
![]()
LlamaIndex (opens new window) es un marco de datos diseñado para implementar aplicaciones utilizando Modelos de Lenguaje Grandes (LLMs), simplificando el análisis, almacenamiento y recuperación de varios tipos de datos de documentos, y agregando un valor inmenso a las capacidades de las aplicaciones de LLM. Este mecanismo se conoce comúnmente como Generación con Recuperación Mejorada (RAG, por sus siglas en inglés).
Para ayudarte a comprender cómo utilizar LlamaIndex para implementar este mecanismo, este artículo construirá un motor de consulta de documentos simple para demostrar el proceso.
# MyScale
Si bien LlamaIndex puede manejar varios tipos de datos fuente, no almacena ni indexa estos datos. Todavía necesitamos un sistema de almacenamiento. MyScale (opens new window) es una base de datos vectorial que admite SQL y es fácil de usar, con su versión gratuita que admite hasta 5 millones de puntos de datos vectoriales. Lo más importante es que LlamaIndex admite bases de datos vectoriales de MyScale (opens new window). Puedes conectarte a una base de datos de MyScale para almacenar y consultar datos utilizando MyScaleVectorStore y MyScaleReader y realizar las siguientes operaciones de datos a través de LlamaIndex:
| Almacenamiento Vectorial | Tipo | Filtrado de Metadatos | Búsqueda Híbrida | Eliminación | Almacenamiento de Documentos |
|---|---|---|---|---|---|
| MyScale | nube | ✓ | ✓ | ✓ | ✓ |
Este conjunto de operaciones proporciona funcionalidades completas. Ahora, comencemos a construir nuestra aplicación de LLM utilizando estas operaciones.
# Preparación
Nota:
Todo el código relacionado mencionado en este artículo se puede encontrar en GitHub en el repositorio myscale/llama_index_myscale (opens new window).
# Datos
Utilizamos la documentación oficial de MyScale (MyScale Docs (opens new window)) en formato Markdown como nuestros datos en bruto. También puedes ver y descargar estos archivos en GitHub (opens new window).
# Dependencias
- Python 3.8.18
- LlamaIndex 0.9.5
- MyScale
# Flujo de Proceso
La construcción de una aplicación de Generación con Recuperación Mejorada (RAG) implica múltiples pasos de procesamiento, como se destaca en el siguiente diagrama. En primer lugar, debemos procesar los datos en bruto sin conexión, lo que incluye dividir los datos de texto, almacenados en archivos planos, en nodos de datos basados en criterios o reglas específicas. Una vez completado esto, debemos calcular la representación vectorial de cada nodo de datos. Y por último, debemos almacenar los datos en la base de datos.
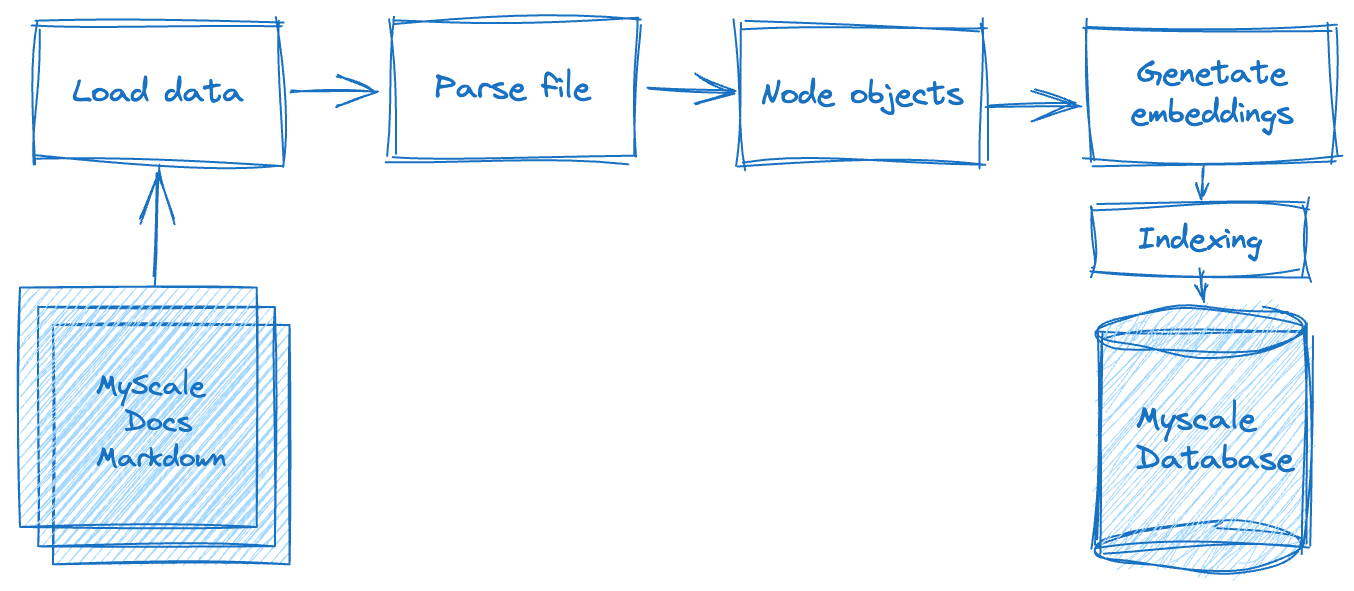
En la segunda fase, la fase de recuperación de datos, consultamos y fusionamos los datos relevantes del documento en función de esta consulta. Estos datos son luego solicitados y devueltos al sistema de LLM, obteniendo los resultados esperados.
