
Los vectores nos permiten ir más allá del aprendizaje que consume tiempo/recursos y utilizar búsquedas simples que son mucho más rápidas y efectivas. Las bases de datos vectoriales son muy útiles para almacenar datos vectoriales de alta dimensión, como datos numéricos, de texto o de imágenes. Las bases de datos vectoriales SQL, como MyScale, evitan a las personas el problema de preocuparse por el manejo de datos complejos y otras operaciones de backend utilizando el poder de SQL y otras características interesantes como la indexación MSTG.
Amazon (opens new window)Bedrock (opens new window) es un servicio administrado que nos permite construir aplicaciones de IA con modelos base (tanto de texto como de imagen). Ofrece ventajas como la escalabilidad de AWS, lo que nos permite ajustar el modelo de forma privada, etc. Podemos llamar a estos servicios de forma tan sencilla como a las bibliotecas de Python normales, como Scikit-learn o NLTK.
Este artículo demuestra cómo construir una aplicación de búsqueda semántica para libros electrónicos utilizando Amazon Bedrock y MyScale. Los lectores electrónicos tradicionales, como Acrobat Reader, Kindle, Apple Books u otros lectores, a menudo limitan las búsquedas a coincidencias exactas de palabras clave. Aprovechando los modelos base de Amazon Bedrock para la generación de incrustaciones y las capacidades de la base de datos vectorial de MyScale, creamos una función de búsqueda más inteligente que va más allá de la coincidencia de palabras clave para comprender el significado semántico. Al aprovechar las fortalezas de los modelos de IA de Bedrock junto con las capacidades de almacenamiento y búsqueda eficientes de MyScale, puedes mejorar la efectividad de las búsquedas de texto en una variedad de aplicaciones.
# Instalación de bibliotecas
Con cualquier proyecto de Python, es una buena práctica crear un entorno. Aquí utilizamos Conda para crear un entorno para el proyecto:
conda create --name AWS python=3.12
Después de activarlo, instalaremos las bibliotecas correspondientes.
pip install boto3 langchain-aws clickhouse-connect
# Conexión con MyScale
Después de crear la cuenta en MyScale (opens new window), puedes ejecutar el clúster desde la Consola (opens new window). En los detalles del clúster encontrarás la cadena de conexión. Simplemente cópiala y pégala para conectarte con el clúster.
import clickhouse_connect
client = clickhouse_connect.get_client(
host='tu-nombre-de-host-aquí',
port=443,
username='tu-nombre-de-usuario-aquí',
password='tu-contraseña-aquí')
Nota:
Para obtener instrucciones detalladas paso a paso, puedes seguir la guía de inicio rápido (opens new window) para obtener los detalles de conexión.
# Prueba de la conexión
Sería útil probar la conexión y la instalación de la biblioteca respectiva creando una pequeña tabla de prueba.
# Crea una tabla con un vector de punto flotante de 128 dimensiones.
client.command("""
CREATE TABLE default.TestTable (
id UInt32,
data Array(Float32),
CONSTRAINT check_length CHECK length(data) = 128,
date Date,
label Enum8('person' = 1, 'building' = 2, 'animal' = 3)
)
ORDER BY id
""")
#['0', 'chi-msc-af209a77-msc-af209a77-0-0', 'OK', '0', '0']
Puedes verificar todas las tablas en el clúster y probar la conexión utilizando la consulta "SHOW TABLES".
# Obtén e imprime los nombres de todas las tablas en la base de datos actual.
res = client.query("SHOW TABLES").named_results()
print([r['name'] for r in res])
# ['TestTable']
# Selección del modelo de incrustación
A continuación, necesitamos seleccionar un modelo de incrustación adecuado. Hay dos métodos disponibles para conectarse a Amazon Bedrock: uno es acceder al sitio web oficial de AWS para crear un usuario IAM para Bedrock; el otro método es utilizar directamente la función EmbedText de MyScale, que proporciona una forma más rápida de invocar a Amazon Bedrock.
# Conexión con Amazon Bedrock
Amazon Bedrock es uno de los varios servicios de AWS. Aloja varios modelos base para crear aplicaciones de IA generativas. RAG es una de las áreas especializadas de Bedrock. Algunas de las razones que hacen de Bedrock una buena opción son:
- Alojamiento de AWS: Los alojamientos de AWS son excelentes (los mejores de hecho) y, como resultado, podemos olvidarnos de problemas como la escalabilidad, la seguridad, el tiempo de actividad, etc.
