
Las bases de datos vectoriales (opens new window) y las búsquedas vectoriales (opens new window) están ganando rápidamente popularidad debido a su impresionante velocidad y escalabilidad. A diferencia de los modelos tradicionales de aprendizaje automático, estas bases de datos aprovechan medidas de similitud eficientes como la distancia euclidiana (opens new window), la similitud del coseno (opens new window), etc. para ofrecer resultados de búsqueda rápidos sin requerir un entrenamiento extenso. Esta eficiencia, junto con su rentabilidad en comparación con las alternativas basadas en IA, las convierte en una solución atractiva para diversas aplicaciones.
Dado el creciente panorama de las bases de datos vectoriales, elegir la adecuada para tus necesidades específicas puede ser un desafío. Factores como el rendimiento, el costo y la funcionalidad juegan un papel crucial en la determinación de la opción ideal.
Este artículo, el tercero de nuestra serie, profundiza en una comparación detallada de dos destacados contendientes: MyScaleDB (opens new window) y Qdrant (opens new window). Ambas bases de datos ofrecen ventajas únicas, por lo que un análisis exhaustivo es esencial para tomar decisiones informadas.
Nota: Si eres nuevo en las bases de datos vectoriales, te recomendamos comenzar con el primer artículo (opens new window) de esta serie para obtener una comprensión básica de esta poderosa tecnología.
# Introducción de MyScaleDB y Qdrant
# MyScaleDB
MyScaleDB se destaca como una base de datos nativa de la nube optimizada para aplicaciones y soluciones de IA. Construida sobre la sólida base de datos de código abierto y altamente escalable ClickHouse (opens new window), MyScaleDB ofrece varias ventajas convincentes:
- Plataforma Unificada para IA: MyScaleDB agiliza los flujos de trabajo de IA al gestionar y procesar de manera fluida tanto datos estructurados como vectorizados dentro de una única plataforma unificada. Esto elimina la necesidad de tuberías de datos complejas y simplifica los procesos de desarrollo.
- Rendimiento Intransigente: Aprovechando una arquitectura de base de datos OLAP de vanguardia, MyScaleDB ofrece un rendimiento excepcional para operaciones en datos vectorizados. Esta arquitectura permite una ejecución de consultas extremadamente rápida, lo que la hace ideal para cargas de trabajo de IA exigentes.
- Simplicidad Potenciada por SQL: MyScaleDB adopta la universalidad de SQL, lo que permite a los desarrolladores interactuar con la base de datos utilizando un lenguaje familiar y ampliamente adoptado. Esto elimina la necesidad de aprender lenguajes de consulta especializados, acelerando los ciclos de desarrollo y aumentando la productividad.
- Indexación MSTG para Búsqueda Mejorada: MyScaleDB utiliza el algoritmo Multi-Scale Tree Graph (MSTG) (opens new window), un algoritmo de indexación avanzado (opens new window) diseñado para una alta densidad de datos y un rendimiento de búsqueda optimizado. MSTG destaca tanto en búsquedas vectoriales básicas como en búsquedas vectoriales filtradas (opens new window), asegurando una recuperación rápida y precisa de información relevante.
# Qdrant
Qdrant es otra base de datos vectorial contemporánea. También es de código abierto y está disponible tanto en Docker como en la nube. Algunas de las características de Qdrant son:
- Compresión Avanzada: Qdrant utiliza cuantización binaria (opens new window), que convierte cualquier vector de incrustación numérica en un vector de valores booleanos. Proporciona un rendimiento de búsqueda hasta 40 veces mejor.
- Soporte de Multitenencia: Tener una única colección con particionamiento basado en carga útil se llama multitenencia (opens new window). Qdrant lo admite para compartir instancias entre múltiples usuarios.
- I/O Uring (opens new window): Qdrant proporciona soporte para
io_uringpara mejorar el rendimiento y combatir la sobrecarga de las llamadas al sistema operativo.
