
Cuando se menciona la palabra base de datos, las bases de datos relacionales (opens new window) han sido durante mucho tiempo la elección predeterminada para el almacenamiento de datos debido a su simplicidad y facilidad de uso. Sin embargo, en el mundo actual impulsado por los datos, la creciente importancia de los datos no estructurados, como texto, imágenes y audio, ha llevado a la aparición de las bases de datos vectoriales (opens new window) como una alternativa viable.
A diferencia de las bases de datos tradicionales, que están restringidas a tipos de datos primitivos como enteros y cadenas, las bases de datos vectoriales almacenan y gestionan los datos como vectores. Esto les permite manejar datos no estructurados de manera eficiente, lo que las hace extremadamente populares. En los últimos años, muchas empresas han proporcionado bases de datos vectoriales y servicios de búsqueda vectorial. Por lo tanto, una serie de artículos realizará una comparación exhaustiva de MyScale (opens new window) y otras bases de datos vectoriales populares, comenzando con Pinecone. Pinecone (opens new window) es una base de datos vectorial especializada de código cerrado diseñada para manejar eficientemente datos vectoriales de alta dimensión. Sobresale en el almacenamiento, indexación y consulta de vectores embebidos, lo que la convierte en una solución ideal para la búsqueda de similitudes y aplicaciones de aprendizaje automático que requieren operaciones vectoriales en tiempo real y de alta dimensión.
Antes de la comparación entre MyScale y Pinecone, permíteme presentar brevemente algunos conceptos importantes relacionados con las bases de datos vectoriales.
# ¿Por qué es importante la búsqueda vectorial?
Un vector puede representar varias cosas: una matriz de valores, datos de texto, datos espaciales, imágenes, etc. Todos sabemos lo fácil que es realizar la aritmética básica de vectores o calcular productos escalares para encontrar su alineación/similitud.
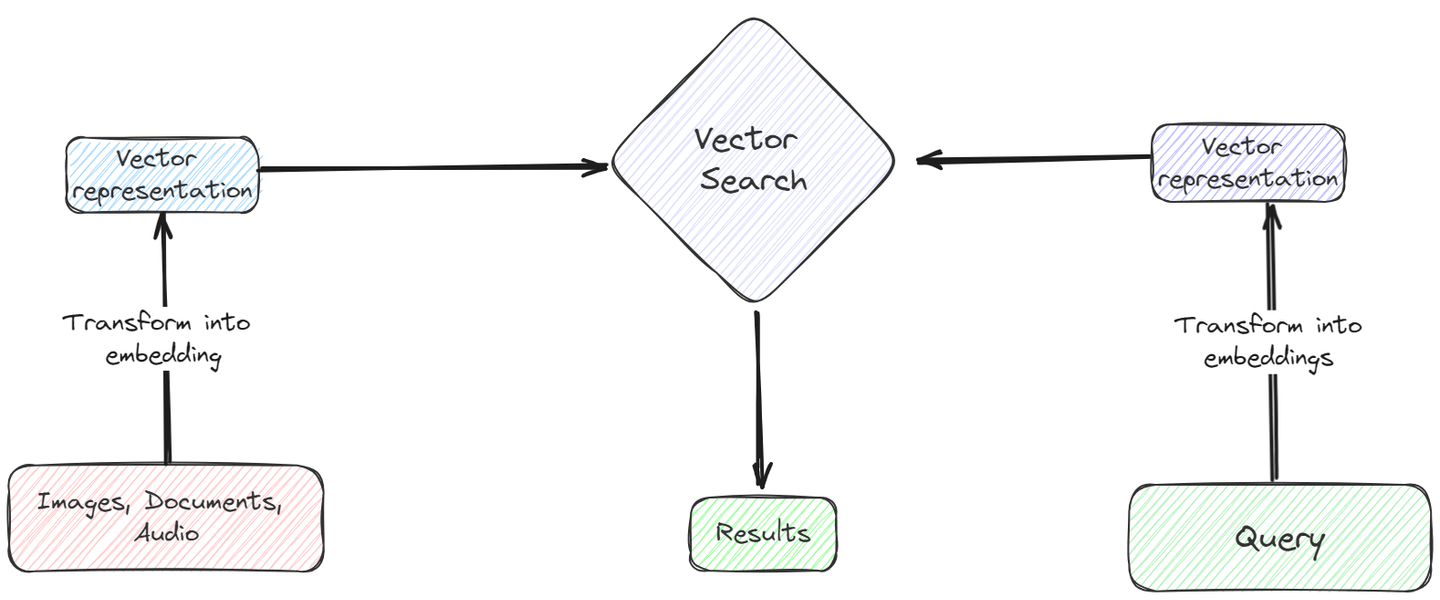
Utilizando algunos embeddings adecuados, los datos no estructurados se pueden almacenar en las bases de datos vectoriales en forma de vectores. Luego, se pueden utilizar medidas de similitud primitivas como la similitud del coseno o incluso la distancia euclidiana para realizar búsquedas de similitud rápidas y eficientes en los vectores. Esta búsqueda vectorial (opens new window) es mucho más rápida y rentable en comparación con las bases de datos tradicionales, lo que la hace adecuada para manejar grandes volúmenes de datos no estructurados de manera efectiva.