- API sencilla: La API, como veremos en breve, es bastante fácil de usar.
- Pago por uso: No es necesario comprar grandes planes de alojamiento. La función de pago por uso nos permite personalizar nuestro uso según nuestras necesidades.
# Creación de una cuenta
En primer lugar, debes crear un usuario IAM (bedrock_test en este caso) para utilizar Bedrock.
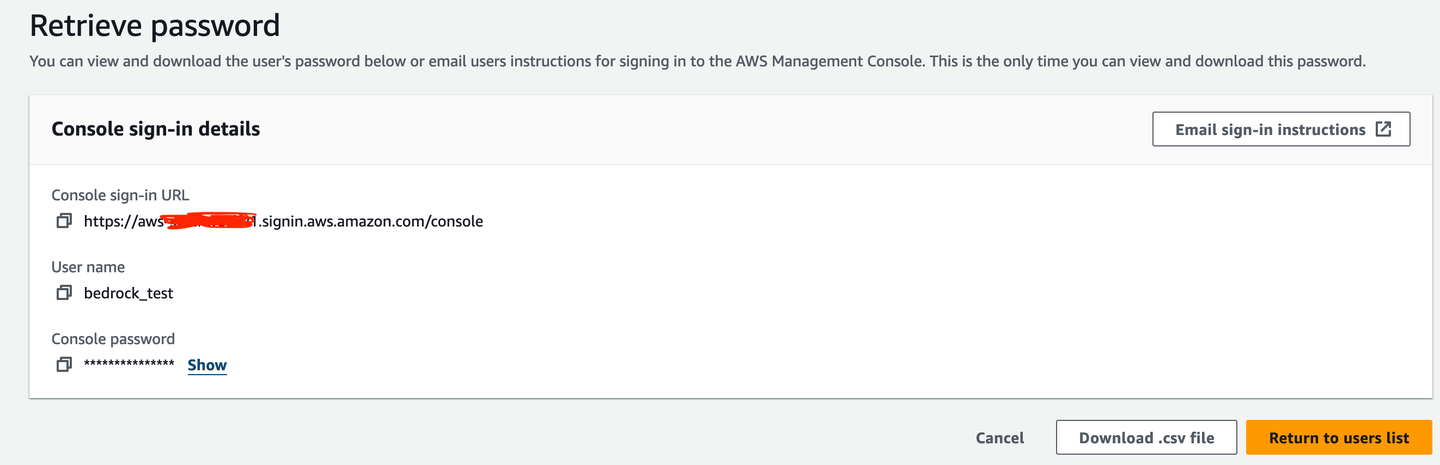
Luego, necesitas una clave de acceso para el acceso desde la terminal.

Sería útil descargarlo como un archivo .csv en caso de que olvides la clave de acceso. Por supuesto, un administrador de contraseñas es la mejor opción para que puedas copiarla de allí cuando sea necesario.
