
En el mundo moderno, los modelos de lenguaje grandes (LLMs, por sus siglas en inglés) han transformado el mundo con su impresionante capacidad para producir textos que imitan el texto escrito por humanos. Estos modelos son altamente hábiles en tareas como crear nuevo contenido y dar respuestas inteligentes, impulsando aún más el campo de la IA. Son entrenados con grandes cantidades de datos, pero solo conocen lo que está en esos datos, lo que dificulta que proporcionen la información más reciente. Esto puede llevar a respuestas desactualizadas o información incorrecta, conocida como alucinaciones de información. Para abordar estos problemas, se ha desarrollado un marco dinámico llamado Retrieval-Augmented Generation (RAG). Combina las fortalezas de los LLMs tradicionales con los sistemas de recuperación, ampliando los casos de uso de estos modelos.
# ¿Qué es RAG?
RAG es una mejora estratégica diseñada para elevar el rendimiento de los LLMs. Al incorporar un paso que recupera información durante la generación de texto, RAG asegura que las respuestas del modelo sean precisas y actualizadas. RAG ha evolucionado significativamente, lo que ha llevado al desarrollo de dos modos principales:
- Naive RAG: Esta es la versión más básica, donde el sistema simplemente recupera la información relevante de una base de conocimientos y se la proporciona directamente al LLM para generar la respuesta.
- Advanced RAG: Esta versión va un paso más allá. Agrega pasos de procesamiento adicionales antes y después de la recuperación para refinar la información recuperada. Estos pasos mejoran la calidad y precisión de la respuesta generada, asegurando que se integre perfectamente con la salida del modelo.
# Naive RAG
Naive RAG es la versión inicial más diseñada del ecosistema RAG. Es un método bastante sencillo para combinar datos de recuperación y modelos LLM para proporcionar al usuario una respuesta eficiente.
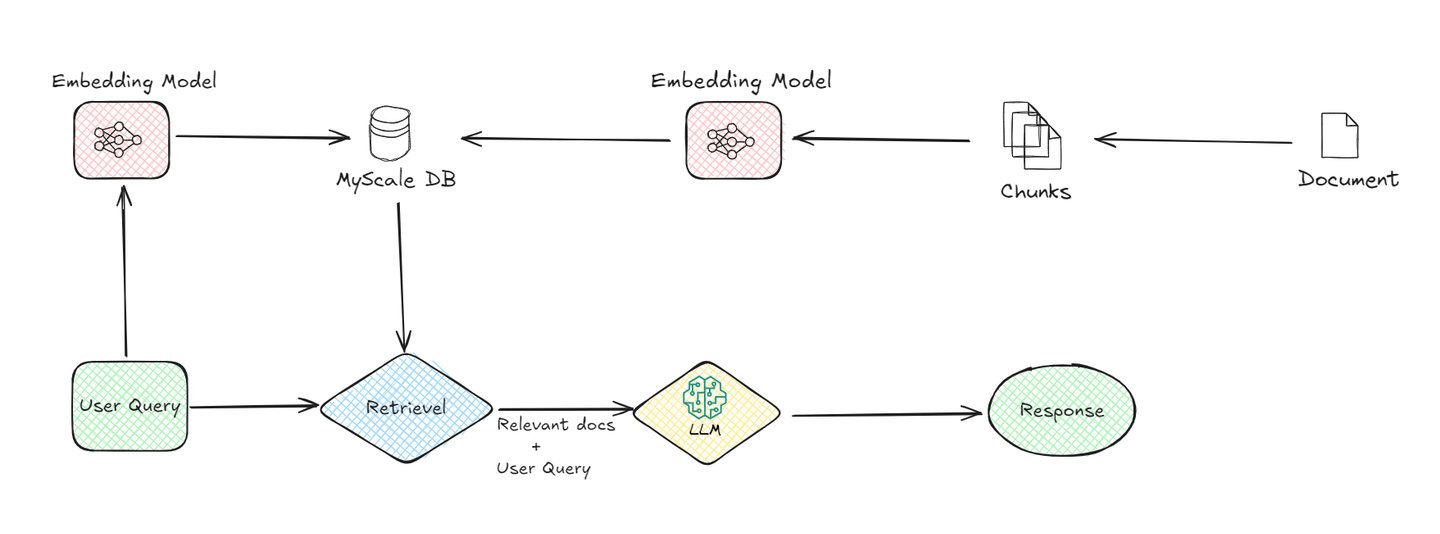
Un sistema básico tiene los siguientes componentes:
# 1. Fragmentación de documentos:
El proceso comienza dividiendo los documentos en fragmentos más pequeños. Esto es esencial porque los fragmentos más pequeños son más fáciles de gestionar y procesar. Por ejemplo, cuando tienes un documento largo, se divide en segmentos, lo que facilita que el sistema recupere información relevante más adelante.
