
En esta publicación, comparamos MyScale, una base de datos vectorial integrada que ofrece soporte completo de SQL, con dos bases de datos tradicionales: PostgreSQL y OpenSearch. Ambas bases de datos han añadido recientemente la búsqueda de similitud vectorial a sus herramientas.
Nota:
Actualizamos continuamente los resultados de referencia para MyScale y otros productos de bases de datos vectoriales en nuestro proyecto de código abierto, vector-db-benchmark (opens new window).
La llegada de los Modelos de Lenguaje Grande (LLMs, por sus siglas en inglés) ha aumentado el interés en integrar interfaces conversacionales en diversas aplicaciones, como motores de búsqueda, generadores de código y herramientas de análisis de datos. La búsqueda de similitud vectorial es una tecnología clave que permite esto, desempeñando un papel vital en mejorar el rendimiento de los LLMs a través de la Generación Mejorada por Recuperación (RAG, por sus siglas en inglés) (opens new window).
Existen una amplia variedad de productos de bases de datos vectoriales en el mercado; algunos son bases de datos vectoriales especializadas diseñadas específicamente para índices vectoriales, mientras que otros son bases de datos vectoriales integradas o bases de datos de propósito general ampliadas para admitir la búsqueda vectorial.
Además, las bases de datos vectoriales integradas tienen varias ventajas distintas sobre las bases de datos vectoriales especializadas, incluyendo:
- Almacenan vectores y datos estructurados en la misma base de datos, lo que facilita búsquedas filtradas más complejas, así como consultas conjuntas de SQL y vectores.
- Utilizan lenguajes de consulta potentes y ampliamente utilizados como SQL para el análisis de datos estructurados y vectoriales.
- Aprovechan herramientas e integraciones maduras de bases de datos de propósito general.
- Reducen los costos adicionales de mano de obra para habilidades especializadas y los costos de licencia de bases de datos especializadas.
Las tres bases de datos vectoriales integradas que estamos comparando son las siguientes:
- MyScale es una base de datos vectorial integrada desarrollada sobre ClickHouse, que combina la capacidad de búsqueda de similitud vectorial con soporte completo de SQL;
- PostgreSQL proporciona soporte de búsqueda vectorial a través de su extensión pgvector (opens new window); y
- OpenSearch incorpora la búsqueda neural (vectorial) en la versión 2.9.0 (opens new window).
