
Recientemente, MyScale presentó la función EmbedText (opens new window), una potente característica que integra consultas SQL con capacidades de vectorización de texto, convirtiendo el texto en vectores numéricos. Estos vectores mapean eficazmente las similitudes semánticas percibidas por los humanos en proximidades dentro de un espacio vectorial. Utilizando la sintaxis familiar de SQL, EmbedText simplifica el proceso de vectorización, mejorando su accesibilidad y permitiendo a los usuarios realizar de manera eficiente la vectorización de texto en MyScale con proveedores como OpenAI (opens new window), Jina AI (opens new window), Amazon Bedrock (opens new window), y otros, tanto en tiempo real como en escenarios de procesamiento por lotes. Además, al aprovechar el batching automático, se mejora en gran medida el rendimiento del procesamiento de grandes cantidades de datos. Esta integración elimina la necesidad de herramientas externas o programación compleja, simplificando el proceso de vectorización dentro del entorno de la base de datos de MyScale.
# Introducción
La función EmbedText, definida como EmbedText(texto, proveedor, base_url, api_key, otros), es altamente configurable y está diseñada tanto para búsqueda en tiempo real como para procesamiento por lotes.
Nota:
Los parámetros detallados de esta función están disponibles en nuestra documentación (opens new window).
Como se describe en la siguiente tabla, la función EmbedText admite ocho proveedores, cada uno con ventajas únicas:
| Proveedor | Soportado | Proveedor | Soportado |
|---|---|---|---|
| OpenAI | ✔ | Amazon Bedrock | ✔ |
| HuggingFace | ✔ | Amazon SageMaker | ✔ |
| Cohere | ✔ | Jina AI | ✔ |
| Voyage AI | ✔ | Gemini | ✔ |
Por ejemplo, el modelo text-embedding-ada-002 de OpenAI (opens new window) es conocido por su sólido rendimiento. Se puede utilizar en MyScale con el siguiente comando SQL:
SELECT EmbedText('TU_TEXTO', 'OpenAI', '', 'API_KEY', '{"model":"text-embedding-ada-002"}')
El modelo jina-embeddings-v2-base-en de Jina AI (opens new window) admite longitudes de secuencia extensas, de hasta 8k, ofreciendo una alternativa rentable y compacta para la dimensión de embedding. Así es cómo se utiliza este modelo:
SELECT EmbedText('TU_TEXTO', 'Jina', '', 'API_KEY', '{"model":"jina-embeddings-v2-base-en"}')
Nota:
Este modelo actualmente está limitado solo a textos en inglés.
Amazon Bedrock Titan (opens new window), compatible con los modelos de OpenAI, se destaca por su integración con AWS y sus características de seguridad, proporcionando una solución integral para los usuarios de AWS, como se describe en el siguiente fragmento de código:
SELECT EmbedText('TU_TEXTO', 'Bedrock', '', 'SECRET_ACCESS_KEY', '{"model":"amazon.titan-embed-text-v1", "region_name":"us-east-1", "access_key_id":"ACCESS_KEY_ID"}')
# Creación de funciones dedicadas
Para facilitar su uso, puedes crear funciones dedicadas para cada proveedor. Por ejemplo, puedes definir la siguiente función con el modelo text-embedding-ada-002 de OpenAI:
CREATE FUNCTION OpenAIEmbedText ON CLUSTER '{cluster}'
AS (x) -> EmbedText(x, 'OpenAI', '', 'API_KEY', '{"model":"text-embedding-ada-002"}')
Luego, la función OpenAIEmbedText se simplifica a:
SELECT OpenAIEmbedText('TU_TEXTO')
Este enfoque simplifica el proceso de embedding y reduce la entrada repetitiva de parámetros comunes como las claves de API.
# Procesamiento de vectores con EmbedText
EmbedText revoluciona el procesamiento de vectores en MyScale, especialmente para la búsqueda vectorial y la transformación de datos. Esta función es fundamental para transformar tanto las consultas de búsqueda como las columnas de la base de datos en vectores numéricos, un paso crítico en la búsqueda vectorial y la gestión de datos.
# Mejorando la búsqueda vectorial
En la búsqueda de similitud vectorial, como se detalla en nuestra guía de búsqueda vectorial (opens new window), y como se describe en el siguiente fragmento de código, el enfoque tradicional requiere que los usuarios ingresen manualmente los vectores de consulta en SQL.
SELECT id, distance(vector, [0.123, 0.234, ...]) AS dist
FROM test_embedding ORDER BY dist LIMIT 10
Como se muestra en el siguiente fragmento de código, el uso de EmbedText agiliza el proceso de búsqueda vectorial, lo hace más intuitivo, simplifica considerablemente la experiencia del usuario y pone el foco en la formulación de consultas en lugar de en la mecánica de creación de vectores.
SELECT id, distance(vector, OpenAIEmbedText('la consulta de texto')) AS dist
FROM test_embedding ORDER BY dist LIMIT 10
# Simplificando las transformaciones por lotes
Basándonos en este diagrama, podemos ver que el flujo de trabajo típico para las transformaciones por lotes implica el preprocesamiento y almacenamiento de los datos de texto en un formato estructurado.
