
El desarrollo de aplicaciones de IA escalables y optimizadas utilizando Modelos de Lenguaje de Gran Escala (LLMs) aún está en sus etapas de crecimiento. Construir aplicaciones basadas en LLMs es complejo y consume mucho tiempo debido al extenso trabajo manual involucrado, como la redacción de prompts. La redacción de prompts es la parte más importante de cualquier aplicación LLM, ya que nos ayuda a extraer los mejores resultados posibles del modelo. Sin embargo, elaborar un prompt optimizado requiere que los desarrolladores dependan en gran medida de métodos de prueba y error, desperdiciando tiempo significativo hasta lograr el resultado deseado.
El método convencional de elaborar prompts manualmente es lento y propenso a errores. Los desarrolladores a menudo pasan mucho tiempo ajustando prompts para lograr la salida deseada, enfrentando problemas como:
- Fragilidad: Los prompts pueden fallar o funcionar de manera inconsistente con pequeños cambios.
- Ajustes Manuales: Se requiere un esfuerzo manual extenso para refinar los prompts.
- Manejo Inconsistente: Diferentes prompts para tareas similares conducen a resultados inconsistentes.
# ¿Qué es DSPy?
DSPy (Programas de Lenguaje Auto-mejorables Declarativos), pronunciado como “dee-s-pie”, es un marco diseñado por Omer Khattab y su equipo en Stanford NL. Su objetivo es resolver los problemas de consistencia y fiabilidad de la redacción de prompts priorizando la programación sobre la redacción manual de prompts. Proporciona un enfoque más declarativo, sistemático y programático para construir flujos de trabajo de datos que permiten a los desarrolladores crear flujos de trabajo de alto nivel sin centrarse en detalles de bajo nivel.
Logo de DSPy
Te permite definir qué lograr en lugar de cómo lograrlo. Así que, para lograr eso, DSPy ha realizado avances:
- Abstracción sobre los Prompts: DSPy ha introducido el concepto de firmas. Las firmas tienen como objetivo reemplazar la redacción manual de prompts con una estructura similar a una plantilla. En esta estructura, solo necesitamos definir las entradas y salidas para cualquier tarea dada. Esto hará que nuestros flujos de trabajo sean más resilientes y flexibles a cambios en el modelo o los datos.
- Bloques de Construcción Modulares: DSPy proporciona módulos que encapsulan técnicas comunes de prompting (como Chain of Thought o ReAct). Esto elimina la necesidad de construir manualmente prompts complejos para estas técnicas.
- Optimización Automatizada: DSPy admite optimizadores incorporados, también conocidos como "teleprompters", que seleccionan automáticamente los mejores prompts para su tarea y modelo específicos. Esta funcionalidad elimina la necesidad de ajuste manual de prompts, haciendo el proceso más simple y eficiente.
- Adaptación Impulsada por Compiladores: El compilador DSPy optimiza todo el flujo de trabajo, ajustando prompts o ajustando modelos según sus datos y lógica de validación, asegurando que el flujo de trabajo siga siendo efectivo incluso cuando los componentes cambien.
# Bloques de Construcción de un Programa DSPy
Exploremos los componentes esenciales que forman la base de un programa DSPy y comprendamos cómo interactúan para crear flujos de trabajo de PNL potentes y eficientes.
# Firmas
Las firmas sirven como el plano para definir lo que quieres que haga tu LLM. En lugar de escribir el prompt exacto, describes la tarea en términos de sus entradas y salidas.
Por ejemplo, una firma para resumir texto podría verse así: texto -> resumen. Esto le dice a DSPy que quieres ingresar algo de texto y recibir un resumen conciso como salida. Tareas más complejas podrían involucrar múltiples entradas, como una firma para responder preguntas: contexto, pregunta -> respuesta. Las firmas son flexibles y se pueden personalizar con información adicional, como descripciones de los campos de entrada y salida.
class GenerateAnswer(dspy.Signature):
"""Responde preguntas con respuestas cortas y factoides."""
context = dspy.InputField(desc="puede contener hechos relevantes")
question = dspy.InputField()
answer = dspy.OutputField(desc="a menudo entre 1 y 5 palabras")
# Módulos: Bloques de Construcción para el Comportamiento de LLM
Los módulos son componentes preconstruidos que encapsulan comportamientos o técnicas específicas de LLM. Son los bloques de construcción que utilizas para ensamblar tu aplicación LLM. Por ejemplo, el módulo ChainOfThought anima al LLM a pensar paso a paso, lo que lo hace mejor en tareas de razonamiento complejo. El módulo ReAct permite que tu LLM interactúe con herramientas externas como calculadoras o bases de datos. Puedes encadenar múltiples módulos juntos para crear flujos de trabajo sofisticados.