# ¿Qué son las bases de datos vectoriales SQL?
Además de las bases de datos vectoriales especializadas, algunas bases de datos SQL han ampliado sus capacidades para proporcionar también búsqueda vectorial. Estas soluciones integradas, conocidas como bases de datos vectoriales SQL (opens new window), tienen como objetivo proporcionar capacidades de búsqueda de similitud basadas en vectores dentro del entorno de datos estructurados y permiten gestionar tanto datos vectoriales como estructurados dentro de un marco de base de datos unificado. [Imagen: testtt (1).png]
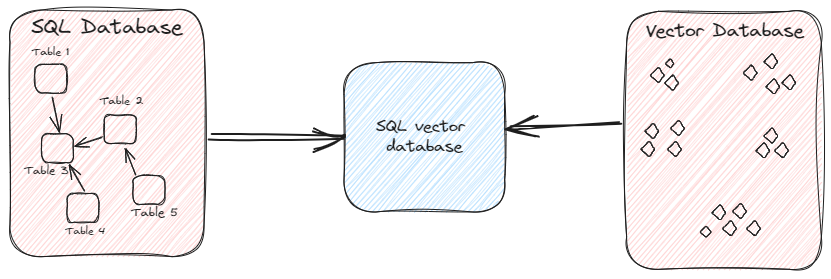
Entre las bases de datos vectoriales SQL, MyScale es una opción de código abierto que amplía las capacidades de ClickHouse. Es la única base de datos integrada que ha logrado superar incluso a las bases de datos vectoriales especializadas (opens new window) en términos de velocidad y rendimiento.
# Importancia en el ámbito de los LLM
Con la llegada de los LLM, inevitablemente sus aplicaciones se están extendiendo a diferentes áreas. Estos modelos fundamentales se pueden adaptar a los requisitos específicos de las aplicaciones utilizando una serie de métodos que se pueden clasificar en dos tipos: ajuste fino (opens new window) y RAG (opens new window).
En el ajuste fino, utilizamos el modelo existente y lo ajustamos a los datos nuevos/relevantes. Dado que implica aprendizaje, es computacionalmente bastante costoso. A pesar de técnicas como LoRA, etc., aún se requieren GPUs potentes para ajustar finamente los LLM.
RAG (opens new window), por otro lado, no implica procesos de aprendizaje tradicionales. En su lugar, utiliza embeddings vectoriales para la búsqueda vectorial. Este método utiliza medidas de similitud primitivas, lo que hace que el proceso de búsqueda sea significativamente más rápido.
Hasta ahora, hemos cubierto casi todos los conceptos básicos. Ahora procedamos a comparar las dos bases de datos, MyScale y Pinecone.
# Alojamiento
El alojamiento es un aspecto crítico a considerar al elegir una solución de base de datos, ya que tiene un impacto significativo en el rendimiento, la escalabilidad y la gestión. Una opción de alojamiento robusta garantiza que tu base de datos pueda manejar cargas variables, mantenerse accesible y ser fácilmente mantenida. Además, comprender las opciones de alojamiento ayuda a determinar si necesitas implementar la base de datos localmente utilizando tus propios recursos o optar por un servicio alojado en la nube.
Ambas opciones se pueden utilizar en modo basado en la nube creando instancias en la nube. Pinecone opera únicamente como un servicio en la nube propietario, mientras que MyScale ofrece tanto una versión en la nube, MyScale Cloud (opens new window), como una versión de código abierto disponible en https://github.com/myscale/myscaledb. La versión de código abierto se puede lanzar utilizando el siguiente comando de Docker:
docker run --name MyScale --net=host myscale/MyScale:1.6
Además, MyScale Cloud ofrece un nivel gratuito, lo que te permite registrarte rápidamente y comenzar (opens new window) a experimentar. Para obtener más detalles, consulta el documento de inicio rápido (opens new window).
