
Los modelos tradicionales de clasificación de imágenes, como las redes neuronales convolucionales (CNN) (opens new window), han sido la base de las tareas de visión por computadora durante años. Estos modelos funcionan entrenando con grandes conjuntos de datos etiquetados, donde cada imagen está asociada con una etiqueta de clase específica. Por lo general, estos modelos se basan en el aprendizaje de N ejemplos, lo que significa que requieren un gran número de imágenes etiquetadas (N ejemplos) para cada clase para lograr una alta precisión.
Sin embargo, estos modelos tradicionales presentan varios desafíos significativos. En primer lugar, requieren una cantidad sustancial de datos etiquetados, lo cual es costoso y consume mucho tiempo producir. Además, los modelos tradicionales tienen dificultades para generalizar de manera efectiva, especialmente cuando el número de ejemplos (N) es pequeño.
Además, estos modelos tienen limitaciones en su capacidad para clasificar datos no vistos. Si un modelo no ha sido entrenado en una clase específica, es poco probable que clasifique con precisión las imágenes de esa clase. Esta limitación se convierte en un cuello de botella importante, especialmente en escenarios donde surgen nuevas categorías con frecuencia o donde los datos etiquetados son escasos.
Estos desafíos dejan claro que necesitamos modelos más inteligentes que puedan hacer más con menos. Ahí es donde CLIP brilla realmente. A diferencia de los modelos tradicionales, CLIP no necesita ser entrenado específicamente en cada clase para reconocerla. Utiliza un gran conjunto de datos de pares de imágenes y texto y el aprendizaje contrastivo para determinar qué hay en una imagen, incluso si no ha visto ese tipo de imagen antes. Esto hace que CLIP sea increíblemente útil, especialmente en situaciones donde los modelos tradicionales no son suficientes.
# CLIP
OpenAI lanzó CLIP (opens new window) en 2021, un modelo que une las imágenes y el texto en un espacio vectorial compartido. Mediante el uso del aprendizaje contrastivo, CLIP aprende a identificar qué pares de imagen y texto pertenecen juntos y cuáles no. Esta capacidad le permite generalizar entre diferentes clases, incluso aquellas que no ha encontrado antes. Como resultado, CLIP es altamente efectivo en la clasificación sin etiquetas, donde puede identificar con precisión nuevas categorías basándose únicamente en descripciones de texto.
- Clasificación sin etiquetas (opens new window): Este enfoque permite que el modelo clasifique nuevas categorías sin necesidad de ejemplos etiquetados durante el entrenamiento. Se llama "sin etiquetas" porque no requiere datos de entrenamiento, sino que se basa únicamente en descripciones de texto para hacer predicciones.
- Clasificación N ejemplos (opens new window): En este caso, el modelo requiere N ejemplos etiquetados por categoría para aprender a clasificarlos correctamente. La "N" representa el número de ejemplos que el modelo necesita ver para comprender cada categoría.
# Cómo se utiliza CLIP para la clasificación sin etiquetas
La arquitectura de CLIP está diseñada para manejar la clasificación sin etiquetas de una manera sencilla pero poderosa. En el núcleo de CLIP se encuentran dos codificadores: uno para imágenes y otro para texto. Estos codificadores transforman las imágenes y las descripciones de texto de entrada en vectores de alta dimensión, o incrustaciones, dentro de un espacio vectorial compartido.
