
Desde el lanzamiento de los Modelos de Lenguaje Grandes (LLMs) y los modelos de chat avanzados, se han utilizado diversas técnicas para extraer las salidas deseadas de estos sistemas de IA. Algunos de estos métodos implican alterar el comportamiento del modelo para que se ajuste mejor a nuestras expectativas, mientras que otros se centran en mejorar cómo consultamos los LLM para extraer información más precisa y relevante.
Las técnicas como Retrieval Augmented Generation (RAG) (opens new window), Prompting (opens new window) y ajuste fino (opens new window) son las más utilizadas. En MyScale, ya hemos discutido en detalle técnicas como RAG (opens new window) y ajuste fino. En el ajuste fino, hemos discutido dos técnicas, ajuste fino utilizando OpenAI (opens new window) y ajuste fino utilizando Hugging Face (opens new window).
Nota:
Si no has leído nuestros blogs sobre RAG y ajuste fino, te recomendamos encarecidamente que los leas antes de comenzar con este.
La discusión de hoy es un poco diferente. Nos estamos moviendo de la exploración a la comparación. Analizaremos los pros y los contras de cada técnica. Esto es importante porque te ayudará a comprender cuándo y cómo utilizar estas técnicas de manera efectiva. Así que comencemos nuestra comparación y veamos qué hace que cada método sea único.
# Ingeniería de Prompts
El prompting es la forma más básica de interactuar con cualquier Modelo de Lenguaje Grande. Es como dar instrucciones. Cuando usas un prompt (opens new window), le estás diciendo al modelo qué tipo de información quieres que te dé. Esto también se conoce como ingeniería de prompts. Es un poco como aprender a hacer las preguntas correctas para obtener las mejores respuestas. Pero hay un límite en cuanto a cuánto puedes obtener de ello. Esto se debe a que el modelo solo puede devolver lo que ya sabe de su entrenamiento (opens new window).
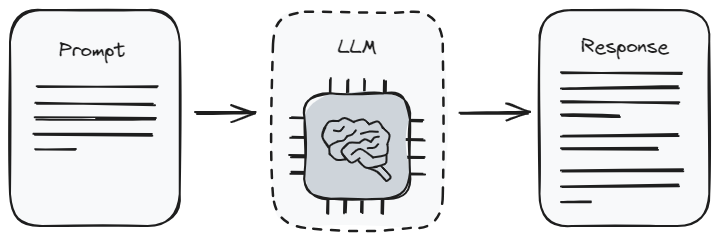
Lo bueno de la ingeniería de prompts es que es bastante sencillo. No necesitas ser un experto en tecnología para hacerlo, lo cual es genial para la mayoría de las personas. Pero dado que depende mucho del aprendizaje original del modelo, es posible que no siempre te proporcione la información más nueva o específica que necesitas. Es mejor cuando estás trabajando con temas generales o cuando solo necesitas una respuesta rápida sin entrar en demasiados detalles.
# Ventajas:
- Facilidad de uso: La ingeniería de prompts es fácil de usar y no requiere habilidades técnicas avanzadas, lo que la hace accesible para un amplio público.
- Rentabilidad: Dado que utiliza modelos pre-entrenados (opens new window), los costos computacionales son mínimos en comparación con el ajuste fino.
- Flexibilidad: Los prompts se pueden ajustar rápidamente para explorar diferentes resultados sin necesidad de volver a entrenar el modelo.
# Desventajas:
- Inconsistencia: La calidad y relevancia de las respuestas del modelo pueden variar significativamente según la redacción del prompt.
- Personalización limitada: La capacidad de adaptar las respuestas del modelo está restringida a la creatividad y habilidad para crear prompts efectivos.
- Dependencia del conocimiento del modelo: Las salidas están limitadas a lo que el modelo ha aprendido durante su entrenamiento inicial, lo que lo hace menos efectivo para información altamente especializada o actualizada.
# Ajuste fino
El ajuste fino es cuando tomas el modelo de lenguaje y lo haces aprender algo nuevo o especial. Piensa en ello como actualizar una aplicación en tu teléfono para obtener mejores funciones. Pero en este caso, la aplicación (el modelo) necesita mucha información nueva y tiempo para aprender todo correctamente. Es un poco como volver a la escuela para el modelo.
