
Nota:
Actualizamos continuamente los resultados de referencia para MyScale y otros productos de bases de datos vectoriales en nuestro proyecto de código abierto, vector-db-benchmark (opens new window).
Se asume ampliamente que las bases de datos relacionales no pueden competir con el rendimiento de las bases de datos vectoriales especializadas. Por ejemplo, PostgreSQL con extensiones vectoriales tiene una desventaja significativa en rendimiento en comparación con bases de datos vectoriales especializadas como Pinecone. Es por eso que hoy en día hay tantas bases de datos vectoriales especializadas disponibles. Las personas prefieren las bases de datos relacionales por diversas razones, como la preparación para la producción, un conjunto de funciones robusto, soporte y comunidad, integración, seguridad y, por supuesto, SQL, el lenguaje familiar y potente para comunicarse con los datos. En las bases de datos vectoriales especializadas, todas estas características se ven comprometidas en cierta medida.
¿Qué pasaría si tuviéramos una base de datos relacional que pudiera competir con, o incluso superar a las bases de datos vectoriales especializadas?
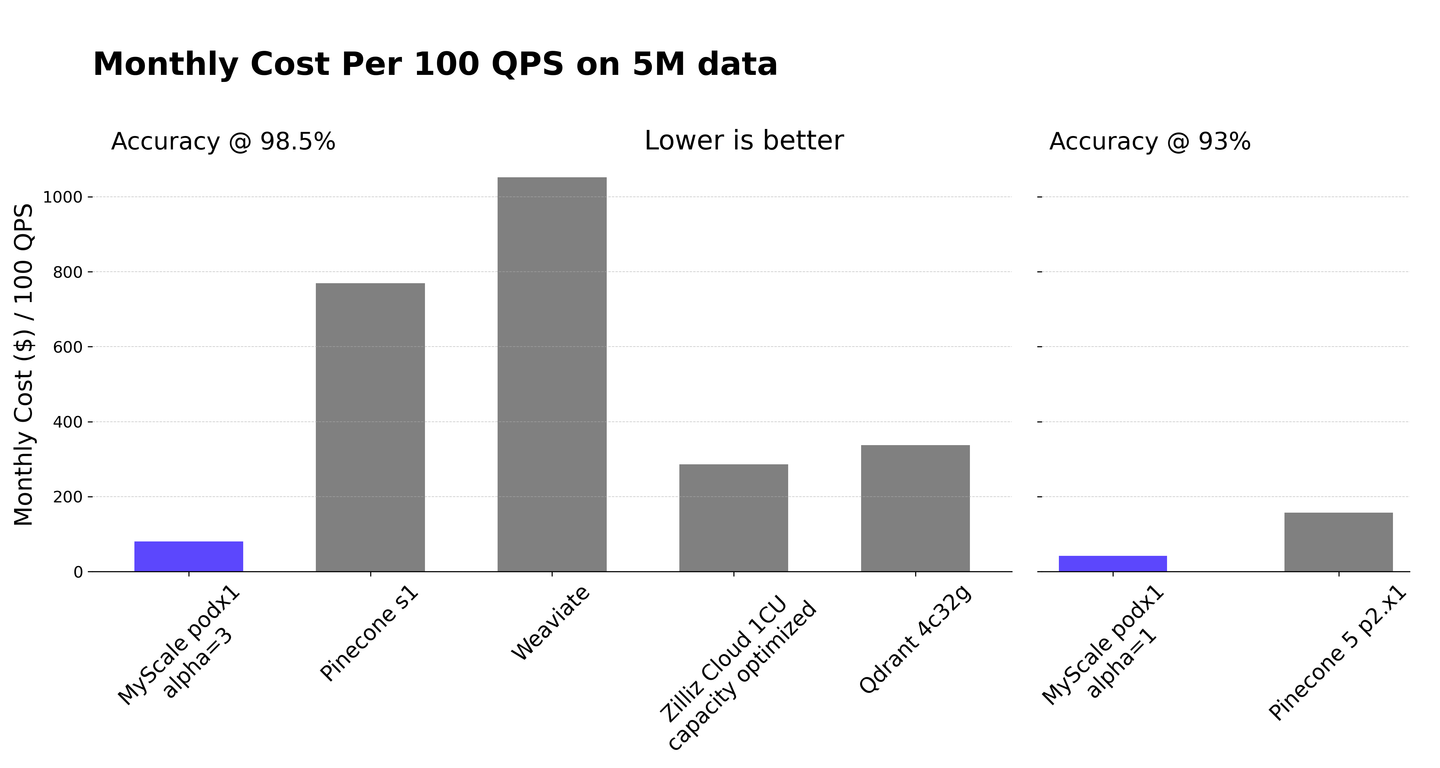
Nos complace anunciar una actualización significativa de MyScale que logra exactamente esto. Por primera vez, una base de datos relacional puede superar a las bases de datos vectoriales especializadas más avanzadas en términos de rendimiento vectorial, al tiempo que conserva todos los beneficios de las bases de datos relacionales y SQL. En una comparación directa con Pinecone, una base de datos vectorial especializada líder, MyScale supera en rendimiento en 10 veces a la s1 de Pinecone en velocidad de consulta, y en 5 veces a la p2 de Pinecone en densidad de datos. Cuando se considera la relación costo-efectividad, MyScale es 3.6 veces más rentable que otras bases de datos vectoriales especializadas de alto rendimiento en varios niveles de precisión. Esto se ilustra en la siguiente figura. Si bien Pinecone es una base de datos líder, la comparación de la relación costo-efectividad en este contexto se realiza con una variedad de las mejores bases de datos vectoriales especializadas, no solo Pinecone.
