
Los datos son el corazón de casi todas las organizaciones hoy en día. A medida que los volúmenes de datos continúan aumentando, las empresas deben encontrar formas de almacenar, procesar y analizar sus datos de manera efectiva. Esto ha llevado a una explosión en el mercado de bases de datos, con empresas que utilizan tanto bases de datos SQL tradicionales como bases de datos vectoriales más nuevas para realizar diferentes tareas.
Sin embargo, cada tipo de base de datos tiene sus ventajas y desventajas. Las bases de datos SQL tradicionales ofrecen consistencia, precisión y facilidad de uso para datos estructurados, mientras que las bases de datos vectoriales están optimizadas para velocidad y escalabilidad, especialmente con grandes volúmenes de datos no estructurados. Pero, ¿qué pasaría si no tuvieras que elegir? ¿Qué pasaría si hubiera una base de datos que te ofreciera lo mejor de ambos mundos?
En este blog, vamos a echar un vistazo a MyScale, desde lo más básico, como crear tablas y definir índices, hasta la búsqueda avanzada de vectores SQL. Al final, también compararemos MyScale con otras bases de datos en el mercado y veremos por qué MyScale es mejor. Así que, empecemos.
# ¿Qué es MyScale?
MyScale (opens new window) es una base de datos vectorial SQL basada en la nube, especialmente diseñada y optimizada para gestionar grandes volúmenes de datos para aplicaciones de inteligencia artificial. Está construida sobre ClickHouse (opens new window) (una base de datos SQL), combinando la capacidad de búsqueda de similitud de vectores con el soporte completo de SQL. En una sola interfaz, una consulta SQL puede aprovechar simultáneamente y de manera rápida diferentes modalidades de datos para manejar demandas complejas de IA que de otra manera requerirían más pasos y tiempo.
A diferencia de las bases de datos vectoriales especializadas, MyScale combina armoniosamente algoritmos de búsqueda de vectores con bases de datos estructuradas, lo que permite la gestión tanto de vectores como de datos estructurados dentro de la misma base de datos. Esta integración ofrece beneficios como una comunicación simplificada, filtrado de metadatos adaptable, soporte para consultas conjuntas de SQL y vectores, y compatibilidad con herramientas maduras comúnmente asociadas con bases de datos versátiles de propósito general. En esencia, MyScale ofrece una solución unificada, proporcionando un enfoque holístico, eficiente y fácil de aprender para abordar las complejidades de la gestión de datos de IA.
# Cómo lanzar un clúster en MyScale
Antes de comenzar a usar MyScale en tu proyecto, lo primero que debes hacer es crear una cuenta y crear un clúster que almacenará tus datos. Aquí te mostramos los pasos:
- Inicia sesión/Regístrate en una cuenta de MyScale en myscale.com (opens new window)
- Una vez creada la cuenta, haz clic en el botón "+ Nuevo Clúster" en el lado derecho de la página
- Ingresa el nombre del clúster y presiona el botón "Siguiente"
- Espera a que se cree el clúster, esto tomará unos segundos
Una vez creado el clúster, verás el texto "Clúster lanzado exitosamente" en el botón emergente.
Nota:
Después de crear el clúster, también tienes la opción de importar datos de muestra predefinidos en tu clúster, si no tienes tus propios datos. Sin embargo, en este tutorial, cargaremos nuestros propios datos.
Ahora, el siguiente paso es configurar el entorno de trabajo y acceder al clúster en ejecución. Hagamos eso.
# Configurando el entorno
Para usar MyScale en tu entorno, necesitas tener:
- Python: MyScale proporciona una biblioteca de cliente de Python para interactuar con la base de datos, por lo que necesitarás tener Python instalado en tu sistema. Si no tienes Python instalado en tu PC, puedes descargarlo desde el sitio web oficial de Python (opens new window).
- Cliente de Python de MyScale: Instala el paquete del cliente de ClickHouse (opens new window) usando
pip:
pip install clickhouse-connect
Una vez que se complete la ejecución, puedes confirmar la instalación ingresando el siguiente comando:
pip show clickhouse-connect
Si la biblioteca está instalada, verás información sobre el paquete; de lo contrario, verás un error.
