
ChatGPT (opens new window) y otros modelos de lenguaje grandes (LLMs) (opens new window) han avanzado mucho en la comprensión y generación de texto similar al humano. Sin embargo, a menudo tienen dificultades para mantenerse precisos y relevantes, especialmente en campos que cambian rápidamente o son especializados. Esto se debe a que se basan en conjuntos de datos grandes pero fijos que pueden volverse rápidamente obsoletos. Aquí es donde las bases de datos vectoriales (opens new window) pueden ayudar, proporcionando una forma de mantener estos modelos actualizados y contextualmente conscientes.
Las bases de datos vectoriales ofrecen una solución a este desafío al proporcionar a los LLMs, incluido ChatGPT, acceso a información relevante y actualizada que va más allá de su entrenamiento inicial. Al integrar bases de datos vectoriales, estos modelos pueden recuperar y aprovechar datos específicos y enfocados en un dominio, lo que conduce a una mayor precisión en las respuestas y una mayor conciencia contextual.
Este artículo explora cómo la utilización de bases de datos vectoriales puede mejorar el rendimiento de ChatGPT. Examinaremos cómo las potentes capacidades de recuperación de las bases de datos vectoriales pueden permitir que ChatGPT maneje tareas especializadas y preguntas detalladas de manera más efectiva, convirtiéndolo en una herramienta más confiable y versátil para los usuarios.
# Comprendiendo las bases de datos vectoriales
Antes de discutir su integración, es vital comprender qué son las bases de datos vectoriales y cómo están revolucionando la IA.
# ¿Qué es una base de datos vectorial?
Una base de datos vectorial es un tipo especial de base de datos diseñada para manejar puntos de datos complejos conocidos como vectores (opens new window). Los vectores son como listas de números que representan datos de una manera que facilita la comparación y búsqueda de similitudes. En lugar de organizar la información en filas y columnas como las bases de datos tradicionales, las bases de datos vectoriales almacenan los datos como estas listas numéricas. Esto las hace muy eficientes para manejar tareas que implican encontrar patrones y similitudes, como recomendar productos o identificar imágenes similares.
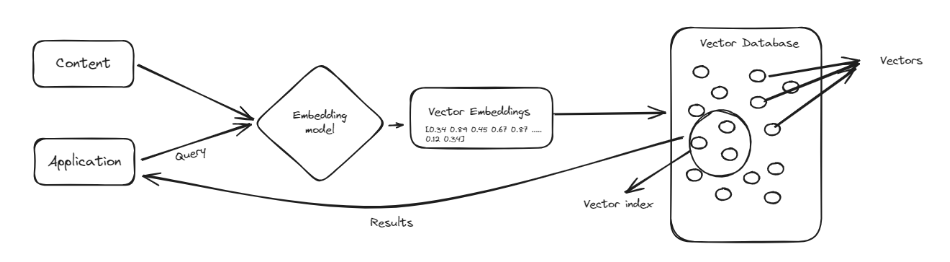
Una de las principales ventajas de las bases de datos vectoriales es su capacidad para buscar rápidamente grandes cantidades de datos y encontrar información relevante. Son particularmente útiles en campos como el aprendizaje automático e inteligencia artificial, donde comprender las relaciones entre los puntos de datos es crucial. Al utilizar bases de datos vectoriales, podemos mejorar herramientas como ChatGPT, haciéndolas más inteligentes y eficientes en el procesamiento y recuperación de información, lo que conduce a respuestas mejores y más precisas.
# Bases de datos vectoriales vs. Bases de datos tradicionales
Cuando se trata de administrar registros estructurados y garantizar la integridad de los datos almacenados, las bases de datos relacionales tradicionales no tienen igual; sin embargo, en comparación con ellas:
- Las bases de datos vectoriales son más flexibles para manejar puntos de datos multidimensionales.
- Las bases de datos vectoriales procesan grandes cantidades de información más rápido.
- Los métodos de recuperación basados en similitud funcionan mejor en las bases de datos vectoriales debido a su eficiencia en el manejo de operaciones rápidas durante el reconocimiento de patrones o la búsqueda de similitudes, que son importantes para las aplicaciones de IA.
# Por qué las bases de datos vectoriales son clave para ChatGPT
Los LLMs como ChatGPT han demostrado un progreso notable en el procesamiento y generación de lenguaje natural. Sin embargo, estos modelos también enfrentan varias limitaciones que se pueden abordar mediante la integración de bases de datos vectoriales.
- Alucinaciones de conocimiento: Una base de datos vectorial actuaría como una base de conocimientos confiable y reduciría la información falsa.
- Falta de capacidad de almacenamiento de memoria a largo plazo: Almacenando datos relevantes de manera eficiente, se puede considerar como otra memoria para el modelo respectivo.