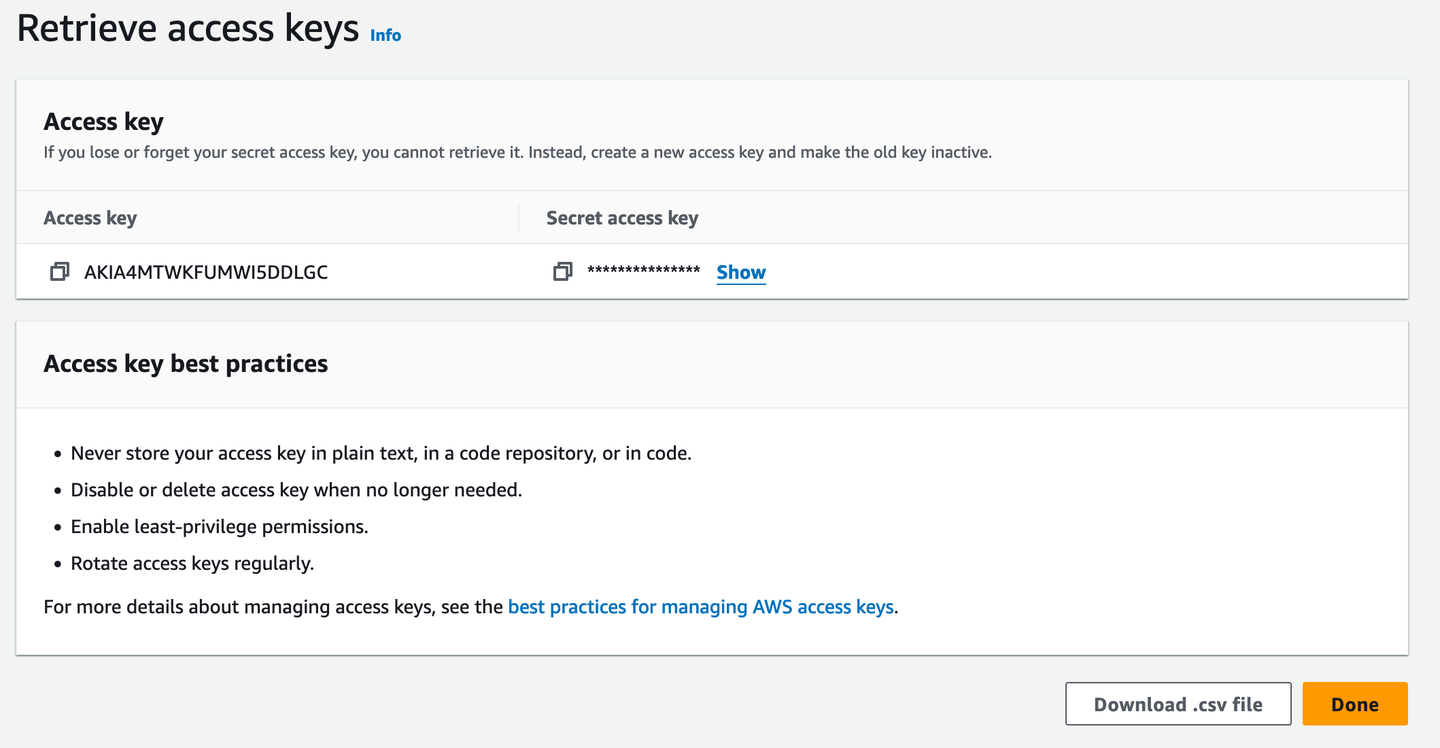
# API de Python
Puedes importar y conectar Bedrock con el servicio. Por lo general, preferimos conectarnos a la región us-east-1.
import boto3
bedrockInterface = boto3.client(service_name="bedrock-runtime", region_name='us-east-1')
Si se ejecuta correctamente, significa que el cliente/interfaz de Bedrock se instaló y configuró correctamente. Hasta ahora, ya tenemos algunas preparaciones:
- Configuramos y conectamos MyScale
- Configuramos y conectamos Bedrock
# Selección de modelos
Antes de implementar la búsqueda semántica en la novela utilizando un modelo de incrustación, es necesario seleccionar el modelo adecuado. A diferencia de las solicitudes de datos habituales que llevan tiempo y se conceden generalmente de inmediato, para acceder al modelo, ve a la parte inferior de la barra lateral y encontrarás la opción correspondiente.