# 2. Modelo de incrustación:
El modelo de incrustación es una parte crítica del sistema RAG. Convierte tanto los fragmentos de documentos como la consulta del usuario en una forma numérica, a menudo llamada incrustaciones. Esta conversión es necesaria porque las computadoras entienden mejor los datos numéricos. El modelo de incrustación utiliza técnicas avanzadas de aprendizaje automático para representar el significado del texto de manera matemática. Por ejemplo, cuando un usuario hace una pregunta, el modelo transforma esta pregunta en un conjunto de números que capturan la semántica de la consulta.
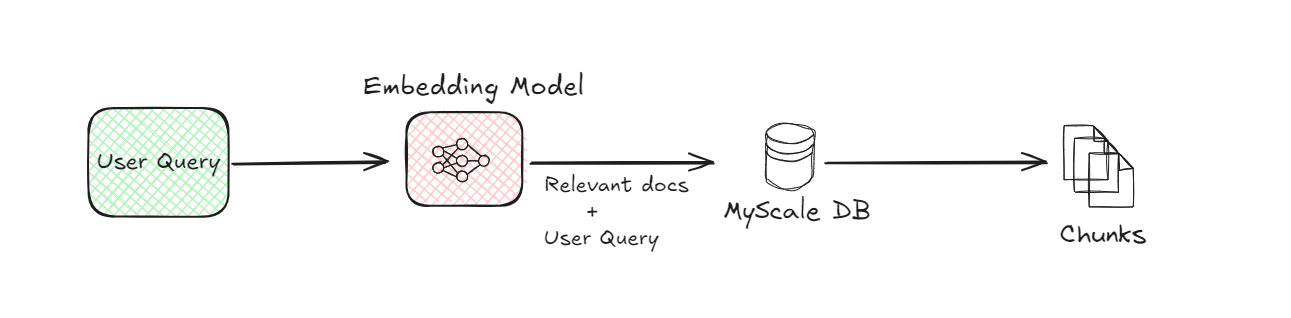
# 3. Base de datos vectorial (MyScaleDB):
Una vez que los fragmentos de documentos se convierten en incrustaciones, se almacenan en una base de datos vectorial como MyScaleDB. Las bases de datos vectoriales están diseñadas para almacenar y recuperar eficientemente estas incrustaciones. Cuando un usuario envía una consulta, el sistema utiliza la base de datos vectorial para encontrar los fragmentos de documentos más relevantes comparando las incrustaciones de la consulta con las almacenadas en la base de datos. Esta comparación ayuda a identificar los fragmentos que son más similares a lo que el usuario está preguntando.
# 4. Recuperación:
Después de que la base de datos vectorial identifica los fragmentos de documentos relevantes, se recuperan. Este proceso de recuperación es crucial porque reduce la información que se utilizará para generar la respuesta final. Básicamente, actúa como un filtro, asegurando que solo se pase a la siguiente etapa los datos más relevantes.
# 5. LLM (Modelo de Lenguaje Grande):
El LLM se encarga una vez que se recuperan los fragmentos relevantes. Su tarea es comprender la información recuperada y generar una respuesta coherente a la consulta del usuario. El LLM utiliza la consulta del usuario y los fragmentos recuperados para proporcionar una respuesta que no solo sea relevante, sino también contextualmente apropiada. Este modelo es responsable de interpretar los datos y formular una respuesta en lenguaje natural que el usuario pueda entender fácilmente.
