
# Acerca de Cowarobot

Fundada en 2015, Cowarobot es una empresa especializada en proporcionar soluciones integrales para la conducción autónoma en entornos urbanos complejos. A mediados de 2022, tenían presencia en más de 10 ciudades en China y una flota de más de 1,000 vehículos autónomos. También han colaborado con fabricantes de automóviles chinos como Cherry, BAIC, Shaanxi Automobile y Zoomlion para desarrollar soluciones de entrega y transporte logístico urbano en estas ciudades.
# Antes de usar MyScale
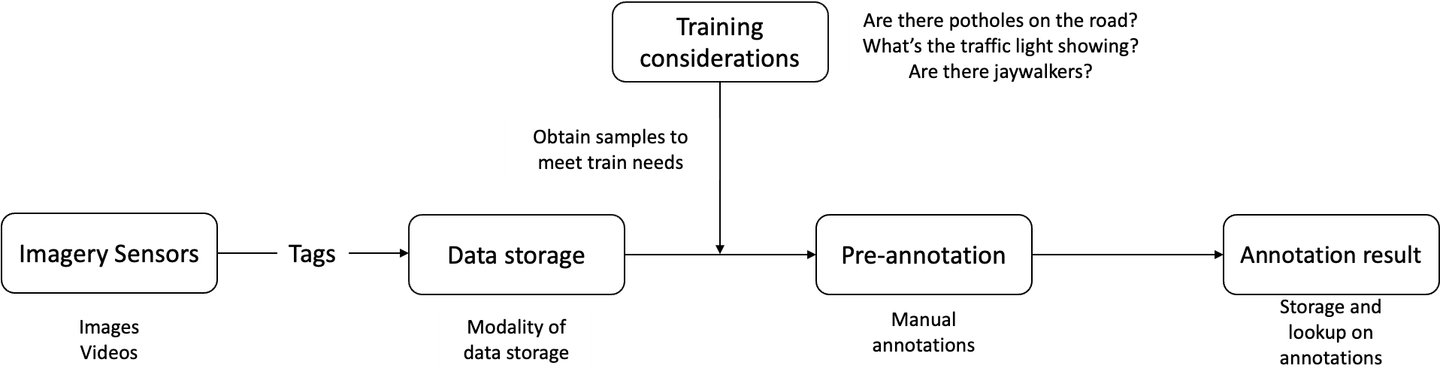
El flujo de trabajo principal de Cowarobot para entrenar su flota de conducción autónoma se divide en cinco secciones:
- Almacenamiento de datos y etiquetas en un almacenamiento centralizado
Cowarobot se especializa en recopilar y procesar datos de video y datos espaciales en bruto que son cruciales para los vehículos autónomos, como información dinámica sobre vehículos cercanos, obstáculos y señales de tráfico, además de datos tradicionales como superficies de carreteras, pavimentos, mapas y límites de velocidad. Los datos se etiquetan y se organizan en carpetas con varios niveles, que luego se guardan en unidades locales. Sin embargo, Cowarobot enfrenta un desafío significativo en cuanto al almacenamiento de datos debido a la gran cantidad de datos producidos. La empresa se enfrenta al desafío de adquirir y mantener un gran número de discos duros para almacenar datos de manera centralizada y sostenible. Además, se requiere un mínimo de un millón de muestras de datos para lograr un reconocimiento de objetos en tiempo real preciso, segmentación y detección de etiquetas.
- Ejecución de tareas de entrenamiento
Cowarobot utiliza los datos en bruto recopilados para entrenar sus modelos, permitiendo que sus vehículos autónomos naveguen desde el punto A al punto B, mantengan una velocidad segura en relación con otros autos, eviten obstáculos y obedezcan las señales de tráfico. Para asegurarse de que los vehículos puedan manejar las condiciones cambiantes de la carretera, los datos de entrenamiento deben actualizarse constantemente. Por ejemplo, si se cambian las marcas viales, las etiquetas de datos anteriores deben reescribirse para reflejar los cambios. De manera similar, si el vehículo se encuentra con situaciones nuevas o inesperadas, como peatones cruzando la calle o un oficial de policía indicándole que se detenga, debe estar entrenado para responder adecuadamente. Estas actualizaciones requieren que Cowarobot adquiera y etiquete repetidamente nuevos datos, así como vuelva a etiquetar los datos existentes, lo que conlleva costos de entrenamiento sustanciales. Estos costos y actualizaciones frecuentes limitan los tipos, la frecuencia y la calidad de las tareas de entrenamiento que Cowarobot puede completar.