# Método 1: Pasa la Clase al módulo ChainOfThought
chain_of_thought = ChainOfThought(TranslateText)
Cada módulo toma una firma y, utilizando el método defined como ChainOfThought, construye el prompt necesario basado en las entradas y salidas definidas. Este método asegura que los prompts se generen sistemáticamente, manteniendo la consistencia y reduciendo la necesidad de redacción manual de prompts.
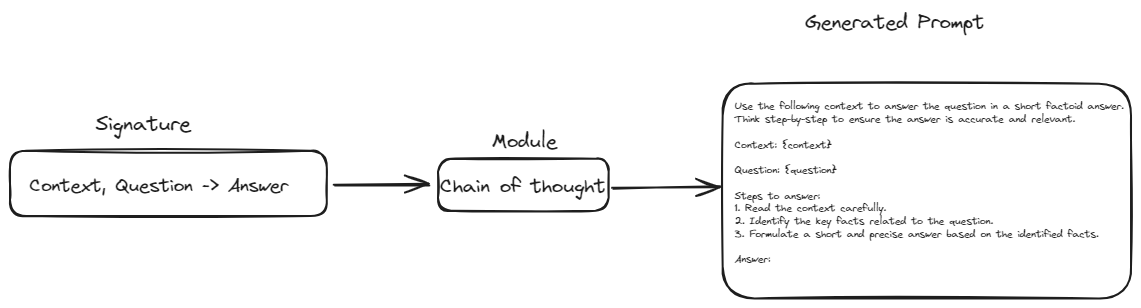
De esta manera, el módulo toma la firma, aplica su comportamiento o técnica específica, y genera un prompt que se alinea con los requisitos de la tarea. Esta integración de firmas y módulos permite construir aplicaciones LLM complejas y flexibles con una intervención manual mínima.
# Teleprompters (Optimizadores): Los Susurradores de Prompts
Los teleprompters son como entrenadores para tu LLM. Utilizan técnicas avanzadas para encontrar los mejores prompts para tu tarea y modelo específicos. Lo hacen probando automáticamente diferentes variaciones de prompts y evaluando su rendimiento basándose en una métrica que defines. Por ejemplo, un teleprompter podría usar una métrica como la precisión para tareas de respuesta a preguntas o la puntuación ROUGE para la resumen de texto.
from dspy.teleprompt import BootstrapFewShot
# Ejemplo simple de teleprompter
teleprompter = BootstrapFewShot(metric=dspy.evaluate.answer_exact_match)
# Compilador DSPy: El Maestro Orquestador
El compilador DSPy es el cerebro detrás de la operación. Toma todo tu programa, incluyendo tus firmas, módulos, datos de entrenamiento y lógica de validación, y lo optimiza para un rendimiento máximo. La capacidad del compilador de manejar automáticamente los cambios en tu aplicación hace que DSPy sea increíblemente robusto y adaptable.
from dspy.teleprompt import BootstrapFewShot
# Conjunto de entrenamiento pequeño con pares de pregunta y respuesta
trainset = [dspy.Example(question="¿Por qué es más conocido Albert Einstein?",
answer="La teoría de la relatividad").with_inputs('question'),
dspy.Example(question="¿Qué ecuación famosa produjo la teoría de la relatividad de Albert Einstein?",
answer="E = mc²").with_inputs('question'),
dspy.Example(question="¿Qué premio prestigioso recibió Albert Einstein en 1921?",
answer="El Premio Nobel de Física").with_inputs('question'),
dspy.Example(question="¿En qué año se mudó Albert Einstein a los Estados Unidos?",
answer="1933").with_inputs('question'),
dspy.Example(question="¿Qué trabajo científico significativo publicó Einstein en 1905, a veces referido como su annus mirabilis (año milagroso)?",
answer="Cuatro artículos revolucionarios que incluyen teorías sobre el efecto fotoeléctrico, el movimiento browniano, la teoría especial de la relatividad y la equivalencia masa-energía").with_inputs('question'),]