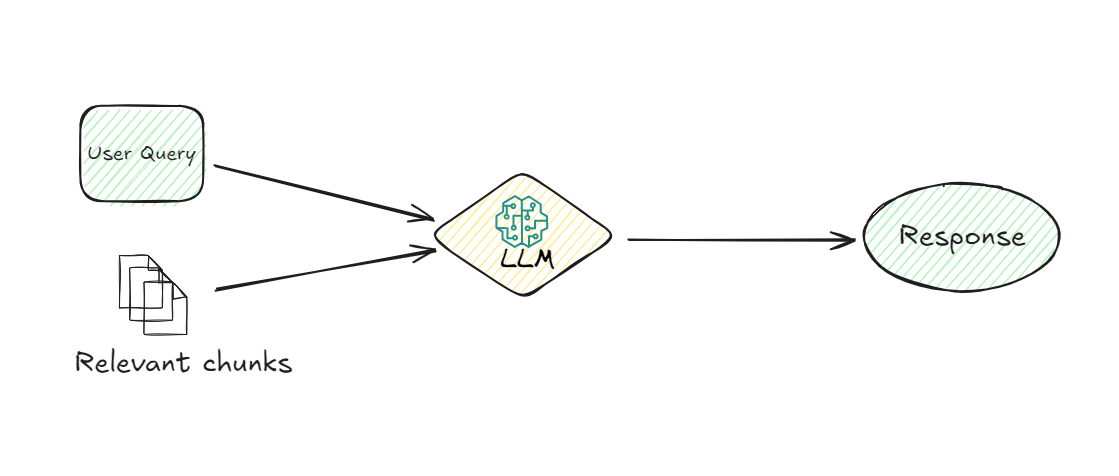
# 6. Generación de respuesta:
Finalmente, el sistema genera una respuesta basada en la información procesada por el LLM. Esta respuesta se entrega al usuario, proporcionándole la información que estaba buscando de manera clara y concisa.
Al comprender el flujo de datos desde la consulta del usuario hasta la respuesta final, podemos apreciar cómo cada componente del sistema Naive RAG desempeña un papel fundamental para garantizar que el usuario reciba información precisa y relevante.
# Ventajas
- Simplicidad de implementación: RAG es fácil de configurar, ya que integra directamente la recuperación con la generación, reduciendo la complejidad involucrada en la mejora de los modelos de lenguaje sin necesidad de modificaciones o componentes adicionales complicados.
- No requiere ajuste fino: Una de las ventajas significativas de RAG es que no requiere el ajuste fino del LLM. Esto no solo ahorra tiempo y reduce los costos operativos, sino que también permite una implementación más rápida de los sistemas RAG.
- Precisión mejorada: Al aprovechar información externa y actualizada, Naive RAG mejora significativamente la precisión de las respuestas generadas. Esto garantiza que las salidas no solo sean relevantes, sino que también reflejen los datos más recientes disponibles.
- Reducción de alucinaciones: RAG mitiga el problema común de los LLMs que generan información incorrecta o fabricada al basar las respuestas en datos reales y factuales recuperados durante el proceso.
- Escalabilidad y flexibilidad: La simplicidad de Naive RAG facilita su implementación en diferentes aplicaciones, ya que se puede adaptar sin cambios significativos en los componentes de recuperación o generación existentes. Esta flexibilidad permite su implementación en varios dominios con una personalización mínima.
# Desventajas
- Procesamiento limitado: La información recuperada se utiliza directamente, sin un procesamiento o refinamiento adicional, lo que puede generar problemas de coherencia en las respuestas generadas.
- Dependencia de la calidad de la recuperación: La calidad de la salida final depende en gran medida de la capacidad del módulo de recuperación para encontrar la información más relevante. Una recuperación deficiente puede dar lugar a respuestas menos precisas o relevantes.
- Problemas de escalabilidad: A medida que el conjunto de datos crece, el proceso de recuperación puede volverse más lento, lo que afecta el rendimiento general y el tiempo de respuesta.
- Limitaciones de contexto: Naive RAG puede tener dificultades para comprender el contexto más amplio de una consulta, lo que puede llevar a respuestas que, aunque sean precisas, no se alineen completamente con la intención del usuario.
