
Recientemente, ha habido mucho revuelo en torno a los Modelos de Lenguaje Grandes(LLMs, por sus siglas en inglés) (opens new window) y sus diversos casos de uso, desde chatbots (opens new window) hasta generación de contenido. Sin embargo, a pesar de sus múltiples aplicaciones, los LLMs enfrentan desafíos significativos en la implementación en el mundo real, especialmente cuando se trata de ejecutarse de manera eficiente en diferentes dispositivos de hardware. Estos modelos son computacionalmente pesados y requieren una memoria sustancial, lo que dificulta su ejecución en dispositivos con capacidades de procesamiento limitadas, como teléfonos inteligentes y tabletas. Esta limitación puede obstaculizar la adopción generalizada de los LLMs.
Para abordar estos desafíos, los investigadores han introducido la cuantización como una solución viable. La cuantización reduce el uso de memoria y el tamaño de un modelo, lo que le permite ejecutarse en diferentes dispositivos sin sacrificar el rendimiento al convertir los parámetros de alta precisión a formatos de menor precisión.
En este artículo, profundizaremos en los principios de los LLMs, su impacto transformador en las tareas de procesamiento del lenguaje natural y la necesidad crítica de optimizar estos modelos para diversas plataformas de hardware. También abordaremos los desafíos de optimización y destacaremos la cuantización como un método poderoso para implementar LLMs en varios dispositivos.
# Cómo funcionan los LLMs y la necesidad de cuantización
Los LLMs operan entrenándose en conjuntos de datos vastos que incluyen libros, artículos y contenido web. Aprenden a comprender y generar lenguaje humano ajustando millones o incluso miles de millones de parámetros, que son básicamente pesos que el modelo ajusta durante el entrenamiento para minimizar los errores de predicción. Estos pesos ocupan una memoria sustancial, lo que puede ser un desafío importante para los dispositivos con recursos computacionales limitados.
Por ejemplo, un modelo con 5 mil millones de parámetros requiere alrededor de 10 GB de memoria para cargarse cuando se utiliza una precisión de 16 bits, lo que lo hace poco práctico para dispositivos con capacidades computacionales limitadas. Aquí es donde la cuantización se vuelve esencial. Al reducir la precisión de los parámetros del modelo, la cuantización disminuye el uso de memoria y la carga computacional sin comprometer significativamente el rendimiento. Este proceso implica convertir los pesos y activaciones de alta precisión (por ejemplo, punto flotante de 16 bits o punto flotante de 32 bits) a una precisión más baja (por ejemplo, entero de 8 bits).
# Resumen de la cuantización:
La cuantización es crucial para implementar LLMs de manera eficiente en diversas plataformas de hardware. Reduce el tamaño del modelo y las demandas computacionales al convertir los pesos y activaciones de alta precisión (por ejemplo, punto flotante de 32 bits) a una precisión más baja (por ejemplo, entero de 8 bits). Esta reducción de la precisión conduce a tamaños de modelo más pequeños, cálculos más rápidos y un menor uso de memoria, lo que permite ejecutar modelos en dispositivos periféricos como teléfonos inteligentes y dispositivos de IoT sin una pérdida significativa de precisión.
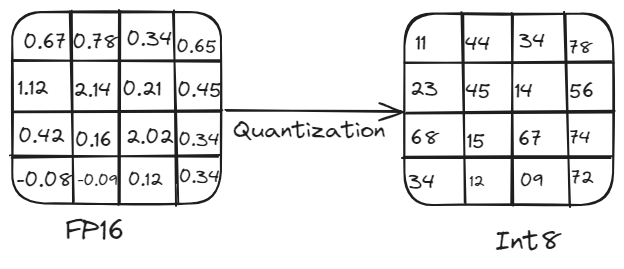
Proceso de cuantización
# Cómo se realiza la cuantización?
La cuantización se puede realizar utilizando dos métodos principales: cuantización simétrica y cuantización asimétrica.
# Cuantización simétrica
Este enfoque escala tanto los valores positivos como los negativos de manera simétrica alrededor de cero. Se utiliza el mismo factor de escala para todos los valores, lo que simplifica los cálculos pero a veces resulta en una representación menos eficiente para valores con una distribución sesgada.