# Conexión con el clúster
El siguiente paso es conectar la aplicación de Python con el clúster y para la conexión, necesitamos los siguientes detalles:
- Host del clúster
- Nombre de usuario
- Contraseña
Para obtener los detalles, puedes volver a tu perfil de MyScale y pasar el cursor sobre los tres puntos alineados verticalmente debajo del texto "Acciones" y hacer clic en "Detalles de conexión".
Una vez que hagas clic en "Detalles de conexión", verás el siguiente cuadro:
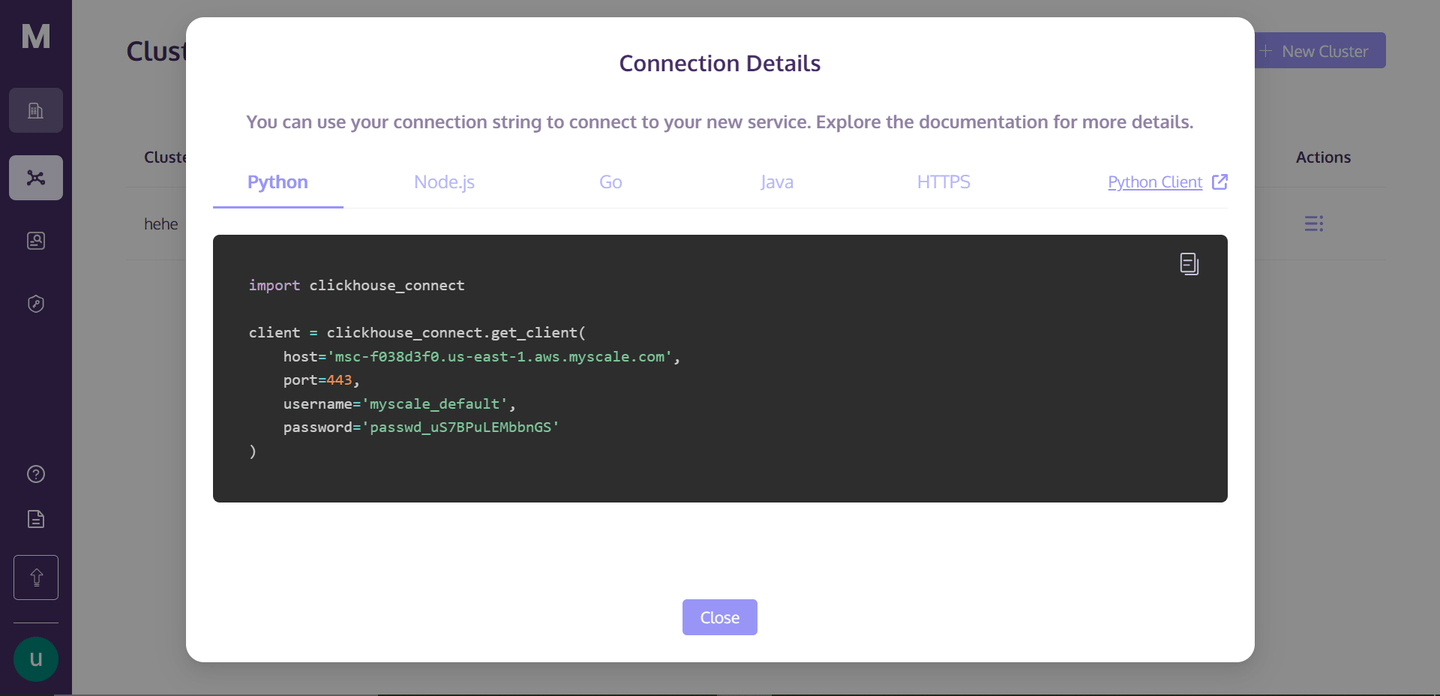
Estos son los detalles de conexión que necesitas para conectarte al clúster. Simplemente crea un archivo de cuaderno de Python en tu directorio, copia y pega el siguiente código en la celda de tu cuaderno y ejecuta la celda. Se establecerá una conexión con tu clúster.
