
Los modelos de lenguaje grandes (opens new window) (LLM) han revolucionado el campo del Procesamiento del Lenguaje Natural (NLP), introduciendo una nueva forma de interactuar con la tecnología. Modelos avanzados como GPT (opens new window) y BERT (opens new window) han inaugurado una nueva era en la comprensión semántica. Permiten a las computadoras procesar y generar texto similar al humano, cerrando la brecha entre la comunicación humana y la interpretación de las máquinas. Los LLM ahora alimentan múltiples aplicaciones, incluyendo análisis de sentimientos, traducción automática, preguntas y respuestas, resumen de texto, chatbots, asistentes virtuales y más.
A pesar de sus aplicaciones prácticas, los modelos de lenguaje grandes (LLM) tienen sus propios desafíos. Están diseñados para ser generalizados, lo que significa que pueden carecer de especificidad. Además, debido a que se entrenan con datos pasados, no siempre pueden proporcionar la información más reciente. Esto puede resultar en que los LLM generen respuestas incorrectas o desactualizadas, lo que lleva a un fenómeno llamado "alucinación (opens new window)". Surge cuando los modelos cometen errores o generan información impredecible debido a lagunas en sus datos de entrenamiento.
Los sistemas de generación con recuperación aumentada (RAG) se utilizan para abordar problemas como la falta de especificidad y las actualizaciones en tiempo real, ofreciendo soluciones potenciales para mejorar la implementación responsable de los LLM.
# ¿Qué es RAG?
En 2020, los investigadores de Meta propusieron la generación con recuperación aumentada (RAG) combinando la capacidad de generación de lenguaje natural (NLG) de los LLM con el componente de recuperación de información (IR) para optimizar la salida. Se refiere a una fuente de conocimiento confiable fuera de sus fuentes de datos de entrenamiento antes de responder a la consulta. Amplía las capacidades de los LLM sin necesidad de volver a entrenar el modelo, lo que proporciona una forma rentable de mejorar la relevancia, precisión y usabilidad de la salida en diversos contextos.
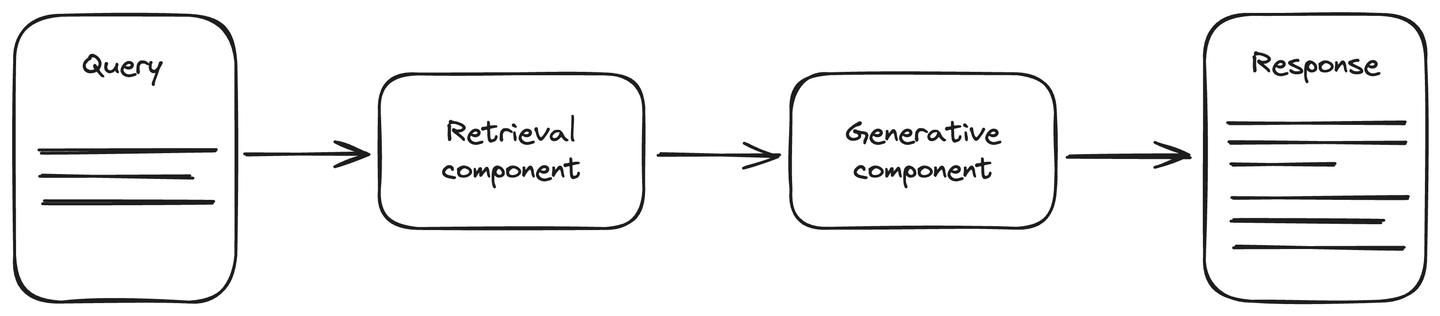
La arquitectura RAG incluye una fuente de datos actualizada para mejorar la precisión durante las tareas de IA generativa. Se divide en dos componentes principales: el componente de recuperación y el componente generativo. El componente de recuperación está conectado a una fuente de datos, generalmente una base de datos vectorial, que recupera la información actualizada sobre la consulta. Esta información, junto con la consulta, se proporciona al componente generativo. El componente generativo es un modelo LLM que genera la respuesta en consecuencia. RAG mejora la comprensión de los LLM y la respuesta generada es más precisa y actualizada.
