus sistemas actuales.
Si tienes alguna sugerencia, contáctanos a través de Twitter (opens new window) o Discord (opens new window).
Este artículo se publicó originalmente en The New Stack. (opens new window)



