
La velocidad de iteración de la Inteligencia Artificial Generativa (GenAI) está creciendo exponencialmente. Un resultado de esto es que la ventana de contexto, es decir, el número de tokens que un modelo de lenguaje grande (LLM, por sus siglas en inglés) puede utilizar al mismo tiempo para generar una respuesta, también está expandiéndose rápidamente.
Google Gemini 1.5 Pro, lanzado en febrero de 2024, estableció un récord para la ventana de contexto más larga hasta la fecha: 1 millón de tokens, equivalente a 1 hora de video o 700,000 palabras. El destacado rendimiento de Gemini al manejar contextos largos llevó a algunas personas a proclamar que "la generación aumentada por recuperación (RAG, por sus siglas en inglés) está muerta". Dijeron que los LLM ya son recuperadores muy poderosos, entonces ¿por qué perder tiempo construyendo un recuperador débil y lidiar con problemas relacionados con RAG como la fragmentación, la incrustación y la indexación?
La ampliación de la ventana de contexto inició un debate: con estas mejoras, ¿sigue siendo necesario RAG? ¿O podría volverse obsoleto pronto?
# Cómo Funciona RAG
Los LLM están constantemente empujando los límites de lo que las máquinas pueden entender y lograr, pero han estado limitados por problemas como la dificultad para responder con precisión a datos no vistos o estar actualizados con la información más reciente. Estos dieron lugar a alucinaciones, para las cuales se desarrolló RAG (opens new window) para abordarlas.
RAG combina el poder de los LLM con fuentes de conocimiento externas para producir respuestas más informadas y precisas. Cuando se recibe una consulta del usuario, el sistema RAG procesa inicialmente el texto para comprender su contexto e intención. Luego recupera datos relevantes para la consulta del usuario desde una base de conocimiento (opens new window) y los pasa, junto con la consulta, al LLM como contexto. En lugar de pasar toda la base de conocimiento, solo pasa los datos relevantes porque los LLM tienen un límite contextual (opens new window), la cantidad de texto que un modelo puede considerar o entender a la vez.
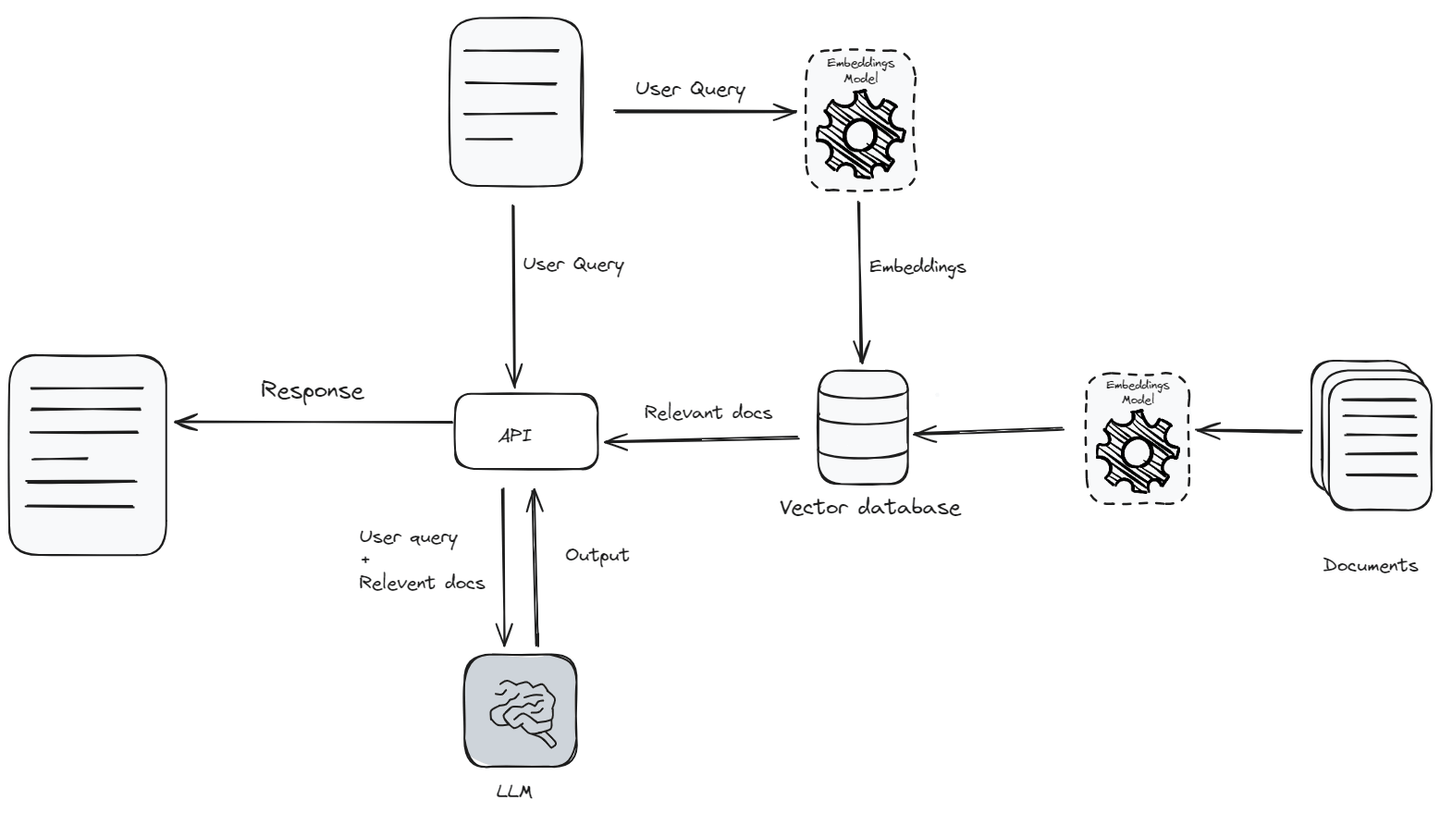
