
En el pasado, he estado utilizando ClickHouse (opens new window) para diferentes proyectos de almacenamiento de datos y análisis de datos. Pero después del auge de la IA generativa y los vectores de incrustación, estaba buscando una base de datos para utilizar con tecnologías de vanguardia. Había tantas bases de datos vectoriales como Pinecone (opens new window), Weaviate (opens new window) y Milvus (opens new window), pero todas estas bases de datos vectoriales estaban especializadas solo en vectores y requerían mucho tiempo para comprender a fondo los fundamentos y acostumbrarse a la sintaxis.
MyScale (opens new window) no es tan popular como esas bases de datos vectoriales que mencioné anteriormente y que figuran al final de la Matriz de características de bases de datos vectoriales (opens new window). Lo exploré más a fondo y descubrí que tenía todas las funcionalidades que necesitaba con una documentación muy sencilla. Está construido sobre ClickHouse y puede almacenar vectores para aplicaciones de IA generativa y datos tabulares para aplicaciones SQL normales. Mi experiencia previa con ClickHouse y SQL me ayudó a acostumbrarme rápidamente a los fundamentos y lo he estado utilizando durante los últimos 4 meses.
# MyScale vs ClickHouse
He intentado comparar ambos de una manera muy sencilla para que puedas tener una idea clara sobre estas dos bases de datos.
| Característica | ClickHouse | MyScale |
|---|---|---|
| Tecnología base | Sistema de gestión de bases de datos de código abierto orientado a columnas | Base de datos vectorial SQL basada en la nube construida sobre ClickHouse |
| Uso principal | Procesamiento de consultas SQL en tiempo real para OLAP | Aplicaciones de IA, combinando búsqueda de similitud de vectores con SQL |
| Método de almacenamiento de datos | Almacenamiento columnar para consultas eficientes | Almacenamiento columnar, manejo de vectores y datos estructurados |
