
En las etapas iniciales del desarrollo de bases de datos, los datos se almacenaban en tablas básicas. Este método era sencillo, pero a medida que la cantidad de datos crecía, se volvía más difícil y lento administrar y recuperar información. Luego se introdujeron las bases de datos relacionales, que ofrecían mejores formas de almacenar y procesar datos.
Una técnica importante en las bases de datos relacionales es la indexación, que es muy similar a la forma en que se almacenan los libros en una biblioteca. En lugar de buscar en toda la biblioteca, se va directamente a una sección específica donde se encuentra el libro requerido. La indexación en las bases de datos funciona de manera similar, acelerando el proceso de búsqueda de los datos que se necesitan.
En este blog, cubriremos los conceptos básicos de la indexación de vectores y cómo se implementa utilizando diferentes técnicas.
# ¿Qué son las incrustaciones de vectores?
Las incrustaciones de vectores son simplemente la representación numérica que se convierte a partir de imágenes, texto y audio. En términos más simples, se crea un vector matemático único para cada elemento que captura la semántica o características de ese elemento. Estas incrustaciones de vectores son más fácilmente comprendidas por los sistemas computacionales y son compatibles con modelos de aprendizaje automático para comprender las relaciones y similitudes entre diferentes elementos.
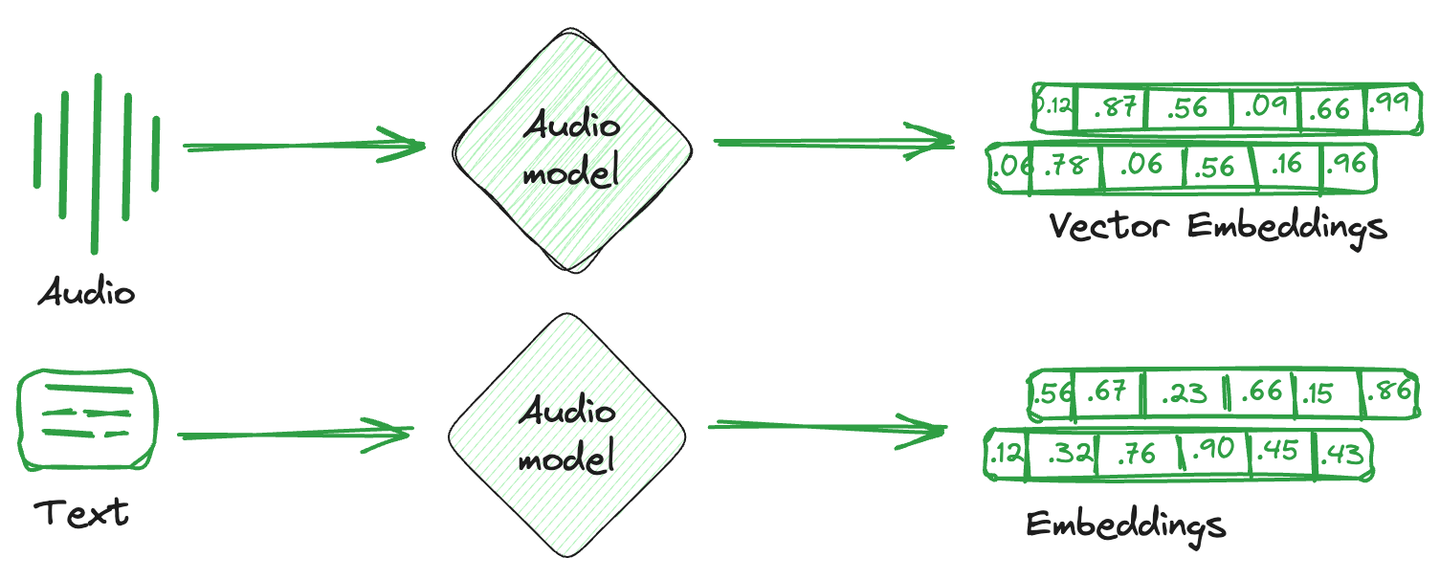
Las bases de datos especializadas utilizadas para almacenar estos vectores de incrustación se conocen como bases de datos de vectores. Estas bases de datos aprovechan las propiedades matemáticas de las incrustaciones que permiten almacenar elementos similares juntos. Se utilizan diferentes técnicas para almacenar vectores similares juntos y vectores diferentes por separado. Estas son técnicas de indexación de vectores.