- Problema de comprensión contextual: Las representaciones vectoriales permiten una comprensión matizada del contexto y las relaciones entre conceptos.
# Integrar ChatGPT con MyScale para un asistente de recursos humanos de IA
En este tutorial, recorreremos el proceso de integración de ChatGPT con MyScale (opens new window), una potente base de datos vectorial, para crear un asistente de recursos humanos de IA capaz de responder consultas de los empleados las 24 horas del día. Este ejemplo práctico demostrará cómo las bases de datos vectoriales pueden mejorar ChatGPT al proporcionar información actualizada y específica del dominio.
# Paso 1: Configurar el entorno
Primero, debemos configurar nuestro entorno instalando las bibliotecas necesarias. Estas bibliotecas incluyen langchain para administrar modelos de lenguaje y procesamiento de texto, sentence-transformers para crear incrustaciones y openai para el modelo ChatGPT.
pip install langchain sentence-transformers openai
# Paso 2: Configurar las variables de entorno
Necesitamos configurar las variables de entorno para conectarnos a MyScale y la API de OpenAI. Estas variables incluyen el host, el puerto, el nombre de usuario y la contraseña para MyScale, y la clave de API para OpenAI.
import os
# Configurando las conexiones de la base de datos vectorial
os.environ["MYSCALE_HOST"] = "tu_nombre_de_host_aquí"
os.environ["MYSCALE_PORT"] = "número_de_puerto"
os.environ["MYSCALE_USERNAME"] = "tu_nombre_de_usuario_aquí"
os.environ["MYSCALE_PASSWORD"] = "tu_contraseña_aquí"
# Configurando la clave de API para OpenAI
os.environ["OPENAI_API_KEY"] = "tu_clave_de_api_aquí"
Nota: Si no tienes una cuenta de MyScaleDB (opens new window), visita el sitio web de MyScale para registrarte (opens new window) y obtener una cuenta gratuita, y sigue la guía de inicio rápido (opens new window). Para usar la API de OpenAI, crea una cuenta en el sitio web de OpenAI (opens new window) y obtén la clave de API.
# Paso 3: Cargar los datos
Cargamos el manual del empleado en formato PDF y lo dividimos en páginas para su procesamiento. Esto implica utilizar un cargador de documentos.
from langchain_community.document_loaders import PyPDFLoader
loader = PyPDFLoader("Manual_del_Empleado.pdf")
pages = loader.load_and_split()
# Saltar las primeras páginas si es necesario
pages = pages[4:]
La clase PyPDFLoader se utiliza para cargar documentos PDF de manera eficiente, manejando el proceso de carga del documento sin problemas. El método load_and_split() lee el documento y lo divide en páginas individuales, lo que facilita el procesamiento posterior del texto. Eliminamos las primeras cuatro páginas usando pages = pages[4:] para excluir información irrelevante como la portada o la tabla de contenidos.
# Paso 4: Limpiar los datos
Ahora, limpiemos el texto extraído del PDF para eliminar caracteres no deseados, espacios y formato.
import re
def clean_text(text):
# Eliminar todas las nuevas líneas y reemplazar múltiples nuevas líneas con un solo espacio
text = re.sub(r'\s*\n\s*', ' ', text)
# Eliminar todos los espacios múltiples y reemplazarlos con un solo espacio
text = re.sub(r'\s+', ' ', text)
# Eliminar todos los números al comienzo de las líneas (como '1 ', '2 ', etc.)
text = re.sub(r'^\d+\s*', '', text)
# Eliminar cualquier espacio o carácter especial no deseado restante
text = re.sub(r'[^A-Za-z0-9\s,.-]', '', text)
# Eliminar los espacios iniciales y finales
text = text.strip()
return text
text = "\n".join([doc.page_content for doc in pages])
cleaned_text = clean_text(text)
La función clean_text procesa y sanea el texto. Elimina las nuevas líneas, los espacios múltiples, los números al comienzo de las líneas y cualquier carácter no deseado restante, lo que resulta en un texto limpio y estandarizado.
# Paso 5: Dividir los datos
El siguiente paso es dividir el texto en fragmentos más pequeños y manejables para su procesamiento en nuestra aplicación de IA.
from langchain.text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000, # Tamaño máximo de cada fragmento
chunk_overlap=300, # Superposición entre fragmentos
length_function=len, # Función para calcular la longitud
is_separator_regex=False,
)
docs = text_splitter.create_documents([cleaned_text])
La clase RecursiveCharacterTextSplitter divide el texto en fragmentos de un tamaño especificado con superposición para garantizar la continuidad. Esto asegura que el texto se divida en piezas manejables sin perder el contexto.
# Paso 6: Definir el modelo de incrustación
Definimos el modelo de incrustación utilizando las incrustaciones OpenAIEmbeddings para convertir los fragmentos de texto en representaciones vectoriales.
