
La generación aumentada por recuperación (RAG) (opens new window) ha sido un avance importante en el campo del procesamiento del lenguaje natural (NLP, por sus siglas en inglés). Ha optimizado la mayoría de las tareas de NLP debido a su simplicidad y eficiencia. Al combinar las fortalezas de los sistemas de recuperación (bases de datos vectoriales) y los modelos generativos (LLMs), RAG mejora significativamente el rendimiento de los sistemas de IA en áreas como la generación de texto, la traducción y la respuesta a preguntas.
La integración de bases de datos vectoriales ha sido un componente clave en la revolución del rendimiento de los sistemas RAG. Exploremos la relación entre RAG y las bases de datos vectoriales y cómo han trabajado juntos para lograr resultados tan notables.
# Una breve descripción del modelo RAG
RAG es una técnica diseñada específicamente para mejorar el rendimiento de los modelos de lenguaje grandes (LLMs, por sus siglas en inglés). Recupera información relacionada con la consulta del usuario de las bases de datos vectoriales y la proporciona al LLM como referencia. Este proceso mejora significativamente la calidad de las respuestas de los LLM, haciéndolas más precisas y relevantes. La siguiente imagen muestra brevemente cómo funciona un modelo RAG (opens new window).
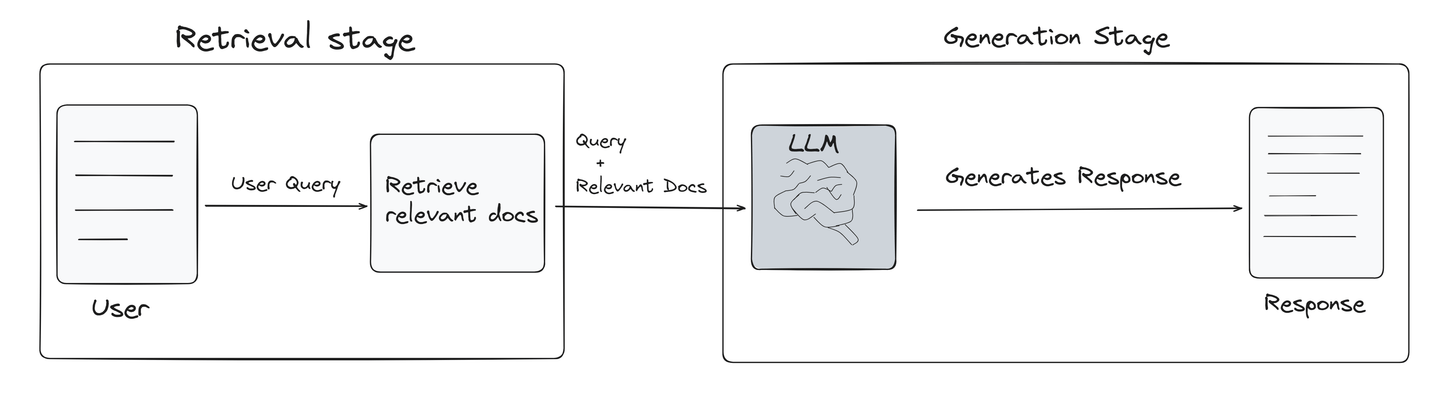
Etapa de recuperación: RAG primero identifica la información más relevante de la base de datos vectorial utilizando la potencia de la búsqueda de similitud. Esta etapa es la parte más crítica de cualquier sistema RAG, ya que sienta las bases para la calidad de la salida final.
Etapa de generación: Una vez que se recupera la información relevante, la consulta del usuario junto con los documentos recuperados se pasan al modelo LLM para producir nuevo contenido que sea coherente, relevante e informativo.
La implementación de RAG mejora significativamente el rendimiento de los LLM al abordar limitaciones clave como imprecisiones factuales, conocimientos desactualizados y alucinaciones. La recuperación de información relevante y actualizada de las bases de datos vectoriales mejora en gran medida la precisión y confiabilidad de las respuestas de los LLM, especialmente en tareas intensivas en conocimiento.
Además, introduce un nivel de transparencia y trazabilidad que permite a los usuarios verificar el origen de la información proporcionada. Este enfoque híbrido de combinar las capacidades generativas de los LLM con el poder informativo de los sistemas de recuperación conduce a aplicaciones de IA más sólidas y confiables que pueden adaptarse dinámicamente a una amplia gama de consultas y tareas complejas.