Con una comprensión clara de lo que ofrecen MyScaleDB y Qdrant, ahora nos centraremos en las diferencias clave. Estas distinciones te ayudarán a determinar qué base de datos se ajusta mejor a tus necesidades y prioridades específicas, desde el rendimiento hasta las características únicas.
# Flexibilidad de Alojamiento: Un Aspecto Clave para las Bases de Datos Vectoriales
Al evaluar las soluciones de bases de datos, el alojamiento se convierte en un factor crítico con implicaciones de gran alcance en el rendimiento, la escalabilidad y la facilidad de administración. La opción de alojamiento adecuada garantiza que tu base de datos pueda manejar con elegancia cargas de trabajo fluctuantes, mantener una alta disponibilidad y minimizar la carga administrativa.
En cuanto al alojamiento, tanto MyScaleDB como Qdrant ofrecen versiones de código abierto, soluciones basadas en la nube y soluciones locales. El alojamiento en la nube ofrece tanto niveles gratuitos como de pago, como veremos en detalle a continuación.
# Alojamiento en la Nube
Para MyScaleDB en la nube (opens new window), puedes comenzar con un pod gratuito que admite 5 millones de vectores de 768 dimensiones. Regístrate aquí (opens new window) y consulta MyScaleDB QuickStart (opens new window) para obtener más instrucciones.
Qdrant te ofrece un clúster gratuito de 1 GB para siempre sin costos iniciales. Para comenzar a usar Qdrant, visita la Guía de Inicio Rápido en la Nube (opens new window).
# Local
Para la solución local, la imagen de Docker es una opción general. Podemos lanzar la imagen de MyScaleDB de Docker de la siguiente manera:
docker run --name MyScaleDB --net=host MyScaleDB/MyScaleDB:1.6
Luego, nos conectamos a la base de datos utilizando el cliente ClickHouse:
docker exec -it MyScaleDBdb clickhouse-client
De manera similar, Qdrant también se puede ejecutar localmente utilizando Docker de la siguiente manera:
docker run -p 6333:6333 qdrant/qdrant
# Funcionalidades Principales
Si bien las opciones de alojamiento sientan las bases para la accesibilidad y escalabilidad de la base de datos, son las funcionalidades principales las que realmente diferencian a MyScaleDB y Qdrant. Esta sección analiza las características esenciales de cada plataforma, brindando información sobre cómo manejan las complejidades del procesamiento de datos basado en vectores.
Comprender estas características te ayudará a ver cómo cada base de datos maneja tareas clave en el procesamiento de datos basado en vectores y cuál de ellas podría satisfacer mejor tus necesidades específicas.
# Lenguaje de Consulta y Soporte de API
La elección del lenguaje de consulta y el soporte de API disponibles desempeñan un papel crucial en la productividad del desarrollador y la facilidad de integración. Veamos cómo abordan estos aspectos MyScaleDB y Qdrant:
# Soporte Multi-Lenguaje:
- Qdrant: Qdrant cuenta con un amplio soporte multi-lenguaje, atendiendo a una amplia gama de desarrolladores con SDK para Python (opens new window), Java (opens new window), Go (opens new window), .Net (opens new window), Rust (opens new window) y TypeScript/JavaScript (opens new window). Esta amplia compatibilidad de lenguajes garantiza una integración fluida con varias pilas tecnológicas.
- MyScaleDB: MyScaleDB proporciona SDK para Python, Java, Go y Node.JS (opens new window), ofreciendo un sólido soporte para lenguajes de programación populares.
Si bien ambas bases de datos ofrecen un respetable soporte multi-lenguaje, MyScaleDB se destaca por su singular adopción de SQL. Puedes utilizar consultas SQL tradicionales con MyScaleDB, y funcionarán sin problemas con bases de datos vectoriales o incluso una combinación de bases de datos tradicionales y vectoriales, como esta:
SELECT id, date, label,
distance(data, {target_row_data}) AS dist
FROM default.myscale_search
ORDER BY dist LIMIT 10
El método distance en MyScaleDB calcula la similitud entre vectores midiendo la distancia entre un vector especificado y todos los vectores almacenados en una columna particular.