Imaginemos que tenemos un rango de números de punto flotante de -6 a 5. Para cuantizar estos valores, encontramos el valor absoluto máximo, que es 6. Usamos este valor para escalar todo el rango. En una representación de 8 bits, el rango es de -128 a 127. Entonces, mapeamos -6 a -128, 0 a 0 y 5 a aproximadamente 106. De esta manera, la escala es simétrica alrededor de cero.
Q=round(SX)
Aquí, S es el factor de escala (por ejemplo, 6/128).
# Cuantización asimétrica
Este método utiliza diferentes factores de escala para diferentes rangos de valores. Proporciona más flexibilidad y a menudo resulta en un mejor rendimiento del modelo, pero puede ser más complejo de implementar.
Supongamos que tenemos un rango de números de punto flotante de 0 a 10. En una representación de 8 bits, este rango se puede mapear directamente de 0 a 255, utilizando todo el rango de valores cuantizados. Aquí, se utiliza un punto cero para alinear correctamente los rangos, asegurando que se utilice todo el rango de manera eficiente.
X=Q×S+Z
Aquí, S es el factor de escala y Z es el ajuste del punto cero.
# Modos de cuantización
Existen dos modos principales de cuantización: cuantización después del entrenamiento y entrenamiento con cuantización.
# Cuantización después del entrenamiento (PTQ, por sus siglas en inglés)
Este método implica tomar un modelo que ya ha sido entrenado con precisión completa (generalmente en punto flotante de 32 bits) y convertirlo a un formato de menor precisión (como enteros de 8 bits) después de que se complete el entrenamiento. El proceso es sencillo y rápido porque no requiere volver a entrenar el modelo. Sin embargo, dado que el modelo no se entrenó originalmente para operar con esta menor precisión, existe la posibilidad de que su precisión pueda disminuir ligeramente. Esto se debe a que los pesos y activaciones del modelo se aproximan para adaptarse a la representación de bits más pequeña, lo que puede introducir algunos errores de cuantización.
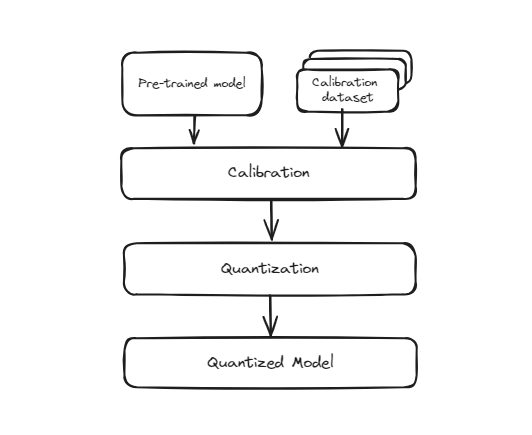
Cuantización antes del entrenamiento
Sin embargo, durante esta conversión, se reduce la precisión de los pesos, lo que puede provocar una ligera disminución en el rendimiento del modelo para reconocer dígitos con precisión. Es especialmente útil en escenarios donde el tamaño del modelo y la velocidad de inferencia son críticos, como aplicaciones móviles, sistemas integrados y computación periférica. A pesar de la posible disminución leve en la precisión, los beneficios de eficiencia y escalabilidad suelen valer la pena.
# Entrenamiento con cuantización (QAT, por sus siglas en inglés)
Esta técnica incorpora la cuantización directamente en el proceso de entrenamiento de la red neuronal. En lugar de entrenar primero el modelo y luego convertirlo a una precisión menor, QAT entrena el modelo teniendo en cuenta la menor precisión desde el principio. Esto significa que durante el entrenamiento, los pesos y activaciones del modelo se "cuantizan falsamente" para simular los efectos de la menor precisión. Esto ayuda al modelo a aprender a operar de manera efectiva dentro de las limitaciones de los valores cuantizados, lo que conduce a un mejor rendimiento cuando se convierte realmente a una menor precisión. QAT requiere más recursos computacionales y tiempo, ya que el modelo pasa por pasos adicionales durante el entrenamiento, pero generalmente resulta en una mayor precisión en comparación con la cuantización después del entrenamiento (PTQ).