| Manipulación de tipos de datos | Datos estructurados | Tanto datos estructurados como vectores |
| Lenguaje de consulta | SQL | Soporte completo de SQL, incluyendo consultas en lenguaje natural |
| Características clave | Informes analíticos en tiempo real, eficiencia en consultas específicas | Integración de IA, precisión, rendimiento y eficiencia en costos |
| Casos de uso | Escenarios OLAP tradicionales | Aplicaciones avanzadas de IA y aprendizaje automático |
Espero que hayas entendido las diferencias y por qué elegí ir con MyScale. Ahora exploremos una función interesante y útil que agregaron hace unos días.
# Explorando el playground de MyScale
Cuando pasé de ClickHouse a MyScale, había algunas cosas en las que pensé que MyScale necesitaba trabajar, y una de ellas era un entorno de pruebas para escribir consultas y ver los resultados sin registrarse. MyScale gradualmente hizo muchas mejoras en su infraestructura y ha incorporado la mayoría de las características que deseaba, pero aún faltaba un playground.
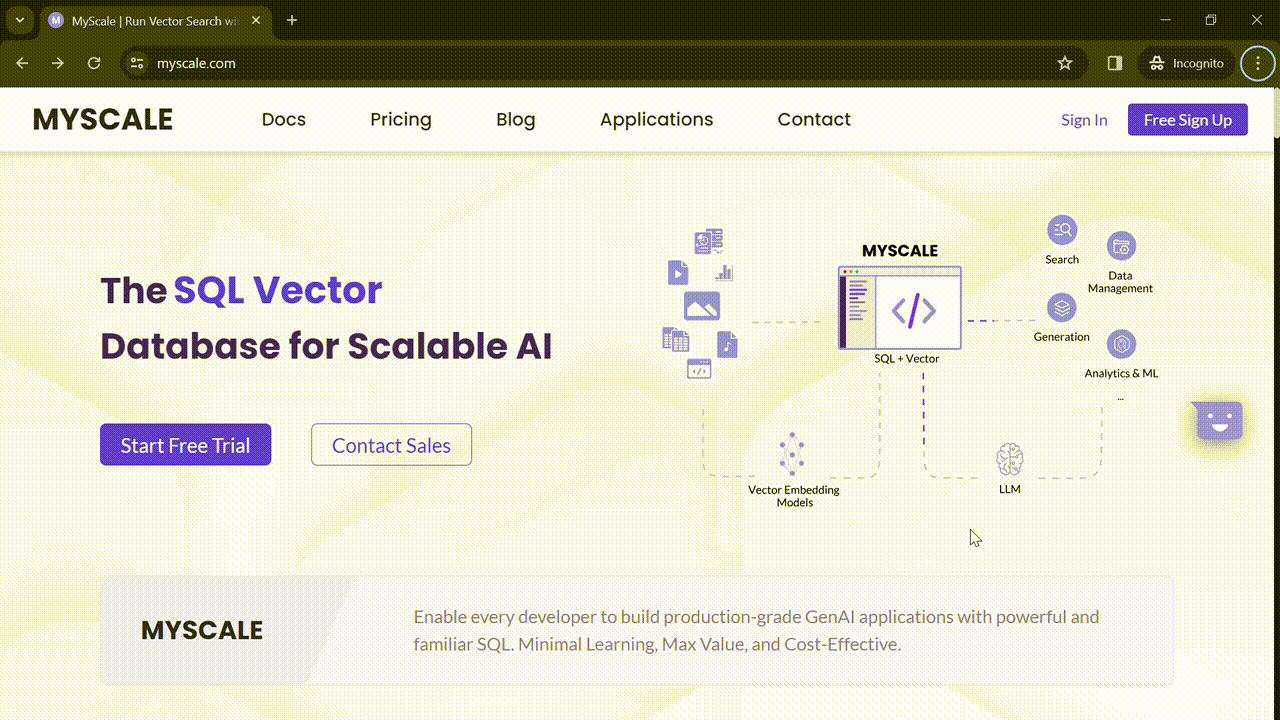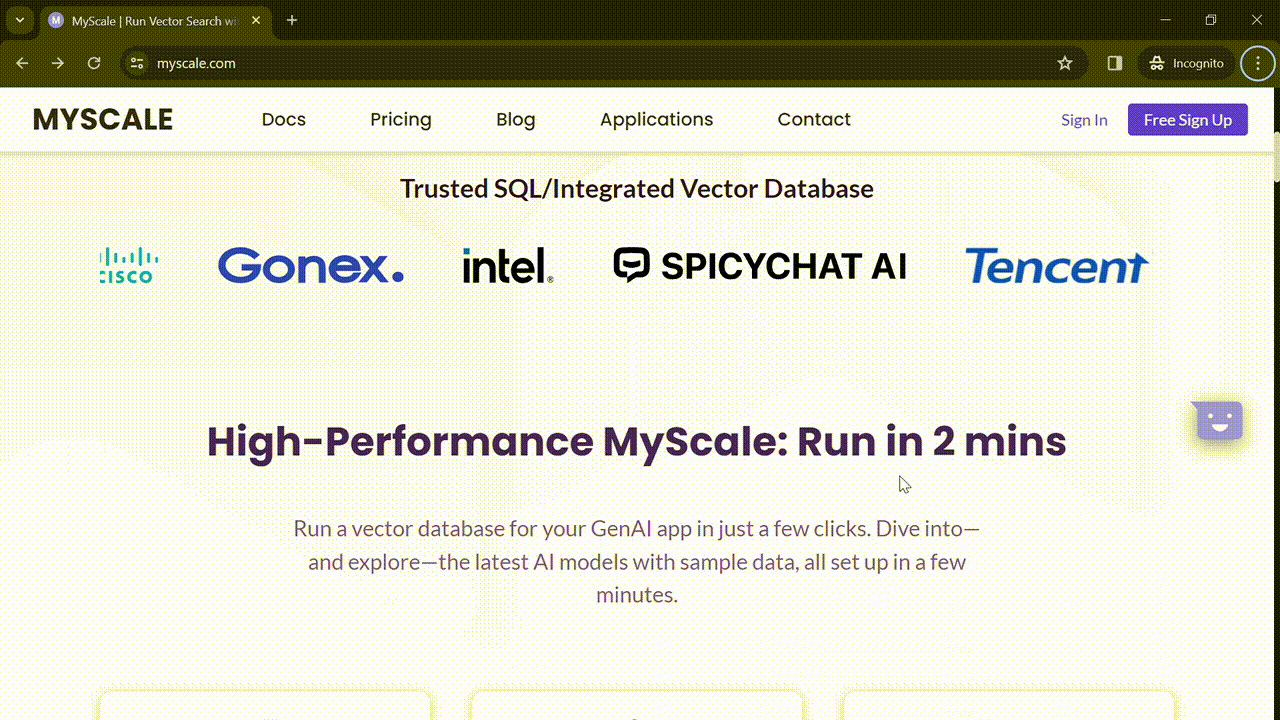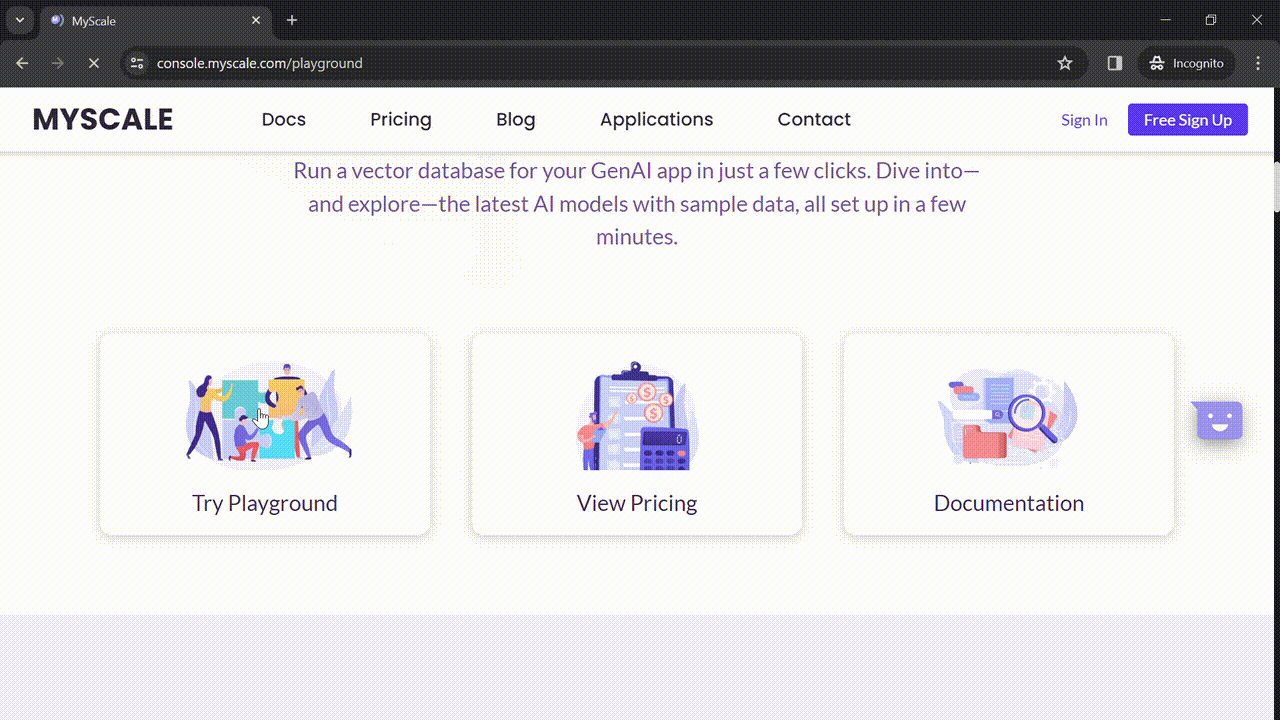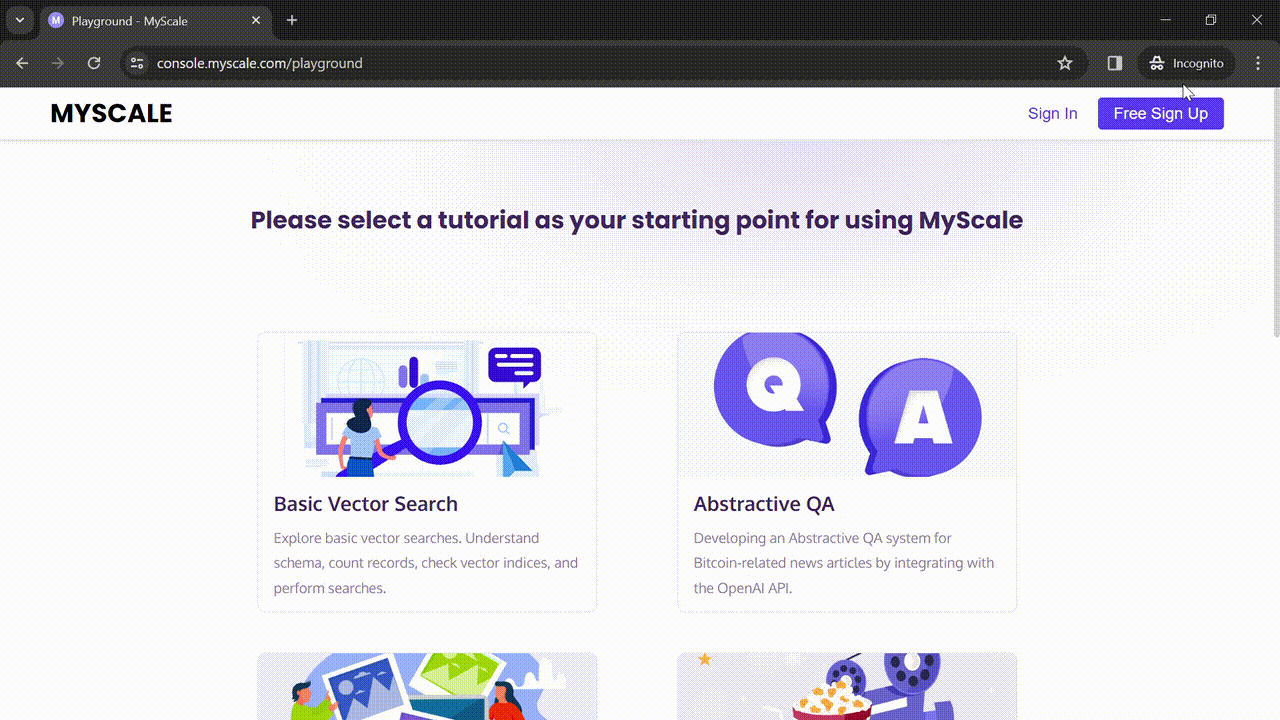
Recientemente, finalmente han agregado un playground a su plataforma y simplemente me encanta. He explorado playgrounds de muchos otros proveedores antes, pero creo que es el único playground que permite la ejecución de consultas conjuntas de SQL y vectores (opens new window), lo cual es una característica rara.
Vamos a explorar juntos el playground de MyScale (opens new window) ahora.
# Interfaz fácil de usar
En el playground, verás que ya se han creado varias aplicaciones de muestra para diferentes escenarios y se han cargado diferentes conjuntos de datos para cada aplicación.