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
La clase OpenAIEmbeddings inicializa un modelo de transformador preentrenado para crear incrustaciones (representaciones vectoriales) de los fragmentos de texto, capturando el significado semántico del texto.
# Paso 7: Agregar datos al almacén de vectores de MyScale
Ahora, agreguemos los fragmentos de texto vectorizados al almacén de vectores de MyScale (opens new window) para una recuperación eficiente.
from langchain_community.vectorstores import MyScale
docsearch = MyScale.from_documents(docs, embeddings)
El método MyScale.from_documents(docs, embeddings) almacena las representaciones vectoriales de los fragmentos de texto en la base de datos vectorial de MyScale, lo que permite búsquedas de similitud eficientes.
# Paso 8: Realizar una búsqueda de similitud
Realicemos una búsqueda de similitud en los vectores almacenados para probar el funcionamiento de nuestro almacén de vectores.
output = docsearch.similarity_search("¿Cuánta gasolina reciben los empleados?", 3)
El método similarity_search busca en la base de datos vectorial los vectores similares a la consulta, recuperando las mejores coincidencias. Después de realizar la consulta, obtendrás resultados como estos:
[Document(page_content='El empleado puede optar por una contribución adicional al Fondo de Providentia a través del Fondo de Providentia Voluntario VPF. Contribución del empleador: 12 del salario básico del empleado. 9.2Gratificación: La gratificación se pagará de acuerdo con la Ley de Gratificación de 1972 a todos los empleados elegibles de Adino Telecom Ltd. El empleador pagará la gratificación al empleado elegible por cada año completo de servicio continuo de más de 5 años a razón de 15 días de salario por cada año completo de servicio. La tasa de salario será la tasa de salario devengado por último. 9.3Mediclaim: Todos los empleados elegibles estarán cubiertos por la póliza médica de Star Healthc laim para el empleado, el cónyuge y el hijo hasta Rs.1 lakh. 9.4ESIC: Todos los empleados elegibles están cubiertos de acuerdo con la Ley ESI de 1948. Todos los empleados que ganen un salario mensual de hasta Rs. 10,000 por mes están cubiertos por el régimen ESI. Contribución de los empleados: a razón de 1.75 del salario. Contribución del empleador: a razón de 4.75 del salario.', metadata={'_dummy': 0}),
Document(page_content='ALLOTED PER MONTHin Rs M5 M4 1500 M3 M2 1250 M1 M0 800 O1 O2 420 A1, A2 A3 300 Tenga en cuenta que no se dará ninguna aprobación especial, excepto a los Gerentes de Negocios que deben realizar llamadas internacionales. Tenga en cuenta que los valores anteriores están sujetos a cambios 437.3Reembolso de transporte: Hasta el nivel DM Máximo de Rs. 1875 al mes para reclamar los gastos reales Nivel de gerente Máximo de Rs. 2,200 al mes para reclamar los gastos reales Nivel de Sr. Gerente Nivel de DGM Máximo de Rs. 2,575 al mes para reclamar los gastos reales GM con automóvil Máximo de Rs. 6 000 por mes para reclamar actua l. Mantenimiento del automóvil máximo de Rs. 2,000 por mes y Rs. 8000 por año. Los gastos de transporte deben mantenerse en los niveles anteriores y no se permitirá ningún reembolso más allá de la cantidad mencionada. En caso de encuesta remunerada, el transporte será de Rs. 5 ,000 al mes. Tenga en cuenta que los valores anteriores están sujetos a cambios 447.4Cargos de Internet: Se aplicarán Rs. 300 al mes por cargos de Internet solo para el nivel M5. 7.5Política de capacitación', metadata={'_dummy': 0}),
Document(page_content='se desembolsará al finalizar cada año durante Diwali. 4.Incentivo de rendimiento: Los empleados tienen derecho a recibir incentivos de rendimiento basados en su desempeño a lo largo del año. El incentivo se desembolsa una vez al año. 5.Médico: Los empleados elegibles están cubiertos por el Plan de Seguro de Salud de Star Health. 6.Todos los empleados que estén sujetos al impuesto sobre la renta deben presentar sus planes de inversión antes de septiembre de cada año fiscal. 7.Todos los comprobantes de los planes de inversión deben presentarse antes de finales de enero. 499.Beneficios 509.1Fondo de Providentia: Todos los empleados están cubiertos de acuerdo con la Ley del Fondo de Providentia de 1952, según la cual la contribución de los empleados es del 12 del salario básico. El empleado puede optar por una contribución adicional al Fondo de Providentia a través del Fondo de Providentia Voluntario VPF. Contribución del empleador: 12 del salario básico del empleado. 9.2Gratificación: La gratificación se pagará de acuerdo con la Ley de Gratificación de 1972 a todos los empleados elegibles de Adino Telecom', metadata={'_dummy': 0})]
# Paso 9: Configurar el recuperador
Ahora, convirtamos este almacén de vectores de un motor de búsqueda de documentos a un recuperador. Será utilizado por la cadena LLM para obtener información relevante.
retriever = docsearch.as_retriever()
El método as_retriever convierte el almacén de vectores en un objeto recuperador que obtiene documentos relevantes en función de su similitud con la consulta.