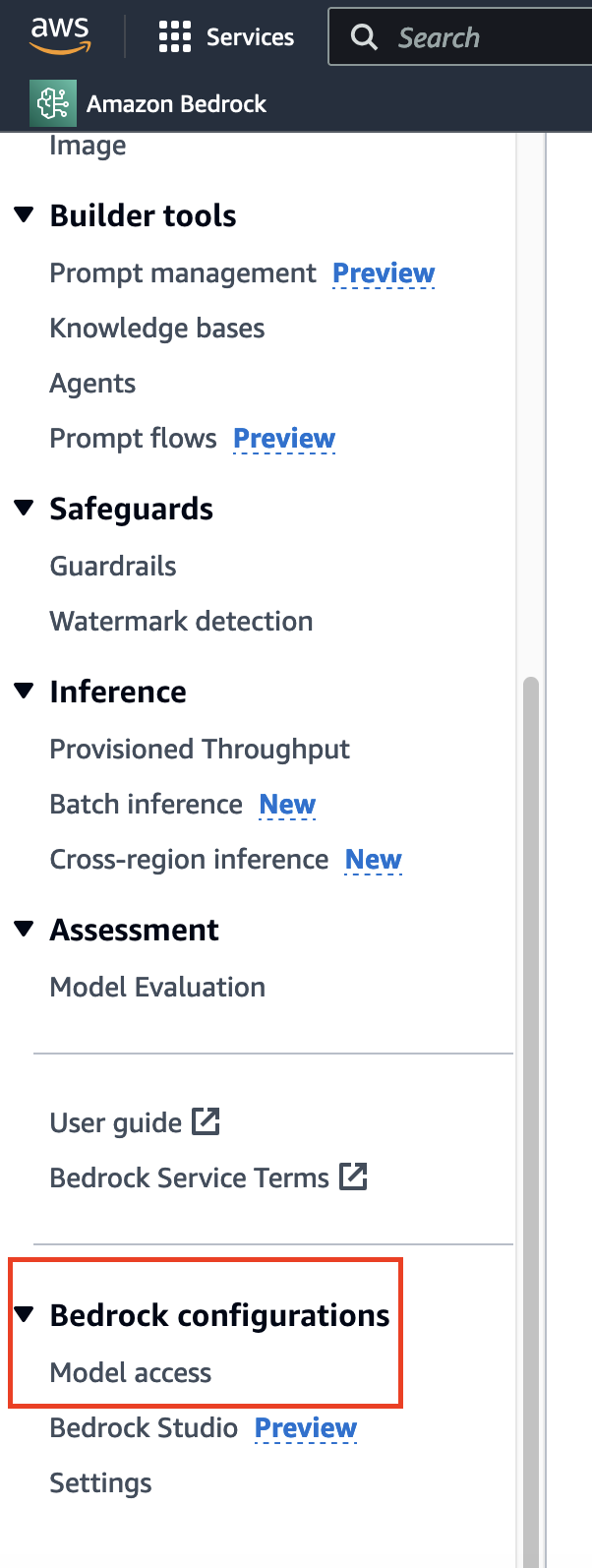
Aquí, ya tengo acceso, por lo que verás "Acceso concedido" para la mayoría de los modelos. Si lo estás utilizando por primera vez, puedes hacer clic en "Modificar acceso al modelo" y habilitar el acceso a los modelos correspondientes.

Nota:
La disponibilidad de algunos modelos depende de la región que elijas (opens new window).
# Titan Embeddings
Para este tutorial, utilizaremos el modelo de incrustaciones de Titan (opens new window). En primer lugar, se aplica el método invoke_model() del cliente/interfaz que acabamos de crear para utilizar el modelo. Dado que hemos especificado JSON como el modus operandi, debemos asegurarnos de que tanto las entradas como las salidas estén en este formato.
import json
consulta = "¿Por qué el número 42 es tan significativo en la literatura?"
consulta_json = json.dumps({
"inputText": consulta,
})
Ahora puedes llamar a invoke_model(). Como se puede ver, la salida es un diccionario.
resultado = bedrockInterface.invoke_model(modelId="amazon.titan-embed-text-v1", body=consulta_json)
# Salida
{'ResponseMetadata': {'RequestId': 'dcbcb135-8b6b-4da4-adbd-523c8c240da6',
'HTTPStatusCode': 200,
'HTTPHeaders': {'date': 'Wed, 18 Sep 2024 03:05:53 GMT',
'content-type': 'application/json',
'content-length': '17180',
'connection': 'keep-alive',
'x-amzn-requestid': 'dcbcb135-8b6b-4da4-adbd-523c8c240da6',
'x-amzn-bedrock-invocation-latency': '68',
'x-amzn-bedrock-input-token-count': '12'},
'RetryAttempts': 0},
'contentType': 'application/json',
'body': <botocore.response.StreamingBody at 0x151b1c880>}
Para decodificar el body, utilizamos nuevamente el cargador JSON.
cuerpo_respuesta = json.loads(resultado.get('body').read())
# Salida
{'embedding': [-0.35351562,
-0.3203125,
-0.083496094,
0.04711914,
0.0034332275,
0.24902344,
-0.13183594,
-4.798174e-06,
-0.28320312,
.