# ¿Qué es un índice de vectores?
La indexación de vectores no se trata solo de almacenar datos, sino de organizar inteligentemente las incrustaciones de vectores para optimizar el proceso de recuperación. Esta técnica implica algoritmos avanzados para organizar de manera ordenada los vectores de alta dimensión de manera que se puedan buscar y recuperar de manera rápida y precisa. Esta organización no es aleatoria; se realiza de manera que los vectores similares se agrupen juntos, lo que permite búsquedas de similitud rápidas y precisas e identificación de patrones, especialmente para buscar conjuntos de datos grandes y complejos.
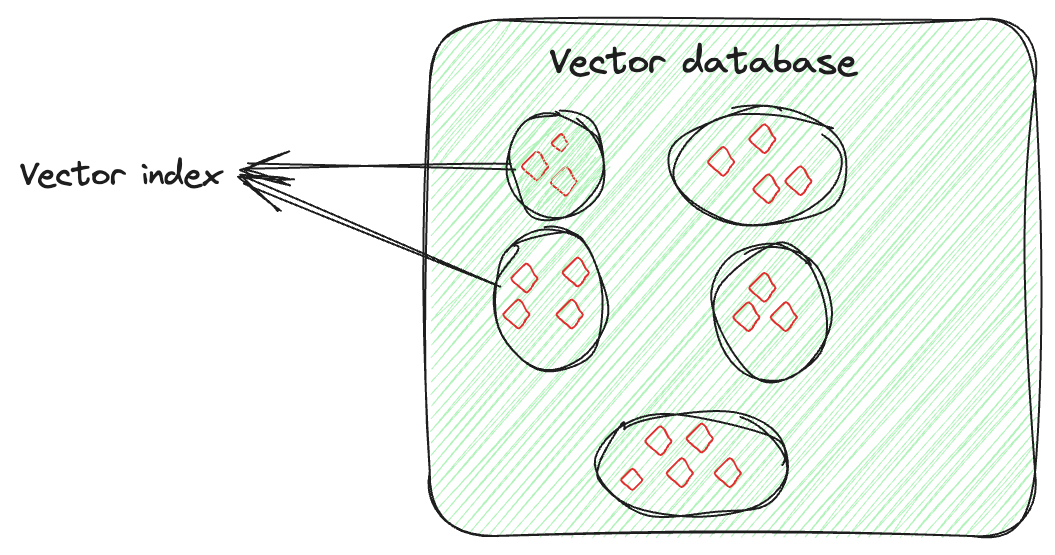
Supongamos que tienes un vector para cada imagen, capturando sus características. El índice de vectores organizará estos vectores de manera que sea más fácil encontrar imágenes similares (aquí). Puedes pensar en ello como si estuvieras organizando las imágenes de cada persona por separado. Entonces, si necesitas una imagen específica de una persona en un evento particular, en lugar de buscar en todas las imágenes, solo revisarías la colección de esa persona y encontrarías fácilmente la imagen.
# Técnicas comunes de indexación de vectores
Se utilizan diferentes técnicas de indexación según los requisitos específicos. Veamos algunas de ellas.
# Archivo invertido (IVF)
Esta es la técnica de indexación más básica. Divide todos los datos en varios grupos utilizando técnicas como el agrupamiento K-means. Cada vector de la base de datos se asigna a un grupo específico. Esta disposición estructurada de vectores permite que las consultas de búsqueda sean mucho más rápidas. Cuando llega una nueva consulta, el sistema no recorre toda la base de datos. En cambio, identifica los grupos más cercanos o más similares y busca el documento específico dentro de esos grupos.