# Funcionalidades principales
# Lenguaje de consulta y soporte de API
Un aspecto clave a considerar al adoptar una nueva tecnología de base de datos es la facilidad de integración con los flujos de trabajo de desarrollo existentes y la familiaridad con el lenguaje de consulta. Afortunadamente, MyScale evita este problema utilizando SQL, que ya utilizamos para las bases de datos relacionales.
MyScale no se detiene aquí, ya que también proporciona diversas herramientas de desarrollo integradas como Python Client (opens new window), Node.js (opens new window), Go Client (opens new window), ClientJDBC Driver (opens new window) e Interfaz HTTPS (opens new window).
TL;DR:
Tanto Pinecone como MyScale ofrecen SDK en varios lenguajes, pero MyScale tiene una ventaja distintiva con su soporte completo de SQL.
# Tipos de datos admitidos
Pinecone se dedica exclusivamente al almacenamiento de vectores. MyScale, por otro lado, es mucho más versátil y nos permite almacenar diferentes tipos de datos, desde texto hasta imágenes.
Podemos crear una tabla que tenga tanto atributos escalares como vectoriales sin problemas. Debido a la interfaz SQL, parece que estamos creando una tabla normal de base de datos relacional. Este código SQL creará una tabla con body_vector de longitud 512.
CREATE TABLE default.wiki_abstract(
id UInt64,
body String,
title String,
url String,
body_vector Array(Float32),
CONSTRAINT check_length CHECK length(body_vector) = 512
)
ENGINE = MergeTree
ORDER BY id;
Además, debido a que utiliza el formato tabular, no hay restricciones en la longitud de la fila. Por lo tanto, el tamaño del documento no está limitado, a diferencia de su competidor.
# Indexación
Existen varios algoritmos de indexación utilizados en las bases de datos vectoriales, como IVF y árboles KD. Pinecone utiliza el algoritmo Hierarchical Navigable Small Worlds (HNSW) y el algoritmo FreshDiskANN. FreshDiskANN está diseñado para actualizaciones en tiempo real eficientes, admitiendo un alto nivel de recuperación y rendimiento para conjuntos de datos a gran escala.
MyScale introduce el Multi-Scale Tree Graph (MSTG) (opens new window), un algoritmo que combina la agrupación jerárquica de árboles y la búsqueda basada en grafos. MSTG supera a los algoritmos contemporáneos al proporcionar búsquedas más rápidas con un consumo de recursos reducido. Si hubiera una sola razón para elegir MyScale sobre Pinecone, MSTG sería lo suficientemente convincente.
# Búsqueda vectorial filtrada
Pinecone ofrece filtrado de metadatos con soporte para hasta 40 KB de metadatos por vector. Estos metadatos pueden incluir cadenas de texto, números y booleanos, lo que permite búsquedas detalladas basadas en atributos. El mecanismo de filtrado de una sola etapa de Pinecone limita la búsqueda a los elementos que cumplen los criterios especificados, lo que acelera el proceso y lo hace más preciso al evitar búsquedas de fuerza bruta.
MyScale optimiza la búsqueda vectorial filtrada (opens new window) utilizando su algoritmo MSTG junto con las capacidades avanzadas de indexación y procesamiento paralelo de ClickHouse. Además, se adopta una estrategia de prefiltrado para reducir el conjunto de datos antes de la búsqueda vectorial principal, mejorando el rendimiento y la precisión. El almacenamiento orientado a columnas, la ejecución de consultas vectorizadas, la indexación avanzada y el procesamiento paralelo de ClickHouse hacen que sea una base sólida para MyScale en conjuntos de datos grandes, manteniendo la velocidad y la precisión sin las desventajas del postfiltrado.
TL;DR:
Pinecone destaca en búsquedas detalladas basadas en atributos con soporte de metadatos. Sin embargo, MyScale ofrece un rendimiento y una escalabilidad superiores para conjuntos de datos grandes con su estrategia de prefiltrado y su arquitectura basada en SQL.