Nota: Si te gusta trabajar con SQL, definitivamente MyScaleDB será tu elección.
# Tipos de Datos Soportados
La capacidad de manejar diversos tipos de datos es esencial para cualquier base de datos, y las bases de datos vectoriales no son una excepción. Comparemos MyScaleDB y Qdrant en términos de los tipos de datos que admiten:
# Enfoque Flexible de JSON de Qdrant
Qdrant aprovecha la flexibilidad de las cargas útiles JSON, lo que le permite almacenar y consultar una amplia gama de tipos de datos, incluyendo:
- Palabras Clave: Para búsquedas y filtrado basados en texto.
- Enteros y Flotantes: Para datos numéricos y consultas de rango.
- Objetos y Arreglos Anidados: Para representar estructuras de datos complejas.
Este enfoque centrado en JSON proporciona flexibilidad en la modelización de datos y se adapta a diversos casos de uso.
# Versatilidad Potenciada por SQL de MyScaleDB:
MyScaleDB lleva el soporte de tipos de datos un paso más allá al aprovechar su plena compatibilidad con SQL. Esto le permite manejar no solo datos vectoriales, sino también una amplia variedad de tipos de datos tradicionales, incluyendo:
- Datos Estructurados: Tipos de datos relacionales tradicionales como enteros, flotantes, cadenas, fechas, etc.
- JSON: Para manejar datos semi-estructurados y objetos anidados.
- Datos Geoespaciales: Para consultas basadas en ubicación y análisis espacial.
- Datos de Series Temporales: Para almacenar y analizar datos con marca de tiempo.
La capacidad de MyScaleDB para manejar tanto datos vectoriales como diversos tipos de datos tradicionales dentro de una sola plataforma ofrece una ventaja significativa. Este enfoque unificado simplifica la gestión de datos, elimina los silos de datos y permite consultas potentes que abarcan diferentes tipos de datos.
A continuación se muestra un ejemplo de tabla que muestra la variedad de columnas que MyScaleDB puede manejar, incluidos los datos vectoriales.
CREATE TABLE default.wiki_abstract_mini(
`id` UInt64,
`body` String,
`title` String,
`url` String,
`body_vector` Array(Float32),
CONSTRAINT check_length CHECK length(body_vector) = 768
)
ENGINE = MergeTree
ORDER BY id
SETTINGS index_granularity = 128;
Este comando SQL crea una tabla con datos estructurados y vectorizados, impone un tamaño de vector de 768 y optimiza las consultas ordenándolas por id.
TL;DR: Ambas bases de datos admiten de manera efectiva una amplia gama de tipos de datos numéricos y de texto, pero MyScaleDB va más allá con su compatibilidad avanzada con SQL, sus capacidades OLAP potentes y su soporte integral para estructuras de datos complejas como datos geoespaciales y de series temporales.
# Indexación
Para la indexación, Qdrant utiliza el algoritmo Hierarchical Navigable Small World (HNSW) (opens new window), que, si bien es efectivo para búsquedas vectoriales estándar, tiene dificultades con las operaciones de búsqueda filtradas.
MyScaleDB aborda esta limitación al introducir el algoritmo Multi-Scale Tree Graph (MSTG). MSTG combina el agrupamiento jerárquico de árboles con la búsqueda basada en grafos, mejorando significativamente la velocidad y el rendimiento de recuperación. Esto lo hace altamente eficiente tanto para búsquedas vectoriales estándar como para búsquedas vectoriales filtradas complejas.
Por cierto, tanto MyScaleDB como Qdrant admiten búsqueda de múltiples vectores.