Como se describe a continuación, nuestra evaluación exhaustiva revela que MyScale supera ampliamente a otros productos en términos de precisión de búsqueda vectorial filtrada, rendimiento, eficiencia de costos y tiempo de construcción de índices. Es importante destacar que MyScale es el único producto probado que ofrece una precisión de búsqueda saludable y QPS en varias proporciones de filtro.
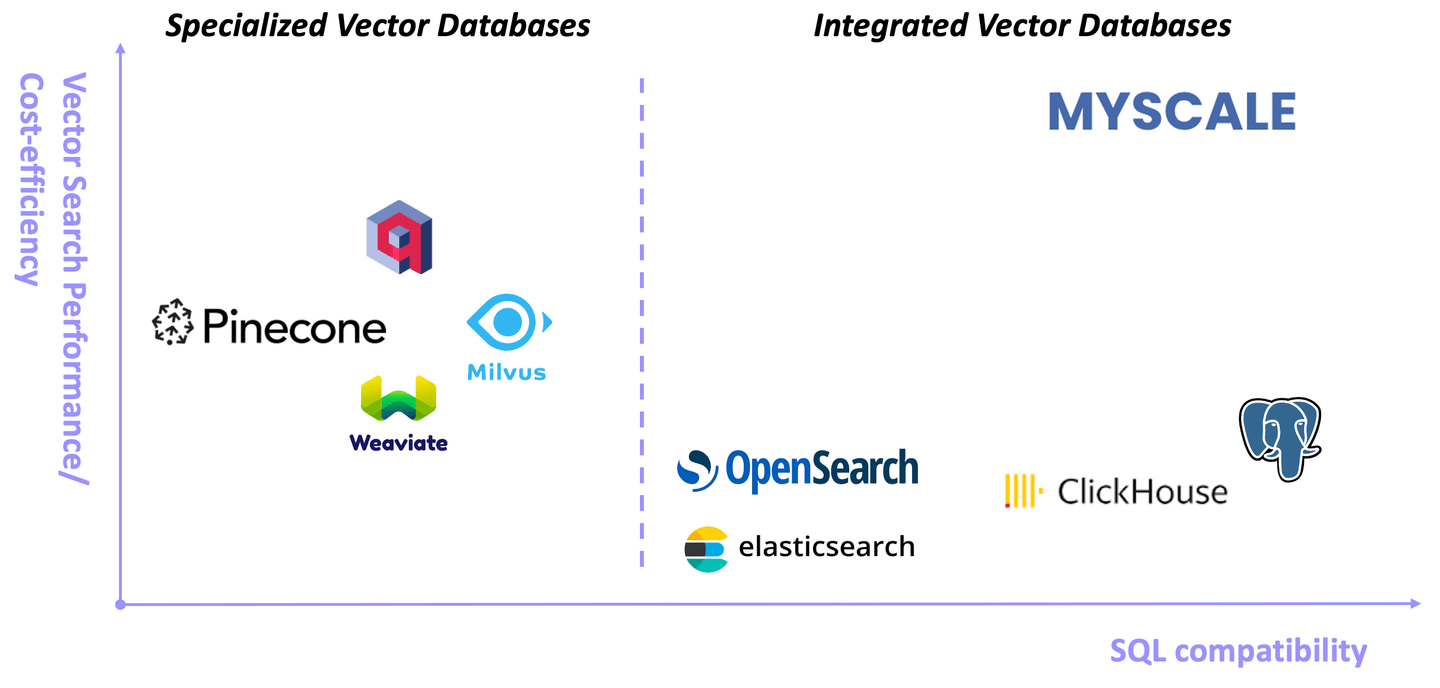
Además, MyScale también supera a las bases de datos vectoriales especializadas, consulte esta publicación (opens new window) y nuestro benchmark de código abierto (opens new window) para obtener más detalles. Como se muestra en la siguiente figura, la combinación de soporte completo de SQL con un alto rendimiento de búsqueda vectorial hace de MyScale una opción convincente para gestionar sus datos relacionados con IA/LLM, tanto estructurados como vectorizados:
# Configuración del benchmark
Realizamos benchmarks en MyScale, OpenSearch y dos extensiones de búsqueda vectorial de PostgreSQL. Los detalles se proporcionan a continuación.
| Base de datos | Tipo de instancia | Costo mensual (USD) | Notas |
|---|---|---|---|
| MyScale (opens new window) | Tamaño de instancia: x1 | 120 | Actualmente gratuito para la capa de desarrollo (opens new window). |
| PostgreSQL con pgvector (opens new window) | db.r6g.xlarge (opens new window) (4C 32GB) | 329 | Amazon RDS para PostgreSQL |
| PostgreSQL con pgvecto.rs (opens new window) | db.r6g.xlarge (opens new window) (4C 32GB) | 329 | Amazon RDS para PostgreSQL |
| AWS OpenSearch Service (opens new window) | r6g.2xlarge.search (opens new window) (8C 64GB) | 488 | Dominio de Amazon OpenSearch Service |
Utilizamos 5 millones de vectores de 768 dimensiones, generados a partir del conjunto de datos LAION 2B images (opens new window), tanto para las pruebas de búsqueda vectorial como para las pruebas de búsqueda vectorial filtrada.
::: nota Nota: El código completo, los conjuntos de datos y los resultados se encuentran en nuestra página de benchmark (opens new window). :::
Elegimos el tipo de instancia más pequeño para cada base de datos que fuera capaz de alojar todos los vectores.
Dado que las versiones más recientes de pgvector y pgvecto.rs aún no han sido ampliamente adoptadas por ningún servicio de PostgreSQL en la nube, optamos por autohospedarlos al ejecutar nuestros benchmarks. Sin embargo, hemos incluido los precios de Amazon RDS para PostgreSQL en la tabla anterior con fines de comparación.