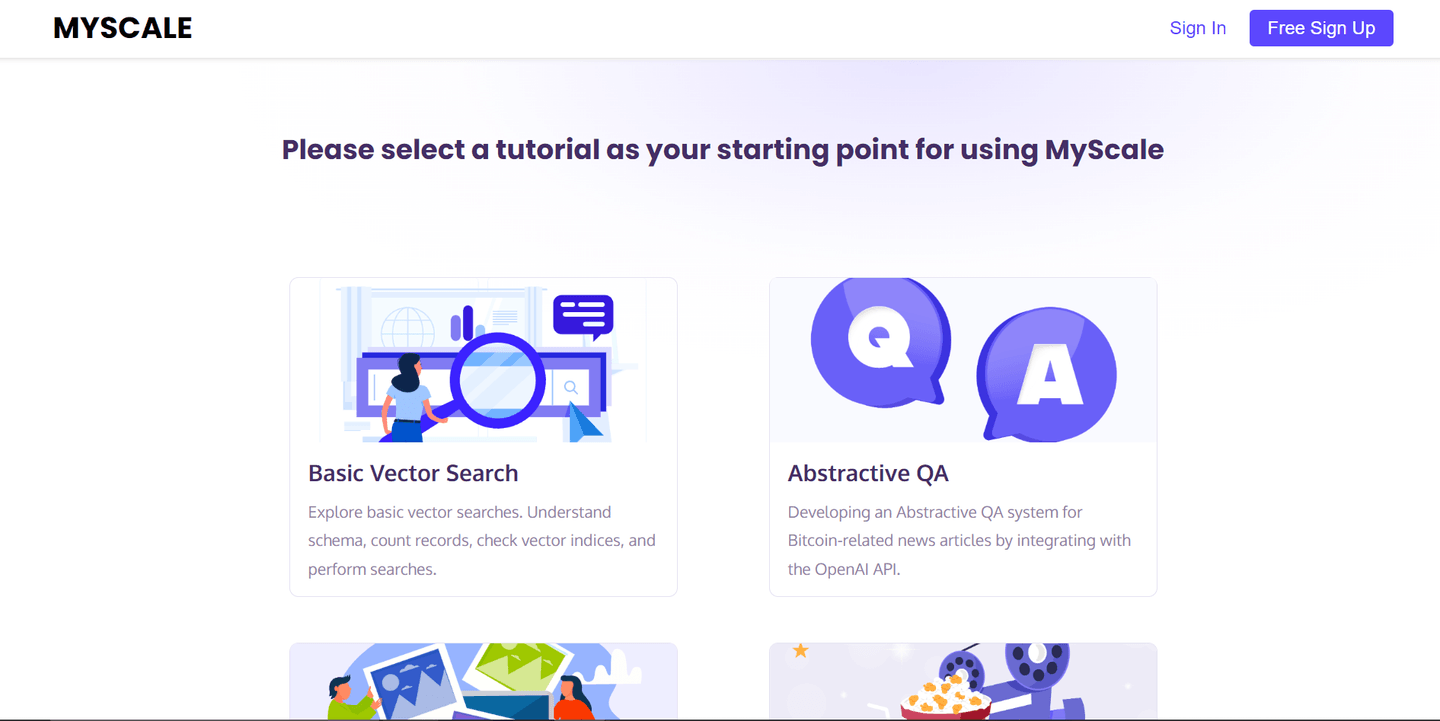
De todas estas aplicaciones de muestra, disfruto más de la aplicación Trabajando con textos (opens new window). Tiene el conjunto de datos de ArXiv precargado, que incluye más de 2.2 millones de artículos con información de metadatos.
Abre la aplicación y verás una interfaz como esta:
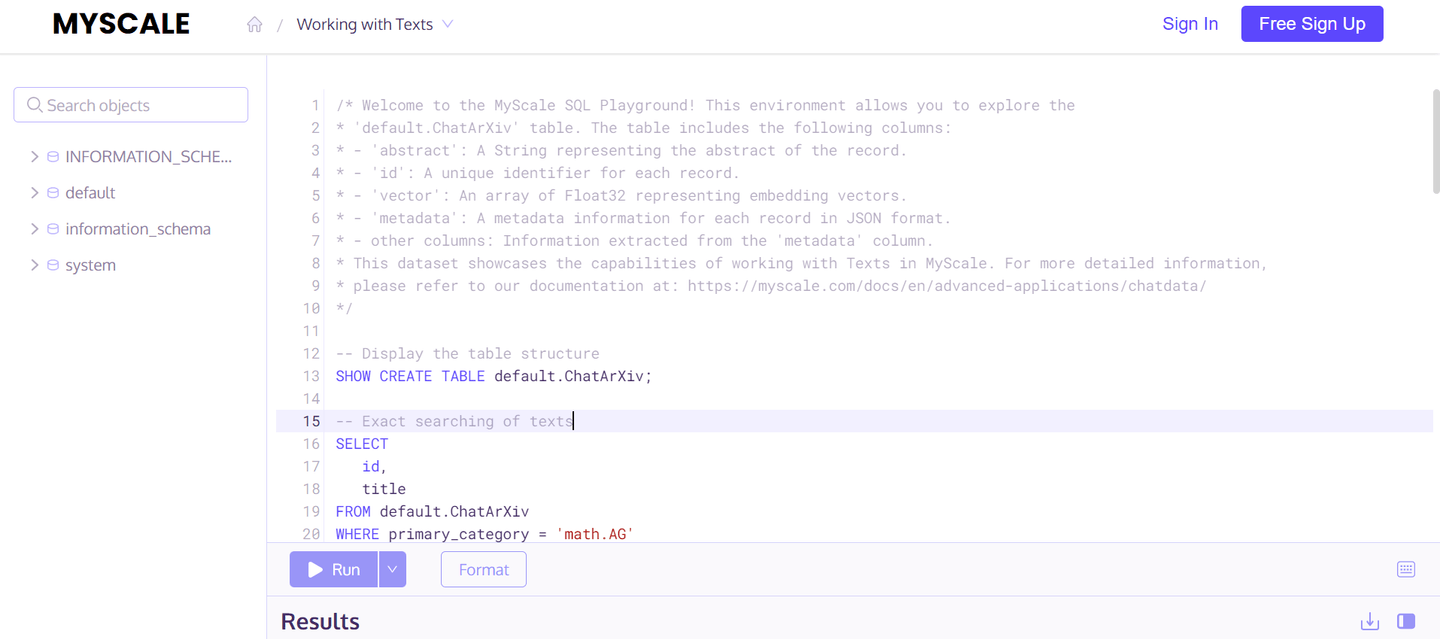
Lo primero que puedes notar al abrir cualquier aplicación es su descripción y los detalles de la tabla utilizada para esta aplicación. Al leer la descripción, puedes entender fácilmente para qué se utiliza la aplicación y cómo jugar con el conjunto de datos. Todas las bases de datos disponibles se muestran en el lado izquierdo para que puedas explorar las tablas preexistentes.
Luego, hay diferentes comandos de muestra agregados que puedes usar para explorar la aplicación y experimentar. Veamos algunas de las consultas de muestra:
# Consulta simple
Una vez que ejecutes la primera consulta, verás el comando utilizado para crear la tabla de esta aplicación.
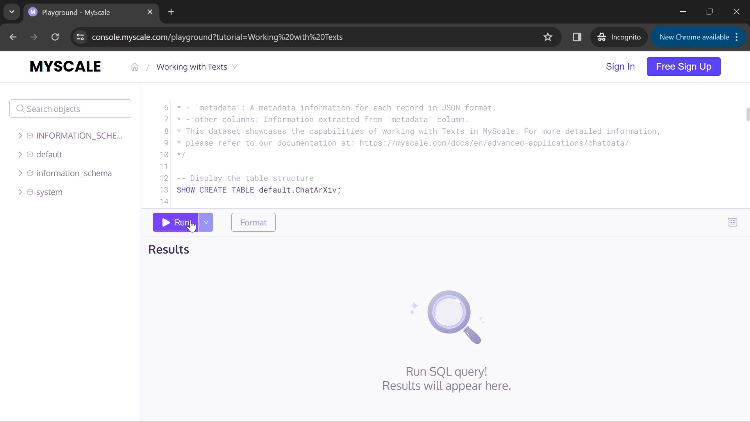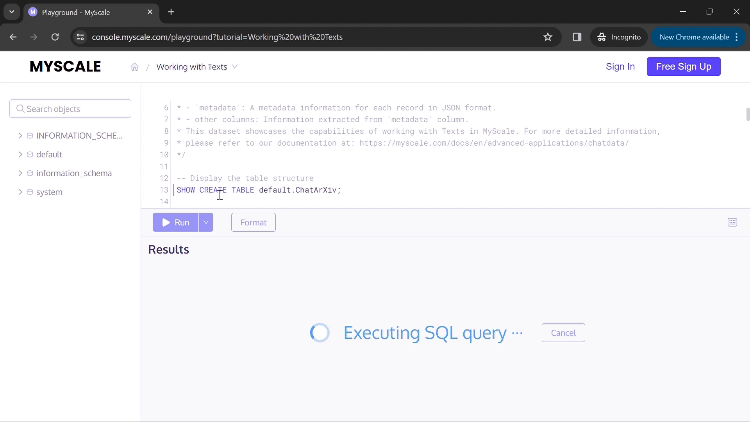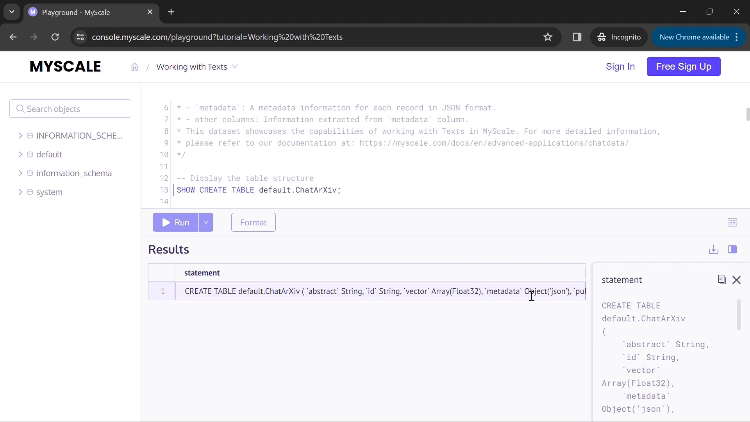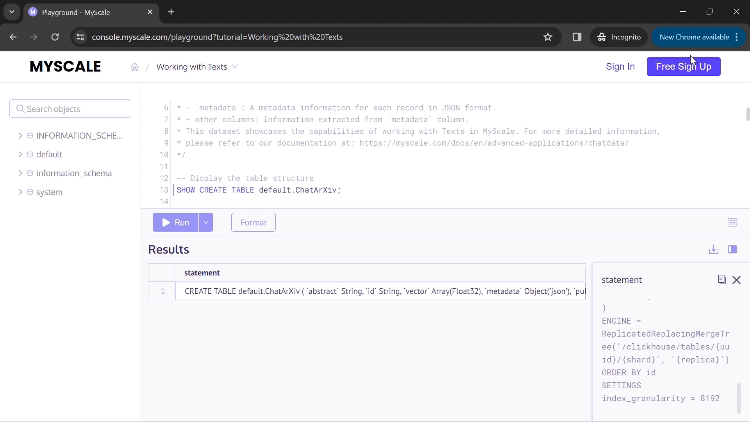