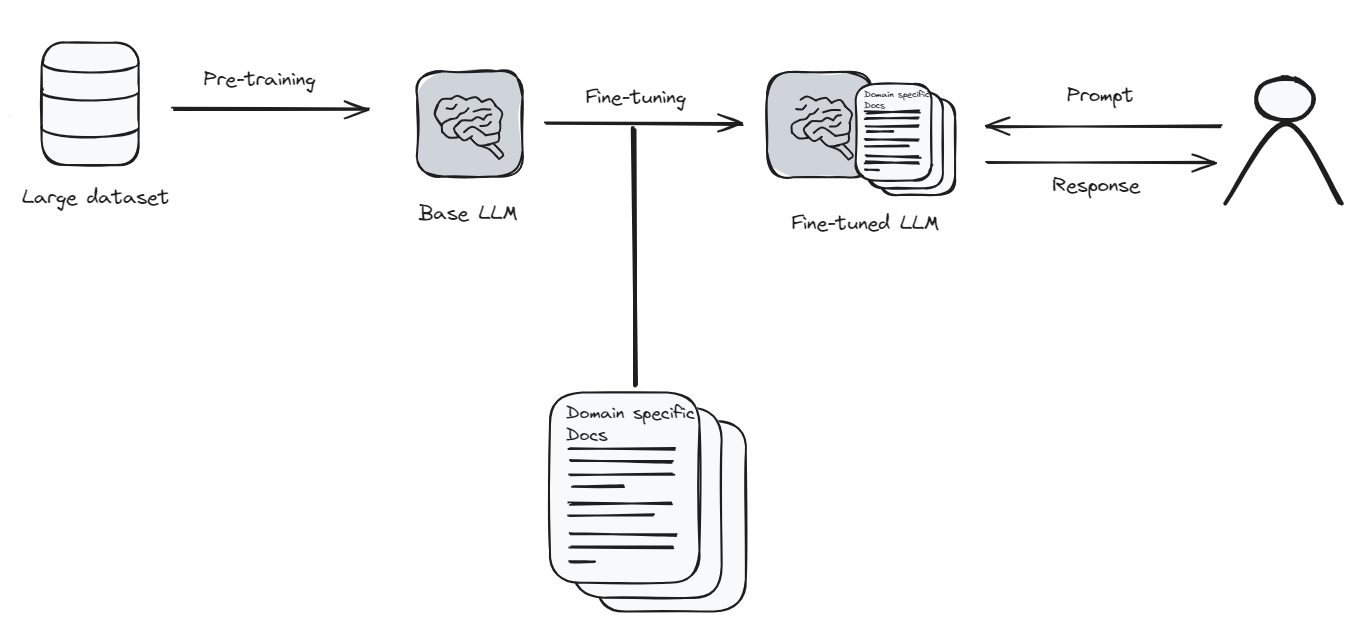
Debido a que el ajuste fino requiere mucha potencia informática y tiempo, puede ser costoso. Pero si necesitas que tu modelo de lenguaje comprenda muy bien un tema específico, entonces el ajuste fino vale la pena. Es como enseñarle al modelo a convertirse en un experto en lo que te interesa. Después del ajuste fino, el modelo puede darte respuestas más precisas y cercanas a lo que estás buscando.
# Ventajas:
- Personalización: Permite una personalización extensa, lo que permite que el modelo genere respuestas adaptadas a dominios o estilos específicos.
- Precisión mejorada: Al entrenar con un conjunto de datos especializado, el modelo puede producir respuestas más precisas y relevantes.
- Adaptabilidad: Los modelos ajustados finamente pueden manejar mejor temas de nicho o información reciente no cubierta en el entrenamiento original.
# Desventajas:
- Costo: El ajuste fino requiere recursos informáticos significativos, lo que lo hace más caro que el prompting.
- Habilidades técnicas: Este enfoque requiere una comprensión más profunda del aprendizaje automático (opens new window) y las arquitecturas de modelos de lenguaje (opens new window).
- Requisitos de datos: El ajuste fino efectivo requiere un conjunto de datos amplio y bien curado, lo que puede ser difícil de compilar.
Artículos relacionados: Cómo construir un sistema de recomendación (opens new window)
# Retrieval Augmented Generation (RAG)
Retrieval Augmented Generation, o RAG, combina las características habituales de los modelos de lenguaje con algo similar a una base de conocimientos (opens new window). Cuando el modelo necesita responder una pregunta, primero busca y recopila información relevante de una base de conocimientos, y luego responde la pregunta en función de esa información. Es como si el modelo hiciera una rápida consulta en una biblioteca de información para asegurarse de darte la mejor respuesta.