Primero, la consulta (opens new window) se convierte en vectores de incrustación (opens new window) utilizando un modelo de incrustación (opens new window). Este vector de incrustación se compara luego con una base de datos de vectores de documentos, identificando los documentos más relevantes. Estos documentos relevantes se obtienen y se combinan con la consulta original para proporcionar un contexto rico para que el LLM genere una respuesta más precisa. Este enfoque híbrido permite que el modelo utilice información actualizada de fuentes externas, lo que permite que los LLM generen respuestas más informadas y precisas.
# Por qué las Ventanas de Contexto Largas Podrían Significar el Fin de RAG
El aumento continuo de la ventana de contexto de los LLM afectará directamente cómo estos modelos ingieren y generan respuestas. Al aumentar la cantidad de texto que los LLM pueden procesar al mismo tiempo, estas ventanas contextuales extendidas mejoran la capacidad del modelo para comprender narrativas más completas e ideas complejas, mejorando la calidad y relevancia general de las respuestas generadas. Esto mejora la capacidad de los LLM para realizar un seguimiento de textos más largos, lo que les permite comprender un contexto y sus detalles más finos de manera más efectiva. En consecuencia, a medida que los LLM se vuelven más hábiles para manejar e integrar un contexto extenso, la dependencia de RAG para mejorar la precisión y relevancia de las respuestas puede disminuir.
# Precisión
RAG mejora la capacidad del modelo al proporcionar documentos relevantes como contexto basado en un puntaje de similitud (opens new window). Sin embargo, RAG no se adapta ni aprende del contexto en tiempo real. En cambio, recupera documentos que parecen similares a la consulta del usuario, lo que no siempre es lo más apropiado contextualmente y puede llevar a respuestas menos precisas.
Por otro lado, al utilizar la ventana de contexto larga de un modelo de lenguaje al incluir todos los datos en él, el mecanismo de atención de un LLM puede generar mejores respuestas. El mecanismo de atención dentro de un modelo de lenguaje se enfoca en las diferentes partes del contexto proporcionado para generar una respuesta precisa. Además, este mecanismo se puede ajustar (opens new window). Al ajustar el modelo de LLM para reducir la pérdida, mejora progresivamente, lo que resulta en respuestas más precisas y contextualmente relevantes.