# Crear una base de datos
El siguiente paso es crear una base de datos en el clúster. Veamos cómo puedes hacer esto:
client.command("""
CREATE DATABASE IF NOT EXISTS getStart;
""")
Este comando primero verifica si ya existe una base de datos con el mismo nombre, si no existe, creará una base de datos con el nombre getStart.
# Crea una tabla usando MyScale
La sintaxis básica para crear una tabla en MyScale es la siguiente:
CREATE TABLE [IF NOT EXISTS] db_name.table_name
(
column_name1 data_type [options],
column_name2 data_type [options],
...
)
ENGINE = engine_type
[ORDER BY expression]
[PRIMARY KEY expression];
En la sintaxis anterior, puedes reemplazar db_name y table_name según tu elección. Dentro de los paréntesis, defines las columnas de tu tabla. Cada columna (column_name1, column_name2, etc.) se define con su respectivo tipo de datos (data_type), y opcionalmente puedes incluir opciones adicionales para las columnas ([options]), como valores predeterminados o restricciones.
Nota:
Solo estamos viendo cómo se crean las tablas en MyScale. Crearemos una tabla real en el siguiente paso según nuestros datos.
La cláusula ENGINE = engine_type es crucial para determinar el almacenamiento y procesamiento de datos. Puedes especificar la expresión ORDER BY, que determina cómo se almacenan físicamente los datos en la tabla. La expresión PRIMARY KEY se utiliza para mejorar la eficiencia de la recuperación de datos. A diferencia de las bases de datos SQL tradicionales, la clave primaria en ClickHouse no garantiza la unicidad, sino que se utiliza como una herramienta de optimización de rendimiento para acelerar el procesamiento de consultas.
# Importar datos para una tabla y crear un índice
Obtengamos una experiencia práctica importando un conjunto de datos y luego aprenderás a crear una columna en función del conjunto de datos.
import pandas as pd
# URL of the data
url = 'https://d3lhz231q7ogjd.cloudfront.net/sample-datasets/quick-start/categorical-search.csv'
# Reading the data directly into a pandas DataFrame
data = pd.read_csv(url)
Esto debería descargar el conjunto de datos desde la URL proporcionada y guardarlo como un dataframe. Los datos deberían verse así:
| id | data | date | label |
|-------|---------------------------------------------------|------------|----------|
| 0 | [0,0,1,8,7,3,2,5,0,0,3,5,7,11,31,13,0,0,0,... | 2030-09-26 | person |
| 1 | [65,35,8,0,0,0,1,63,48,27,31,19,16,34,96,114,3... | 1996-06-22 | building |
| 2 | [0,0,0,0,0,0,0,4,1,15,0,0,0,0,49,27,0,0,0,... | 1975-10-07 | animal |
| 3 | [3,9,45,22,28,11,4,3,77,10,4,1,1,4,3,11,23,0,... | 2024-08-11 | animal |
| 4 | [6,4,3,7,80,122,62,19,2,0,0,0,32,60,10,19,4,0,... | 1970-01-31 | animal |
| ... | ... | ... | ... |
| 99995 | [9,69,14,0,0,0,1,24,109,33,2,0,1,6,13,12,41,... | 1990-06-24 | animal |
| 99996 | [29,31,1,1,0,0,2,8,8,3,2,19,19,41,20,8,5,0,0,6... | 1987-04-11 | person |
| 99997 | [0,1,116,99,2,0,0,0,0,2,97,117,6,0,5,2,101,86,... | 2012-12-15 | person |
| 99998 | [0,20,120,67,76,12,0,0,8,63,120,55,12,0,0,0,... | 1999-03-05 | building |
| 99999 | [48,124,18,0,0,1,6,13,14,70,78,3,0,0,9,15,49,4... | 1972-04-20 | building |
El siguiente paso es crear una tabla real en el clúster de MyScale y almacenar estos datos. Hagámoslo.
client.command("""
CREATE TABLE getStart.First_Table (
id UInt32,
data Array(Float32),
date Date,
label String,
CONSTRAINT check_data_length CHECK length(data) = 128
) ENGINE = MergeTree()
ORDER BY id
""")
El comando anterior creará una tabla llamada First_Table. También se proporcionan los nombres de columna con los tipos de datos aquí. La razón para elegir la restricción es que queremos que los vectores de la columna de datos sean exactamente iguales, porque en la parte posterior aplicaremos una búsqueda de vectores en esta columna.