Ahora, exploremos cómo integrar LlamaIndex con MyScale para lograr estos pasos.
# Carga de los Datos
En esta fase, debemos leer los archivos de documentos descargados, convertirlos en objetos de documentos de MyScale y utilizar las capacidades de procesamiento de documentos de LlamaIndex, que incluyen el manejo de Markdown, PDF, documentos de Word, presentaciones de PowerPoint, imágenes, audio y video. Para los documentos .md, se utiliza el MarkdownReader, como se muestra a continuación:
# utils.py
from llama_index import download_loader
from llama_index import Document
from typing import Dict, List, Union
from pathlib import Path
UnstructuredReader = download_loader("MarkdownReader")
loader = UnstructuredReader()
def load_and_parse_files(file_row: Dict[str, Path]) -> List[Dict[str, Document]]:
documents = []
file = file_row["path"]
if file.is_dir():
return []
# Omitir todos los archivos que no sean .md, como png, jpg, etc., html.
if file.suffix.lower() == ".md":
loaded_doc = loader.load_data(file=file)
loaded_doc[0].extra_info = {"path": str(file)}
documents.extend(loaded_doc)
return [{"doc": doc} for doc in documents]
# Análisis de los Documentos
Después de leer los segmentos de texto de estos documentos, debemos encapsularlos en nodos de datos para la siguiente operación de vectorización. Para garantizar la consistencia del formato, continuamos utilizando el MarkdownNodeParser. El flujo de procesamiento de esta parte es el siguiente:
# utils.py
from llama_index.node_parser import MarkdownNodeParser
from llama_index.data_structs import Node
def convert_documents_into_nodes(documents: Dict[str, Document]) -> List[Dict[str, Node]]:
parser = MarkdownNodeParser()
document = documents["doc"]
nodes = parser.get_nodes_from_documents([document])
return [{"node": node} for node in nodes]
# Vectorización
La vectorización es un paso crucial y que consume mucho tiempo. Esto implica vectorizar el contenido de texto de los nodos de datos devueltos en el paso anterior y almacenar los vectores en el campo "embedding" de los nodos de datos. Utilizamos el modelo sentence-transformers/all-mpnet-base-v2 (opens new window), que se puede obtener de Hugging Face. LlamaIndex nos ayudará automáticamente a descargar y aplicar estos embeddings en nuestra aplicación.
# utils.py
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
class EmbedNodes:
def __init__(self):
self.embedding_model = HuggingFaceEmbeddings(
# Utilizar el modelo all-mpnet-base-v2 de Sentence_transformer.
# Este es el modelo de embedding predeterminado para LlamaIndex/Langchain.
model_name="sentence-transformers/all-mpnet-base-v2",
model_kwargs={},
# Utilizar GPU para la vectorización y especificar un tamaño de lote lo suficientemente grande para maximizar la utilización de la GPU.