# El papel de las bases de datos vectoriales
Una base de datos vectorial es un tipo especializado de base de datos diseñada para almacenar y gestionar datos en forma de vectores numéricos, conocidos como embeddings. Estos embeddings codifican los significados semánticos y la información contextual de cualquier tipo de datos. Los datos pueden ser texto, imágenes o incluso audio. Las bases de datos vectoriales almacenan eficientemente estos embeddings y proporcionan una recuperación rápida de los embeddings a través de una búsqueda de similitud. Estas características desempeñan un papel importante en tareas como la recuperación de información, los sistemas de recomendación y la búsqueda semántica. Estas bases de datos son particularmente útiles en aplicaciones de aprendizaje automático (ML, por sus siglas en inglés) e inteligencia artificial (IA), donde los datos se transforman a menudo en espacios vectoriales para capturar patrones y relaciones complejas.
Las características clave de las bases de datos vectoriales incluyen:
- Soporte para datos de alta dimensionalidad: Estas bases de datos están diseñadas para manejar datos vectoriales de alta dimensionalidad, que se utilizan comúnmente en modelos de aprendizaje automático.
- Búsqueda eficiente: Estas bases de datos proporcionan algoritmos de búsqueda optimizados para encontrar rápidamente los vectores más similares de un vasto conjunto de datos. La funcionalidad de búsqueda principal es la búsqueda del vecino más cercano, y todos los algoritmos están diseñados para optimizar este enfoque.
- Escalabilidad: Las bases de datos vectoriales están diseñadas para manejar grandes volúmenes de datos y consultas de usuarios. Esto las hace adecuadas para conjuntos de datos en crecimiento y demandas crecientes.
- Indexación: Estas bases de datos a menudo utilizan técnicas avanzadas de indexación para acelerar el proceso de búsqueda y comparación de vectores.
- Integración: Se pueden integrar fácilmente en canalizaciones de aprendizaje automático para proporcionar capacidades de recuperación de datos en tiempo real.
Las bases de datos vectoriales son un componente crucial en sistemas que aprovechan el aprendizaje automático para tareas como el reconocimiento de imágenes, el análisis de texto y los algoritmos de recomendación, donde la capacidad de acceder y comparar rápidamente conjuntos grandes de datos vectorizados es fundamental.
# Cómo las bases de datos vectoriales mejoran el rendimiento de RAG
Las bases de datos vectoriales mejoran significativamente el rendimiento de los sistemas RAG al optimizar varias etapas del flujo de trabajo. Inicialmente, los datos textuales se convierten en vectores utilizando un modelo de embedding. Esta conversión es importante ya que transforma los datos textuales en un formato que se puede almacenar y recuperar de manera eficiente según los significados semánticos.
La fortaleza de una base de datos vectorial radica en sus métodos avanzados de indexación. Una vez que los datos se convierten en vectores, se guardan en la base de datos vectorial utilizando métodos avanzados de indexación como HNSW (Hierarchical Navigable Small World) o IVF (Inverted File Index) (opens new window). Estos métodos de indexación organizan los vectores de manera que permiten una recuperación rápida y eficiente. El proceso de indexación garantiza que cuando se realiza una consulta, el sistema pueda localizar rápidamente los vectores relevantes del vasto conjunto de datos.