Nota: MSTG supera a los algoritmos de indexación contemporáneos, lo que le brinda a MyScaleDB una ventaja significativa tanto en búsquedas vectoriales estándar como en búsquedas vectoriales filtradas.
# Búsqueda de Texto Completo
La búsqueda de texto completo (opens new window) está disponible tanto en Qdrant (a partir de la versión 0.10.0) como en MyScaleDB. Qdrant implementa la búsqueda de texto completo mediante el soporte de tokenización e indexación de campos de texto, lo que le permite buscar y filtrar en función de palabras o frases específicas.

MyScaleDB, por otro lado, utiliza la biblioteca Tantivy, que aprovecha el algoritmo BM25 para una recuperación precisa y eficiente de documentos.
# Ejemplo de Qdrant
Aquí tienes un ejemplo de cómo crear un índice de texto completo (generalmente llamado índice de carga útil en su terminología) en Qdrant,
from qdrant_client import QdrantClient, models
client = QdrantClient(url="<http://localhost:6333>")
client.create_payload_index(
collection_name="{collection_name}",
field_name="name_of_the_field_to_index",
field_schema=models.TextIndexParams(
type="text",
tokenizer=models.TokenizerType.WORD,
min_token_len=2,
max_token_len=15,
lowercase=True,
),
)
Este fragmento de código en Qdrant configura un índice de texto mediante la tokenización de un campo de texto en función de parámetros como la longitud de las palabras y la sensibilidad a las mayúsculas y minúsculas.
# Ejemplo de MyScaleDB
En el ejemplo de MyScaleDB, estamos utilizando el tokenizador stem con palabras de parada en inglés, lo que puede mejorar la precisión de la búsqueda al centrarse en la forma raíz de las palabras. En este caso, estamos utilizando la tabla en_wiki_abstract (se ha utilizado a lo largo de este ejemplo (opens new window) si deseas verlo en detalle).
ALTER TABLE default.en_wiki_abstract
ADD INDEX body_idx (body)
TYPE fts('{"body":{"tokenizer":{"type":"stem", "stop_word_filters":["english"]}}}');
Nota: No hay muchas diferencias en términos de búsqueda de texto completo, ya que ambas ofrecen soluciones efectivas.
# Búsqueda Filtrada
MyScaleDB optimiza la búsqueda vectorial filtrada a través de su algoritmo MSTG, junto con técnicas de máscara de bits. Esta combinación, junto con las capacidades avanzadas de indexación y procesamiento paralelo de ClickHouse, permite que MyScaleDB maneje eficientemente conjuntos de datos grandes. Al utilizar una estrategia de prefiltrado, MyScaleDB reduce el conjunto de datos antes de la búsqueda vectorial principal, asegurando que solo se procesen los datos más relevantes, lo que mejora significativamente tanto el rendimiento como la precisión.
Qdrant utiliza una versión filtrable del algoritmo HNSW (opens new window), que aplica filtros durante el proceso de búsqueda para garantizar que solo se consideren los nodos relevantes en el grafo de búsqueda.
# Búsqueda Geoespacial
Tanto MyScaleDB como Qdrant admiten la búsqueda geoespacial. MyScaleDB tiene una serie de funciones geoespaciales (opens new window) para admitir la búsqueda geoespacial. Por ejemplo, esta función encuentra la distancia entre dos puntos en la Tierra (tomada como una variedad):
greatCircleDistance(lon1Deg, lat1Deg, lon2Deg, lat2Deg)
# Integración de APIs de LLM
Probablemente, la mayor aplicación de las búsquedas vectoriales sean los LLM y los RAG. Tanto Qdrant como MyScaleDB tienen su respaldo al admitir varias integraciones de APIs de LLM como LlamaIndex (opens new window), LangChain (opens new window) y Hugging Face (opens new window).
# Precios
Tanto Qdrant como MyScaleDB adoptan un modelo de precios freemium, ofreciendo niveles gratuitos adecuados para experimentación y proyectos más pequeños, junto con niveles pagados más potentes para cargas de trabajo exigentes. Es importante destacar que ambas plataformas permiten a los usuarios explorar sus ofertas gratuitas sin requerir información de tarjeta de crédito.