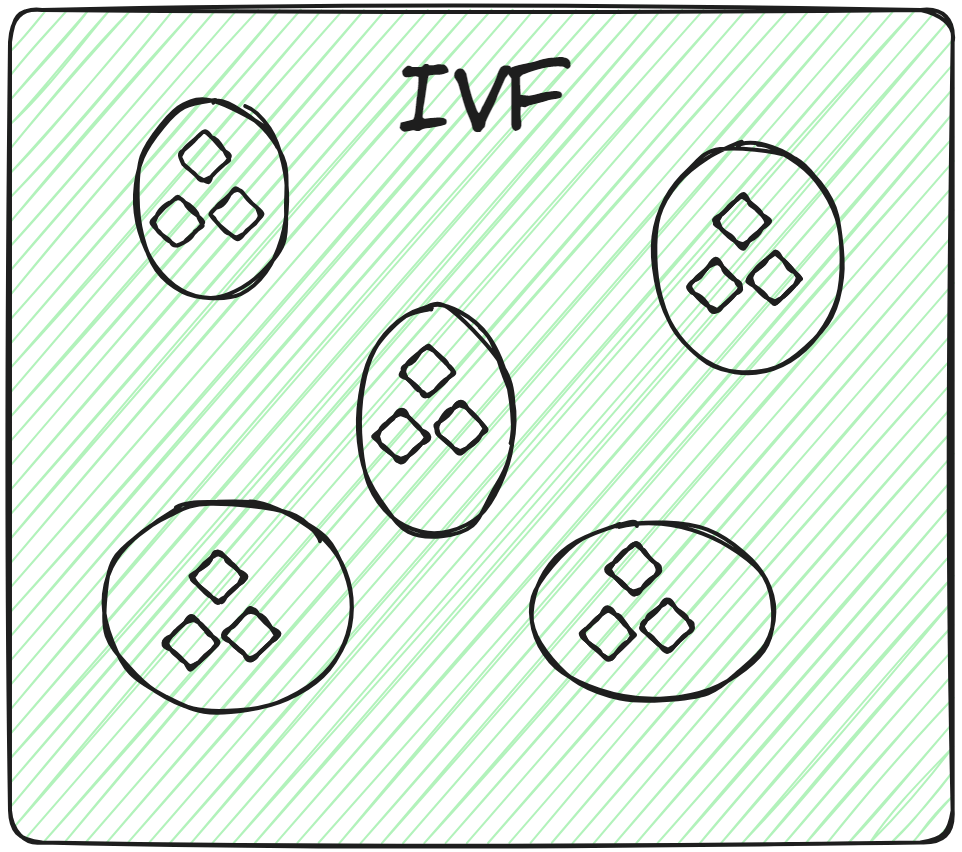
Por lo tanto, al aplicar la búsqueda de fuerza bruta exclusivamente dentro del grupo relevante, en lugar de en toda la base de datos, no solo se mejora la velocidad de búsqueda, sino que también se reduce considerablemente el tiempo de consulta.
# Variantes de IVF: IVFFLAT, IVFPQ e IVFSQ
Existen diferentes variantes de IVF, dependiendo de los requisitos específicos de la aplicación. Veámoslas en detalle.
# IVFFLAT
IVFFLAT (opens new window) es una forma más simple de IVF. Divide el conjunto de datos en grupos, pero dentro de cada grupo utiliza una estructura plana (de ahí el nombre "FLAT") para almacenar los vectores. IVFFLAT está diseñado para optimizar el equilibrio entre la velocidad de búsqueda y la precisión.
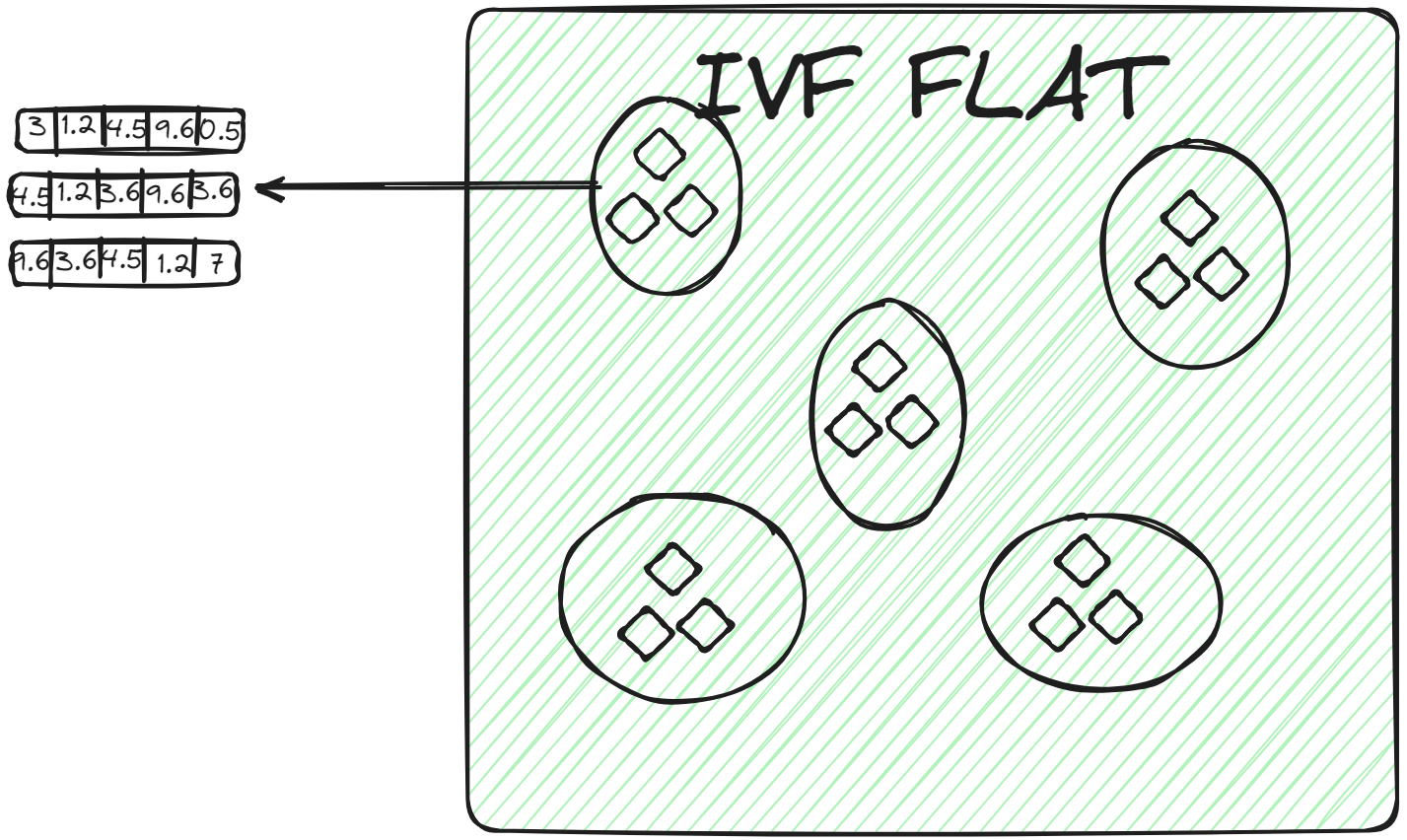
En cada grupo, los vectores se almacenan en una lista o matriz simple sin subdivisiones adicionales ni estructuras jerárquicas. Cuando se asigna un vector de consulta a un grupo, se encuentra el vecino más cercano mediante una búsqueda de fuerza bruta, examinando cada vector en la lista del grupo y calculando