# Recuperación de Información
Al recuperar información de una base de conocimiento para mejorar las respuestas de los LLM, siempre es difícil encontrar datos completos y relevantes para la ventana contextual. Siempre existe incertidumbre sobre si los datos recuperados responden completamente a la consulta del usuario. Esta situación puede causar ineficiencias y errores si la información elegida no es suficiente y no se alinea bien con las intenciones reales del usuario o el contexto de la conversación.
# Almacenamiento Externo
Tradicionalmente, los LLM no podían manejar grandes cantidades de información simultáneamente porque estaban limitados en la cantidad de contexto que podían procesar. Pero sus capacidades mejoradas les permiten manejar datos extensos directamente, eliminando la necesidad de almacenamiento separado por consulta. Esto agiliza la velocidad de acceso a las bases de datos externas y mejora la eficiencia de la IA.
# Por qué RAG Permanecerá
Las ventanas contextuales ampliadas en los LLM pueden proporcionarle al modelo una comprensión más profunda, pero también presentan desafíos como costos computacionales más altos y eficiencia. RAG aborda estos desafíos al recuperar selectivamente solo la información más relevante, lo que ayuda a optimizar el rendimiento y la precisión.
# Persistirá RAG Complejo
No hay duda de que RAG simple, donde los datos se fragmentan en documentos de longitud fija y se recuperan según la similitud, está desapareciendo. Sin embargo, los sistemas de RAG complejos no solo persisten, sino que también evolucionan significativamente.
RAG complejo incluye una gama más amplia de capacidades como reescritura de consultas (opens new window), limpieza de datos (opens new window), reflexión (opens new window), búsqueda de vectores optimizada (opens new window), búsqueda de gráficos (opens new window), reordenadores (opens new window) y técnicas de fragmentación más sofisticadas. Estas mejoras no solo están refinando la funcionalidad de RAG, sino también ampliando sus capacidades.
# Rendimiento más allá de la Longitud del Contexto
Si bien expandir la ventana contextual en los LLM para incluir millones de tokens parece prometedor, las implementaciones prácticas aún son cuestionables debido a varios factores, incluido el tiempo, la eficiencia y el costo.
Tiempo: A medida que aumenta el tamaño de la ventana contextual, también aumenta la latencia en los tiempos de respuesta. A medida que se expande el tamaño de la ventana contextual, el LLM tarda más tiempo en procesar un mayor número de tokens, lo que conduce a retrasos y un aumento de la latencia. Muchas aplicaciones de LLM requieren respuestas rápidas. El retraso adicional en el procesamiento de bloques de texto más grandes puede obstaculizar significativamente el rendimiento del LLM en escenarios en tiempo real, creando un cuello de botella importante en la implementación de ventanas contextuales más grandes.
Eficiencia: Los estudios sugieren que los LLM obtienen mejores resultados cuando se les proporciona menos documentos más relevantes en lugar de grandes volúmenes de datos no filtrados. Un estudio reciente de Stanford (opens new window) encontró que los LLM de última generación a menudo tienen dificultades para extraer información valiosa de sus ventanas contextuales extensas. La dificultad es particularmente pronunciada cuando los datos críticos están enterrados en medio de un bloque de texto grande, lo que hace que los LLM pasen por alto detalles importantes y conduzcan a un procesamiento ineficiente de datos.
Costo: Expandir el tamaño de la ventana de contexto en los LLM resulta en mayores costos computacionales. Procesar un mayor número de tokens de entrada requiere más recursos, lo que lleva a un aumento de los gastos operativos. Por ejemplo, en sistemas como ChatGPT, se enfoca en limitar el número de tokens procesados para mantener los costos bajo control.
RAG optimiza directamente cada uno de estos tres factores. Al pasar solo documentos similares o relacionados como contexto (en lugar de incluir todo), los LLM procesan la información más rápidamente, lo que no solo reduce la latencia, sino que también mejora la calidad de las respuestas y reduce el costo.