# Búsqueda de texto completo
MyScale también ofrece funciones avanzadas de búsqueda de texto completo (opens new window) (FTS) utilizando la biblioteca Tantivy, que incluye búsquedas difusas y con comodines, y puntuación de relevancia basada en el algoritmo BM25. Esta configuración permite a MyScale acceder de manera intuitiva y eficiente a datos de texto no estructurados, lo que permite a los usuarios buscar según temas o ideas clave. MyScale ahora ofrece una solución sólida y eficiente para requisitos complejos de búsqueda de texto. Para crear un índice básico de FTS, puedes seguir la siguiente sintaxis:
-- Crear índice de búsqueda de texto completo
ALTER TABLE [nombre_tabla] ADD INDEX [nombre_índice] [nombre_columna]
TYPE fts;
-- Realizar consulta
SELECT
id,
title,
body,
TextSearch(body, 'instituto sin fines de lucro en Washington') AS score
FROM default.en_wiki_abstract
ORDER BY score DESC
LIMIT 5;
En cambio, Pinecone está diseñado únicamente para la búsqueda vectorial y no incluye capacidades de búsqueda de texto completo integradas.
TL;DR:
Esta función de búsqueda de texto completo de MyScale la convierte en una opción más versátil para aplicaciones que necesitan consultas y análisis de datos completos.
# Integración de APIs de LLM
No hay muchas diferencias aquí, ya que ambas admiten APIs comunes como LangChain, LlamaIndex, etc. Para tener una mejor idea, proporcionaré un código básico aquí que utiliza LangChain con MyScale.
from langchain_community.vectorstores import MyScale
docsearch = MyScale.from_documents(docs, embeddings)
output = docsearch.similarity_search("¿Cómo funcionan los LLM?", 3)
# Precios
Tanto Pinecone como MyScale ofrecen un nivel gratuito. Esto es muy útil, ya que a menudo los nuevos usuarios quieren simplemente probar una nueva herramienta antes de poder llegar a un consenso sobre si implementarla (o no). Para los nuevos usuarios, el nivel gratuito de Pinecone ofrece hasta 2 GB de almacenamiento, que puede manejar aproximadamente 300,000 vectores con 1,536 dimensiones cada uno.
Por otro lado, MyScale ofrece almacenamiento gratuito para hasta 5 millones de vectores de 768 dimensiones, que puede acomodar aproximadamente 2.5 millones de vectores de 1,536 dimensiones. Esto es significativamente mayor que el nivel gratuito de Pinecone, lo que hace que MyScale sea una opción más atractiva para los usuarios que necesitan gestionar conjuntos de datos más grandes sin costos iniciales.
Tanto Pinecone como MyScale ofrecen a los usuarios pods optimizados para el rendimiento y el almacenamiento según sus requisitos. Esta flexibilidad permite a los usuarios elegir la mejor solución según sus necesidades específicas. En cuanto a los precios, MyScale es significativamente más barato en comparación con Pinecone.
# Precios para pods optimizados para la capacidad
La siguiente tabla es ideal para los usuarios que requieren una mayor capacidad de almacenamiento para sus aplicaciones. Muestra las opciones de precios y capacidad disponibles tanto para MyScale como para Pinecone en la categoría de pods optimizados para la capacidad.
| Tipo de pod (MyScale) | Tamaño del pod | Precio base de MyScale ($/hora) | Capacidad estimada de MyScale | Tipo de pod (Pinecone) | Precio base de Pinecone ($/hora) | Capacidad aproximada de Pinecone |
|---|---|---|---|---|---|---|
| Pod optimizado para capacidad | x 1 | $0.094/hora | 10 millones de vectores | s1 | $0.11 | 5 millones de vectores |
| Pod optimizado para capacidad | x 2 | $0.189/hora | 20 millones de vectores | s1 | $0.22 | 10 millones de vectores |
| Pod optimizado para capacidad | x 4 | $0.378/hora | 40 millones de vectores | s1 | $0.44 | 20 millones de vectores |
| Pod optimizado para capacidad | x 8 | $0.756/hora | 80 millones de vectores | s1 | $0.89 | 40 millones de vectores |
| Pod optimizado para capacidad | x 16 | $1.511/hora | 160 millones de vectores | - | - | - |
| Pod optimizado para capacidad | x 32 | $3.022/hora | 320 millones de vectores | - | - | - |
Los pods optimizados para capacidad de MyScale tienen un precio razonable y ofrecen una mayor capacidad. En comparación con Pinecone, MyScale permite almacenar más vectores a un costo menor por hora.