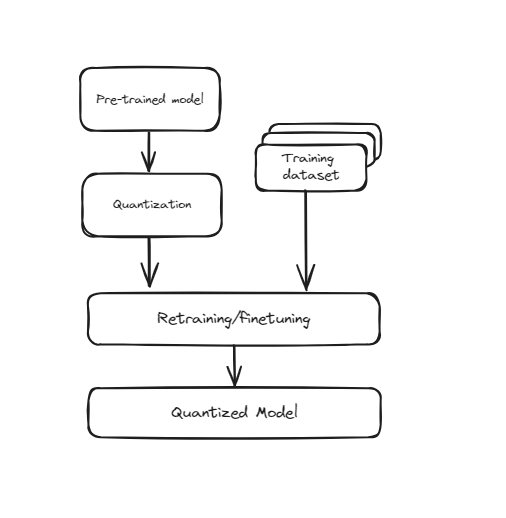
Cuantización consciente del entrenamiento
Es especialmente útil para aplicaciones donde mantener una alta precisión es crucial, como el reconocimiento de imágenes, el procesamiento del lenguaje natural y otras tareas de inteligencia artificial. A pesar del aumento en el tiempo de entrenamiento y los requisitos de recursos, el rendimiento y la precisión mejorados a una menor precisión hacen que QAT sea una técnica valiosa para implementar modelos de alto rendimiento en entornos con recursos limitados.
# Ventajas y desventajas de la cuantización
Ventajas:
- Los modelos ocupan menos espacio de almacenamiento, lo que facilita su distribución e implementación.
- Los cálculos de menor precisión son más rápidos, mejorando el rendimiento en tiempo real.
- Ideal para dispositivos con batería.
Desventajas:
- La cuantización puede introducir errores, lo que reduce la precisión del modelo.
- Especialmente para la cuantización asimétrica y QAT.
- No todos los dispositivos admiten todos los tipos de cuantización de manera eficiente.

# Ejemplo práctico de cuantización
En este ejemplo, demostraremos cómo realizar la cuantización dinámica en un modelo preentrenado de DistilBERT utilizando las bibliotecas transformers y torch. Esto ayudará a reducir el tamaño del modelo y hacerlo adecuado para la implementación en dispositivos con recursos computacionales limitados.
Creemos un script de Python para cargar un modelo preentrenado de DistilBERT, realizar la cuantización dinámica y comparar los tamaños de los modelos original y cuantizado. Aquí se explica el código paso a paso:
- Importar las bibliotecas necesarias
Primero, debemos instalar las bibliotecas transformers y torch para realizar la cuantización. Esto se puede hacer ejecutando el siguiente comando en tu terminal:
pip install transformers torch
La biblioteca torch se utiliza para manejar modelos y tareas de cuantización de PyTorch, mientras que la biblioteca transformers se utiliza para cargar el modelo preentrenado de DistilBERT y el tokenizador. Además, el módulo os se utiliza para interactuar con el sistema operativo, como leer y escribir archivos.
import torch
from transformers import DistilBertModel, DistilBertTokenizer
import os
- Cargar el modelo preentrenado y el tokenizador
Luego, cargamos el modelo preentrenado de DistilBERT y el tokenizador utilizando las clases DistilBertModel y DistilBertTokenizer de la biblioteca transformers. El nombre del modelo distilbert-base-uncased se utiliza para especificar la variante particular de DistilBERT.
model_name = 'distilbert-base-uncased'
model = DistilBertModel.from_pretrained(model_name)
tokenizer = DistilBertTokenizer.from_pretrained(model_name)
- Definir la función de cuantización
A continuación, definimos una función quantize_model que realiza la cuantización dinámica en el modelo. La función torch.quantization.quantize_dynamic se utiliza para convertir el modelo a una versión cuantizada, apuntando específicamente a las capas torch.nn.Linear y utilizando una precisión de entero de 8 bits (qint8).