Artículo relacionado: Qué esperar de RAG (opens new window)
# Cómo configurar el componente de recuperación de un sistema RAG
En primer lugar, debes recopilar todos los datos necesarios para tu aplicación. Una vez que hayas completado la recopilación de datos, elimina los datos irrelevantes. Divide los datos recopilados en fragmentos más pequeños y manejables y convierte estos fragmentos en representaciones vectoriales utilizando modelos de incrustación (opens new window). Los vectores son representaciones numéricas donde el contenido semánticamente similar está más cerca entre sí. Esto permite que el sistema comprenda y coincida la consulta del usuario con la información relevante en la fuente de datos. Almacena los vectores en una base de datos vectorial y vincula los fragmentos de datos fuente con sus incrustaciones. Esto ayudará a recuperar el fragmento de datos de un vector similar a la consulta del usuario.
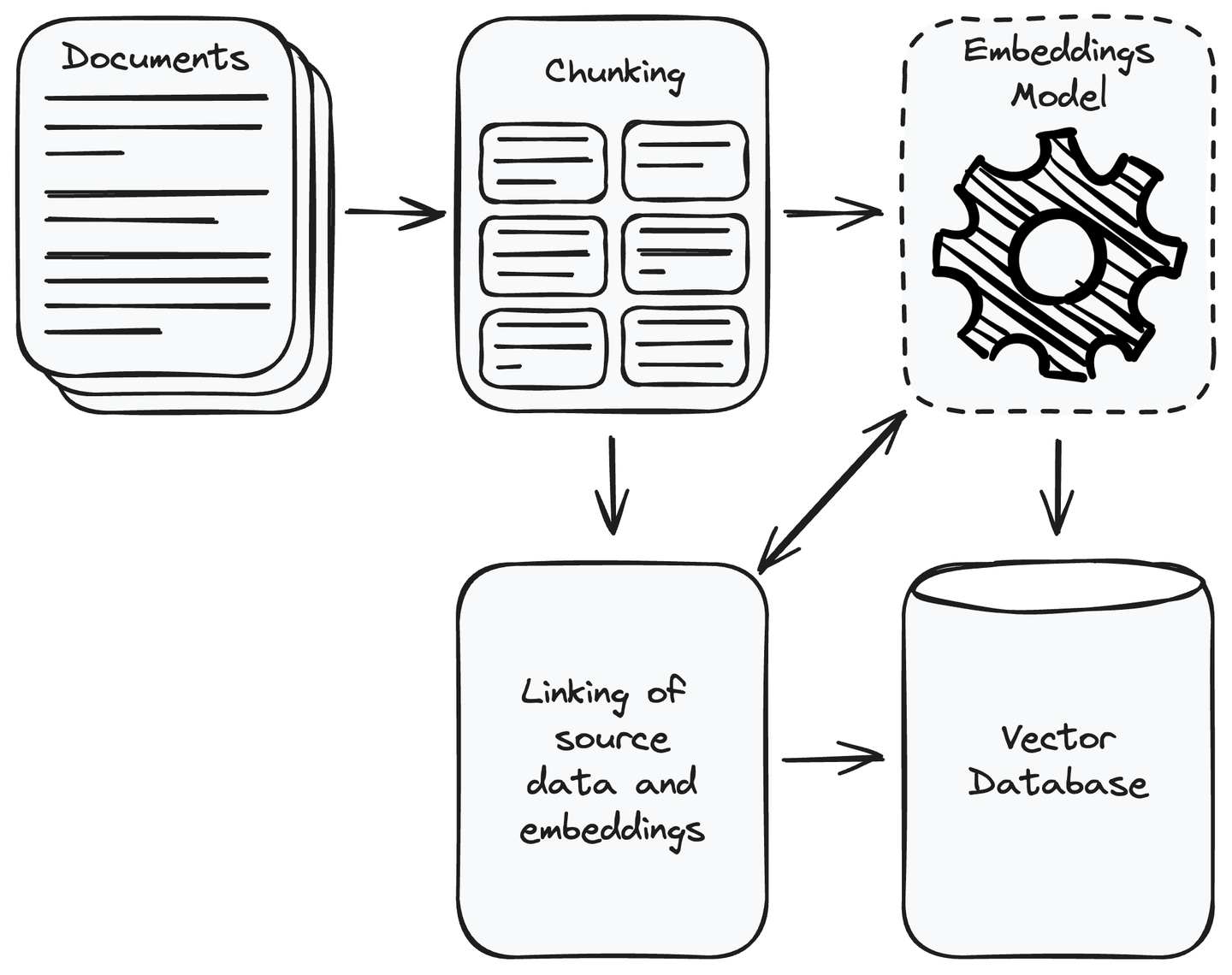
MyScale (opens new window) es una base de datos vectorial basada en la nube y basada en ClickHouse (opens new window) que combina las consultas SQL habituales con la fortaleza de una base de datos vectorial. Esto te permite guardar y encontrar datos de alta dimensionalidad, como características de imágenes o incrustaciones de texto, utilizando las consultas SQL regulares para solicitar información. MyScale es especialmente potente para aplicaciones de IA donde es importante comparar vectores. Está diseñado para ser asequible y práctico para los desarrolladores que trabajan con una gran cantidad de datos vectoriales en tareas de IA y aprendizaje automático.