# Precios para pods optimizados para el rendimiento
La siguiente tabla es ideal para los usuarios que priorizan el rendimiento sobre la capacidad. Muestra las opciones de precios y capacidad disponibles tanto para MyScale como para Pinecone en la categoría de pods optimizados para el rendimiento.
| Tipo de pod (MyScale) | Tamaño del pod | Precio base de MyScale ($/hora) | Capacidad estimada de MyScale | Tipo de pod (Pinecone) | Precio base de Pinecone ($/hora) | Capacidad aproximada de Pinecone |
|---|---|---|---|---|---|---|
| Pod estándar | x 1 | $0.167/hora | 5 millones de vectores | P2 | $0.17 | 1 millón de vectores |
| Pod estándar | x 2 | $0.333/hora | 10 millones de vectores | P2 | $0.33 | 2 millones de vectores |
| Pod estándar | x 4 | $0.667/hora | 20 millones de vectores | P2 | $0.67 | 4 millones de vectores |
| Pod estándar | x 8 | $1.333/hora | 40 millones de vectores | P2 | $1.33 | 8 millones de vectores |
| Pod estándar | x 16 | $2.667/hora | 80 millones de vectores | - | - | - |
| Pod estándar | x 32 | $5.333/hora | 160 millones de vectores | - | - | - |
En términos de pods optimizados para el rendimiento, MyScale ofrece una solución más rentable con la capacidad de almacenar un mayor número de vectores en comparación con Pinecone. Esto hace que MyScale sea una excelente opción para los usuarios que buscan una opción económica que no comprometa la capacidad.
TL;DR:
MyScale destaca como una mejor opción en términos de rendimiento y costos, ofreciendo una mayor capacidad de almacenamiento a precios más bajos en comparación con Pinecone, lo que la hace ideal para usuarios que necesitan gestionar eficientemente datos a gran escala.

# Evaluación comparativa
Ahora, compararemos el rendimiento entre MyScale y Pinecone mediante una evaluación comparativa en algunas métricas clave. A lo largo de la comparación, utilizaremos MyScale con MSTG, mientras que utilizaremos dos variantes de Pinecone (1 nodo y 5 pods).