# Elimina "device": "cuda" para utilizar la CPU en su lugar.
encode_kwargs={"batch_size": 100}
)
def __call__(self, node_batch: Dict[str, List[Node]]) -> Dict[str, List[Node]]:
nodes = node_batch["node"]
text = [node.text for node in nodes]
embeddings = self.embedding_model.embed_documents(text)
assert len(nodes) == len(embeddings)
for node, embedding in zip(nodes, embeddings):
node.embedding = embedding
return {"embedded_nodes": nodes}
# Ejecución Local y Almacenamiento en MyScale
Introdujimos las operaciones principales de análisis y vectorización de documentos Markdown en los procesos anteriores. A continuación, debemos generar los datos y construir un índice. En LlamaIndex, podemos utilizar MyScaleVectorStore para realizar estas operaciones no complejas, como se muestra en el siguiente script de Python:
Nota:
Este script contiene todo el flujo de procesamiento de datos.
# create_vector_index.py
import clickhouse_connect
import utils
from pathlib import Path
from llama_index import VectorStoreIndex
from llama_index.vector_stores import MyScaleVectorStore
from llama_index.storage import StorageContext
all_docs_gen = Path("./docs.myscale.com/").rglob("*")
all_docs = [{"path": doc.resolve()} for doc in all_docs_gen]
blog_nodes = {"embedded_nodes": []}
for docs in all_docs:
loaded_docs = utils.load_and_parse_files(docs)
for doc in loaded_docs:
nodes = utils.convert_documents_into_nodes(doc)
newNodes = {"node": []}
for node in nodes:
newNodes["node"].append(node["node"])
embedNodes = utils.EmbedNodes()
tmpNodes = embedNodes(newNodes)
blog_nodes["embedded_nodes"].extend(tmpNodes["embedded_nodes"])
client = clickhouse_connect.get_client(
host='{MYSCALE_CLUSTER_URL}',
port=443,
username='{YOUR_USERNAME}',
password='{YOUR_PASSWORD}'
)
vector_store = MyScaleVectorStore(myscale_client=client)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
VectorStoreIndex(blog_nodes["embedded_nodes"], storage_context=storage_context)
Para reutilizar el código, las funciones load_and_parse_files, convert_documents_into_nodes y EmbedNodes se colocan en utils.py.
# Construcción del Servicio de Consulta
Una vez que los datos se almacenan en MyScale, podemos utilizar MyScaleVectorStore y la API de LLM para manejar las consultas de los usuarios, según el siguiente script: query_myscale.py. El siguiente es el contenido de query_myscale.py, que incluye los siguientes pasos principales:
Este script incluye estos pasos principales:
- Leer la consulta de entrada del usuario desde la terminal y vectorizar la consulta.
- Utilizar
llama_index.vector_stores.MyScaleVectorStorepara consultar los datos relacionados con la consulta utilizando el modo de Búsqueda Híbrida. Este modo garantiza un cierto nivel de relevancia tanto en el texto como en la distancia vectorial. - Sintetizar la respuesta enviando los documentos obtenidos en el paso anterior al LLM para generar el resultado final.
# query_myscale.py
import clickhouse_connect
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
from llama_index.schema import NodeWithScore
from llama_index.vector_stores import MyScaleVectorStore, VectorStoreQuery
from llama_index.vector_stores.types import VectorStoreQueryMode
# Agrega aquí tu clave de API de OpenAI antes de ejecutar el script.
model = HuggingFaceEmbeddings(model_name="sentence-transformers/all-mpnet-base-v2")
client = clickhouse_connect.get_client(
host='{MYSCALE_CLUSTER_URL}',
port=443,
username='{YOUR_USERNAME}',
password='{YOUR_PASSWORD}'
)
# consulta de entrada
query = input("Consulta: ")
while len(query) == 0:
query = input("\nConsulta: ")
# vectorización de la consulta
embedded_query = model.embed_query(query)
# enviar la consulta a MyScale utilizando llama_index.vector_stores.MyScaleVectorStore
vector_store = MyScaleVectorStore(myscale_client=client)
vector_store_query = VectorStoreQuery(
query_embedding=embedded_query,
similarity_top_k=20,
mode=VectorStoreQueryMode.HYBRID
)
result = vector_store.query(vector_store_query)
scoreNodes = [NodeWithScore(node=result.nodes[i], score=result.similarities[i]) for i in range(len(result.nodes))]
# sintetizar la respuesta
from llama_index.response_synthesizers import (
get_response_synthesizer,
)
synthesizer = get_response_synthesizer()
response_obj = synthesizer.synthesize(query, scoreNodes)
print(f"Respuesta: {str(response_obj.response)}")
Nota:
Reemplaza los marcadores de posición como {MYSCALE_CLUSTER_URL}, {YOUR_USERNAME} y {YOUR_PASSWORD} con la información real de tu clúster de MyScale.