su distancia al vector de consulta. IVFFLAT se utiliza en escenarios donde el conjunto de datos no es considerablemente grande y el objetivo es lograr una alta precisión en el proceso de búsqueda.
# IVFPQ
IVFPQ (opens new window) es una variante avanzada de IVF, que significa Inverted File with Product Quantization. También divide los datos en grupos, pero cada vector en un grupo se descompone en vectores más pequeños, y cada parte se codifica o comprime en un número limitado de bits utilizando la cuantización de productos.
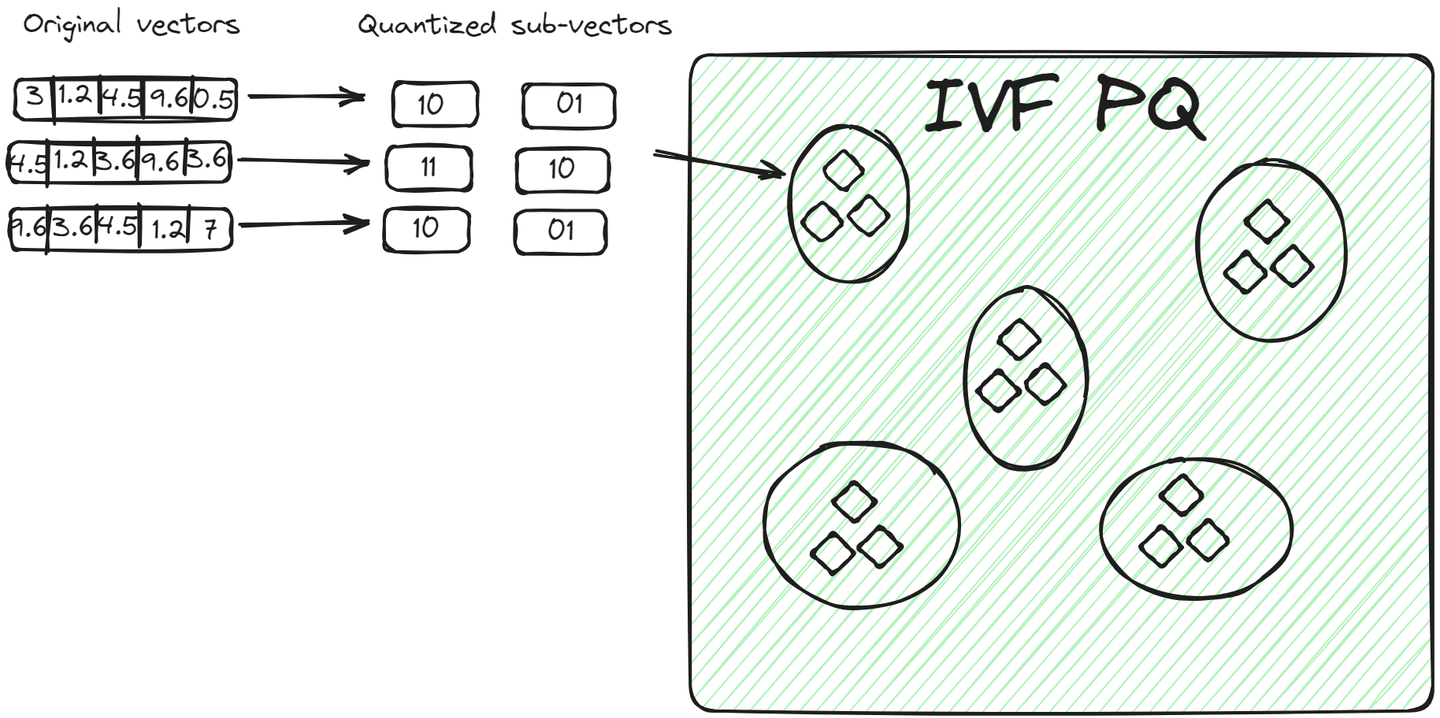
Para un vector de consulta, una vez identificado el grupo relevante, el algoritmo compara la representación cuantizada de la consulta con las representaciones cuantizadas de los vectores dentro del grupo. Esta comparación es más rápida que comparar vectores sin procesar debido a la reducción de dimensionalidad y tamaño lograda mediante la cuantización. Este método tiene dos ventajas sobre el método anterior:
- Los vectores se almacenan de manera compacta, ocupando menos espacio que los vectores sin procesar.