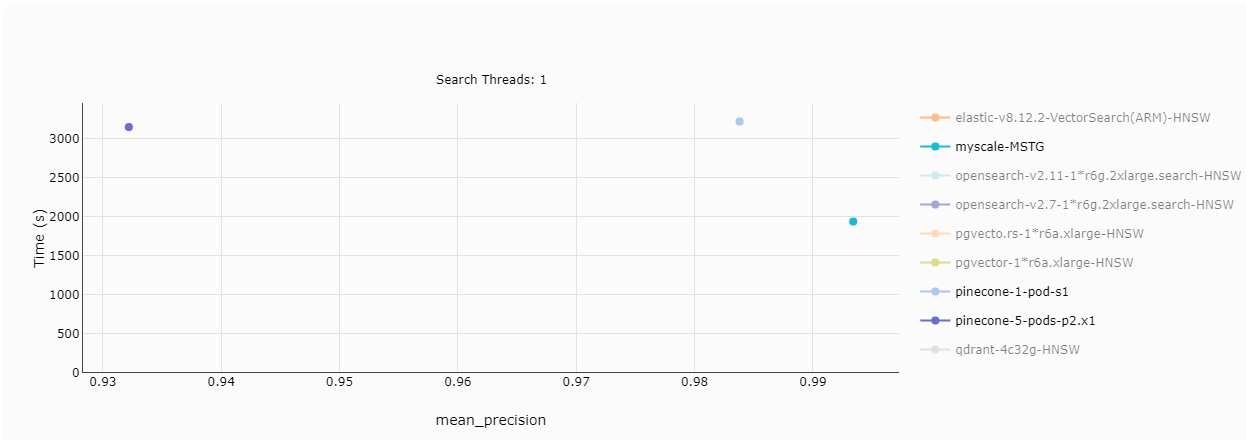
# Rendimiento (Consultas por segundo)
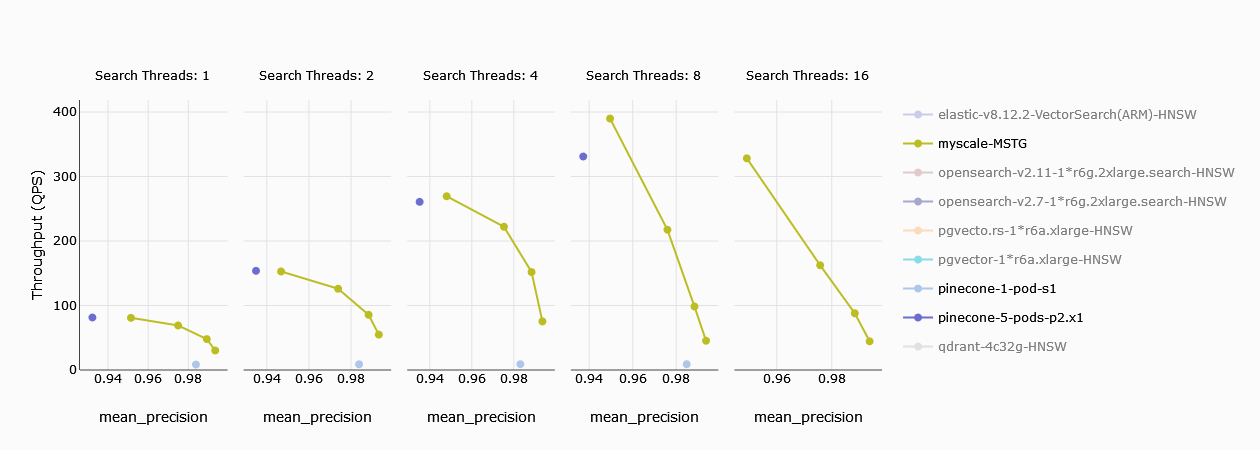
El rendimiento es una medida fundamental del rendimiento del sistema, y los clientes naturalmente están interesados en la cantidad de consultas que se pueden manejar por segundo. En búsquedas de un solo hilo, el pod s1 de Pinecone se queda significativamente atrás de MyScale. Sin embargo, cinco pods p2 de Pinecone pueden manejar una cantidad comparable de consultas por segundo. Cuando el número de hilos aumenta a 2, la brecha de rendimiento se amplía, y con 8 hilos, incluso los cinco pods p2 comienzan a quedarse rezagados.
Nota: En los gráficos, el amarillo representa a MyScale, y los cuatro puntos diferentes indican diferentes niveles de precisión. Una limitación de Pinecone es su incapacidad para ajustar la precisión como MyScale, lo que resulta en un máximo de recuperación de solo el 94%.
TL;DR:
El pod s1 de Pinecone no puede competir con MyScale, pero cinco pods p2 pueden igualar su rendimiento. La falta de ajuste de precisión de Pinecone le impide alcanzar una recuperación superior al 94%, a diferencia de MyScale.
# Latencia promedio de consulta
La siguiente métrica de interés es la latencia promedio de consulta, que mide el tiempo promedio que se tarda en procesar una consulta. En nuestra comparación, el pod s1 de Pinecone no coincide con MyScale, mientras que los cinco pods p2 son competitivos.
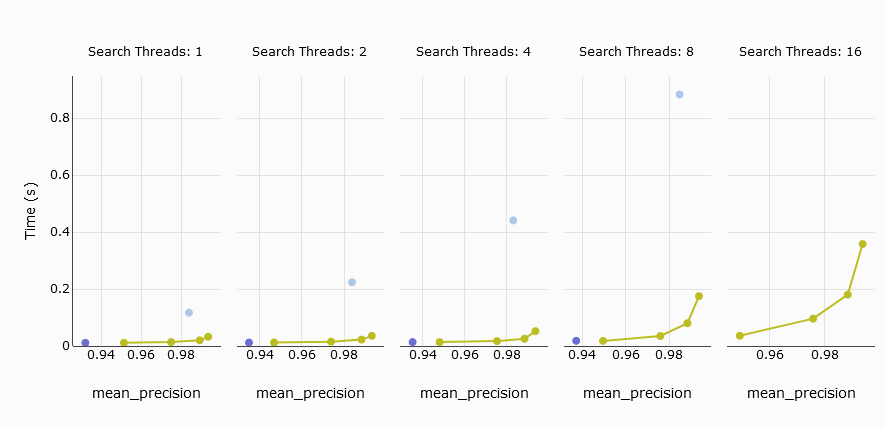
Para mejorar la comparación, excluimos el pod s1 y nos centramos en los cinco pods p2 frente a MyScale. Los resultados muestran que MyScale y Pinecone exhiben retrasos similares con hasta 4 hilos. Sin embargo, la latencia promedio de consulta de MyScale aumenta significativamente cuando el número de hilos alcanza 8 o más.