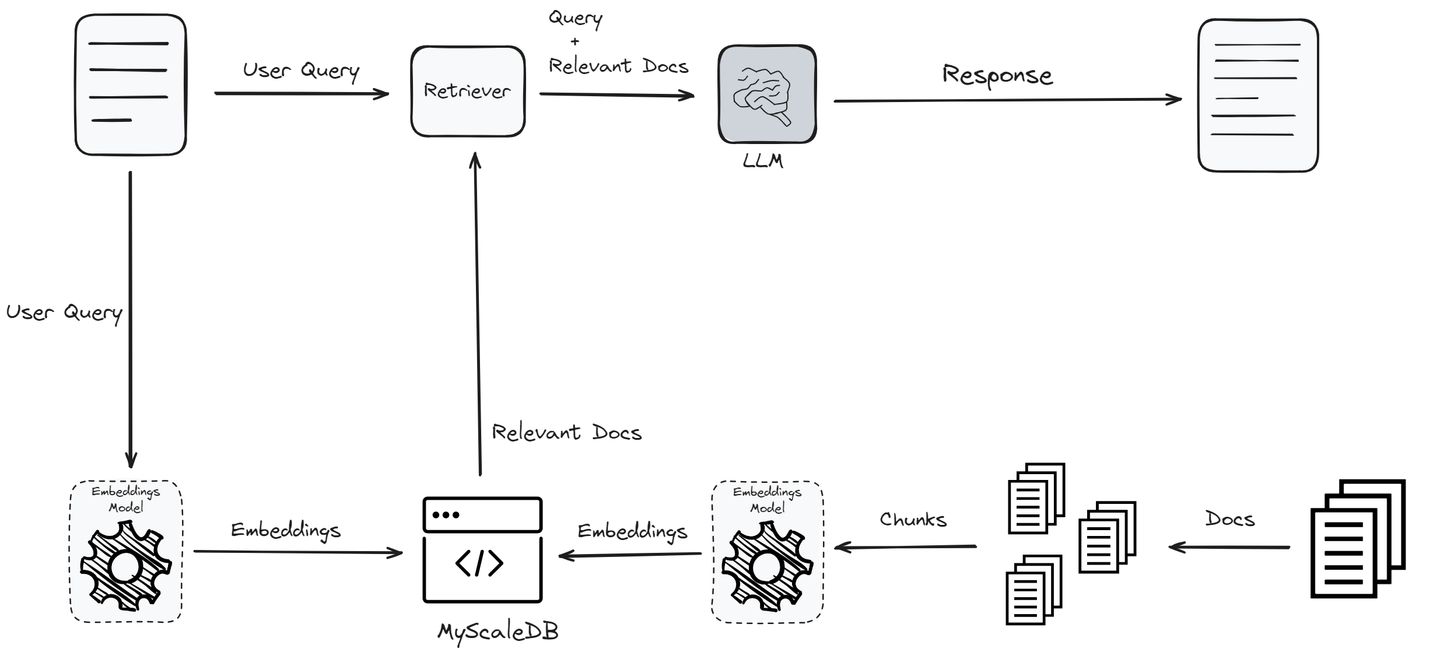
Cuando un usuario envía una consulta, esta también se convierte en un vector utilizando el mismo modelo de embedding. La base de datos vectorial busca el clúster más cercano con vectores similares. La base de datos vectorial busca clústeres de vectores que sean semánticamente más cercanos al vector de consulta. Esta búsqueda de similitud es la base de cualquier sistema RAG y las bases de datos vectoriales permiten la identificación rápida y precisa de vectores semánticamente similares.
Los documentos similares se pasan al recuperador, que combina la consulta con los documentos relevantes y los envía al LLM para generar la respuesta. El uso de bases de datos vectoriales garantiza que el recuperador trabaje con la información más relevante. Esto mejora la precisión y relevancia de la respuesta generada.
Las bases de datos vectoriales no solo mejoran la velocidad de recuperación, sino que también manejan grandes volúmenes de datos de manera eficiente. Esta escalabilidad es esencial para aplicaciones que manejan conjuntos de datos extensos. Al garantizar una recuperación rápida y precisa, las bases de datos vectoriales admiten consultas en tiempo real, proporcionando respuestas inmediatas y relevantes a los usuarios.

# La solución ideal: bases de datos vectoriales especializadas vs. bases de datos vectoriales de SQL
En los sistemas RAG del mundo real, superar la precisión de recuperación (y los cuellos de botella de rendimiento asociados) requiere una forma eficiente de combinar la consulta de datos estructurados, vectoriales y basados en palabras clave.
Algunas bases de datos vectoriales (como Pinecone, Weaviate y Milvus) están diseñadas específicamente para la búsqueda de vectores desde el principio. Exhiben un buen rendimiento en esta área, pero tienen capacidades de gestión de datos generales algo limitadas.
- Capacidades de consulta limitadas: Proporcionan un soporte limitado para consultas complejas, incluidas aquellas con múltiples condiciones, uniones y agregaciones, debido al almacenamiento de metadatos restringido.
- Restricciones de tipo de datos: Diseñadas principalmente para almacenamiento de vectores y metadatos mínimos, carecen de la flexibilidad para manejar varios tipos de datos como enteros, cadenas y fechas.
Las bases de datos vectoriales de SQL (opens new window) representan una fusión avanzada de las funcionalidades tradicionales de las bases de datos SQL con las capacidades especializadas de las bases de datos vectoriales. Estos sistemas integran algoritmos de búsqueda de vectores directamente en el entorno de datos estructurados, lo que permite la gestión de datos vectoriales y estructurados dentro de un marco de base de datos unificado.
Esta integración proporciona varias ventajas clave:
- Comunicación simplificada entre tipos de datos.
- Filtrado flexible basado en metadatos.
- Soporte para ejecutar consultas tanto SQL como de vectores.
- Compatibilidad con herramientas existentes diseñadas para bases de datos de propósito general.