# Paso 10: Definir el LLM y la cadena
El último paso es definir el LLM (ChatGPT) y configurar una cadena de preguntas y respuestas basada en la recuperación.
from langchain_openai import OpenAI
from langchain.chains import RetrievalQA
llm = OpenAI()
qa = RetrievalQA.from_chain_type(
llm=llm,
retriever=retriever,
verbose=False,
)
La clase OpenAI inicializa el modelo ChatGPT, mientras que RetrievalQA.from_chain_type configura una cadena de preguntas y respuestas que utiliza el recuperador para obtener documentos relevantes y el modelo de lenguaje para generar respuestas.
# Paso 11: Consultar la cadena
Consultamos la cadena de preguntas y respuestas para obtener respuestas del asistente de recursos humanos de IA.
# Consultar la cadena
respuesta1 = qa.run("¿Cuánto es la asignación de transporte?")
print(respuesta1)
El método qa.run(query) envía una consulta a la cadena de preguntas y respuestas, que recupera documentos relevantes y genera una respuesta utilizando ChatGPT. Luego, se imprimen las respuestas a las consultas.
Al realizar la consulta, obtendrás una respuesta como esta:
"La asignación de transporte varía según el grado y nivel del empleado, oscilando entre Rs. 1,875 por mes para los empleados de nivel DM y un máximo de Rs. 6,000 por mes para los empleados de nivel GM con automóvil. Los montos están sujetos a cambios."
Hagamos otra consulta:
respuesta2 = qa.run("¿Cuál es el horario de trabajo de la oficina?")
print(respuesta2)
Esta consulta devolverá resultados similares a estos:
'El horario de trabajo de la oficina es de 9:00 am a 5:45 pm o de 9:30 am a 6:15 pm, con la posibilidad de que ciertos empleados tengan horarios o turnos diferentes.'
Así es como podemos mejorar el rendimiento de ChatGPT al integrarlo con bases de datos vectoriales. Al hacerlo, nos aseguramos de que el modelo pueda acceder a información actualizada y específica del dominio, lo que conduce a respuestas más precisas y relevantes.

# Por qué elegir MyScale como base de datos vectorial
MyScale se destaca como una base de datos vectorial debido a su compatibilidad total con SQL (opens new window), lo que simplifica las operaciones de datos complejas y las búsquedas semánticas. Los desarrolladores pueden utilizar consultas SQL familiares para manejar vectores, evitando la necesidad de aprender nuevas herramientas. Los algoritmos avanzados de indexación de vectores y la arquitectura OLAP de MyScale garantizan un alto rendimiento y escalabilidad, lo que la hace adecuada para administrar datos de aplicaciones de IA a gran escala de manera eficiente.
La seguridad y la facilidad de integración son fortalezas adicionales de MyScale. Se ejecuta en una infraestructura segura de AWS, ofreciendo características como cifrado y controles de acceso para proteger los datos. MyScale también admite herramientas de monitoreo exhaustivas (opens new window), que brindan información en tiempo real sobre el rendimiento y la seguridad de las aplicaciones LLM. Como plataforma de código abierto, MyScale fomenta la innovación y la personalización, lo que la convierte en una opción versátil para diversos proyectos de IA.
# Conclusión
Combinar LLMs como ChatGPT con bases de datos vectoriales permite a los desarrolladores construir aplicaciones potentes sin tener que volver a entrenar modelos con nuevos datos. Esta configuración permite que ChatGPT acceda a información específica y actualizada en tiempo real, lo que hace que sus respuestas sean más precisas y relevantes.
Las bases de datos vectoriales desempeñan un papel clave en la mejora de la calidad de respuesta y el rendimiento de los LLMs. Aseguran que los modelos tengan acceso a los datos más recientes y relevantes. MyScale se destaca en esta área, proporcionando soluciones eficientes y escalables que facilitan la integración. MyScale también ha superado a las bases de datos vectoriales especializadas (opens new window) en términos de velocidad y rendimiento. Además, los nuevos usuarios pueden acceder a 5 millones de almacenamiento de vectores gratuitos en su entorno de desarrollo, lo que les permite probar las características de MyScale y experimentar los beneficios de primera mano.
Si deseas discutir más con nosotros, te invitamos a unirte a Discord de MyScale (opens new window) para compartir tus ideas y comentarios.