# Configura un teleprompter básico, que compilará nuestro programa RAG.
teleprompter = BootstrapFewShot(metric=dspy.evaluate.answer_exact_match)
compiled_rag = teleprompter.compile(RAG(), trainset=trainset)
El compilador DSPy toma el prompt básico, los ejemplos de entrenamiento y el programa DSPy para generar un prompt optimizado y de mejor rendimiento. Este proceso implica simular diversas versiones del programa en las entradas y realizar un proceso de arranque de los rastros de ejemplo de cada módulo para optimizar el flujo de trabajo para tu tarea
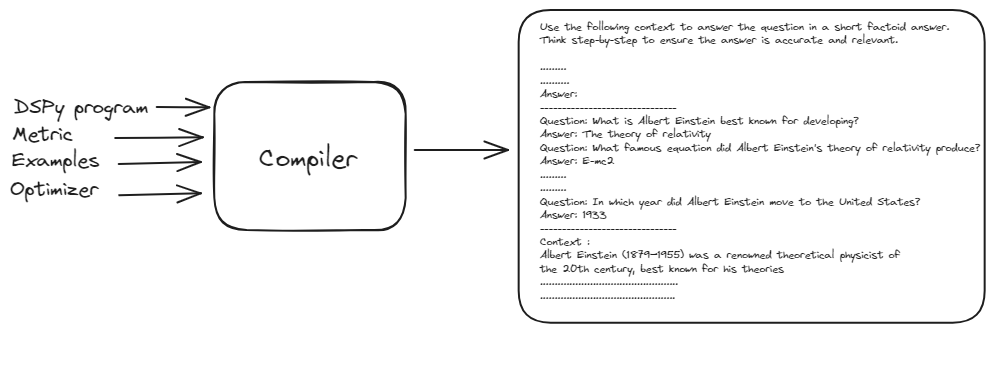
Este proceso de optimización automatizada elimina la necesidad de ajuste manual de prompts, haciendo que DSPy sea robusto y adaptable a cambios, y en última instancia proporciona un flujo de trabajo de PNL altamente eficaz y eficiente.
# Ejemplo Práctico: Construir un Modelo RAG Usando DSPy y MyScaleDB
Ahora que hemos cubierto lo básico de DSPy, creemos una aplicación práctica. Construiremos un flujo de trabajo de respuesta a preguntas RAG y usaremos MyScaleDB como base de datos vectorial.
# 1. Cargando Documentos desde Wikipedia
Comenzamos cargando documentos relacionados con "Albert Einstein" desde Wikipedia. Esto se hace usando el WikipediaLoader del módulo langchain_community.document_loaders.
from langchain_community.document_loaders.wikipedia import WikipediaLoader
loader = WikipediaLoader(query="Albert Einstein")
# Carga los documentos
docs = loader.load()
# 2. Transformando Documentos a Texto Plano
A continuación, transformamos los documentos cargados en texto plano usando el Html2TextTransformer.
from langchain_community.document_transformers import Html2TextTransformer
html2text = Html2TextTransformer()
docs_transformed = html2text.transform_documents(docs)
# Obtén el texto limpio
cleaned_text = docs_transformed[0].page_content
text = ' '.join([page.page_content.replace('\\t', ' ') for page in docs_transformed])
# 3. Dividiendo el Texto en Fragmentos
El texto se divide en fragmentos manejables usando el CharacterTextSplitter. Esto ayuda en el manejo de documentos grandes y asegura que el modelo los procese eficientemente.
import os
from langchain_text_splitters import CharacterTextSplitter
# Establece la clave API como una variable de entorno
os.environ["OPENAI_API_KEY"] = "tu_clave_openai_api"
# Divide el texto en fragmentos
text = ' '.join([page.page_content.replace('\\\\t', ' ') for page in docs])
text_splitter = CharacterTextSplitter(
separator="\\n",
chunk_size=300,
chunk_overlap=50,
length_function=len,
is_separator_regex=False,
)
texts = text_splitter.create_documents([text])
splits = [item.page_content for item in texts]
# 8. Definiendo el Modelo de Incrustaciones
Usamos la biblioteca transformers para definir un modelo de incrustaciones. Usaremos el modelo all-MiniLM-L6-v2 para transformar el texto en incrustaciones vectoriales.