Al examinar estas ventajas y desventajas, podemos comprender de manera integral dónde sobresale Naive RAG y dónde puede enfrentar desafíos. Esto allanará el camino para mejoras y creará la oportunidad de desarrollar Advanced RAG.
# Advanced RAG
Sobre la base de Naive RAG, Advanced RAG introduce un nivel de sofisticación al proceso. A diferencia de Naive RAG, que incorpora directamente la información recuperada, Advanced RAG involucra pasos de procesamiento adicionales que optimizan la relevancia y la calidad general de la respuesta.
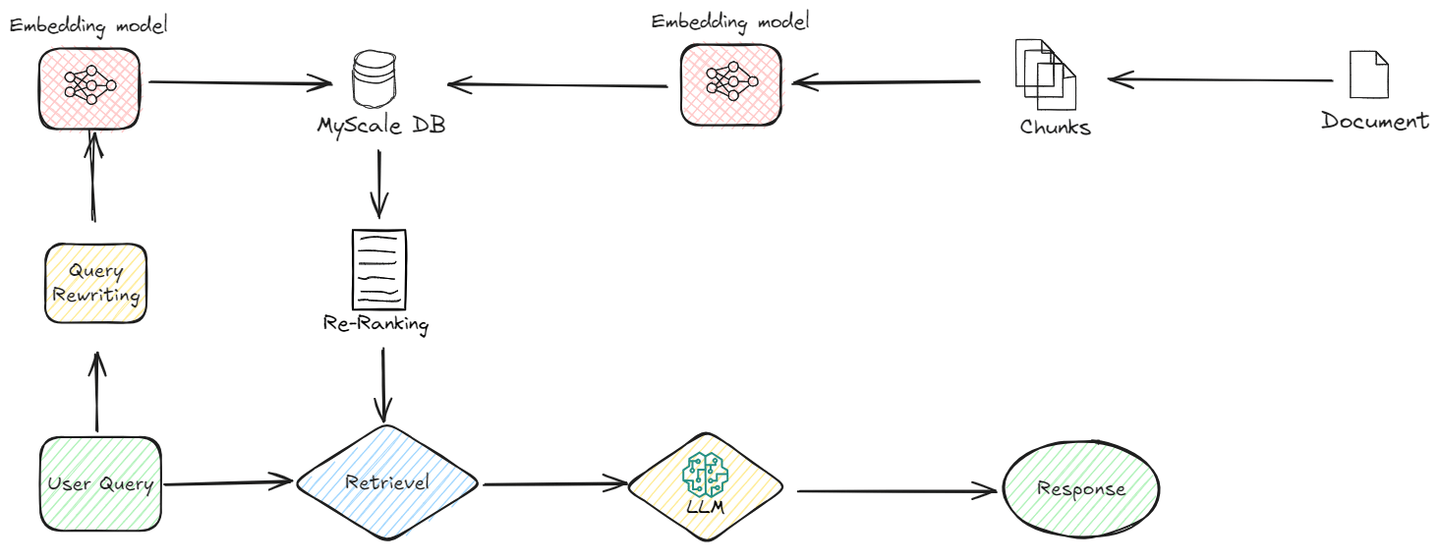
Veamos cómo funciona:
# Optimizaciones previas a la recuperación
En Advanced RAG, el proceso de recuperación se refina incluso antes de que se produzca la recuperación real. Esto es lo que sucede en esta fase:
# Mejoras en la indexación
Los métodos de indexación desempeñan un papel vital en la organización y recuperación eficiente de datos en las bases de datos. Los métodos de indexación tradicionales, como los árboles B y la indexación hash, se han utilizado ampliamente para este propósito. Sin embargo, la velocidad de búsqueda de estos algoritmos disminuye a medida que aumenta el tamaño de los datos. Por lo tanto, necesitamos métodos de indexación más eficientes para conjuntos de datos más grandes. El algoritmo de indexación MSTG (Multi-Strategy Tree-Graph) de MyScale es un ejemplo destacado de este avance. Este algoritmo supera a otros métodos de indexación en términos de velocidad y rendimiento.