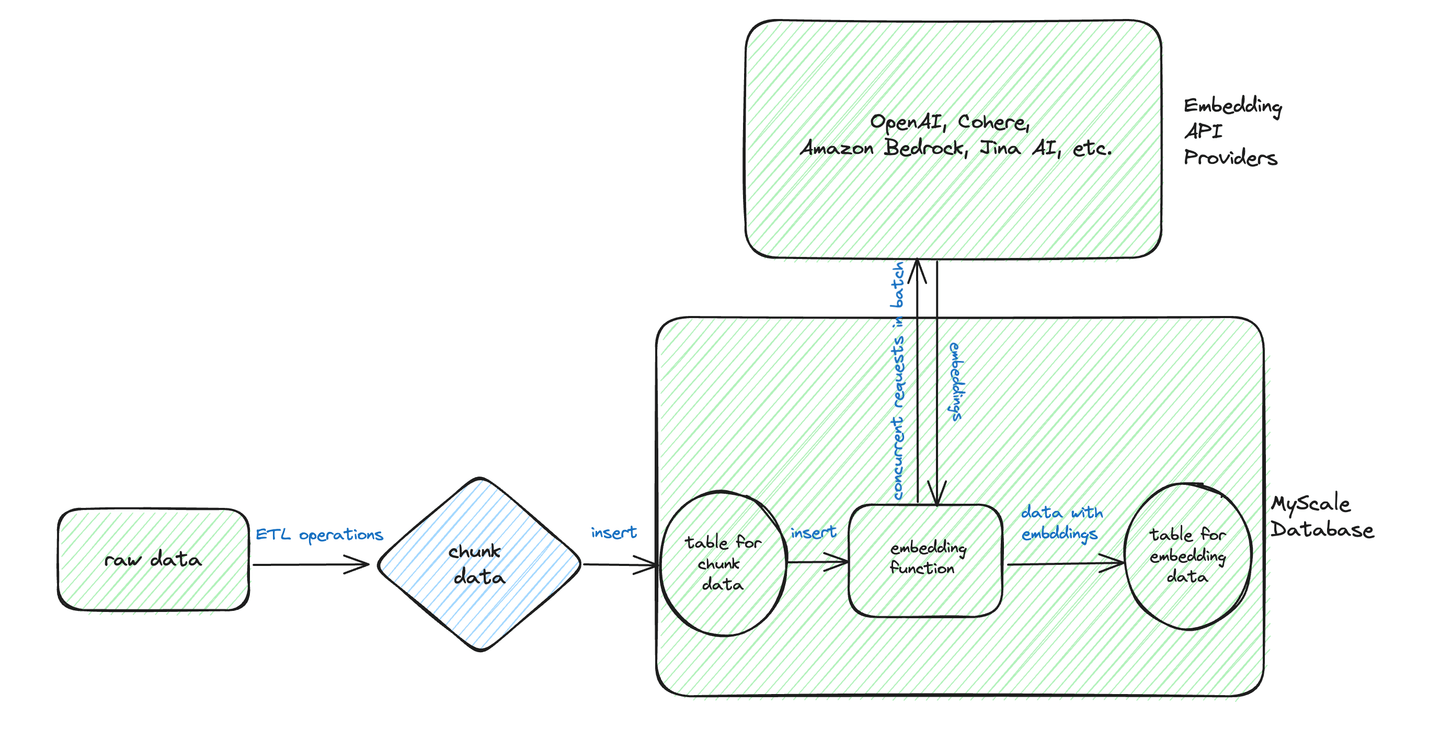
Supongamos que tenemos la siguiente tabla chunk_data que contiene datos en bruto.
CREATE TABLE chunk_data
(
id UInt32,
chunk String,
) ENGINE = MergeTree ORDER BY id
INSERT INTO chunk_data VALUES (1, 'chunk1'), (2, 'chunk2'), ...
Podemos crear una segunda tabla, la tabla test_embedding, para almacenar los embeddings vectoriales creados de la siguiente manera, utilizando la función EmbedText.
CREATE TABLE test_embedding
(
id UInt32,
paragraph String,
vector Array(Float32) DEFAULT OpenAIEmbedText(paragraph),
CONSTRAINT check_length CHECK length(vector) = 1536,
) ENGINE = MergeTree ORDER BY id
La inserción de datos en test_embedding se vuelve sencilla.
INSERT INTO test_embedding (id, paragraph) SELECT id, chunk FROM chunk_data
Alternativamente, EmbedText se puede aplicar explícitamente durante la inserción.
INSERT INTO test_embedding (id, paragraph, vector) SELECT id, chunk, OpenAIEmbedText(chunk) FROM chunk_data
Como se destacó anteriormente, EmbedText incluye una característica de batching automático que mejora significativamente la eficiencia al procesar varios textos. Esta característica gestiona internamente el proceso de batching antes de enviar los datos a la API de embedding, asegurando un flujo de trabajo de procesamiento de datos eficiente y simplificado. Un ejemplo de esta eficiencia se demuestra con el modelo BAAI/bge-small-en (opens new window) en una GPU NVIDIA A10G, logrando hasta 1200 solicitudes por segundo.

# Conclusión
La función EmbedText de MyScale es una herramienta práctica y eficiente de vectorización de texto, que simplifica procesos complejos y democratiza la búsqueda vectorial avanzada y la transformación de datos. Nuestra visión es integrar esta innovación de manera transparente en las operaciones diarias de la base de datos, empoderando a una amplia gama de usuarios en el procesamiento de datos relacionados con IA/LLM.