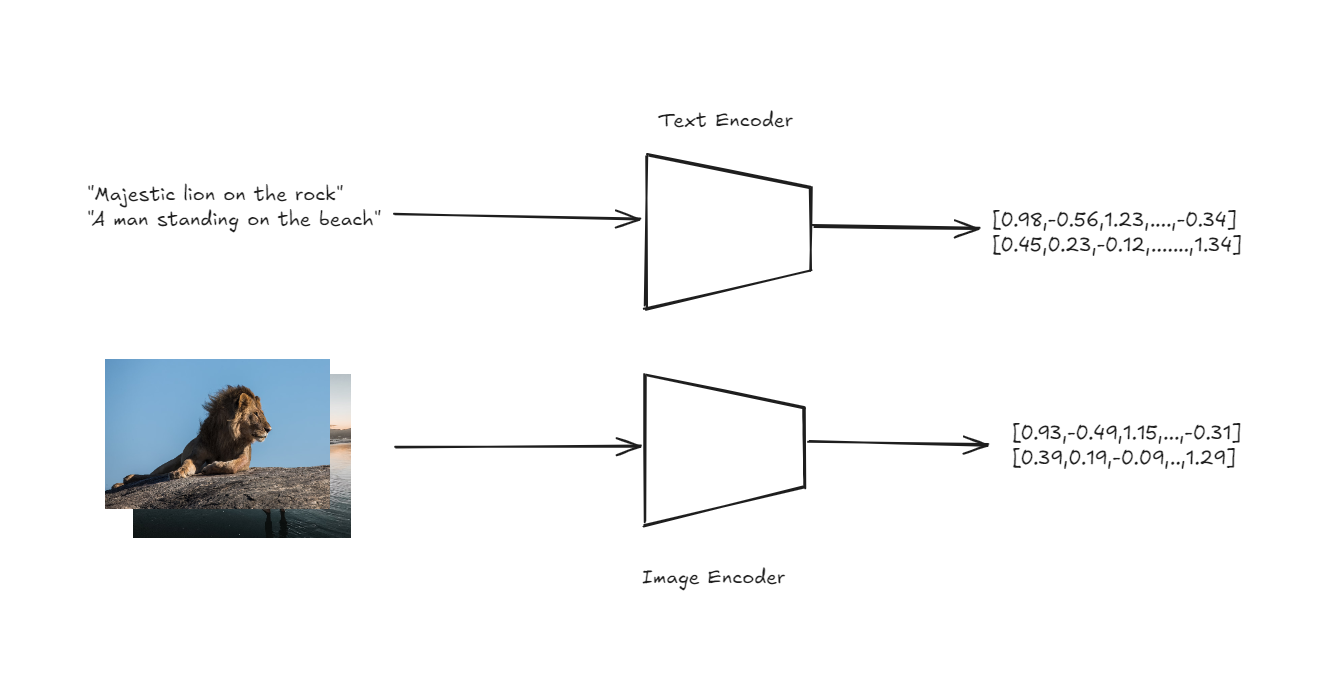
Codificadores de texto e imagen para obtener incrustaciones
La clave de la innovación aquí es que tanto las imágenes como el texto se representan en el mismo espacio, lo que permite una comparación directa entre las dos modalidades.
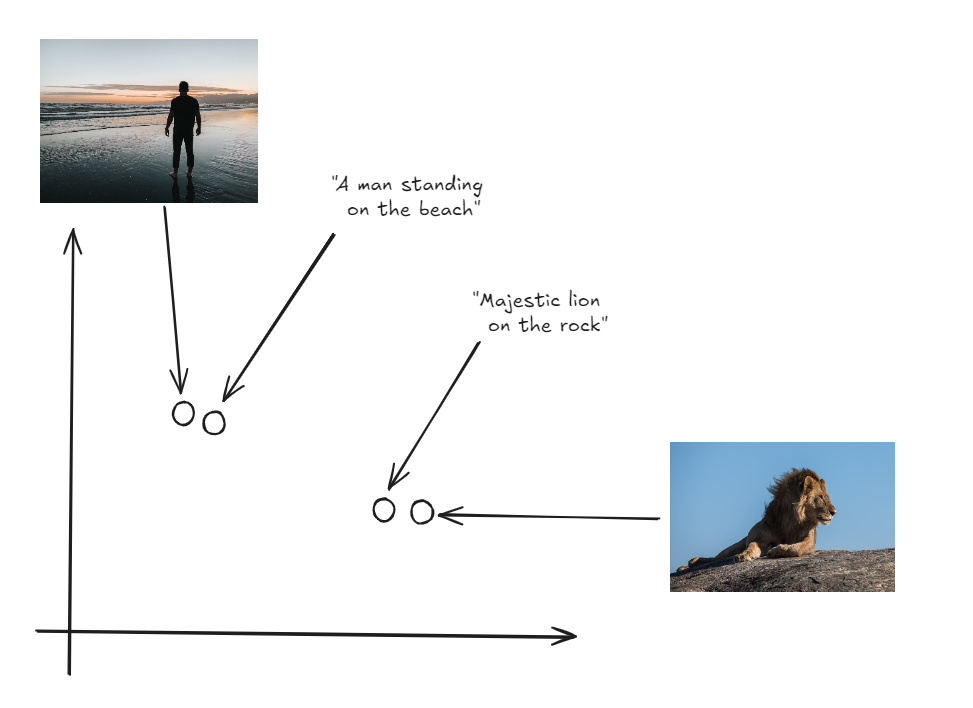
Tanto las imágenes como las etiquetas en el mismo espacio vectorial
Para realizar la clasificación sin etiquetas, CLIP primero genera incrustaciones para un conjunto de descripciones de texto que corresponden a diferentes clases (por ejemplo, "una foto de un gato", "una foto de un perro"). Luego genera una incrustación para la imagen de entrada. El modelo calcula la similitud del coseno entre la incrustación de la imagen y cada una de las incrustaciones de texto. La similitud del coseno mide el coseno del ángulo entre dos vectores, lo que indica qué tan cerca se alinean. La descripción de texto con la similitud del coseno más alta con la incrustación de la imagen se selecciona como la etiqueta predicha. Este proceso permite que CLIP clasifique imágenes en categorías que nunca ha visto explícitamente durante el entrenamiento, basándose únicamente en la información semántica capturada en las descripciones de texto.