Esto se logra mediante la integración perfecta de datos estructurados y vectores con una serie de innovaciones que involucran tanto algoritmos como ingeniería de sistemas:
- Innovaciones en algoritmos. En el núcleo de las bases de datos vectoriales se encuentran los algoritmos de búsqueda del vecino más cercano. A diferencia de la mayoría de las bases de datos vectoriales, que se basan en el mismo conjunto de algoritmos, como IVF y HNSW o sus variantes, y por lo tanto tienen límites de rendimiento similares. MyScale implementa un algoritmo propietario llamado MSTG (Multi-Scale Tree Graph) que supera a IVF y HNSW, a veces en 10 veces o más.
- Ingeniería de sistemas. MyScale se basa en ClickHouse. Nos encanta ClickHouse por su alto rendimiento y su amplio conjunto de funciones. Sin embargo, viene con algunos problemas conocidos y sobrecargas del sistema. Hicimos numerosas mejoras y correcciones de errores en el sistema para hacer que los vectores funcionen con ClickHouse (algunas se han contribuido de vuelta a la comunidad de ClickHouse, como las eliminaciones ligeras).
Las mejoras de rendimiento, que ahora están disponibles a través de MyScale, permiten a los usuarios crear aplicaciones de IA aún más potentes. MyScale incluye las siguientes características clave:
- Alta capacidad y rendimiento de datos: En MyScale, un solo pod estándar admite 5 millones de puntos de datos de 768 dimensiones con alta precisión, logrando más de 150 consultas por segundo (QPS).
- Ingesta rápida de datos: Ingesta de 5 millones de puntos de datos en menos de 30 minutos, minimizando el tiempo de espera y permitiéndole servir sus datos vectoriales más rápido.
- Soporte para múltiples índices: Puede crear múltiples tablas con índices vectoriales únicos en cada pod de MyScale (consulte Referencia de vectores (opens new window)). Al aprovechar esta función con alta capacidad de datos, puede administrar eficientemente datos vectoriales heterogéneos en un solo clúster de MyScale, reduciendo aún más la complejidad y el costo del sistema.
- Importación y respaldo de datos sencillos: Con soporte para formatos estándar como Parquet o archivos tar comprimidos, puede importar/exportar datos desde/hacia S3 (opens new window) u otros sistemas de almacenamiento de objetos compatibles utilizando un solo comando SQL.