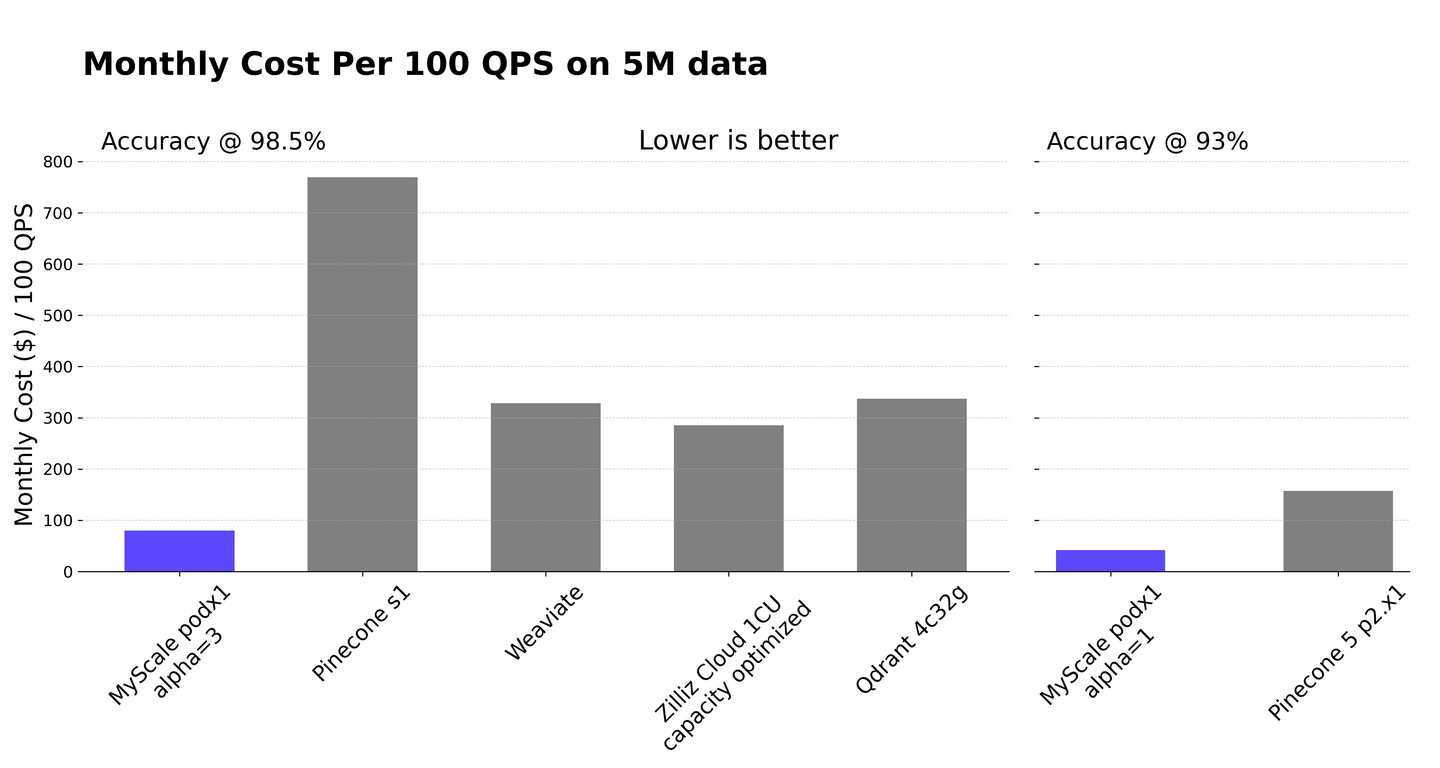
Entre las bases de datos vectoriales de SQL, MyScaleDB (opens new window) es una opción de código abierto que amplía las capacidades de ClickHouse. Combina de manera transparente la gestión de datos estructurados con operaciones vectoriales, optimizando el rendimiento para interacciones de datos complejas y mejorando la eficiencia de los sistemas RAG. Con búsquedas filtradas (opens new window), MyScaleDB filtra eficientemente los datos en conjuntos de datos grandes según atributos específicos antes de realizar búsquedas vectoriales, garantizando una recuperación rápida y precisa para los sistemas RAG.
# Conclusión
Las bases de datos vectoriales han mejorado en gran medida los sistemas RAG al optimizar la recuperación y el procesamiento de datos. Estas bases de datos permiten el almacenamiento eficiente y la recuperación rápida basada en el significado semántico. Los métodos avanzados de indexación como HNSW y IVF garantizan que los datos relevantes se encuentren rápidamente, mejorando la precisión de las respuestas. Además, las bases de datos vectoriales manejan grandes volúmenes de datos, proporcionando la escalabilidad necesaria para consultas en tiempo real y respuestas inmediatas a los usuarios.
Una base de datos vectorial de SQL lleva estas ventajas aún más lejos al integrar la búsqueda de vectores con SQL. Esto permite interacciones de datos complejas y precisas. Esta integración simplifica el desarrollo y reduce la curva de aprendizaje para construir aplicaciones RAG robustas.
Te invitamos a explorar el repositorio de MyScaleDB de código abierto en GitHub (opens new window) y aprovechar SQL y vectores para construir aplicaciones RAG innovadoras a nivel de producción.
Este artículo fue publicado originalmente en The New Stack. (opens new window)