# Nivel gratuito
- Qdrant: Proporciona una capacidad de almacenamiento de 1 GB en su nivel gratuito.
- MyScaleDB: Ofrece un nivel gratuito significativamente más generoso, permitiendo el almacenamiento de hasta 5 millones de vectores de 768 dimensiones. Para poner esto en perspectiva, lograr esta capacidad de almacenamiento en la plataforma de Qdrant requeriría un plan de pago que costaría aproximadamente $275 al mes.
# Nivel pagado
Para el nivel pagado, tanto Qdrant como MyScaleDB ofrecen los 3 tipos de alojamiento en la nube: GCP, Azure y AWS. Por lo general, Azure y AWS tienen costos más altos, mientras que GCP es la opción más económica disponible.
Para el nivel pagado, compararemos el alojamiento de Qdrant en GCP con MyScaleDB. Para MyScaleDB, consideraremos tanto opciones optimizadas para capacidad como para rendimiento, utilizando un tamaño de vector constante de 768 dimensiones para todas las comparaciones.
| Capacidad | Qdrant ($)/hora | Nodos | MyScaleDB Optimizado para Capacidad ($)/hora | Pods | MyScaleDB Optimizado para Rendimiento ($)/hora | Pods |
|---|---|---|---|---|---|---|
| 10 Millones | 0.75 | 1 | 0.09 | 1 | 0.33 | 2 |
| --- | --- | --- | --- | --- | --- | --- |
| 20 Millones | 1.5 | 1 | 0.19 | 2 | 0.67 | 4 |
| 40 Millones | 3.02 | 2 | 0.38 | 4 | 1.33 | 8 |
| 80 Millones | 4.52 | 3 | 0.76 | 8 | 2.67 | 16 |
| 160 Millones | 9.05 | 6 | 1.51 | 16 | 5.33 | 32 |
| 320 Millones | 16.58 | 11 | 3.02 | 32 | 10.66 | 64 |
En los pods optimizados para capacidad de MyScaleDB, obtenemos 10 millones de vectores por pod, mientras que la configuración optimizada para rendimiento proporciona una latencia más baja y, como resultado, tenemos más pods para el almacenamiento. Podemos ver que incluso los pods optimizados para rendimiento de MyScaleDB son mucho más económicos que la configuración más económica de Qdrant.
Otra tendencia que observamos es que MyScaleDB tiene un factor de escalado lineal, mientras que Qdrant tiene un patrón más asimétrico, como se puede ver en este gráfico.
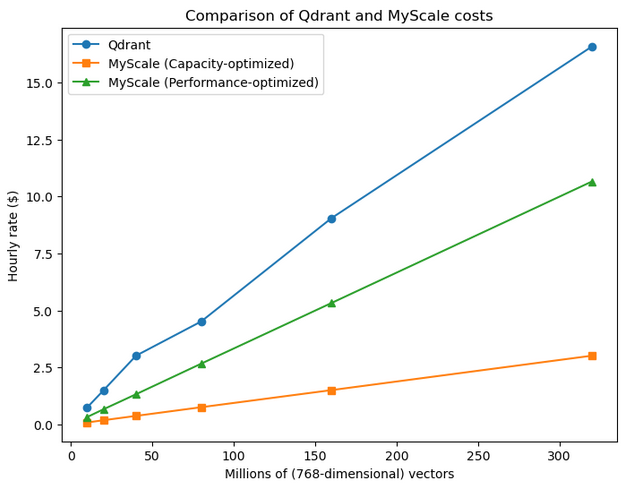
Nota: En cuanto a los precios, tanto en el nivel gratuito como en el nivel pagado, no hay comparación con MyScaleDB.