# Ejecución del Script
Ejecuta el script y, después del indicador, ingresa una consulta para recibir la siguiente respuesta:
$ python query_myscale.py
Consulta: ¿Cómo crear un clúster de MyScale?
Respuesta: Para crear un clúster de MyScale, puedes seguir estos pasos:
1. Ve a la página de Clusters.
2. Haz clic en el botón "+ Nuevo Clúster".
3. Nombra tu clúster.
4. Haz clic en "Lanzar" para ejecutar el clúster.
Una vez creado el clúster, se iniciará automáticamente. Ten en cuenta que el clúster se terminará si no hay actividad durante 7 días, y todos los datos en el clúster se eliminarán.
Puedes ingresar varias preguntas relacionadas con MyScale. Esta aplicación está diseñada para proporcionar respuestas valiosas.
# Avanzando
Hemos construido con éxito una aplicación de LLM completamente funcional con MyScale y LlamaIndex, demostrando su rendimiento efectivo. ¿Cómo podemos acelerar el proceso de vectorización para hacer frente a cien mil o incluso millones de datos de documentos?
Afortunadamente, podemos utilizar Ray, un marco diseñado para el aprendizaje automático, en combinación con LlamaIndex y MyScale para el procesamiento distribuido y mejorar la eficiencia del procesamiento de datos. Puedes consultar la documentación oficial de Ray, Installing Ray (opens new window), o Ray on Kubernetes (opens new window), para construir un clúster local o basado en Kubernetes.
Suponiendo que ya tienes un RayCluster Head en el host local o has habilitado el reenvío de puertos para RayCluster Head en el clúster de Kubernetes, puedes utilizar el siguiente código directamente para mejorar el procesamiento de los embeddings con cómputo paralelo, acelerando significativamente las velocidades y eficiencias de procesamiento de datos:
# create_vector_index_by_ray.py
import clickhouse_connect
import utils
import ray
from pathlib import Path
from llama_index import VectorStoreIndex
from llama_index.vector_stores import MyScaleVectorStore
from llama_index.storage import StorageContext
from ray.data import ActorPoolStrategy
all_docs_gen = Path("./docs.myscale.com/").rglob("*")
all_docs = [{"path": doc.resolve()} for doc in all_docs_gen]
ds = ray.data.from_items(all_docs)
loaded_docs = ds.flat_map(utils.load_and_parse_files)
nodes = loaded_docs.flat_map(utils.convert_documents_into_nodes)
embedded_nodes = nodes.map_batches(
utils.EmbedNodes,
batch_size=100,
compute=ActorPoolStrategy(size=4),
num_gpus=0)
blogs_nodes = []
for row in embedded_nodes.iter_rows():
node = row["embedded_nodes"]
assert node.embedding is not None
blogs_nodes.append(node)
client = clickhouse_connect.get_client(
host='{MYSCALE_CLUSTER_URL}',
port=443,
username='{YOUR_USERNAME}',
password='{YOUR_PASSWORD}'
)
vector_store = MyScaleVectorStore(myscale_client=client)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
VectorStoreIndex(blogs_nodes, storage_context=storage_context)
Estos procesos, utilizando la misma entrada y salida descrita anteriormente en la sección Ejecución Local y Almacenamiento en MyScale, también pueden consultar los datos vectoriales relevantes almacenados en la base de datos de MyScale. Luego, puedes ejecutar consultas utilizando query_myscale.py.
# En Conclusión
MyScale y LlamaIndex son dos herramientas excelentes para el procesamiento de LLM. Pueden ayudarte a construir rápidamente tu aplicación de LLM. Cuando te enfrentes a problemas de escala de datos desafiantes, puedes utilizar Ray para el procesamiento distribuido, combinándolo con LlamaIndex y MyScale para mejorar significativamente la facilidad de desarrollo.
¡Finalmente, para aplicaciones RAG a gran escala, visita myscale.com (opens new window) para configurar tu clúster sin demora!