# Insertar datos en la tabla definida
Después del proceso de creación de la tabla, el siguiente paso es insertar los datos en la tabla. Entonces, insertaremos los datos que hemos descargado anteriormente.
# Convert the data vectors to float, so that it can meet the defined datatype of the column
data['data'] = data['data'].apply(lambda x: [float(i) for i in ast.literal_eval(x)])
# Convert the 'date' column to the 'YYYY-MM-DD' string format
data['date'] = pd.to_datetime(data['date']).dt.date
# Define batch size and insert data in batches
batch_size = 1000 # Adjust based on your needs
num_batches = len(data) // batch_size
for i in range(num_batches):
start_idx = i * batch_size
end_idx = start_idx + batch_size
batch_data = data[start_idx:end_idx]
client.insert("getStart.First_Table", batch_data.to_records(index=False).tolist(), column_names=batch_data.columns.tolist())
print(f"Batch {i+1}/{num_batches} inserted.")
El código anterior cambia los tipos de datos de algunas columnas según la tabla definida. Estamos insertando datos en forma de lotes debido al gran volumen de datos. Por lo tanto, estamos creando lotes de 1000.
# Crear un índice de vectores
Entonces, el siguiente paso es crear un índice de vectores. Veamos cómo se hace.
client.command("""
ALTER TABLE getStart.First_Table
ADD VECTOR INDEX vector_index data
TYPE MSTG
""")
Nota:
El tiempo para crear el índice vectorial depende de los datos en su tabla.
El índice vectorial MSTG ha sido creado por MyScale internamente y ha superado ampliamente a sus competidores en términos de velocidad, precisión y eficiencia de costos.
Para verificar si el índice vectorial ha sido creado con éxito, probaremos este comando:
get_index_status="SELECT status FROM system.vector_indices WHERE table='First_Table'"
print(f"El estado del índice es {client.command(get_index_status)}")
La salida del código debe ser "El estado del índice es Construido". La palabra "Construido" significa que el índice está activo y se ha creado con éxito.
Nota:
En este momento, MyScale solo permite crear un índice por tabla. Pero en el futuro, podrás crear múltiples índices en una tabla.
# Escribe diferentes tipos de consultas SQL utilizando MyScale
MyScale te permite escribir diferentes tipos de consultas, desde las más básicas hasta las más complicadas. Comencemos con una consulta muy básica.
result=client.query("SELECT * FROM getStart.First_Table ORDER BY date DESC LIMIT 1")
for row in result.named_results():
print(row["id"], row["date"], row["label"],row["data"])
También puedes encontrar los vecinos más cercanos de una entidad utilizando puntuaciones de similitud de vectores. Tomemos el resultado extraído y obtengamos sus vecinos más cercanos:
results = client.query(f"""
SELECT id, date, label,
distance(data, {result.first_item["data"]}) as dist FROM getStart.First_Table ORDER BY dist LIMIT 10
""")
for row in results.named_results():
print(row["id"], row["date"], row["label"])
Nota:
El método first_item nos da el primer elemento del arreglo de resultados.
Esto imprimirá los 10 vecinos más cercanos de la entrada dada.
# Escribe consultas en lenguaje natural utilizando MyScale
También puedes consultar MyScale utilizando consultas en lenguaje natural, pero para eso, crearemos otra tabla con nuevos datos con características de redes neuronales.