- El proceso de consulta es aún más rápido porque no se comparan todos los vectores sin procesar, sino vectores codificados.
# IVFSQ
File System with Scalar Quantization (IVFSQ) (opens new window), al igual que otras variantes de IVF, también segmenta los datos en grupos. Sin embargo, la diferencia principal es su técnica de cuantización. En IVFSQ, cada vector en un grupo se somete a una cuantización escalar. Esto significa que cada dimensión del vector se maneja por separado.
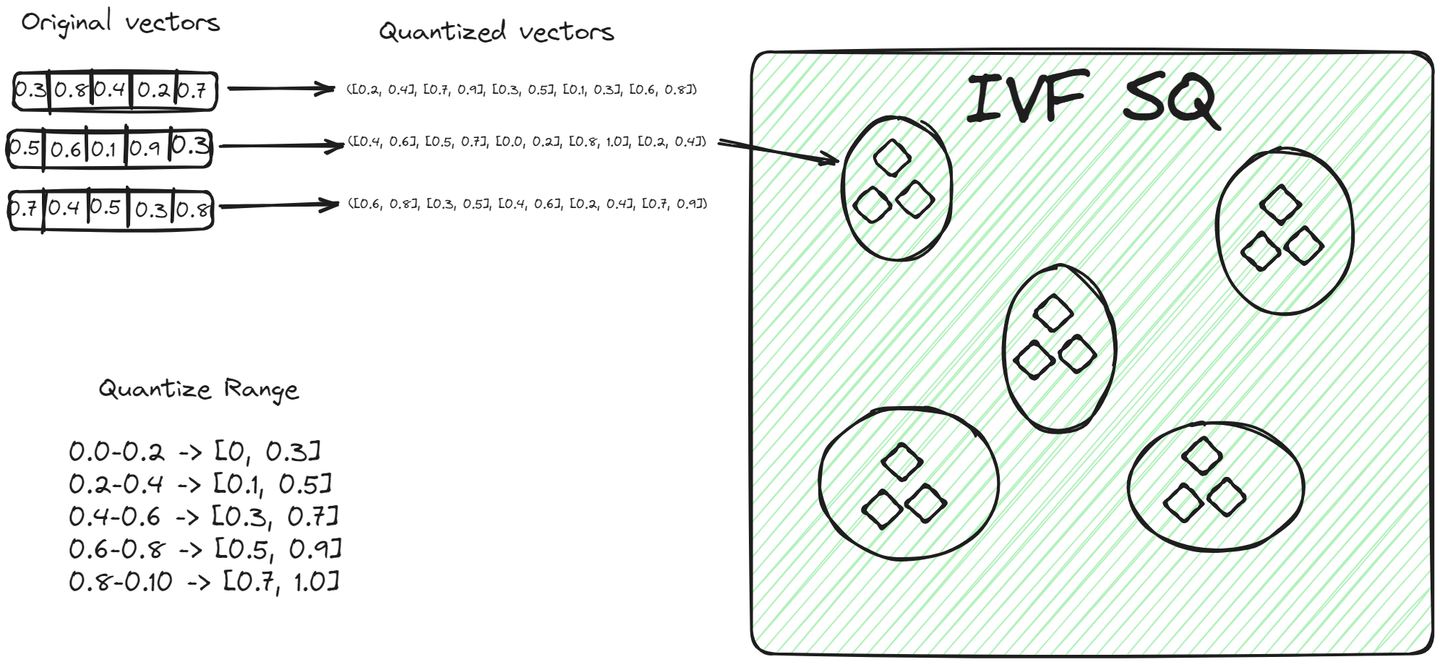
En términos simples, para cada dimensión de un vector, se establece un valor o rango predefinido. Estos valores o rangos ayudan a determinar a qué grupo pertenece un vector. Luego, cada componente del vector se compara con estos valores predefinidos para encontrar su lugar en un grupo. Este método de descomponer y cuantizar cada dimensión por separado hace que el proceso sea más sencillo. Es especialmente útil para datos de baja dimensionalidad, ya que simplifica la codificación y reduce el espacio necesario para el almacenamiento.