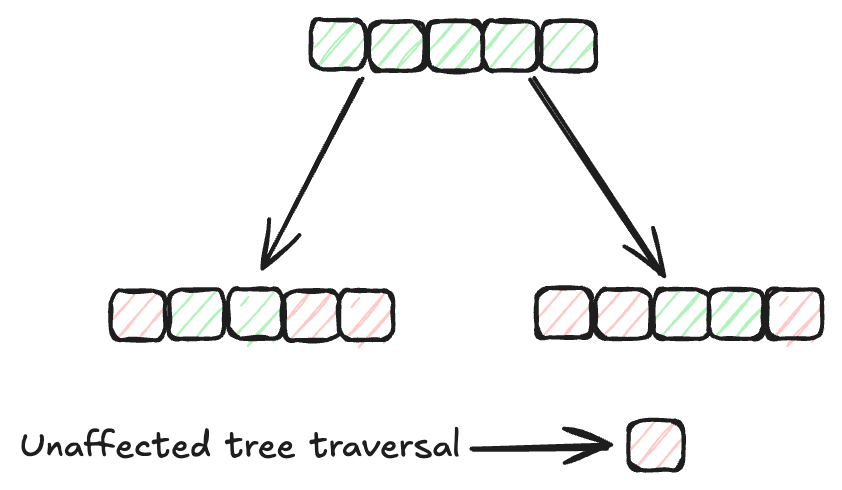
MSTG combina las fortalezas de las estructuras de gráficos jerárquicos y de árboles. Por lo general, los algoritmos de gráficos son más rápidos para búsquedas sin filtrar, pero pueden no ser eficientes para búsquedas filtradas. Por otro lado, los algoritmos de árbol sobresalen en búsquedas filtradas, pero son más lentos para las no filtradas. Al combinar estos dos enfoques, MSTG garantiza un alto rendimiento y precisión tanto para búsquedas sin filtrar como para búsquedas filtradas, lo que lo convierte en una opción sólida para una variedad de escenarios de búsqueda.
# Reescritura de consultas
Antes de que comience el proceso de recuperación, la consulta original del usuario se somete a varias mejoras para mejorar su precisión y relevancia. Este paso garantiza que el sistema de recuperación recupere la información más pertinente. Aquí se emplean técnicas como la reescritura, expansión y transformación de consultas. Por ejemplo, si la consulta del usuario es demasiado amplia, la reescritura de consultas puede refinarla agregando más contexto o términos específicos, mientras que la expansión de consultas puede agregar sinónimos o términos relacionados para capturar una gama más amplia de documentos relevantes.
# Incrustaciones dinámicas
En Naive RAG, se puede utilizar un solo modelo de incrustación para todos los tipos de datos, lo que puede generar ineficiencias. Sin embargo, Advanced RAG ajusta y adapta las incrustaciones en función de la tarea o dominio específico. Esto significa que el modelo de incrustación se entrena o adapta para capturar mejor la comprensión contextual requerida para un tipo particular de consulta o conjunto de datos.
Al utilizar incrustaciones dinámicas, el sistema se vuelve más eficiente y preciso, ya que las incrustaciones están más alineadas con los matices de la tarea específica en cuestión.
# Búsqueda híbrida
Advanced RAG también aprovecha un enfoque de búsqueda híbrida, que combina diferentes estrategias de búsqueda para mejorar el rendimiento de la recuperación. Esto puede incluir búsquedas basadas en palabras clave, búsquedas semánticas y búsquedas neuronales. Por ejemplo, MyScaleDB admite la búsqueda de vectores filtrados y la búsqueda de texto completo, lo que permite el uso de consultas SQL complejas debido a su sintaxis compatible con SQL. Este enfoque híbrido garantiza que el sistema pueda recuperar información con un alto grado de relevancia, independientemente de la naturaleza de la consulta.
# Procesamiento posterior a la recuperación
Después del proceso de recuperación, Advanced RAG no se detiene ahí. Procesa aún más los datos recuperados para garantizar la máxima calidad y relevancia en la salida final.
# Reordenamiento
Después del proceso de recuperación, Advanced RAG realiza un paso adicional para refinar la información. Este paso, conocido como reordenamiento, garantiza que los datos más relevantes y útiles se prioricen. Inicialmente, el sistema recupera varias piezas de información que pueden estar relacionadas con la consulta del usuario. Sin embargo, no toda esta información es igualmente valiosa. El reordenamiento ayuda a clasificar estos datos en función de factores adicionales, como qué tan cerca se ajusta a la consulta y qué tan bien se adapta al contexto.