Nota: El mismo enfoque se puede aplicar para construir una aplicación de búsqueda de imágenes utilizando CLIP (opens new window).
# Ejemplo práctico
Cuando probamos el modelo CLIP en el conjunto de datos Imagenette para la clasificación sin etiquetas, tuvo un rendimiento excepcional, logrando una precisión de más del 99%. Este resultado muestra que CLIP puede igualar o incluso superar el rendimiento de los modelos tradicionales de clasificación de imágenes.
Con resultados tan impresionantes, está claro que CLIP ofrece una alternativa poderosa para las tareas de clasificación de imágenes. Ahora, profundicemos en cómo podemos implementar este modelo en un escenario práctico.
Nota: Puedes encontrar el cuaderno completo en Github (opens new window).
# Instalación de las bibliotecas necesarias
Primero, necesitamos instalar las bibliotecas necesarias. Usa el siguiente comando para instalar los paquetes requeridos:
pip install datasets transformers
La biblioteca datasets de Hugging Face te brinda acceso a una gran variedad de conjuntos de datos listos para usar que son muy útiles para proyectos de aprendizaje automático. La biblioteca transformers, también de Hugging Face, es la herramienta principal para utilizar modelos preentrenados potentes. En nuestro caso, la utilizaremos para cargar y trabajar con el modelo CLIP.
# Importación de dependencias
Después de instalar las bibliotecas, podemos importar las dependencias necesarias. Estas incluyen módulos esenciales para manejar datos, trabajar con el modelo CLIP y visualizar los resultados.
import torch
import numpy as np
from datasets import load_dataset
from tqdm.auto import tqdm
from transformers import AutoProcessor, CLIPModel, AutoTokenizer
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
import seaborn as sns
Utilizaremos matplotlib y seaborn para crear y mostrar visualizaciones, lo que nos ayudará a interpretar y presentar mejor nuestros datos a lo largo de este proyecto.
# Carga del modelo CLIP
Para realizar la clasificación sin etiquetas, cargamos el modelo CLIP. El modelo se cargará en la GPU si está disponible; de lo contrario, se utilizará la CPU. También cargamos el procesador y el tokenizador asociados.
device = "cuda" if torch.cuda.is_available() else "cpu"
model = CLIPModel.from_pretrained("openai/clip-vit-large-patch14").to(device)
processor = AutoProcessor.from_pretrained("openai/clip-vit-large-patch14")
tokenizer = AutoTokenizer.from_pretrained("openai/clip-vit-large-patch14")
El AutoProcessor se encarga de procesar tanto los datos de imagen como de texto para que sean compatibles con el modelo CLIP. El AutoTokenizer convierte el texto en un formato que el modelo puede entender, generando los tokens necesarios para su posterior procesamiento.
Nota: Para este blog, estamos utilizando la GPU gratuita disponible en Google Colab, lo que acelera significativamente el tiempo de procesamiento.
# Carga del conjunto de datos Imagenette
Procedemos cargando el conjunto de datos Imagenette, que es un subconjunto más pequeño del conjunto de datos ImageNet más grande. Este subconjunto contiene 10 clases, lo que lo hace más manejable para experimentación rápida:
imagenette = load_dataset(
'frgfm/imagenette',
'320px',
split='validation',
revision="4d512db"
)
La función load_dataset de la biblioteca datasets de Hugging Face se utiliza para descargar y preparar el conjunto de datos Imagenette. Esta versión del conjunto de datos consta de imágenes redimensionadas a 320 píxeles y se divide en un conjunto de validación para evaluar el rendimiento del modelo.
# Análisis del conjunto de datos
Comenzamos imprimiendo las etiquetas de clase presentes en el conjunto de datos para comprender con qué categorías estamos trabajando:
labels = imagenette.features["label"].names
print(f"Etiquetas de clase en el conjunto de datos: {labels}")
El código anterior imprimirá el siguiente resultado:
Etiquetas de clase en el conjunto de datos: ['tench', 'English springer', 'cassette player', 'chain saw', 'church', 'French horn', 'garbage truck', 'gas pump', 'golf ball', 'parachute']
# Visualización de la distribución de clases
Para comprender mejor la distribución de imágenes en diferentes clases, creamos un gráfico de barras.
plt.figure(figsize=(10, 6))
sns.barplot(x=labels, y=class_counts, palette='viridis')
plt.xticks(rotation=45, ha='right')
plt.title('Distribución de clases en el conjunto de datos Imagenette')
plt.xlabel('Etiquetas de clase')
plt.ylabel('Número de imágenes')
plt.show()
El código anterior generará un gráfico de barras como este: El gráfico muestra que la distribución de clases en el conjunto de datos Imagenette no es uniforme. Sin embargo, este desequilibrio no es un problema para nosotros, ya que no estamos utilizando el conjunto de datos para el entrenamiento, sino para la clasificación sin etiquetas.