def quantize_model(model):
quantized_model = torch.quantization.quantize_dynamic(
model, {torch.nn.Linear}, dtype=torch.qint8
)
return quantized_model
- Cuantizar el modelo de DistilBERT
Luego, aplicamos la función quantize_model al modelo de DistilBERT, lo que resulta en una versión cuantizada del modelo.
quantized_model = quantize_model(model)
- Verificar el tamaño de los modelos original y cuantizado
Finalmente, definimos una función print_model_size para verificar e imprimir los tamaños de los modelos original y cuantizado. La función torch.save se utiliza para guardar el diccionario de estado del modelo en un archivo, y la función os.path.getsize se utiliza para obtener el tamaño del archivo en megabytes (MB).
def print_model_size(model, model_name):
torch.save(model.state_dict(), f'{model_name}.pt')
print(f'Tamaño de {model_name}: {os.path.getsize(f"{model_name}.pt") / 1e6} MB')
Luego, utilizamos esta función para imprimir los tamaños de los modelos de DistilBERT original y cuantizado.
print_model_size(model, 'distilbert_original')
print_model_size(quantized_model, 'distilbert_cuantizado')
La salida final del código se ve así:
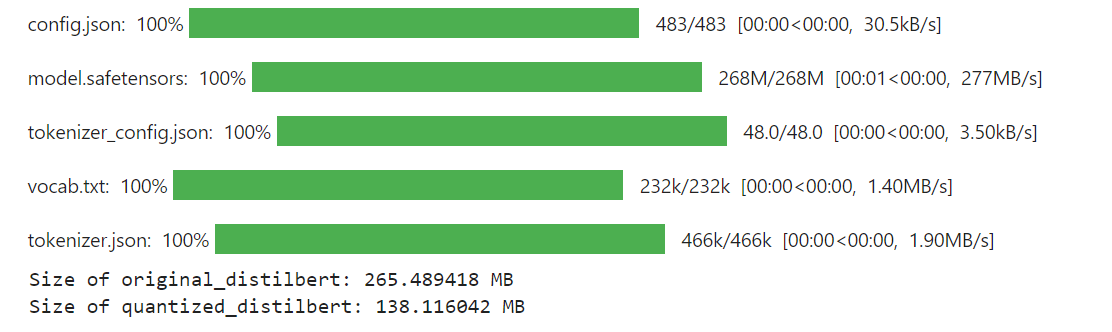
Resultados
Como se puede ver, después de aplicar la cuantización al modelo de DistilBERT, su tamaño se ha reducido significativamente a 138 MB desde 265 MB.
# Cómo la cuantización ayuda a construir mejores sistemas RAG
La cuantización nos permite utilizar modelos más grandes de manera más efectiva al reducir su tamaño sin una disminución significativa en el rendimiento. Los LLMs naturalmente tienen un mejor rendimiento y capacidades más avanzadas a medida que aumenta su tamaño, pero también requieren recursos computacionales sustanciales. Con la cuantización, podemos reducir estos modelos grandes, lo que nos permite implementarlos en entornos con recursos limitados y aprovechar sus capacidades mejoradas.
Las bases de datos vectoriales se pueden integrar con técnicas de cuantización para mejorar significativamente los sistemas RAG al mejorar la eficiencia y la escalabilidad. Al almacenar y buscar incrustaciones cuantizadas, las bases de datos vectoriales permiten una recuperación más rápida, un menor uso de memoria y costos computacionales más bajos. Esto permite que los sistemas RAG manejen conjuntos de datos más grandes y respondan más rápidamente, manteniendo una precisión aceptable. La compatibilidad con LLMs cuantizados garantiza la consistencia en todo el proceso, lo que potencialmente mejora el rendimiento general. MyScaleDB (opens new window), una base de datos vectorial SQL, mejora aún más el rendimiento de RAG al proporcionar una recuperación de datos eficiente y precisa. Es una buena opción para los desarrolladores debido a su interfaz SQL familiar, además de ser asequible, rápida y optimizada para aplicaciones RAG a nivel de producción.
Si tienes alguna sugerencia, contáctanos a través de Twitter (opens new window) o Discord (opens new window).