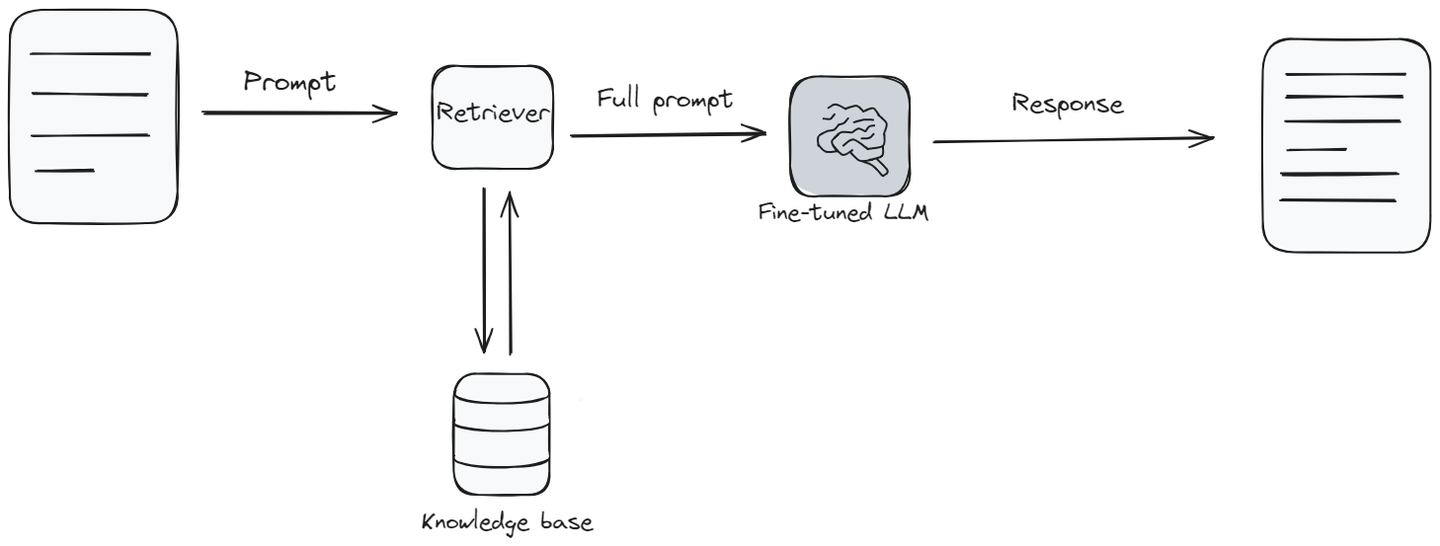
RAG es especialmente útil en situaciones en las que necesitas la información más reciente o respuestas que involucran una gama más amplia de temas que los que el modelo aprendió originalmente. Está en un punto intermedio en cuanto a la dificultad de configuración y los costos. Es genial porque ayuda al modelo de lenguaje a dar respuestas frescas y con más detalles. Pero, al igual que el ajuste fino, necesita herramientas e información adicionales para funcionar correctamente.
El costo, la velocidad y la calidad de respuesta de tu sistema RAG dependen en gran medida de la base de datos vectorial, lo que la convierte en una parte muy importante del sistema RAG. MyScale (opens new window) es una base de datos vectorial que no solo cobra casi la mitad en comparación con otras bases de datos vectoriales, sino que también ofrece un rendimiento 3 veces mejor. Puedes ver la comparativa (opens new window) aquí. Lo más importante es que no necesitas aprender herramientas o lenguajes externos para acceder a MyScale, puedes acceder a través de una sintaxis SQL sencilla, lo que la convierte en una elección perfecta para los desarrolladores.
# Ventajas:
- Información dinámica: Al aprovechar fuentes de datos externas, RAG puede proporcionar información actualizada y altamente relevante.
- Equilibrio: Ofrece un punto intermedio entre la facilidad de uso del prompting y la personalización del ajuste fino.
- Relevancia contextual: Mejora las respuestas del modelo con contexto adicional, lo que conduce a salidas más informadas y matizadas.
# Desventajas:
- Complejidad: Implementar RAG puede ser complejo, requiriendo la integración entre el modelo de lenguaje y el sistema de recuperación.
- Requerimientos de recursos: Si bien requiere menos recursos que el ajuste fino completo, RAG aún demanda una considerable potencia informática.
- Dependencia de datos: La calidad de la salida depende en gran medida de la relevancia y precisión de la información recuperada.
# Comparación: Ingeniería de Prompts vs Ajuste fino vs RAG
Veamos ahora una comparación lado a lado de la Ingeniería de Prompts, el Ajuste fino y la Retrieval Augmented Generation (RAG). Esta tabla te ayudará a ver las diferencias y decidir qué método puede ser el mejor para tus necesidades.