# Algoritmo Hierarchical Navigable Small World (HNSW)
El algoritmo Hierarchical Navigable Small World (opens new window) (HNSW) es un método sofisticado para almacenar y recuperar datos de manera eficiente. Su estructura similar a un grafo se inspira en dos técnicas diferentes: la lista de saltos de probabilidad y Navigable Small World (NSW).
Para comprender mejor HNSW, primero intentemos comprender los conceptos básicos relacionados con este algoritmo.
# Lista de saltos de probabilidad
Una lista de saltos de probabilidad es una estructura de datos avanzada que combina las ventajas de dos estructuras tradicionales: la capacidad de inserción rápida de una lista enlazada y la característica de recuperación rápida de una matriz. Esto se logra a través de su arquitectura de múltiples capas donde los datos se organizan en múltiples capas, cada una de las cuales contiene un subconjunto de los puntos de datos.
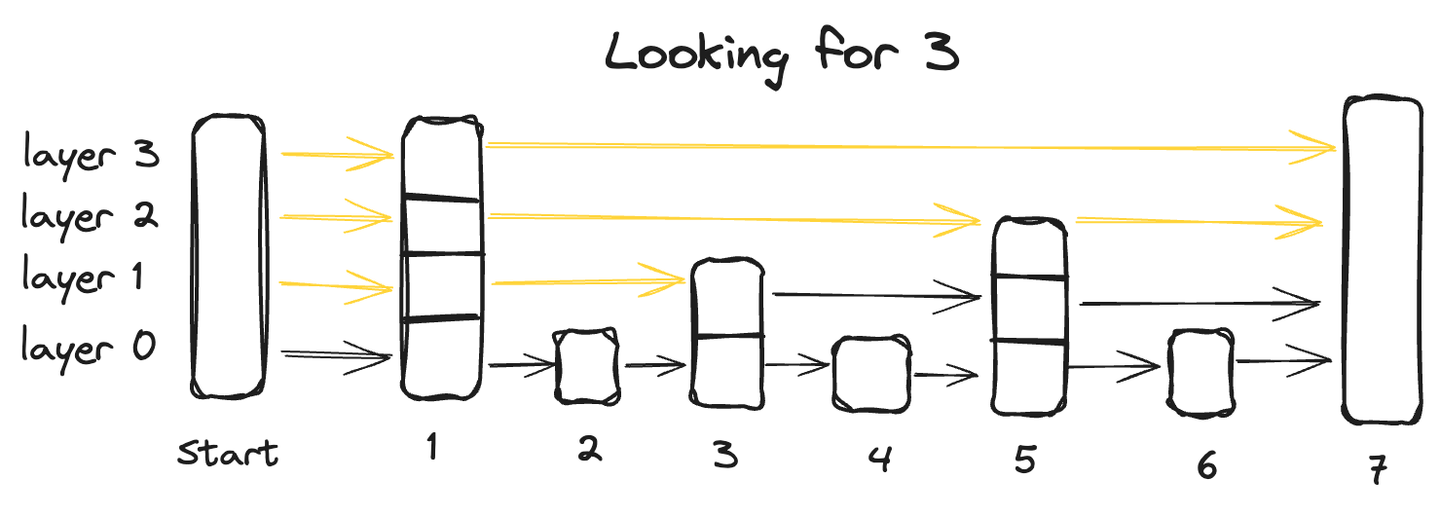
Comenzando desde la capa inferior, que contiene todos los puntos de datos, cada capa sucesiva salta algunos puntos y, por lo tanto, tiene menos puntos de datos, y finalmente la capa más alta tendrá el menor número de puntos de datos.