import torch
from transformers import AutoTokenizer, AutoModel
# Inicializa el tokenizador y el modelo para incrustaciones
tokenizer = AutoTokenizer.from_pretrained("sentence-transformers/all-MiniLM-L6-v2")
model = AutoModel.from_pretrained("sentence-transformers/all-MiniLM-L6-v2")
def get_embeddings(texts: list) -> list:
inputs = tokenizer(texts, padding=True, truncation=True, return_tensors="pt", max_length=512)
with torch.no_grad():
outputs = model(**inputs)
embeddings = outputs.last_hidden_state.mean(dim=1)
return embeddings.numpy().tolist()
# 7. Obteniendo las Incrustaciones
Generamos incrustaciones para los fragmentos de texto usando el modelo de incrustaciones mencionado anteriormente.
import pandas as pd
all_embeddings = []
for i in range(0, len(splits), 25):
batch = splits[i:i+25]
embeddings_batch = get_embeddings(batch)
all_embeddings.extend(embeddings_batch)
# Crea un DataFrame con los fragmentos de texto y sus incrustaciones
df = pd.DataFrame({
'page_content': splits,
'embeddings': all_embeddings
})
# 8. Conectando a la Base de Datos Vectorial
Usaremos MyScaleDB (opens new window) como base de datos vectorial para desarrollar esta aplicación de muestra. Puedes crear una cuenta gratuita en MyScaleDB visitando la página de Registro (opens new window) de MyScale. Después de eso, puedes seguir el tutorial de inicio rápido (opens new window) para iniciar un nuevo clúster y obtener los detalles de conexión.
import clickhouse_connect
client = clickhouse_connect.get_client(
host='tu-host-en-la-nube',
port=443,
username='tu-nombre-de-usuario',
password='tu-contraseña'
)
Copia y pega los detalles de conexión en tu cuaderno Python y ejecuta el bloque de código. Se conectará con tu clúster MyScaleDB en la nube.
# 9. Creando una Tabla e Insertando Datos
Desglosemos el proceso de crear una tabla en el clúster MyScaleDB. Primero, crearemos una tabla llamada RAG. Esta tabla tendrá tres columnas: id, page_content y embeddings. La columna id contendrá el id único de cada fila, la columna page_content almacenará el contenido textual, y la columna embeddings guardará las incrustaciones del contenido de página correspondiente.
# Crea la tabla
client.command("""
CREATE TABLE IF NOT EXISTS default.RAG (
id Int64,
page_content String,
embeddings Array(Float32),
CONSTRAINT check_data_length CHECK length(embeddings) = 384
) ENGINE = MergeTree()
ORDER BY id
""")
# Inserta datos en la tabla
batch_size = 100
num_batches = (len(df) + batch_size - 1) // batch_size
for i in range(num_batches):
batch_data = df[i * batch_size: (i + 1) * batch_size]
client.insert('default.RAG', batch_data.values.tolist(), column_names=batch_data.columns.tolist())
print(f"Lote {i+1}/{num_batches} insertado.")
Después de crear la tabla, guardamos los datos en la tabla RAG recién creada en forma de lotes.
# 10. Configurando DSPy con MyScaleDB
Conectamos DSPy y MyScaleDB, y configuramos DSPy para usar nuestros modelos de lenguaje y recuperación por defecto.
import dspy
import openai
from dspy.retrieve.MyScaleRM import MyScaleRM
# Establece la clave API de OpenAI
openai.api_key = "tu_clave_api_openai"
# Configura LLM
lm = dspy.OpenAI(model="gpt-3.5-turbo")
# Configura el modelo de recuperación
rm = MyScaleRM(client=client,
table="RAG",
local_embed_model="sentence-transformers/all-MiniLM-L6-v2",
vector_column="embeddings",
metadata_columns=["page_content"],
k=6)
# Configura DSPy para usar el siguiente modelo de lenguaje y modelo de recuperación por defecto
dspy.settings.configure(lm=lm, rm=rm)
Nota: El modelo de incrustaciones que usamos aquí debería ser el mismo definido anteriormente.