.
.
0.7890625,
...],
'inputTextTokenCount': 12}
Está bien, pero LangChain proporciona una clase mucho más sencilla, BedrockEmbeddings. Utilizará la bedrockInterface que ya hemos declarado anteriormente.
from langchain_aws import BedrockEmbeddings
embeddingOutput = BedrockEmbeddings(client=bedrockInterface)
BedrockEmbeddings contiene varios métodos. Uno de ellos es embed_query(), que toma una cadena de texto y devuelve la incrustación. Dado que estamos utilizando el modelo Titan, deberíamos esperar un vector de incrustación de longitud 1536.
x = embeddingGenerator.embed_query("¿Cómo va todo?")
len(x)
# 1536
# Guardar las incrustaciones en MyScale
Ahora, también estamos obteniendo las incrustaciones del modelo correspondiente, lo que significa que estamos en una posición perfecta para utilizar la base de datos vectorial. Primero crearemos la tabla para almacenar el texto y las incrustaciones respectivas y la utilizaremos más adelante para la inferencia.
client.command("""
CREATE TABLE IF NOT EXISTS BookEmbeddings (
id UInt64,
sentences String,
embeddings Array(Float32),
CONSTRAINT check_data_length CHECK length(embeddings) = 1536
) ENGINE = MergeTree()
ORDER BY id;
""")
# Funciones de incrustación de MyScale
MyScale proporciona funciones integradas para diversos fines, incluido el acceso a modelos de ML. Una de estas funciones es EmbedText(), que es muy valiosa debido a varias razones:
- Interfaz directa para calcular las incrustaciones del texto de entrada.
- La capacidad de llamar a una serie de diversas API como Bedrock, Hugging Face, Open AI, etc.
EmbedText() (opens new window) toma varios argumentos. Si hablamos específicamente de Bedrock, todo lo que necesitamos son:
- Texto de entrada: El texto del que queremos obtener la incrustación.
- Proveedor: Será 'Bedrock' en nuestro caso.
- URL de la API: Algunas API pueden utilizar URL, pero no es necesario en nuestro caso y se mantendrá como una cadena vacía.
api_key: La clave de acceso secreta (de AWS) de la que hablamos anteriormente.access_key_id: El ID de clave correspondiente.model: ID del modelo (uno en Bedrock).region_name: Nombre de la región de AWS.
Por ejemplo, utilizaremos esta función de la siguiente manera:
SELECT EmbedText('Llámame Ismael. Hace algunos años, no importa cuánto tiempo exactamente, teniendo poco o ningún dinero en mi bolsillo y nada en particular que me interesara en tierra, pensé en navegar un poco y ver la parte acuática del mundo.', 'Bedrock', '', 'xxxxxxxx', '{"model":"amazon.titan-embed-text-v1", "region_name":"us-east-1", "access_key_id":"xxxxxx"}')
Dado que es una función escalar, obtenemos esta salida directa.

Ahora, cada vez que llamamos a esta función, todos los argumentos excepto el texto de entrada son los mismos. Por lo tanto, podemos personalizarlo de la siguiente manera:
CREATE FUNCTION EmbedTest AS (x) -> EmbedText(x, 'Bedrock', '', 'xxxx', '{"model":"amazon.titan-embed-text-v1", "region_name":"us-east-1", "access_key_id":"xxxxx"}')
SELECT EmbedTest('Llámame Ismael. Hace algunos años, no importa cuánto tiempo exactamente, teniendo poco o ningún dinero en mi bolsillo y nada en particular que me interesara en tierra, pensé en navegar un poco y ver la parte acuática del mundo.')
Esta función personalizada se puede llamar fácilmente desde cualquier lugar. Después de ver esta función de incrustación sencilla (que se puede ampliar con otras API también), volvamos a nuestro front-end para extraer algo de texto, que utilizaremos en el resto del blog.