::: nota Nota: Los servicios en la nube de PostgreSQL como Supabase (opens new window) y TimeScaleDB (opens new window) pueden costar más para configuraciones de hardware similares. :::
Para OpenSearch, seleccionamos el tipo de instancia r6g.2xlarge.search (64GB de memoria) ya que encontramos problemas al intentar construir el índice vectorial en una instancia r6g.xlarge.search (32GB de memoria). Como muestra el resumen, MyScale sigue siendo la base de datos vectorial integrada más rentable.
# Resultados del benchmark
Hemos resumido nuestros hallazgos a continuación:
# Búsqueda Vectorial
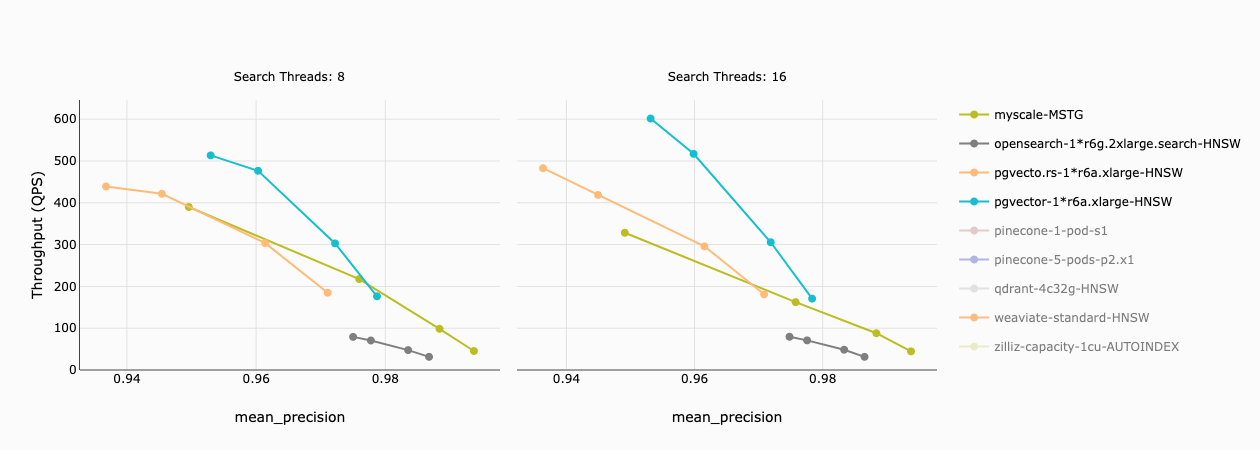
En el gráfico siguiente, el eje x representa la precisión y el eje y representa el rendimiento (QPS) para cada base de datos vectorial. Encontramos lo siguiente:
- MyScale y las dos extensiones de PostgreSQL tienen un rendimiento similar a una precisión del 97%;
- pgvector y pgvecto.rs pueden lograr un rendimiento más alto a precisiones más bajas, pero incurren en costos significativamente más altos que MyScale; y
- OpenSearch se quedó rezagado en velocidad en todas las precisiones.
# Búsqueda Vectorial Filtrada
En escenarios del mundo real, la búsqueda vectorial pura rara vez es suficiente. Los vectores suelen venir con metadatos y los usuarios a menudo necesitan aplicar uno o más filtros a estos metadatos.
El siguiente gráfico describe el rendimiento de MyScale (y otras bases de datos vectoriales integradas) en un conjunto de datos con una proporción de filtro del 1%. Una proporción de filtro del 1% implica que quedan 50K vectores (1% x 5M vectores) después de aplicar la condición de filtro.