# Comparación de Rendimiento
Aunque las comparaciones de características anteriores proporcionan información valiosa, las pruebas de rendimiento objetivas ofrecen una comprensión más concreta de las capacidades de MyScaleDB y Qdrant.
# Rendimiento (Consultas por Segundo)
El rendimiento, generalmente medido en Consultas por Segundo (QPS), refleja directamente la capacidad de una base de datos para manejar solicitudes concurrentes de manera eficiente. Los resultados de las pruebas demuestran claramente la superioridad de MyScaleDB en términos de rendimiento en comparación con Qdrant. Además, la brecha de rendimiento se amplía significativamente a medida que aumenta el número de hilos concurrentes, lo que destaca la excepcional escalabilidad de MyScaleDB bajo cargas de trabajo pesadas.
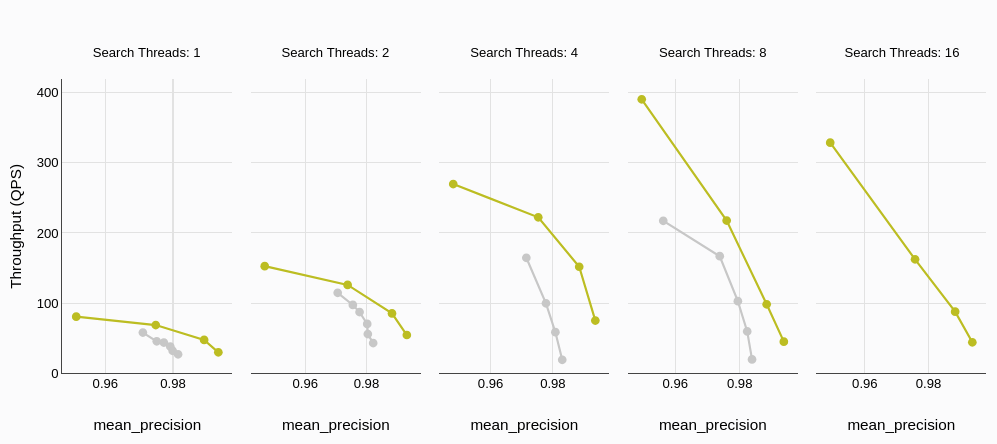
# Latencia Promedio de Consulta
La latencia promedio de consulta, medida en milisegundos o segundos, representa el tiempo promedio que tarda una base de datos en procesar una consulta y devolver resultados. Una menor latencia se traduce en tiempos de respuesta más rápidos, un factor crítico en aplicaciones en tiempo real y para la experiencia del usuario.
Los resultados de las pruebas muestran consistentemente que MyScaleDB logra una latencia promedio de consulta significativamente menor en comparación con Qdrant. Esta tendencia se mantiene con diferentes cantidades de hilos, lo que indica la capacidad de MyScaleDB para mantener una baja latencia incluso bajo alta concurrencia.
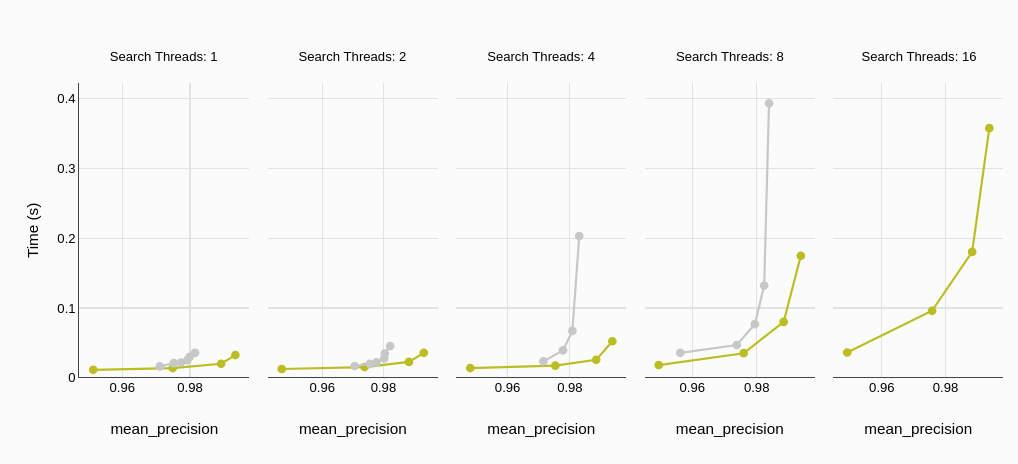
Observamos tendencias similares en la latencia P95 (percentil 95), lo que refuerza la baja latencia de MyScaleDB para aplicaciones prácticas.