# Generación de incrustaciones de libros
Ahora elijamos un libro y generemos sus incrustaciones. Por ejemplo, utilizando Gutenberg (opens new window) para tomar el clásico de Tolstói (opens new window):
import requests
url = "<https://www.gutenberg.org/files/1399/1399-0.txt>"
response = requests.get(url)
if response.status_code == 200:
texto_libro = response.content.decode('utf-8-sig')
inicio = texto_libro.find("CHAPTER I")
fin = texto_libro.find("End of the Project Gutenberg EBook")
texto_libro = texto_libro[inicio:fin]
capitulos = re.split(r'(Chapter \\d+)', texto_libro)
capitulos_separados = ["".join(x) for x in zip(capitulos[1::2], capitulos[2::2])]
Ahora tenemos "Ana Karenina" en formato de capítulo por capítulo. Puedes pasar todos ellos a través del modelo Titan para obtener las incrustaciones.
matriz_incrustaciones = [embeddingGenerator.embed_query(capitulo) for capitulo in capitulos_separados]
A continuación, se convertirá en un dataframe e insertará en la tabla.
import pandas as pd
df = pd.DataFrame({
'Texto': capitulos_separados,
'Incrustacion': matriz_incrustaciones
})
registros_df = df.to_records(index=True)
client.insert("BookEmbeddings", registros_df.tolist(), column_names=["id", "sentences", "embeddings"])
Los datos se insertaron correctamente, como se puede confirmar en el espacio de trabajo SQL (opens new window) (en la consola de MyScale).
# Indexación
La indexación es útil para calcular rápidamente la distancia entre las incrustaciones.
client.command("""
ALTER TABLE BookEmbeddings
ADD VECTOR INDEX dist_idx embeddings
TYPE MSTG
""")
Puede llevar unos momentos aplicar este índice (dependiendo de los datos).
# Uso de MyScale para buscar en la novela Ana Karenina
Después de que toda la novela se almacene en la base de datos y se haya creado el índice, volvamos a la base de datos vectorial para ejecutar algunas consultas. Por ejemplo, busquemos los capítulos más relevantes (es decir, recuperación de documentos).
consulta = "¿Qué le sucedió al hermano de Levin?"
incrustaciones_consulta = embeddingGenerator.embed_query(consulta)
resultados = client.command(f"""
SELECT id, sentences, embeddings,
distance(embeddings, {incrustaciones_consulta}) as dist
FROM BookEmbeddings
ORDER BY dist LIMIT 3
""")
En el siguiente resultado, puedes ver que estos 3 capítulos son los más relevantes para abordar la consulta.

consulta = "¿Cuándo fue Dolly a visitar a Anna en su casa?"
incrustaciones_consulta = embeddingGenerator.embed_query(consulta)
resultados = client.command(f"""
SELECT id, sentences, embeddings,
distance(embeddings, {incrustaciones_consulta}) as dist
FROM BookEmbeddings
ORDER BY dist LIMIT 3
""")
Nuevamente, el resultado es notable, ya que podemos ver que la búsqueda vectorial funciona bastante bien en la recuperación.

Jugué un poco y probé una medida diferente (similitud del coseno). Si bien las distancias eran diferentes, obtuve las mismas respuestas que se muestran arriba. En caso de que quieras probarlo, no dudes en eliminar el índice existente y agregar el índice de similitud del coseno.
client.command("""
ALTER TABLE BookEmbeddings
ADD VECTOR INDEX cosine_idx embeddings
TYPE MSTG
('metric_type=Cosine')
""")

# Conclusión
El uso de Amazon Bedrock y MyScale para la búsqueda vectorial ofrece una clara mejora en comparación con las búsquedas basadas en palabras clave tradicionales que se encuentran en la mayoría de los lectores electrónicos. Con la búsqueda semántica, los usuarios pueden encontrar contenido relevante incluso cuando no recuerdan los términos exactos, lo que hace que la experiencia de lectura sea mucho más fluida. Si bien este ejemplo se centra en una sola novela, este enfoque se puede aplicar a una amplia gama de textos, desde otros libros hasta documentos legales o papeles oficiales.
El proceso también es bastante accesible. Todo lo que se muestra aquí se hizo utilizando el nivel gratuito de MyScale, que proporciona recursos suficientes para probar y reproducir los resultados. Al combinar las fortalezas de los modelos base de Bedrock y las capacidades de almacenamiento y búsqueda eficientes de MyScale, puedes manejar las búsquedas de texto de manera más efectiva en una variedad de aplicaciones.