Además, MyScale está diseñado para ser más asequible, rápido y preciso que otras opciones. Para animar a los usuarios a experimentar con sus beneficios, MyScale ofrece 5 millones de almacenamiento de vectores gratuitos en el nivel gratuito. Esto lo convierte en una solución rentable y fácil de usar para los desarrolladores que exploran bases de datos vectoriales en sus proyectos de IA y aprendizaje automático.
Artículo relacionado: Construye un chatbot habilitado para RAG (opens new window)
# ¿Cómo funciona un sistema RAG?
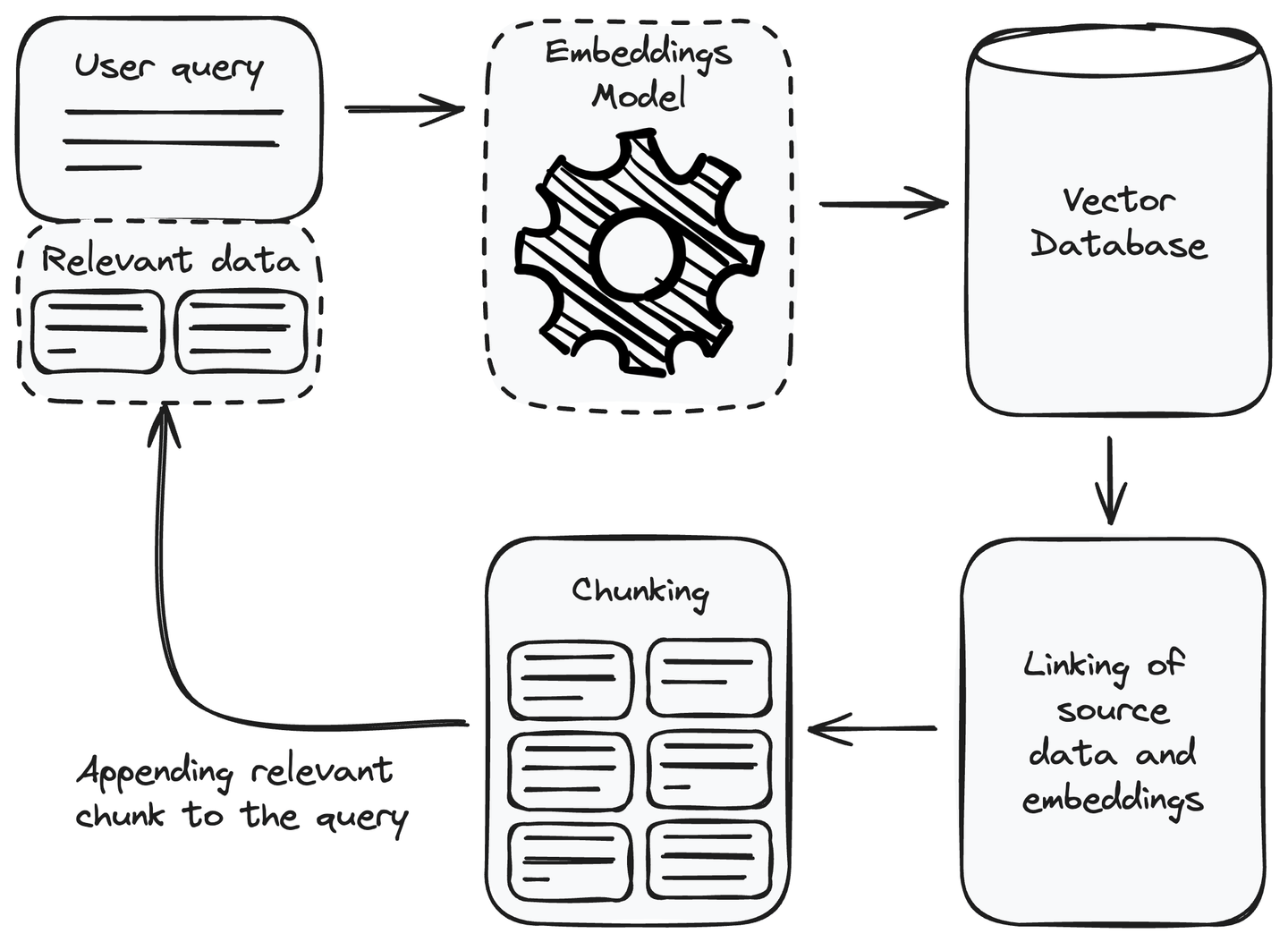
Después de configurar el componente de recuperación, ahora podemos utilizarlo en nuestro sistema RAG. Para responder a una consulta del usuario, podemos utilizarlo para recuperar la información relevante y agregarla a la consulta del usuario como contexto antes de pasarla al modelo de lenguaje para generar la respuesta. Veamos cómo utilizar el componente de recuperación para obtener la información relevante.