Puedes hacer clic en 'Ejecutar' para ejecutar tu comando y mostrar los resultados. Si un resultado contiene valores demasiado grandes para verse completamente en las columnas, puedes hacer clic en esa columna y se abrirá una nueva ventana de diálogo que mostrará los resultados completos (como se muestra en el GIF anterior).
También se han agregado algunas consultas de muestra con funciones predefinidas (opens new window). Sin embargo, omitiré estas consultas y pasaré directamente a la última consulta para realizar la consulta de búsqueda de vectores SQL.

# Consulta de búsqueda de vectores SQL
Como ya he mencionado, MyScale es una base de datos muy dinámica donde puedes ejecutar consultas SQL con búsquedas avanzadas de vectores. Esta combinación permite que MyScale maneje conjuntos de datos complejos de manera más efectiva y rentable. Se proporcionan algunas consultas de muestra solo para comprender mejor el conjunto de datos, pero las aplicaciones potenciales de MyScale van más allá de estos ejemplos. Por ejemplo, puedes utilizar la sintaxis SQL familiar para un análisis en profundidad del conjunto de datos, obteniendo así información valiosa. Toma la siguiente consulta, que proporciona una visión de la evolución y las tendencias actuales en la investigación de la computación cuántica:
WITH recent_quantum_papers AS (
SELECT id, vector, title, abstract, pubdate
FROM default.ChatArXiv
WHERE abstract LIKE '%computación cuántica%' AND pubdate > '2019-01-01'
),
reference_vector AS (
SELECT vector
FROM recent_quantum_papers
ORDER BY pubdate DESC
LIMIT 1
)
SELECT
id,
title,
abstract,
EXTRACT(YEAR FROM pubdate) AS year,
distance(vector, (SELECT vector FROM reference_vector)) AS similarity
FROM recent_quantum_papers
ORDER BY year DESC, similarity ASC
LIMIT 10;
Esta consulta filtra artículos académicos sobre computación cuántica publicados después de 2019, utilizando un vector del artículo más reciente para medir la similitud contextual entre ellos. Este enfoque no solo ordena los artículos cronológicamente, sino también por su relevancia con las últimas tendencias de investigación. La siguiente imagen muestra el resultado de la búsqueda que contiene los metadatos de los documentos y la distancia de similitud:
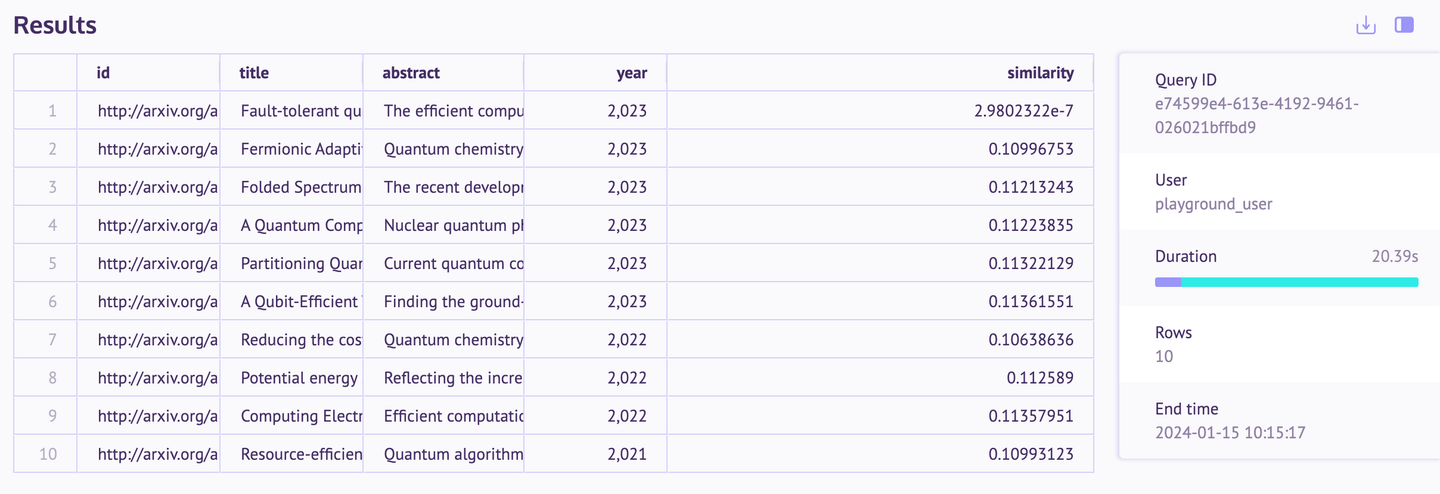
También puedes escribir consultas mucho más complejas con MyScale, ya que tiene soporte completo de SQL y vectores. Las otras aplicaciones de muestra también son bastante impresionantes. Si alguien está interesado, puede explorarlas.
Nota: No se admite la carga de datos directamente en el playground de MyScale. Para usar tus datos, primero inicia sesión o regístrate en MyScale y luego sigue las instrucciones paso a paso proporcionadas en la guía de inicio rápido (opens new window).
# Conclusión
En resumen, tengo una gran experiencia con el playground de MyScale, que proporciona un entorno fácil de usar para integrar sin problemas consultas SQL y vectoriales. La inclusión de aplicaciones de muestra estándar de la industria resultó invaluable para aprender y hacer la transición de las bases de datos tradicionales.
Construido sobre la sólida base de ClickHouse, MyScale abarca todas sus funcionalidades al tiempo que satisface las demandas de las aplicaciones de IA modernas. Su compatibilidad con la integración con OpenAI (opens new window), LangChain (opens new window) y LlamaIndex (opens new window) subraya aún más su versatilidad.
Si estás interesado en MyScale, vale la pena explorar el playground de MyScale, especialmente considerando que la interfaz del playground es tan simple y fácil de usar. Eso es todo lo que exploré del playground de MyScale. No dudes en compartir tus pensamientos o participar en discusiones en los comentarios.