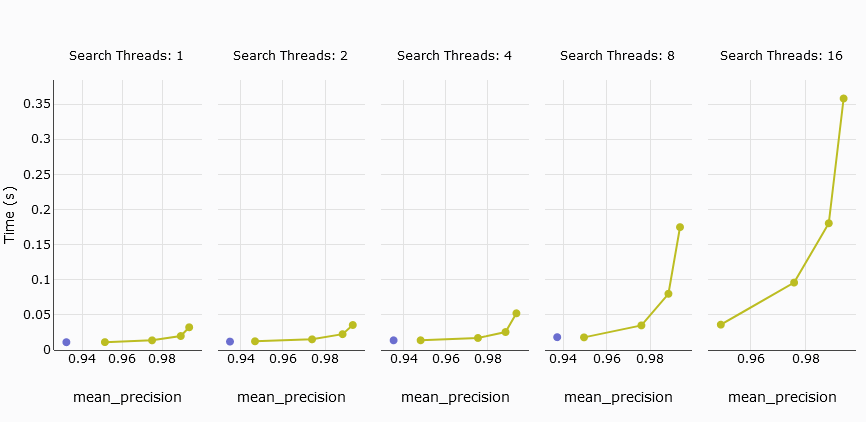
TL;DR:
Al comparar los cinco pods p2 de Pinecone con MyScale, ambos muestran una latencia promedio de consulta similar a baja precisión. Sin embargo, Pinecone no puede ajustar su precisión para lograr una recuperación superior al 94%, a diferencia de MyScale.
# Tiempo de ingestión de datos
Otra métrica útil es el tiempo de ingestión de datos, es decir, cuánto tiempo se tarda en cargar y construir la base de datos.
MyScale tuvo el tiempo de ingestión más rápido para 5 millones de puntos de datos, completando la tarea en aproximadamente 30 minutos. Pinecone s1 tarda aproximadamente 53 minutos.
# Comparación de costos
Utilizamos cinco pods p2 en esta comparación, que ofrecen un rendimiento comparable a un solo pod estándar de MyScale. Sin embargo, el costo de cinco pods p2 asciende a aproximadamente $600 al mes, lo que los hace cinco veces más caros que MyScale. Esta marcada diferencia de costos destaca la superioridad de MyScale en cuanto a rentabilidad, al ofrecer el mismo rendimiento a una fracción del precio.
| Base de datos | Tipo de pod | Costo mensual ($) | Notas |
|---|---|---|---|
| MyScale | Pod estándar de tamaño x1 | 120 | Ofrece un rendimiento y una latencia comparables a cinco pods p2 de Pinecone |
| MyScale | Pod optimizado para capacidad | 68 | Opción rentable para la optimización de capacidad |
| Pinecone | Pod s1.x1 | 80 | Optimizado para almacenamiento |
| Pinecone | 5 x pods p2.x1 | 600 | Optimizado para el rendimiento mediante la escalabilidad horizontal |
A pesar del mayor costo por pod de MyScale en comparación con el pod s1 de Pinecone, ofrece un rendimiento y una latencia comparables a cinco pods p2 de Pinecone a una quinta parte del costo.
TL;DR:
El pod estándar de MyScale es mucho más rentable, ofreciendo un rendimiento similar a cinco pods p2 de Pinecone, que son cinco veces más caros.
# Conclusión
Al comparar MyScale y Pinecone, MyScale destaca por su integración basada en SQL, soporte versátil de tipos de datos y rendimiento superior con el algoritmo MSTG. MyScale ofrece un mayor rendimiento en consultas y tiempos de ingestión de datos, opciones de almacenamiento rentables y capacidades de búsqueda de texto completo. Esto la convierte en una excelente opción para gestionar conjuntos de datos grandes y diversos.
Pinecone destaca en búsquedas detalladas basadas en atributos con soporte de metadatos ricos. Sin embargo, la naturaleza de código abierto de MyScale, su escalabilidad y sus ventajas de rendimiento la convierten en una opción más versátil y poderosa. La ventaja de MyScale en rendimiento, flexibilidad y costos la hace ideal para manejar diversas necesidades de gestión de datos a gran escala.
Si tienes alguna sugerencia, por favor contáctanos a través de Twitter (opens new window) o Discord (opens new window).