Antes de crear la tabla, carguemos los datos. El archivo original se puede descargar aquí (opens new window).
with open('/`../../modules/state_of_the_union.txt`', 'r', encoding='utf-8') as f:
texts = [line.strip() for line in f if line.strip()]
Este comando cargará el archivo de texto y lo dividirá en documentos separados. Para transformar estos documentos de texto en vectores de incrustación, utilizaremos la API de OpenAI. Para instalar esto, abre tu terminal e ingresa el siguiente comando:
pip install openai
Una vez que se complete la instalación, puedes configurar tu modelo de incrustaciones y obtener las incrustaciones:
import os
# Import OPENAI
import openai
# Import pandas
import pandas as pd
# Set the environment variable for OPENAI API Key
os.environ["OPENAI_API_KEY"] = "your_api_key_here"
# Get the embedding vectors of the documents
response = openai.embeddings.create(
input = texts,
model = 'text-embedding-ada-002')
# The code below creates a dataframe. We will insert this dataframe directly to the table
embeddings_data = []
for i in range(len(response.data)):
embeddings_data.append({'id': i, 'data': response.data[i].embedding, 'content': texts[i]})
# Convert to Pandas DataFrame
df_embeddings = pd.DataFrame(embeddings_data)
El código anterior convertirá los documentos de texto en incrustaciones y luego creará un dataframe que se insertará en una tabla. Ahora, procedamos a crear la tabla.
client.command("""
CREATE TABLE getStart.natural_language (
id UInt32,
content String,
data Array(Float32),
CONSTRAINT check_data_length CHECK length(data) = 1536
) ENGINE = MergeTree()
ORDER BY id;
""")
El siguiente paso es insertar los datos en la tabla.
# Set the batch size to 20
batch_size = 20
# Find the number of batches
num_batches = len(df_embeddings) // batch_size
# Insert the data in the form of batches
for i in range(num_batches + 1):
# Define the starting point for each batch
start_idx = i * batch_size
# Define the last index for each batch
end_idx = min(start_idx + batch_size, len(df_embeddings))
# Get the batch from the main DataFrame
batch_data = df_embeddings[start_idx:end_idx]
# Insert the data
if not batch_data.empty:
client.insert("getStart.natural_language",
batch_data.to_records(index=False).tolist(),
column_names=batch_data.columns.tolist())
print(f"Batch {i+1}/{num_batches + 1} inserted.")
El proceso de inserción de datos puede llevar algún tiempo, dependiendo del tamaño de los datos, pero puedes monitorear el progreso de esta manera. Ahora, pasemos a crear el índice para nuestra tabla.
client.command("""
ALTER TABLE getStart.natural_language
ADD VECTOR INDEX vector_index_new data
TYPE MSTG
""")
Una vez que se haya creado el índice, estás listo para comenzar a hacer consultas.
# Convert the query to vector embeddigs
response = openai.embeddings.create(
# Write your query in the input parameter
input = 'What did the president say about Ketanji Brown Jackson?',
model = 'text-embedding-ada-002'
)
# Get the results
results = client.query(f"""
SELECT id,content,
distance(data, {list(response.data[0].embedding)}) as dist FROM getStart.natural_language ORDER BY dist LIMIT 5
""")
for row in results.named_results():
print(row["id"] ,row["content"], row["dist"])
Debería imprimir los siguientes resultados:
| ID | Text | Score |
| --- | ---------------------------------------------------------------------------------------------------------------- | ------------------- |
| 269 | And I did that 4 days ago, when I nominated Circuit Court of Appeals Judge Ketanji Brown Jackson... | 0.33893799781799316 |
| 331 | The Cancer Moonshot that President Obama asked me to lead six years ago. | 0.4131550192832947 |
| 80 | Vice President Harris and I ran for office with a new economic vision for America. | 0.4235861897468567 |
| 328 | This is personal to me and Jill, to Kamala, and to so many of you. | 0.42732131481170654 |
| 0 | Madam Speaker, Madam Vice President, our First Lady and Second Gentleman. Members of Congress and the Cabinet... | 0.427462637424469 |
Estos son solo algunos ejemplos de consultas, puedes escribir tantas consultas complejas como desees según tus propias necesidades y proyecto.