# Selección y procesamiento de imágenes
Luego iteramos a través del conjunto de datos para seleccionar imágenes y sus etiquetas correspondientes. Este paso prepara los datos para la generación de incrustaciones posterior.
selected_images = []
selected_labels = []
for example in tqdm(imagenette):
label = example["label"]
selected_images.append(example["image"])
selected_labels.append(label)
# Preparación de las entradas de texto
Para la clasificación sin etiquetas, convertimos las etiquetas de clase en entradas de texto utilizando el tokenizador. Estas entradas se alimentan al modelo para generar incrustaciones de texto.
text_inputs = tokenizer([f"una foto de un {c}" for c in labels], return_tensors="pt", padding=True).to(device)
La razón por la que formateamos las cadenas como "una foto de un {etiqueta}" es que el modelo CLIP fue entrenado con pares de texto-imagen similares. Esta formulación ayuda al modelo a relacionar mejor el texto con las imágenes correspondientes.
# Generación de incrustaciones de texto
Utilizando el modelo CLIP, generamos incrustaciones de texto para cada etiqueta de clase. Estas incrustaciones se compararán más tarde con las incrustaciones de imagen para clasificar las imágenes.
with torch.no_grad():
label_emb = model.get_text_features(input_ids=text_inputs['input_ids'], attention_mask=text_inputs['attention_mask'])
label_emb = label_emb.cpu().numpy()
# Procesamiento por lotes y generación de incrustaciones de imagen
Procesamos las imágenes seleccionadas en lotes para generar incrustaciones de imagen. Luego, estas incrustaciones se comparan con las incrustaciones de texto para calcular las puntuaciones de similitud.
preds = []
batch_size = 50
for i in tqdm(range(0, len(selected_images), batch_size)):
i_end = min(i + batch_size, len(selected_images))
images = processor(
images=selected_images[i:i_end],
return_tensors='pt'
)['pixel_values'].to(device)
with torch.no_grad():
img_emb = model.get_image_features(images)
img_emb = img_emb.cpu().numpy()
# Calcular las puntuaciones de similitud entre las incrustaciones de imagen y las incrustaciones de texto
scores = np.dot(img_emb, label_emb.T)
preds.extend(np.argmax(scores, axis=1))
Ahora tenemos un conjunto de etiquetas predichas para nuestras imágenes seleccionadas. A continuación, exploraremos qué tan bien se desempeñó el modelo y las ideas que ofrecen estas predicciones.
# Cálculo y visualización de la precisión
Finalmente, calculamos la precisión de la clasificación sin etiquetas comparando las etiquetas predichas con las etiquetas reales.
accuracy = accuracy_score(selected_labels, preds)
print(f"Precisión de la clasificación sin etiquetas en Imagenette: {accuracy * 100:.2f}%")
El fragmento anterior nos dará la siguiente salida:

Como podemos ver, el modelo CLIP tuvo un rendimiento muy bueno en el conjunto de datos Imagenette, logrando una alta precisión. Este sólido rendimiento se debe a la alta calidad de las imágenes y al número relativamente pequeño de clases en el conjunto de datos, lo que facilita que el modelo relacione las imágenes con sus descripciones de texto correspondientes. CLIP fue entrenado con un vasto conjunto de datos de 400 millones de pares de imágenes y texto, generalmente utilizando imágenes redimensionadas a alrededor de 224x224 píxeles, lo que le ayudó a aprender a generalizar en una amplia gama de datos visuales y textuales.
Sin embargo, cuando se utilizan imágenes de baja resolución o conjuntos de datos con más clases, el rendimiento del modelo varía. Por ejemplo, cuando probamos el modelo en el conjunto de datos CIFAR-10, con imágenes de 32x32 píxeles, la precisión disminuyó al 94.76%. De manera similar, las pruebas en el conjunto de datos SaulLu/Caltech-101, con 102 clases, mostraron una precisión más baja del 81.21% debido al mayor número de clases y la variedad de calidad de las imágenes.
Nota: Aquí puedes encontrar los cuadernos completos con los resultados para SaulLu/Caltech-101 (opens new window) y CIFAR-10 (opens new window).

A pesar de estos desafíos, CLIP sigue siendo una excelente opción, especialmente cuando se tiene datos de entrenamiento limitados o inexistentes. Su capacidad para realizar clasificación sin etiquetas y manejar diversas tareas sin un extenso reentrenamiento lo convierte en una herramienta valiosa en situaciones donde los modelos tradicionales pueden no ser suficientes.