| Característica | Ingeniería de Prompts | Ajuste fino | Retrieval Augmented Generation (RAG) |
|---|---|---|---|
| Nivel de habilidad requerido | Bajo: Requiere una comprensión básica de cómo construir prompts. | Moderado a alto: Requiere conocimientos de principios de aprendizaje automático y arquitecturas de modelos. | Moderado: Requiere comprensión tanto de aprendizaje automático como de sistemas de recuperación de información. |
| Precios y recursos | Bajo: Utiliza modelos existentes, costos computacionales mínimos. | Alto: Se requieren recursos computacionales significativos para el entrenamiento. | Medio: Requiere recursos tanto para los sistemas de recuperación como para la interacción con el modelo, pero menos que el ajuste fino. |
| Personalización | Baja: Limitada por el conocimiento pre-entrenado del modelo y la habilidad del usuario para crear prompts efectivos. | Alta: Permite una personalización extensa para dominios o estilos específicos. | Media: Personalizable a través de fuentes de datos externas, aunque depende de su calidad y relevancia. |
| Requisitos de datos | Ninguno: Utiliza modelos pre-entrenados sin datos adicionales. | Alto: Requiere un conjunto de datos grande y relevante para un ajuste fino efectivo. | Medio: Necesita acceso a bases de datos externas o fuentes de información relevantes. |
| Frecuencia de actualización | Baja: Dependiente de la reentrenamiento del modelo subyacente. | Variable: Dependiente de cuándo se reentrena el modelo con nuevos datos. | Alta: Puede incorporar la información más reciente. |
| Calidad | Variable: Depende en gran medida de la habilidad para crear prompts. | Alta: Adaptado a conjuntos de datos específicos, lo que conduce a respuestas más relevantes y precisas. | Alta: Mejora las respuestas con información externa contextualmente relevante. |
| Casos de uso | Consultas generales, temas amplios, fines educativos. | Aplicaciones especializadas, necesidades específicas de la industria, tareas personalizadas. | Situaciones que requieren información actualizada y consultas complejas que involucran contexto. |
| Facilidad de implementación | Alta: Fácil de implementar con herramientas e interfaces existentes. | Baja: Requiere una configuración y procesos de entrenamiento profundos. | Media: Implica la integración de modelos de lenguaje con sistemas de recuperación. |
La tabla desglosa los puntos clave de la Ingeniería de Prompts, el Ajuste fino y RAG. Debería ayudarte a comprender cuál podría funcionar mejor en diferentes situaciones. Esperamos que esta comparación te ayude a elegir la herramienta adecuada para tu próxima tarea.
Artículos relacionados: Cómo funciona RAG (opens new window)

# RAG: la mejor opción para mejorar tu aplicación de IA
RAG es un enfoque único que combina el poder de los modelos de lenguaje tradicionales con la precisión de las bases de conocimientos externas. Este método se destaca por varias razones, lo que lo hace particularmente ventajoso sobre el simple prompting o el ajuste fino en contextos específicos.
En primer lugar, RAG garantiza que la información proporcionada sea actual y relevante al recuperar datos externos en tiempo real. Esto es crucial para aplicaciones donde la información actualizada es importante, como en consultas relacionadas con noticias o campos en constante evolución.
En segundo lugar, RAG ofrece un enfoque equilibrado en términos de personalización y requisitos de recursos. A diferencia del ajuste fino completo, que requiere una gran potencia informática, RAG permite operaciones más flexibles y eficientes en términos de recursos, lo que la hace accesible a una amplia gama de usuarios y desarrolladores.
Por último, la naturaleza híbrida de RAG une la capacidad generativa amplia de los LLM con la información específica y detallada disponible en las bases de conocimientos. Esto da como resultado salidas que no solo son relevantes y detalladas, sino también enriquecidas contextualmente.
Una solución de base de datos vectorial optimizada, escalable y rentable puede mejorar en gran medida el rendimiento y la funcionalidad de tus aplicaciones RAG. Por eso necesitas MyScale (opens new window), una base de datos vectorial basada en SQL, que ofrece integraciones fluidas con los principales marcos de IA y plataformas de modelos de lenguaje como OpenAI, Langchain, Langchain JS/TS y LlamaIndex. Con MyScale, RAG se vuelve más rápido y preciso (opens new window), lo cual es ideal para los usuarios que buscan los mejores resultados.
# Conclusión
En conclusión, si optas por la Ingeniería de Prompts, el Ajuste fino o la Retrieval Augmented Generation (RAG) dependerá de los requisitos específicos de tu proyecto, los recursos disponibles y los resultados deseados. Cada método tiene sus fortalezas y limitaciones únicas. La Ingeniería de Prompts es accesible y rentable, pero ofrece menos personalización. El Ajuste fino proporciona una personalización detallada a un costo y complejidad más altos. RAG encuentra un equilibrio, ofreciendo información actualizada y específica del dominio con una complejidad moderada.
Si deseas discutir más con nosotros, te invitamos a unirte a Discord de MyScale (opens new window) para compartir tus ideas y comentarios.