# Por qué no Ajustar
Además de utilizar una ventana contextual más grande, otra alternativa a RAG es el ajuste fino. Sin embargo, el ajuste fino puede ser costoso y complicado. Es un desafío actualizar un LLM cada vez que llega nueva información para mantenerlo actualizado. Otros problemas con el ajuste fino incluyen:
- Limitaciones de los datos de entrenamiento: No importa los avances realizados en los LLM, siempre habrá contextos que no estuvieron disponibles en el momento del entrenamiento o que no se consideraron relevantes.
- Recursos computacionales: Para ajustar finamente un LLM en su conjunto de datos y adaptarlo a tareas específicas, se necesitan recursos computacionales altos.
- Se requiere experiencia: Desarrollar y mantener IA de vanguardia no es para los débiles de corazón. Se necesitan habilidades y conocimientos especializados que pueden ser difíciles de encontrar.
Otros problemas incluyen la recopilación de datos, asegurarse de que la calidad sea lo suficientemente buena y la implementación del modelo.
# Comparación entre RAG y Ajuste Fino o Ventanas de Contexto Largas
A continuación se muestra una descripción comparativa de RAG y las técnicas de ajuste fino o ventanas de contexto largas (debido a que las dos últimas tienen características similares, las he combinado en este cuadro). Destaca aspectos clave como el costo, la actualidad de los datos y la escalabilidad.
| Característica | RAG | Ajuste Fino / Ventanas de Contexto Largas |
| Costo | Mínimo, no requiere entrenamiento | Alto, requiere entrenamiento y actualización extensivos |
| Actualidad de los Datos | Datos recuperados bajo demanda, asegurando actualidad | Los datos pueden volverse rápidamente obsoletos |
| Transparencia | Alta, muestra los documentos recuperados | Baja, no está claro cómo los datos influyen en los resultados |
| Escalabilidad | Alta, se integra fácilmente con diversas fuentes de datos | Limitada, escalar requiere recursos significativos |
| Rendimiento | La recuperación selectiva de datos mejora el rendimiento | El rendimiento puede degradarse con tamaños de contexto más grandes |
| Adaptabilidad | Se puede adaptar a tareas específicas sin necesidad de reentrenamiento | Requiere reentrenamiento para adaptaciones significativas |

# Optimizando los Sistemas RAG con Bases de Datos Vectoriales
Los LLM de última generación pueden procesar millones de tokens simultáneamente, pero la complejidad y la evolución constante de las estructuras de datos dificultan que los LLM gestionen de manera efectiva datos empresariales heterogéneos. RAG aborda estos desafíos, aunque la precisión de recuperación sigue siendo un cuello de botella importante para el rendimiento de extremo a extremo. Ya sea la ventana de contexto grande de los LLM o RAG, el objetivo es aprovechar al máximo los grandes datos y garantizar la alta eficiencia del procesamiento de datos a gran escala.
La integración de LLM con grandes datos utilizando bases de datos vectoriales SQL avanzadas como MyScaleDB (opens new window) mejora la efectividad de los LLM y facilita una mejor extracción de inteligencia de los grandes datos. Además, mitiga la alucinación del modelo, ofrece transparencia de datos y mejora la confiabilidad. MyScaleDB, una base de datos vectorial SQL de código abierto construida sobre ClickHouse (opens new window), está diseñada para aplicaciones de IA/RAG a gran escala. Aprovechando ClickHouse como base y presentando el algoritmo MSTG propietario, MyScaleDB demuestra un rendimiento superior en la gestión de datos a gran escala en comparación con otras bases de datos vectoriales (opens new window).
La tecnología de LLM está cambiando el mundo y la importancia de la memoria a largo plazo persistirá. Los desarrolladores de aplicaciones de IA siempre buscan el equilibrio perfecto entre la calidad de la consulta y el costo. Cuando las grandes empresas ponen en producción la IA generativa, necesitan controlar los costos mientras mantienen la mejor calidad de respuesta. RAG y las bases de datos vectoriales siguen siendo herramientas importantes para lograr este objetivo.
Te invitamos a explorar MyScaleDB en GitHub (opens new window) o a discutir más sobre LLM o RAG en nuestro Discord (opens new window).
Este artículo fue publicado originalmente en The New Stack. (opens new window)