MyScale está actualmente en versión beta, con un nivel gratuito para desarrolladores y un plan comercial en camino. Hasta donde sabemos, MyScale ofrece el primer plan gratuito que admite 5 millones de puntos de datos vectoriales de 768 dimensiones con búsqueda de alto rendimiento.
# Comparación de rendimiento de MyScale con los principales servicios de bases de datos vectoriales
En este artículo, realizamos una comparación exhaustiva de rendimiento de MyScale con otros servicios de bases de datos vectoriales ampliamente utilizados. El código y los resultados de las pruebas de referencia están disponibles públicamente aquí (opens new window), y los actualizaremos de forma regular. Este artículo contiene un resumen conciso de los hallazgos clave.
Los servicios elegidos para este ejercicio de referencia incluyen líderes de la industria como Pinecone, Qdrant, Weaviate y Zilliz Cloud. Evaluamos estos servicios en tres parámetros clave: tiempo de ingestión de datos, QPS de búsqueda (consultas por segundo) y latencia promedio. El conjunto de datos utilizado para las pruebas consta de 5 millones de vectores de 768 dimensiones, generados a partir de las imágenes LAION 2B (opens new window). Este conjunto de datos también es accesible (opens new window) públicamente.
Nuestro enfoque principal durante este ejercicio de referencia fue en servicios con alta capacidad. Por lo tanto, cuando un servicio proporcionaba múltiples configuraciones de pod, elegimos la que tenía la mayor densidad de datos. Ejemplos incluyen el pod s1 de Pinecone y el 1CU optimizado para capacidad de Zilliz Cloud, que proporcionan una capacidad de datos de 5 millones de vectores. Además, servicios como MyScale, Weaviate y Zilliz Cloud ofrecen varias opciones de ajuste para equilibrar la velocidad de búsqueda y la precisión. En el caso de MyScale, seleccionamos una configuración con alpha=3 que proporcionaba una tasa de recuperación de los 10 mejores del 98.5%, y la comparamos con otros servicios con niveles similares de precisión. Todas las pruebas se realizaron utilizando cuatro conexiones de cliente en paralelo.
# Relación costo-rendimiento
Un componente esencial de este estudio de referencia es la evaluación de la relación costo-rendimiento, que mide la relación entre el costo mensual y el QPS (consultas por segundo) del servicio por cada cien unidades. Cuantifica el costo mensual necesario para lograr 100 QPS en 5 millones de puntos de datos vectoriales. Nuestro análisis destaca la relación costo-rendimiento superior de MyScale, que es más de 3.6 veces más barato que otras bases de datos vectoriales. A pesar de su alta densidad de datos, el pod s1 de Pinecone se ve obstaculizado por su menor QPS, lo que resulta en una relación costo-rendimiento menos favorable. La rentabilidad de Weaviate se ve limitada por su estructura de precios, que escala la cantidad de consultas. Incluso a una tasa de consulta mínima de una por mes, el costo base se mantiene en $192/mes, y con un QPS promedio de 5, el costo aumenta a $690/mes, que se utilizó en la figura anterior para calcular la eficiencia de costos. A pesar de su capacidad de almacenamiento de datos sustancial, Zilliz Cloud tiene un QPS más bajo, lo que afecta negativamente su relación costo-rendimiento. Qdrant cloud requiere 32 GB de memoria para administrar eficientemente 5 millones de puntos de datos, lo que resulta en costos más altos. A pesar de investigar numerosos parámetros de ajuste de HNSW y establecer m=32 ef_c=256 para un rendimiento óptimo, la tasa de consultas por segundo (QPS) es insuficiente para una relación costo-rendimiento satisfactoria.