# Agregar información relevante a la consulta
Cada vez que recibimos una consulta del usuario, el primer paso que debemos realizar es convertir la consulta del usuario en una representación de incrustación o vector. Utiliza el mismo modelo de incrustación que utilizamos para convertir la fuente de datos en incrustaciones al configurar el componente de recuperación. Después de la conversión de la consulta del usuario en una representación vectorial, encuentra los
# Generar respuesta utilizando LLM
Ahora, tenemos la consulta y los fragmentos de información relacionados. Alimenta la consulta del usuario junto con los datos recuperados al LLM (el componente generativo). El LLM es capaz de comprender la consulta del usuario y procesar los datos proporcionados. Generará la respuesta a la consulta del usuario de acuerdo con la información recibida del componente de recuperación.
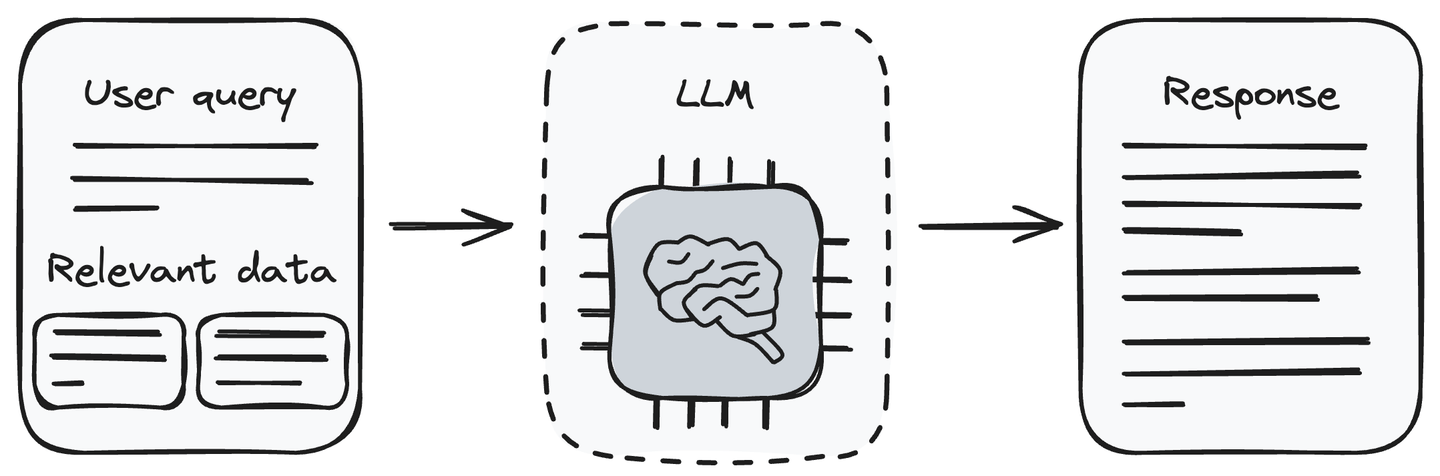
Pasar la información relevante junto con la consulta del usuario al LLM es un método que elimina el problema de la alucinación de los LLM. Ahora, el LLM puede generar respuestas a la consulta del usuario utilizando la información que le proporcionamos junto con la consulta del usuario.
Nota: Recuerda actualizar la base de datos regularmente con la información más reciente para garantizar la precisión del modelo.
# Algunas aplicaciones de RAG
Los sistemas RAG se pueden utilizar en diferentes aplicaciones que requieren una recuperación de información precisa y contextualmente relevante. Esto ayuda a mejorar la precisión, puntualidad y confiabilidad de las respuestas generadas. Veamos algunas aplicaciones de un sistema RAG.