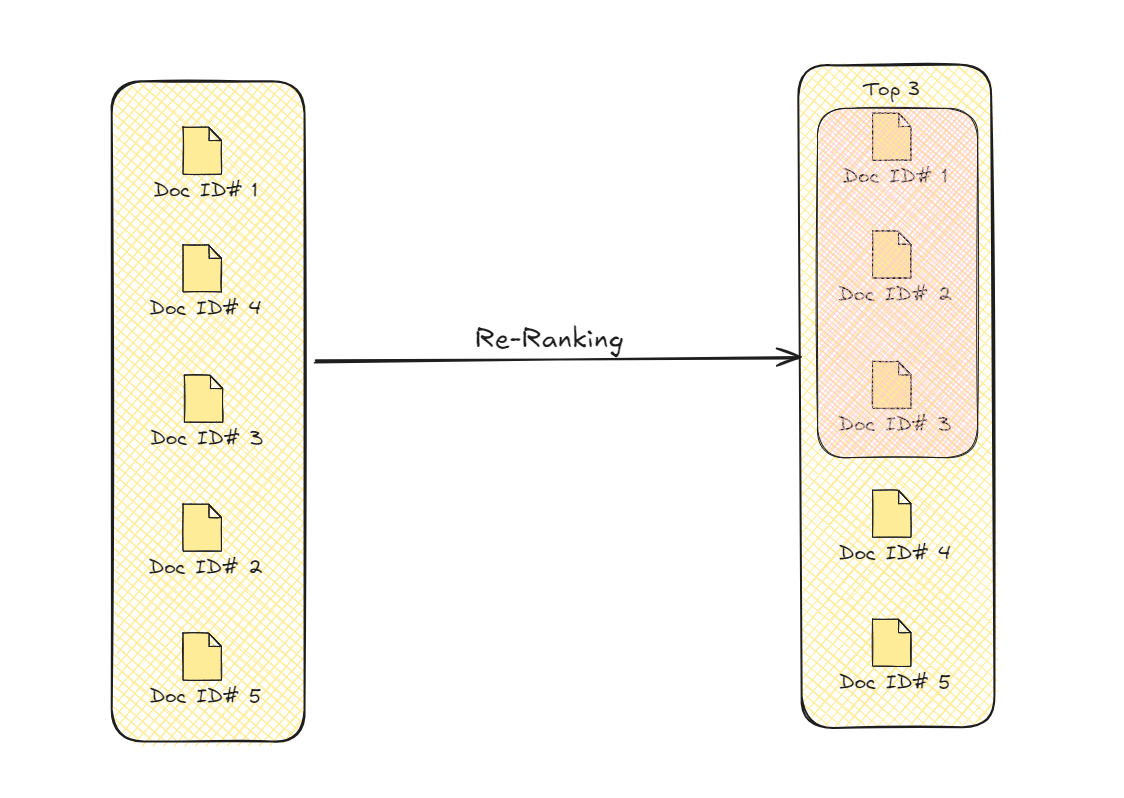
Al volver a evaluar el contenido recuperado, el reordenamiento coloca las piezas más relevantes en la parte superior. Esto garantiza que la respuesta generada no solo sea precisa, sino también coherente y aborde directamente las necesidades del usuario. El proceso utiliza varios criterios, como la relevancia semántica y la adecuación contextual, para reordenar la información. Esta refinación conduce a una respuesta final más enfocada y precisa, mejorando la calidad general de la salida.
# Compresión de contexto
Después de filtrar los documentos relevantes, incluso con el uso de un algoritmo de reordenamiento, puede haber datos irrelevantes dentro de esos documentos filtrados para responder la consulta del usuario. El proceso de eliminar o eliminar estos datos irrelevantes es lo que llamamos compresión de contexto. Este paso se aplica justo antes de pasar los documentos relevantes al LLM, asegurando que el LLM solo reciba la información más relevante, lo que le permite ofrecer los mejores resultados posibles.