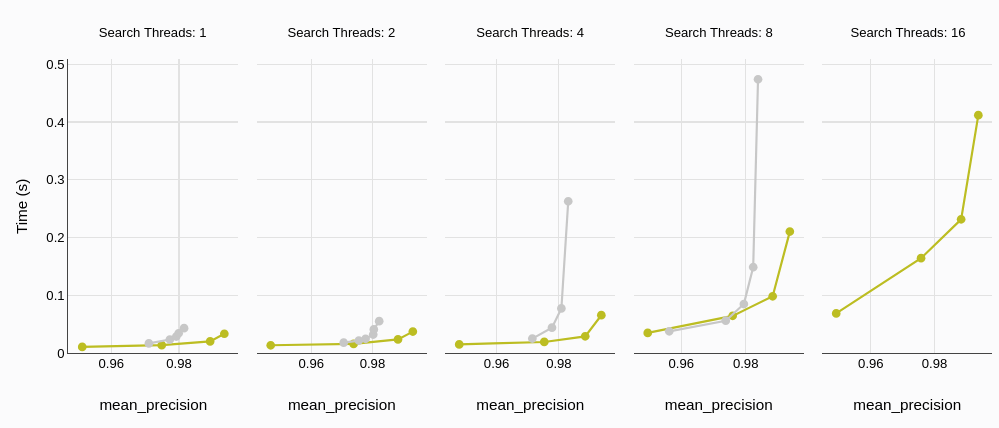
# Tiempo de Construcción
MyScaleDB (en verde; ese pequeño punto en la esquina inferior derecha) no solo tiene mejor precisión, sino que lo hace casi 5 veces más rápido.
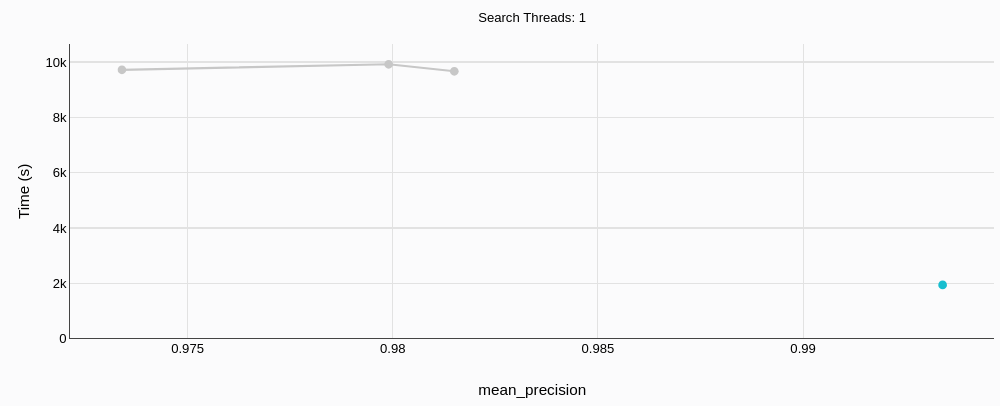
# Costo Mensual
La relación costo-efectividad juega un papel crucial al elegir la solución de base de datos adecuada. Como se destaca en la sección de precios, MyScaleDB generalmente ofrece una opción más asequible en comparación con Qdrant, especialmente al considerar su generoso nivel gratuito.