# 11. Definiendo la Firma
Definimos la firma GenerateAnswer para especificar las entradas y salidas para nuestra tarea de respuesta a preguntas.
class GenerateAnswer(dspy.Signature):
"""Responde preguntas con respuestas cortas y factoides."""
context = dspy.InputField(desc="puede contener hechos relevantes")
question = dspy.InputField()
answer = dspy.OutputField(desc="a menudo entre 1 y 5 palabras")
# 12. Definiendo el Módulo RAG
El módulo RAG integra los pasos de recuperación y generación. Recupera pasajes relevantes y genera respuestas basadas en el contexto.
class RAG(dspy.Module):
def __init__(self, num_passages=3):
super().__init__()
self.retrieve = dspy.Retrieve(k=num_passages)
this.generate_answer = dspy.ChainOfThought(GenerateAnswer)
def forward(self, question):
context = this.retrieve(question).passages
prediction = this.generate_answer(context=context, question=question)
return dspy.Prediction(context=context, answer=prediction.answer)
El método forward acepta la pregunta como entrada y utiliza el recuperador para encontrar fragmentos relevantes de la base de datos integrada. Estos fragmentos recuperados se pasan luego al módulo ChainOfThought para generar un prompt fundamental.
# 13. Configurando Teleprompters
A continuación, usaremos el teleprompter/optimizador BootstrapFewShot para compilar y optimizar nuestro prompt básico.
from dspy.teleprompt import BootstrapFewShot
# Pequeño conjunto de entrenamiento con pares de pregunta y respuesta
trainset = [dspy.Example(question="¿Por qué es más conocido Albert Einstein?",
answer="La teoría de la relatividad").with_inputs('question'),
dspy.Example(question="¿Qué ecuación famosa produjo la teoría de la relatividad de Albert Einstein?",
answer="E = mc²").with_inputs
('question'),
dspy.Example(question="¿Qué premio prestigioso recibió Albert Einstein en 1921?",
answer="El Premio Nobel de Física").with_inputs('question'),
dspy.Example(question="¿En qué año se mudó Albert Einstein a los Estados Unidos?",
answer="1933").with_inputs('question'),
dspy.Example(question="¿Qué trabajo científico significativo publicó Einstein en 1905, a veces referido como su annus mirabilis (año milagroso)?",
answer="Cuatro artículos revolucionarios que incluyen teorías sobre el efecto fotoeléctrico, el movimiento browniano, la teoría especial de la relatividad y la equivalencia masa-energía").with_inputs('question'),]
# Configura un teleprompter básico, que compilará nuestro programa RAG.
teleprompter = BootstrapFewShot(metric=dspy.evaluate.answer_exact_match)
# Compila el flujo de trabajo RAG con el teleprompter
compiled_rag = teleprompter.compile(RAG(), trainset=trainset)
Este código toma la clase RAG definida anteriormente y utiliza los ejemplos junto con el optimizador para generar el mejor prompt posible para nuestro LLM.
# 14. Ejecutando el Flujo de Trabajo
Finalmente, ejecutamos nuestro flujo de trabajo RAG compilado para responder preguntas basadas en el contexto almacenado en MyScaleDB.
# Recupera documentos relevantes
retrieve_relevant_docs = dspy.Retrieve(k=5)
context = retrieve_relevant_docs("¿Quién es Albert Einstein?").passages
# Realiza la consulta
pred = compiled_rag(question="¿Quién fue Albert Einstein?")
Esto generará una salida como esta:
['Albert Einstein (1879–1955) fue un renombrado físico teórico del siglo XX,
mejor conocido por sus teorías de la relatividad especial ........
.......
su originalidad han hecho que la palabra "Einstein" sea sinónimo de "genio".']

# Conclusión
El marco DSPy ha revolucionado nuestra interacción con los LLMs reemplazando los prompts codificados con una interfaz programable, simplificando significativamente el proceso de desarrollo. Esta transición de la redacción manual de prompts a una metodología más estructurada y orientada a la programación ha mejorado la eficiencia, consistencia y escalabilidad de las aplicaciones de IA. Al abstraer las complejidades de la ingeniería de prompts, DSPy permite a los desarrolladores concentrarse en definir la lógica y los flujos de trabajo de alto nivel, acelerando así el despliegue de soluciones sofisticadas impulsadas por IA.
MyScaleDB, una base de datos vectorial desarrollada específicamente para aplicaciones de IA, juega un papel crucial en mejorar el rendimiento de estos sistemas. Sus algoritmos avanzados y patentados aumentan la velocidad y precisión de las aplicaciones de IA. Además, MyScaleDB es rentable, ofreciendo a los nuevos usuarios almacenamiento gratuito para hasta 5 millones de vectores. Esto lo convierte en una opción atractiva para startups e investigadores que buscan utilizar soluciones de base de datos robustas sin la inversión inicial.