Para buscar un punto de datos en una lista de saltos de probabilidad, comenzamos desde la capa más alta y avanzamos de izquierda a derecha explorando cada punto de datos. En cualquier punto, si el valor consultado es mayor que el punto de datos actual, retrocedemos al punto de datos anterior en la capa inferior y reanudamos la búsqueda de izquierda a derecha hasta encontrar el punto exacto.
# Navigable Small World (NSW)
Navigable Small World (NSW) es similar a un grafo aproximado donde los nodos están vinculados entre sí en función de cuán similares son entre sí. Se utiliza el método codicioso para buscar el punto más cercano.
Siempre comenzamos con un punto de entrada predefinido, que se conecta a varios nodos cercanos. Identificamos cuáles de estos nodos son los más cercanos a nuestro vector de consulta y nos movemos allí. Este proceso se repite hasta que no haya ningún nodo más cercano al vector de consulta que el nodo actual, lo que sirve como condición de detención del algoritmo.
Ahora, volvamos al tema principal y veamos cómo funciona.
# Cómo se desarrolla HNSW
Entonces, lo que sucede en HNSW es que tomamos la motivación de la lista de saltos de probabilidad y creamos capas como la lista de saltos de probabilidad. Pero para la conexión entre los puntos de datos, se crea una conexión similar a un grafo entre los nodos. Los nodos en cada capa están conectados no solo a los nodos de la capa actual, sino también a los nodos de las capas inferiores. Los nodos en la parte superior son muy pocos y la intensidad aumenta a medida que bajamos a las capas inferiores. La última capa contiene todos los puntos de datos de la base de datos. Así es como se ve la arquitectura de HNSW.