# Ventajas
Para comprender mejor las diferencias entre estos dos enfoques, exploremos las ventajas específicas que ofrece Advanced RAG en comparación con Naive RAG.
- Mejor relevancia con reordenamiento: El reordenamiento se asegura de que la información más relevante aparezca primero, mejorando tanto la precisión como el flujo de la respuesta final.
- Incrustaciones dinámicas para un mejor contexto: Las incrustaciones dinámicas se personalizan para tareas específicas, lo que ayuda al sistema a comprender y responder de manera más precisa a diferentes consultas.
- Recuperación más precisa con búsqueda híbrida: La búsqueda híbrida utiliza múltiples estrategias para encontrar datos de manera más efectiva, garantizando una mayor relevancia y precisión en los resultados.
- Respuestas eficientes con compresión de contexto: La compresión de contexto elimina detalles innecesarios, lo que hace que el proceso sea más rápido y produce respuestas más enfocadas y de alta calidad.
- Mejor comprensión de la consulta del usuario: Al reescribir y expandir las consultas antes de la recuperación, Advanced RAG garantiza que las consultas del usuario se comprendan completamente, lo que conduce a resultados más precisos y relevantes.
Advanced RAG marca una mejora importante en la calidad de las respuestas generadas por los modelos de lenguaje. Al agregar una etapa de refinamiento, aborda de manera efectiva los problemas clave que se encuentran en Naive RAG, como la coherencia y la relevancia.
# Análisis comparativo: Naive RAG vs. Advanced RAG
Al comparar Naive RAG y Advanced RAG, podemos observar cómo Advanced RAG amplía el marco básico de Naive RAG. Introduce mejoras clave que mejoran la precisión, eficiencia y calidad general de la recuperación.
| Criterio | Naive RAG | Advanced RAG |
|---|---|---|
| Precisión y relevancia | Proporciona una precisión básica utilizando la información recuperada. | Mejora la precisión y relevancia con un filtrado avanzado, reordenamiento y un mejor uso del contexto. |
| Recuperación de datos | Utiliza verificaciones básicas de similitud, lo que puede omitir algunos datos relevantes. | Optimiza la recuperación con técnicas como la búsqueda híbrida y las incrustaciones dinámicas, asegurando datos altamente relevantes y precisos. |
| Optimización de consultas | Maneja las consultas de manera directa sin muchas mejoras. | Mejora el manejo de consultas con métodos como la reescritura de consultas y la adición de metadatos, lo que hace que la recuperación sea más precisa. |
| Escalabilidad | Puede volverse menos eficiente a medida que crece el tamaño de los datos, lo que afecta la recuperación. | Diseñado para manejar conjuntos de datos grandes de manera eficiente, utilizando mejores métodos de indexación y recuperación para mantener un rendimiento alto. |
| Recuperación de múltiples etapas | Realiza un solo paso de recuperación, lo que puede omitir datos importantes. | Utiliza un proceso de múltiples etapas, refinando los resultados iniciales con pasos como el reordenamiento y la compresión de contexto para garantizar que las salidas finales sean precisas y relevantes. |

# Conclusión
Al elegir entre Naive RAG y Advanced RAG, considera las necesidades específicas de tu aplicación. Naive RAG es ideal para casos de uso más simples donde la velocidad y la implementación directa son prioridades. Mejora el rendimiento de LLM en escenarios donde la comprensión contextual profunda no es crítica. Por otro lado, Advanced RAG es más adecuado para aplicaciones más complejas, ofreciendo una mayor precisión y coherencia a través de pasos de procesamiento adicionales como un filtrado refinado y reordenamiento, lo que lo convierte en la opción preferida para manejar conjuntos de datos más grandes y consultas complejas.
MyScale eleva aún más estos avances al ofrecer soluciones de recuperación escalables y eficientes. Sus sofisticadas técnicas de indexación y manejo de datos mejoran tanto la velocidad como la precisión de la recuperación de información, respaldando el rendimiento mejorado de los sistemas RAG. Al aprovechar MyScale, los desarrolladores pueden optimizar su uso de los métodos avanzados de RAG, impulsando mejoras en los sistemas de IA y su capacidad para proporcionar información precisa y relevante.