Para realizar una comparación exhaustiva, también examinamos el pod p2 de Pinecone. Cada pod p2 admite 1 millón de datos de 768 dimensiones, y seleccionamos la configuración de escalado 5 p2.x1 para acomodar los datos minimizando los costos. El pod p2 de Pinecone tiene una tasa de recuperación de los 10 mejores de aproximadamente el 93%, que es menor que el rendimiento de otros servicios de bases de datos vectoriales pero comparable al rendimiento de la configuración alpha=1 de MyScale. Por lo tanto, incluimos una comparación separada para el pod p2 de Pinecone en el gráfico derecho. En este caso, MyScale resulta ser 3.7 veces más rentable que 5 p2.x1. El resto del artículo se enfoca principalmente en la configuración de alta precisión, que es consistente con el estándar predominante entre los servicios de bases de datos vectoriales.
Aquí hay un resumen de los servicios probados en este artículo, consulte la figura anterior para la relación costo-rendimiento de cada servicio.
| Precisión | Servicio | QPS | Costo Mensual ($) | Comentario |
|---|---|---|---|---|
| 98.5% | Pod estándar de MyScale (alpha=3) | 150 | 120 | Versión beta con prueba gratuita, nivel estándar próximamente |
| Pinecone s1 | 9 | 69 | Precio base de GCP | |
| Weaviate | 66 | 690 | Total de consultas mensuales calculadas como 5 * 3600 * 24 * 30 | |
| Zilliz Cloud 1CU Capacity Optimized | 63 | 186 | - | |
| Qdrant 4c32g | 81 | 273 | HNSW m=32 ef_c=256 | |
| 93% | Pod estándar de MyScale (alpha=1) | 288 | 120 | - |
| Pinecone 5 p2.x1 | 331 | 518 | Escalado horizontal de 5 pods p2 |
Examinemos algunas métricas de rendimiento más específicas, como QPS, latencia promedio de consulta y tiempo de ingestión de datos.
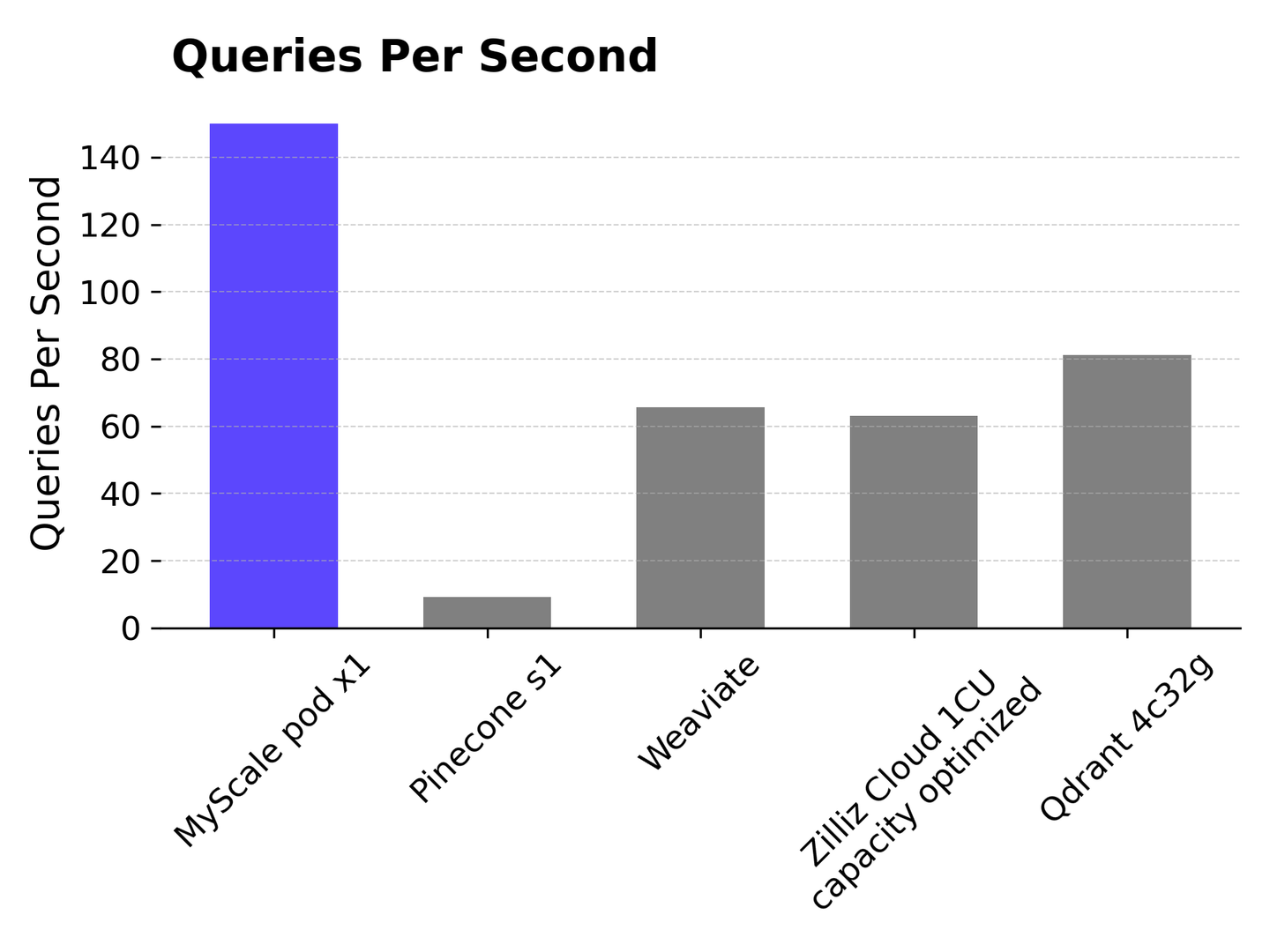
# Consultas por segundo (QPS)
MyScale supera a otras bases de datos vectoriales en términos de QPS en el conjunto de datos LAION 5M con una tasa de recuperación de los 10 mejores del 98.5%, logrando más de 150 QPS. En comparación, Pinecone s1 tiene un QPS de aproximadamente 10, que es significativamente menor que el de MyScale. Weaviate y Zilliz Cloud logran alrededor de 65 QPS, mientras que Qdrant logra 81 QPS.