- Obtención de nuevas muestras
Cowarobot carece de medios para acceder y recuperar fácilmente las etiquetas que han asignado previamente a sus datos, y no puede recuperar las etiquetas anteriores. Esta limitación significa que la empresa solo puede admitir tareas de entrenamiento de modelos con sus datos existentes. Cowarobot debe exportar manualmente todos los datos de sus unidades locales para poder utilizarlos, lo que es un proceso que consume mucho tiempo. Además, los datos existentes son insuficientes para admitir el entrenamiento de los modelos de Cowarobot, por lo que la empresa debe continuar recopilando nuevos datos y generando muestras de entrenamiento. Sin embargo, el flujo de trabajo actual requiere que Cowarobot exporte manualmente todos los datos de las unidades locales después de cada actualización, lo que es un proceso tedioso y que consume mucho tiempo.
- Etiquetas de datos
La naturaleza manual del proceso de etiquetado actual de Cowarobot dificulta la eficiencia en la generación de conjuntos de datos para actualizar sus modelos e implementar nuevas actualizaciones en su flota autónoma. Este procedimiento laborioso y que consume mucho tiempo dificulta la capacidad de la empresa para mantener sus modelos actualizados con los datos más recientes.
- Entrenamiento de modelos
Actualmente, para el entrenamiento de modelos, Cowarobot utiliza una arquitectura distribuida en la que se utilizan múltiples supercomputadoras para aprovechar su potencia de cálculo en varias etapas del proceso de entrenamiento. Esta estrategia es más económica que utilizar una sola supercomputadora más potente. Sin embargo, una desventaja de este método es que las muestras de entrenamiento deben transmitirse entre computadoras, ya sea a través de la red o sin conexión, lo que puede ser engorroso y llevar mucho tiempo.
Además, la salida de los modelos entrenados se subutiliza. Las tareas de entrenamiento completadas permitirían a Cowarobot utilizar estos modelos directamente en línea, pero los datos almacenados fuera de las muestras de entrenamiento del modelo no se han actualizado para reflejar el nuevo modelo.
# Adoptar MyScale como solución de almacenamiento de datos para sus vehículos autónomos
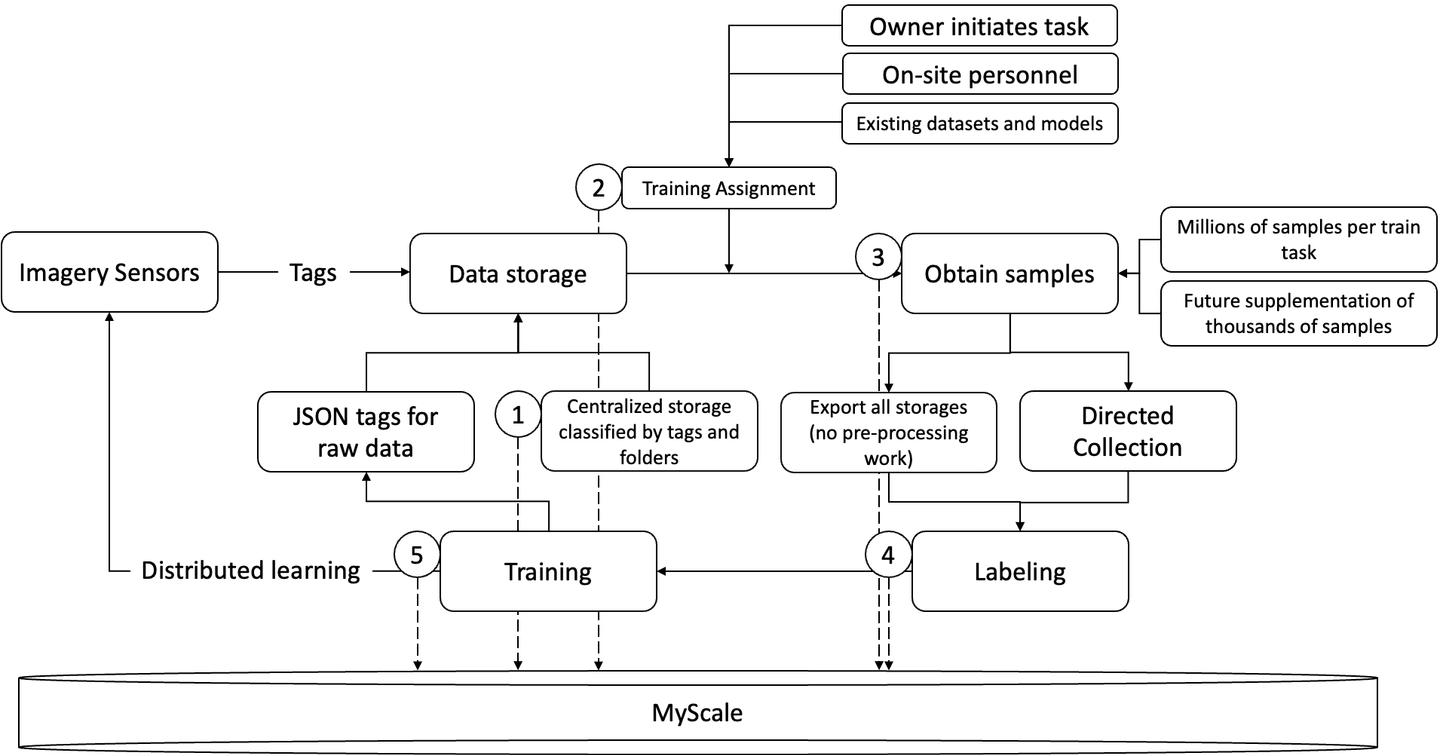
Cowarobot ha utilizado MyScale para mejorar los flujos de trabajo de entrenamiento de modelos para sus vehículos autónomos, en áreas que van desde el almacenamiento hasta las etiquetas de datos y el entrenamiento de modelos.