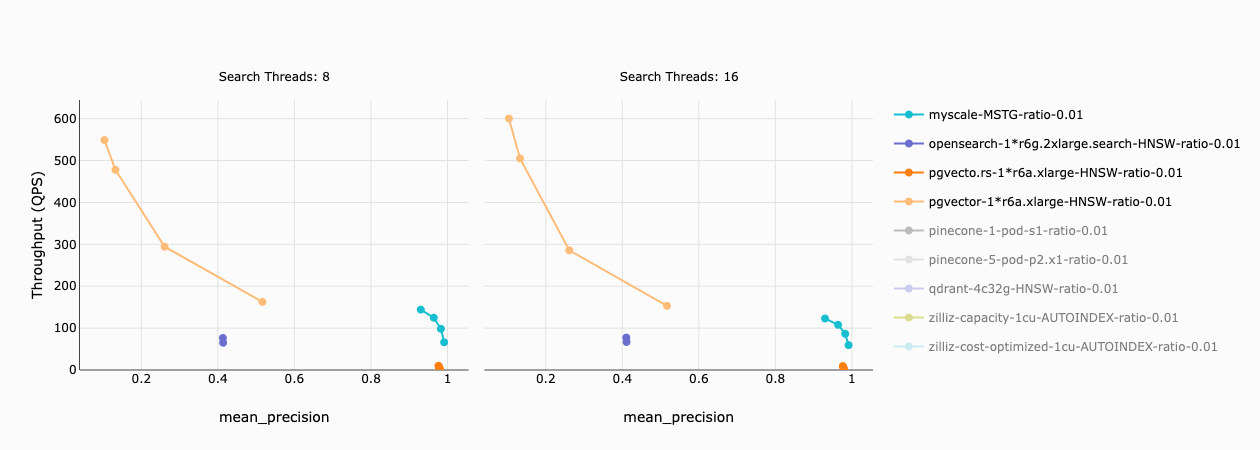
Nuestros hallazgos revelaron la siguiente información:
- La precisión de pgvector y OpenSearch es baja (menos del 50%) y casi inutilizable en la práctica.
- El rendimiento de pgvecto.rs es relativamente bajo (menos de 10 QPS).
- Solo MyScale mantiene un rendimiento saludable (66 - 144 QPS) y una precisión del (93% - 99%).
Existen dos enfoques principales al implementar búsquedas vectoriales filtradas en estas bases de datos.
# Post-Filtrado
Este método consiste en realizar una búsqueda vectorial primero y luego eliminar los resultados que no coinciden con el filtro. Desafortunadamente, hay dos desventajas importantes al utilizar este método:
- En primer lugar, el número de elementos en la búsqueda es impredecible, ya que el filtro se aplica a una lista de candidatos que ya ha sido reducida.
- En segundo lugar, si el filtro es muy restrictivo, es decir, coincide solo con un pequeño porcentaje de puntos de datos en relación con el tamaño del conjunto de datos, existe la posibilidad de que la búsqueda vectorial original no contenga ninguna coincidencia en absoluto.
# Pre-Filtrado
Las bajas precisiones de pgvector y OpenSearch se deben a su uso de post-filtrado. En contraste, MyScale y pgvecto.rs utilizan un enfoque diferente conocido como pre-filtrado. El filtro se aplica primero y se pasa un mapa de bits al índice vectorial para realizar la búsqueda vectorial.
Durante nuestro benchmark, el algoritmo HNSW utilizado por pgvecto.rs tuvo un rendimiento deficiente cuando la proporción de filtro era baja. Además, el almacenamiento basado en filas de PostgreSQL no es adecuado para la operación de escaneo a gran escala requerida en el pre-filtrado, lo que empeora aún más el rendimiento subóptimo. MyScale, por otro lado, supera este problema combinando el motor de ejecución de SQL columnar rápido de ClickHouse (opens new window) y nuestro algoritmo de índice vectorial MSTG (opens new window).
# Evaluación de la Eficiencia de Costos: Búsqueda Vectorial Pura vs. Búsqueda Vectorial Filtrada
Al seleccionar una base de datos, no solo se debe considerar el rendimiento bruto, sino también el valor derivado de la inversión. La eficiencia de costos, especialmente en niveles de precisión más altos como el 95%, se convierte en un criterio fundamental para las empresas que realizan búsquedas vectoriales extensas.