- Preguntas específicas del dominio: Cuando un sistema RAG se enfrenta a preguntas en un dominio específico, utiliza el componente de recuperación para acceder dinámicamente a fuentes de conocimiento externas, bases de datos o documentos específicos del dominio. Esto permite que los sistemas RAG generen respuestas contextualmente relevantes al reflejar la información más reciente y precisa dentro del dominio especificado. Esto podría ser útil en varios dominios, como la atención médica, la interpretación legal, la investigación histórica, la solución de problemas técnicos, etc.
- Precisión factual: La precisión factual es crucial para garantizar que el contenido o las respuestas generadas se alineen con datos precisos y verificados. En situaciones donde puedan surgir inexactitudes, RAG prioriza la precisión factual para proporcionar información que sea coherente con la realidad del tema en cuestión. Esto es esencial para diversas aplicaciones, incluyendo la cobertura de noticias, el contenido educativo y cualquier escenario donde la confiabilidad y la confianza en la información sean fundamentales.
- Consultas de investigación: Los sistemas RAG son valiosos para abordar consultas de investigación al recuperar de manera dinámica información relevante y actualizada de sus fuentes de conocimiento. Por ejemplo, supongamos que un investigador realiza una consulta relacionada con los últimos avances en un campo científico específico. En ese caso, un sistema RAG puede aprovechar su componente de recuperación para acceder a documentos de investigación recientes, publicaciones y datos relevantes para garantizar que el investigador reciba información contextualmente precisa y actualizada.
Artículo relacionado: Cómo construir un sistema de recomendación (opens new window)

# Desafíos para construir un sistema RAG
Aunque los sistemas RAG tienen varios casos de uso y ventajas, también enfrentan algunas limitaciones únicas. Veamos algunas de ellas:
- Integración: Integrar un componente de recuperación con un componente generativo basado en LLM puede ser difícil. La complejidad aumenta al trabajar con múltiples fuentes de datos en diferentes formatos. Asegúrate de mantener la consistencia en todas las fuentes de datos utilizando módulos separados antes de integrar el componente de recuperación con el componente generativo.
- Calidad de los datos: Los sistemas RAG dependen de la fuente de datos adjunta. La calidad de un sistema RAG puede ser deficiente por múltiples razones, como el uso de contenido de baja calidad, el uso de diferentes incrustaciones en caso de múltiples fuentes de datos o el uso de formatos de datos inconsistentes. Asegúrate de mantener la calidad de los datos.
- Escalabilidad: El rendimiento de un sistema RAG se ve comprometido a medida que aumenta la cantidad de datos externos. Las tareas de convertir datos en incrustaciones, comparar el significado de fragmentos similares de datos y recuperar en tiempo real pueden volverse computacionalmente intensivas. Esto puede ralentizar el sistema RAG. Para abordar este problema, puedes utilizar MyScale, que ha resuelto el problema al proporcionar una velocidad de consulta promedio de 390 QPS (consultas por segundo) en el conjunto de datos LAION 5M con una tasa de recuperación del 95% y una latencia de consulta promedio de 17 ms con el pod x1.
# Conclusión
RAG es una de las técnicas para mejorar las capacidades de los LLM al adjuntarle una base de conocimientos. Puedes entenderlo como un motor de búsqueda con habilidades de generación de lenguaje. Estos sistemas mitigan el problema de la alucinación de los LLM sin ningún costo de reentrenamiento o ajuste fino. El uso de una fuente de datos externa al responder a la consulta del usuario proporciona una respuesta más precisa y actualizada, especialmente cuando se trabaja con datos factuales, actualizados o regularmente actualizados. A pesar de estas ventajas de los sistemas RAG, también tienen sus limitaciones.
MyScale ofrece una solución potente para aplicaciones RAG complejas y a gran escala al combinar las fortalezas de ClickHouse, algoritmos avanzados de búsqueda vectorial y optimizaciones conjuntas de vectores SQL. Está diseñado específicamente para aplicaciones de IA, teniendo en cuenta todos los factores, incluidos el costo y la escalabilidad. Además, proporciona integraciones con conocidos marcos de IA como LangChain (opens new window) y LlamaIndex (opens new window). Estas cualidades y características hacen de MyScale la mejor opción para tu próxima aplicación de IA.
Si tienes alguna sugerencia o comentario, contáctanos a través de Twitter (opens new window) o Discord (opens new window).