# MyScale lidera el camino en las bases de datos vectoriales SQL
MyScale se destaca en el mercado de bases de datos vectoriales SQL con una precisión, rendimiento y eficiencia de costos inigualables. Sobresale sobre otras bases de datos vectoriales integradas como pgvector y bases de datos vectoriales especializadas como Pinecone, logrando una precisión de búsqueda mucho mejor y un procesamiento de consultas más rápido a un costo menor. Más allá del rendimiento, la interfaz SQL es muy amigable para los desarrolladores, ofreciendo un valor máximo con un aprendizaje mínimo necesario.
MyScale realmente eleva el juego. No se trata solo de una mejor búsqueda a través de vectores; ofrece alta precisión y consultas por segundo (QPS) en escenarios que involucran filtros de metadatos complejos. Además, aquí está lo más importante: si te registras, puedes usar el pod S1 de forma gratuita, que puede manejar hasta 5 millones de vectores. Es la opción ideal para cualquier persona que necesite una solución de base de datos vectorial potente pero rentable.
# MyScale potencia las aplicaciones con integraciones de IA
MyScale mejora sus capacidades y te permite crear aplicaciones más robustas a través de la integración con tecnologías de IA. Veamos algunas de esas integraciones donde puedes mejorar tu aplicación MyScale.
Integración con LangChain: En el mundo actual, donde los casos de uso de las aplicaciones de IA aumentan día a día, no puedes crear una aplicación de IA robusta simplemente combinando LLMs con bases de datos. Tendrás que usar diferentes marcos y herramientas para desarrollar mejores aplicaciones. En este sentido, MyScale proporciona una integración completa con LangChain (opens new window), lo que te permite crear aplicaciones de IA más efectivas y confiables con una estrategia de recuperación avanzada. Especialmente, el recuperador de autoconsulta para MyScale (opens new window) implementa un método flexible y potente para convertir texto en consultas de vectores filtradas por metadatos, logrando una alta precisión en muchos escenarios del mundo real.
Integración con OpenAI: Al integrar MyScale con OpenAI, puedes mejorar significativamente la precisión y robustez de tu aplicación de IA. OpenAI te permite obtener los mejores vectores de incrustación, manteniendo el contexto y la semántica. Esto es muy importante cuando aplicas la búsqueda de vectores utilizando consultas de lenguaje natural o extraes incrustaciones de tus datos. Así es como puedes mejorar la precisión y exactitud de tus aplicaciones. Para obtener una comprensión más detallada, puedes leer nuestra documentación sobre Integración con OpenAI (opens new window).
Recientemente, OpenAI lanzó GPTs, lo que permite a los desarrolladores personalizar fácilmente GPTs y chatbots. MyScale se adapta a este cambio, transformando el desarrollo del sistema RAG al inyectar sin problemas contextos del lado del servidor en los modelos GPT. MyScale agiliza la inyección de contexto con filtrado de datos estructurados y búsqueda semántica a través de cláusulas WHERE de SQL, optimizando el costo de almacenamiento de la base de conocimientos de manera rentable y permitiendo compartir en GPTs. Bienvenido a probar MyScaleGPT (opens new window) en GPT Store o conectar tu base de conocimientos a GPTs con MyScale (opens new window).
# Conclusión
A medida que las aplicaciones de IA y aprendizaje automático están creciendo, hay una creciente necesidad de bases de datos como MyScale, diseñadas especialmente para aplicaciones de IA modernas. MyScale es una base de datos vectorial SQL de vanguardia que combina la velocidad y las funcionalidades de las bases de datos tradicionales con capacidades de búsqueda vectorial de última generación. Esta combinación es perfecta para impulsar aplicaciones de IA.
Lo más importante es que, debido a la compatibilidad total de MyScale con la sintaxis SQL, cualquier desarrollador familiarizado con SQL puede comenzar rápidamente con MyScale. Además, los costos en MyScale son significativamente más bajos que otros tipos de bases de datos vectoriales. (opens new window) Esto hace de MyScale una opción convincente para empresas que manejan volúmenes sustanciales de datos, ya que ofrece una ventaja distintiva en la construcción de aplicaciones GenAI de calidad de producción con la familiaridad y el poder de SQL. Si deseas mantenerte actualizado sobre MyScale, bienvenido a unirte a nosotros hoy en Discord (opens new window) o Twitter (opens new window).