Este gráfico lo explica en términos de los hilos de búsqueda. Podemos ver que el costo de Qdrant (gris) exhibe una tendencia ascendente pronunciada a medida que aumenta el número de hilos de búsqueda. En contraste, MyScaleDB mantiene un perfil de costo significativamente más bajo, permaneciendo relativamente estable incluso con un mayor número de hilos.
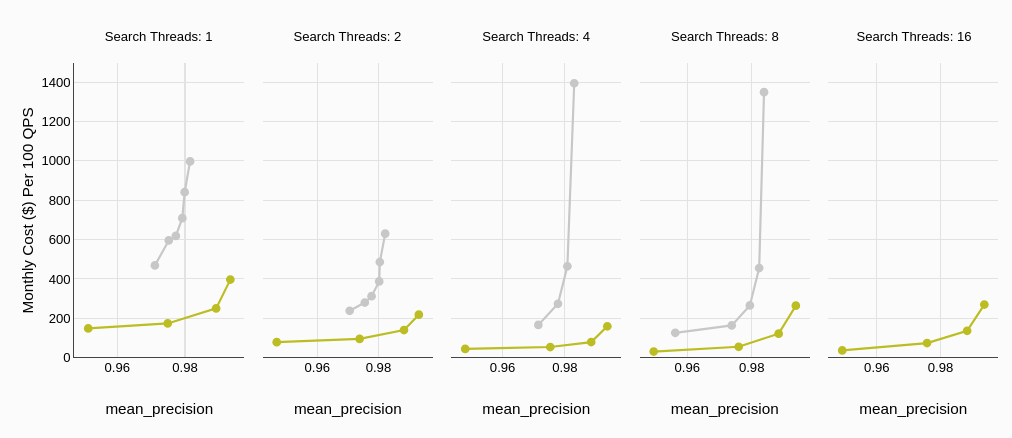

# Conclusión
Tanto Qdrant como MyScaleDB se destacan como contendientes prominentes en el panorama en rápida evolución de las bases de datos vectoriales. Qdrant, con su mayor presencia en el mercado, se beneficia de una adopción más amplia y ofrece características atractivas como el soporte para vectores dispersos y técnicas eficientes de cuantización.
Sin embargo, MyScaleDB emerge como una alternativa poderosa, con ventajas significativas en áreas clave:
- Rendimiento y escalabilidad: MyScaleDB supera constantemente a Qdrant en las pruebas, mostrando un rendimiento superior, menor latencia e impresionante escalabilidad para cargas de trabajo exigentes.
- Relación costo-efectividad: MyScaleDB ofrece una propuesta de valor convincente con su generoso nivel gratuito y costos significativamente más bajos en los planes de pago, especialmente para escenarios de alta concurrencia.
- Gestión unificada de datos: La capacidad de MyScaleDB para gestionar tanto datos vectoriales como diversos tipos de datos tradicionales en una única plataforma simplifica los flujos de datos y habilita consultas cruzadas de datos potentes.
- Simplicidad impulsada por SQL: Aprovechando la familiaridad y expresividad de SQL, MyScaleDB agiliza el desarrollo y permite a los usuarios interactuar con datos vectoriales utilizando un lenguaje ampliamente adoptado.
En última instancia, la elección óptima depende de tus requisitos y prioridades específicos. Si el soporte para múltiples lenguajes y características especializadas como el manejo de vectores dispersos son primordiales, Qdrant podría ser una opción adecuada. Sin embargo, si el rendimiento, la escalabilidad, la relación costo-efectividad y la gestión unificada de datos son consideraciones críticas, MyScaleDB se presenta como la opción ganadora.
Te animamos a evaluar cuidadosamente tus necesidades y aprovechar los conocimientos de esta comparación para tomar una decisión informada que se alinee con tus requisitos únicos de procesamiento de datos y aplicaciones.