# Búsqueda Vectorial Pura
Para tener una idea clara de la eficiencia de costos, hemos calculado el costo por rendimiento de cada base de datos examinando su costo mensual en relación con las Consultas por Segundo (QPS) que pueden lograr a aproximadamente el 95% de precisión, lo que proporciona una indicación del costo por 100 QPS para cada base de datos.
Como indican los siguientes resultados, MyScale ofrece una eficiencia de costos excepcional, superando a su competidor más cercano en al menos un factor de 1.8x.
| Base de datos | Costo mensual (USD) por 100 QPS |
|---|---|
| MyScale | 30 |
| pgvector | 54 |
| pgvecto.rs | 79 |
| OpenSearch | 613 |
# Búsqueda Vectorial Filtrada con una Proporción de Filtro del 1%
Sin embargo, muchos escenarios del mundo real requieren más que búsquedas vectoriales puras. A menudo se aplican filtros a los conjuntos de datos para reducir los resultados. Cuando evaluamos la eficiencia de costos para una búsqueda vectorial filtrada con una proporción de filtro del 1%, el panorama cambia. Es importante destacar que pgvector y OpenSearch no pudieron lograr una precisión superior al 50%. Esta baja precisión es inutilizable en la mayoría de los casos, por lo que se marcan como N/A en este análisis.
| Base de datos | Costo mensual (USD) por 100 QPS |
|---|---|
| MyScale | 96 |
| pgvector | N/A |
| pgvecto.rs | 3290 |
| OpenSearch | N/A |
En conclusión, si bien MyScale sigue siendo el líder en búsquedas vectoriales puras, su dominio es aún más pronunciado en las búsquedas vectoriales filtradas. Ofreciendo un rendimiento de primer nivel a una fracción del costo, MyScale garantiza a las empresas un retorno óptimo de su inversión. Esta combinación de alta precisión, eficiencia de costos y rendimiento hace de MyScale una opción destacada para las organizaciones que buscan aprovechar las bases de datos vectoriales integradas de manera efectiva.
# Tiempo de Construcción de Índices
Después de insertar vectores en una base de datos vectorial, los usuarios deben crear un índice vectorial antes de realizar búsquedas vectoriales. El tiempo necesario para construir el índice es crucial para obtener resultados de búsqueda rápidos, y los tiempos de construcción de índices para las cuatro bases de datos vectoriales diferentes se describen en la siguiente tabla:
| Base de datos | Tiempo de carga y construcción del índice |
|---|---|
| MyScale | 32 min |
| Pgvector | 10.9 horas |
| Pgvecto.rs | 80 min |
| OpenSearch | 45 min |
Estos resultados muestran que MyScale es el claro líder con el tiempo de construcción más rápido, mientras que pgvector fue extremadamente lento en la construcción del índice vectorial HNSW debido a la falta de soporte de construcción paralela. La construcción rápida de índices es fundamental cuando la aplicación requiere insertar y actualizar muchos vectores (como en el chat en línea a gran escala, la edición de documentos, etc.), y también reduce la contención de recursos entre la construcción de índices y la búsqueda vectorial.
# Conclusión
Después de un análisis exhaustivo, MyScale supera consistentemente a sus competidores, mostrando un rendimiento superior en la búsqueda vectorial filtrada y un tiempo de construcción de índices rápido. Entre todos los productos probados, MyScale es la única base de datos vectorial integrada que ofrece una alta precisión de búsqueda y QPS en varias proporciones de filtro. Lo que distingue a MyScale de otros productos también es su destacada eficiencia de costos, lo que la convierte en una opción sólida de base de datos vectorial integrada y una elección financieramente inteligente. Para las organizaciones que buscan aprovechar las capacidades de las bases de datos vectoriales integradas, MyScale se destaca como un competidor destacado debido a su combinación imbatible de rendimiento, precisión y relación calidad-precio.

# Exploración Adicional
Para comprender mejor cómo MyScale se compara con las bases de datos vectoriales especializadas en términos de rendimiento, recomendamos leer esta publicación (opens new window).
Y para aquellos que estén considerando migrar sus datos vectoriales de PostgreSQL a MyScale, esta guía (opens new window) proporciona información valiosa e instrucciones paso a paso.