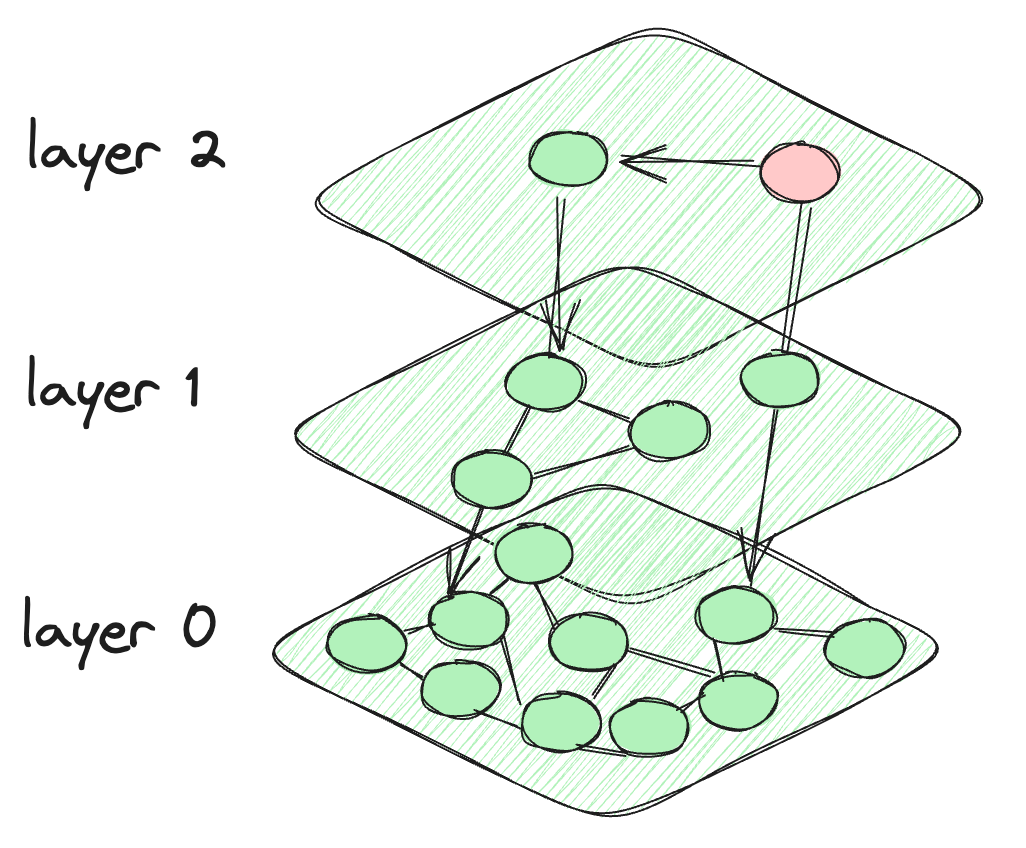
La arquitectura del algoritmo HNSW
# ¿Cómo funciona una consulta de búsqueda en HNSW?
El algoritmo comienza en el nodo predefinido de la capa más alta. Luego calcula la distancia entre los nodos conectados de la capa actual y los de la capa inferior. El algoritmo se desplaza a una capa inferior si la distancia a un nodo en esa capa es menor que la distancia a los nodos en la capa actual. Este proceso continúa hasta que se alcanza la última capa o se llega a un nodo que tiene la distancia mínima de todos los demás nodos conectados. La capa final, Capa 0, contiene todos los puntos de datos, lo que proporciona una representación completa y detallada del conjunto de datos. Esta capa es crucial para garantizar que la búsqueda incluya todos los vecinos más cercanos potenciales.
# Diferentes variantes de HNSW: HNSWFLAT y HNSWSQ
Al igual que IVFFLAT e IVFSQ, donde uno almacena vectores sin procesar y el otro almacena rangos cuantizados, el mismo proceso se aplica a HNSWFLAT y HNSWSQ. En HNSWFLAT, los vectores sin procesar se almacenan tal como están, mientras que en HNSWSQ, los vectores se almacenan en forma cuantizada. Aparte de esta diferencia clave en el almacenamiento de datos, el proceso y la metodología general de indexación y búsqueda son los mismos en HNSWFLAT y HNSWSQ.

# Algoritmo Multi-Scale Tree Graph (MSTG)
La Indexación Estándar de Archivos Invertidos (IVF) particiona un conjunto de datos vectoriales en numerosos clústeres, mientras que Hierarchical Navigable Small World (HNSW) construye un grafo jerárquico para los datos vectoriales. Sin embargo, una limitación notable de estos métodos es el crecimiento sustancial en el tamaño del índice para conjuntos de datos masivos, lo que requiere el almacenamiento de todos los datos vectoriales en la memoria. Aunque métodos como DiskANN pueden transferir el almacenamiento de vectores a SSD, construye el índice lentamente y tiene un rendimiento de búsqueda filtrada muy bajo.
Multi-Scale Tree Graph (MSTG) fue desarrollado por MyScale (opens new window) y supera estas limitaciones al combinar el agrupamiento jerárquico de árboles con la travesía de grafos, utilizando memoria con SSDs NVMe rápidos. MSTG reduce significativamente el consumo de recursos de IVF/HNSW mientras mantiene un rendimiento excepcional. Se construye rápidamente, busca rápidamente y sigue siendo rápido y preciso bajo diferentes proporciones de búsqueda filtrada, al mismo tiempo que es eficiente en recursos y costos.
# Conclusión
Las bases de datos de vectores han revolucionado la forma en que se almacenan los datos, proporcionando no solo una mayor velocidad, sino también una inmensa utilidad en diversos campos como la inteligencia artificial y el análisis de big data. En una era de crecimiento exponencial de datos, especialmente en formas no estructuradas, las aplicaciones de las bases de datos de vectores son ilimitadas. Las técnicas de indexación personalizadas amplifican aún más el poder y la efectividad de estas bases de datos, por ejemplo, mejorando la búsqueda de vectores filtrados. MyScale optimiza la búsqueda de vectores filtrados (opens new window) con el algoritmo MSTG único, proporcionando una solución potente para búsquedas de vectores complejas a gran escala. Prueba MyScale hoy mismo (opens new window) para experimentar la búsqueda avanzada de vectores.