- Almacenamiento de datos y etiquetas en un almacenamiento centralizado
MyScale ofrece un almacenamiento unificado para consultas y gestión de datos, con tipos de datos que incluyen ID, datos vectoriales, datos de etiquetas, URL, y más, lo que facilita la gestión y el uso de conjuntos de datos para diversos fines. Esto permite que diferentes departamentos dentro de una empresa realicen un mejor seguimiento de sus procesos de aprendizaje automático, mejoren el uso de sus datos y amplíen el alcance de sus tareas de entrenamiento.
- Ejecución de tareas de entrenamiento
MyScale admite la generación rápida de muestras de entrenamiento a partir de datos almacenados al permitir a los usuarios realizar consultas SQL conjuntas (filtrado de atributos). Como resultado, las nuevas tareas de entrenamiento pueden requerir un tamaño de muestra más pequeño o incluso no requerir la adquisición de nuevos datos en absoluto. Esto reduce los costos de entrenamiento y permite a los usuarios aumentar la frecuencia y los tipos de tareas de entrenamiento con conjuntos de datos más pequeños.
- Obtención de nuevas muestras
La ventaja clave de MyScale es que solo requiere un pequeño número de muestras de datos. Con menos muestras requeridas, se reduce la carga de trabajo para obtener nuevas muestras necesarias para entrenar el modelo. MyScale logra esto al permitir que los usuarios ejecuten consultas SQL conjuntas para generar rápidamente muestras de entrenamiento a partir de datos almacenados. Esto también es útil si hay una base de datos existente con un gran número de muestras, ya que MyScale puede filtrar las muestras de entrenamiento y buscar muestras de entrenamiento de mayor calidad. Esto aumenta la precisión de las muestras positivas en los datos etiquetados.
- Etiquetas de datos
MyScale requiere una pequeña muestra de datos que ya han sido etiquetados para iniciar el proceso de entrenamiento del modelo. El etiquetado de datos lleva menos tiempo y cuesta menos dinero cuando hay menos muestras de datos que deben cambiarse manualmente.
- Entrenamiento de modelos
MyScale puede gestionar los datos de entrenamiento y proporcionar soporte completo de SQL. MyScale permite a los usuarios escribir declaraciones SQL simples para crear directamente muestras de entrenamiento. El entrenamiento del modelo puede llamar directamente a los datos originales para iniciar el proceso de entrenamiento del modelo. Esto simplifica en gran medida las tareas de entrenamiento del modelo y la forma en que se transmite los datos desde diversas fuentes.

# Cómo MyScale puede ayudarlo a desbloquear nuevo valor comercial a partir de sus datos de video

MyScale trabajó con la empresa de robótica Cowarobot para gestionar su proceso de aprendizaje automático que incluye la recopilación, almacenamiento, adquisición de datos, etiquetado y entrenamiento de modelos para su flota autónoma. Se gestionan una variedad de fuentes de datos, incluidos datos vectoriales y anotaciones de datos, en una plataforma unificada. La plataforma MyScale también ofrece soporte completo de SQL, lo que simplifica el entrenamiento de modelos al requerir solo un lenguaje de consulta.
MyScale también proporciona capacidades de búsqueda para localizar rápidamente muestras de entrenamiento a partir de datos almacenados. Esto reduce el costo de entrenamiento de modelos y mejora la frecuencia y la forma en que se entrenan. Cowarobot utilizó MyScale y el aprendizaje de pocos ejemplos para realizar la selección de datos de entrenamiento, la clasificación de datos y el etiquetado de datos. Esta estrategia redujo la cantidad de anotaciones de datos y la recopilación de datos requerida.
Si su empresa también trabaja con imágenes y videos en su aplicación actual y desea explorar más sobre cómo MyScale puede ayudar a extraer más valor de sus aplicaciones y negocios, no dude en ponerse en contacto con nosotros en contact@myscale.com.