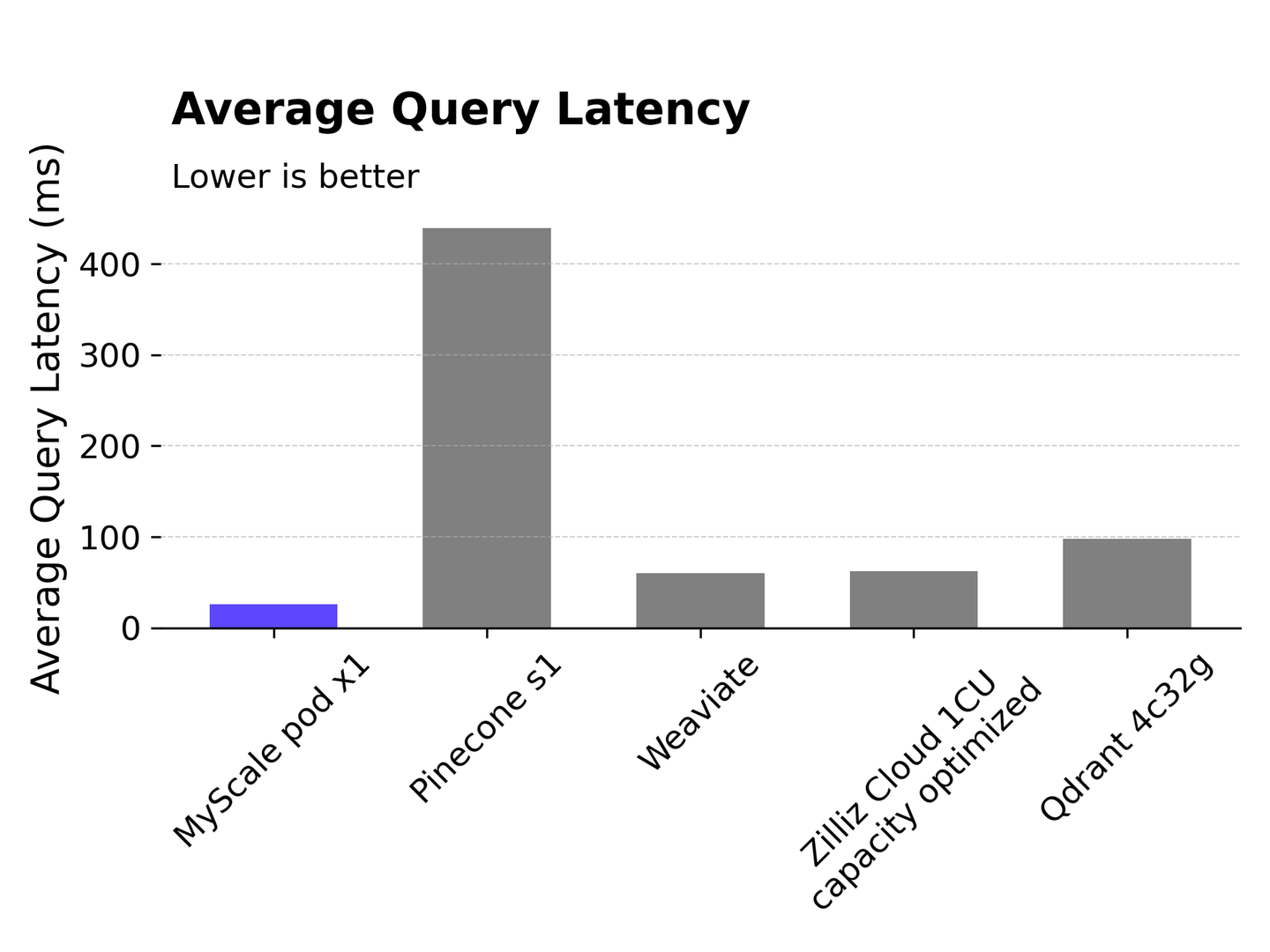
# Latencia promedio de consulta
La latencia de consulta es una métrica de rendimiento importante que se mide desde el momento en que el cliente envía la solicitud hasta que recibe la respuesta. MyScale logra 150 QPS manteniendo una latencia promedio tan baja como 25.8 ms. Pinecone s1 tiene una latencia relativamente alta de más de 400 ms. Weaviate y Zilliz Cloud tienen latencias de alrededor de 60 ms, mientras que Qdrant tiene una latencia ligeramente mayor de alrededor de 100 ms.
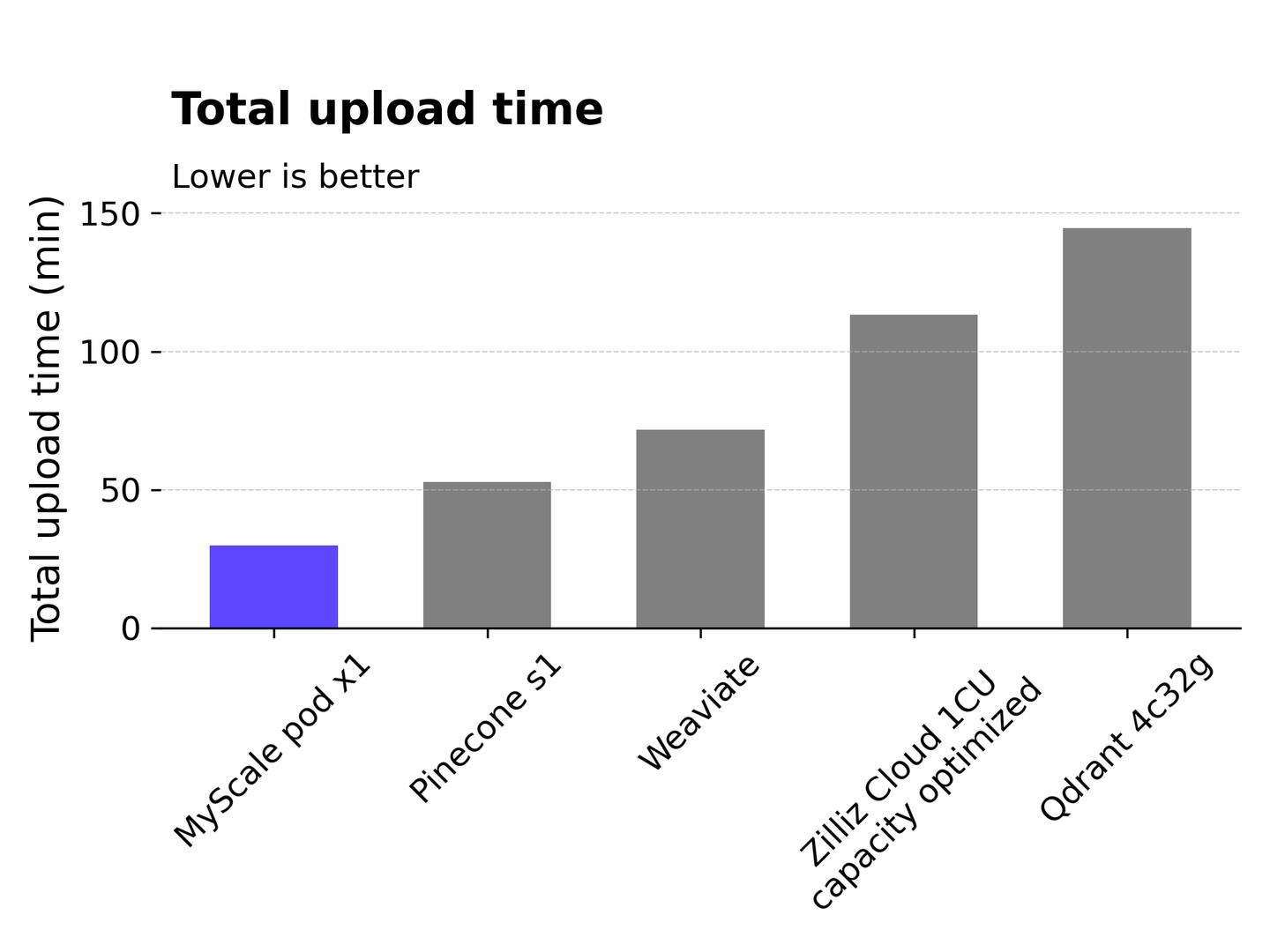
# Tiempo de ingestión de datos
El tiempo que lleva desde la carga de datos hasta que el índice vectorial se construye y está listo para servir se denomina tiempo de ingestión de datos. La creación del índice puede llevar mucho tiempo, especialmente para algoritmos basados en gráficos como HNSW. Entre todos los servicios probados, MyScale tuvo el tiempo de ingestión más rápido para 5 millones de puntos de datos, completando la tarea en aproximadamente 30 minutos. Pinecone s1 tarda aproximadamente 53 minutos, mientras que Weaviate tarda 72 minutos. Zilliz Cloud requiere una duración más larga de aproximadamente 113 minutos, mientras que Qdrant tiene el tiempo de ingestión más largo, tardando 145 minutos en procesar 5 millones de puntos de datos.

# Conclusión
En conclusión, MyScale, que se basa en ClickHouse, demuestra que es posible superar a las bases de datos vectoriales especializadas al lograr una eficiencia de costos 3.6 veces mayor, al tiempo que conserva todos los beneficios de las bases de datos relacionales y SQL. Y esto es solo el comienzo.
MyScale se ha lanzado oficialmente con un nivel gratuito para desarrolladores. El plan comercial ofrece características adicionales, incluyendo mayor capacidad de datos, así como replicación múltiple y disponibilidad en múltiples zonas. Para obtener más información, contáctenos en contact@myscale.com o únase a nuestro Discord (opens new window).



