
Los grandes modelos de lenguaje (LLM, por sus siglas en inglés) son sistemas avanzados de inteligencia artificial que pueden responder una amplia gama de preguntas. Aunque proporcionan respuestas informativas sobre los temas que conocen, no siempre son precisos en temas desconocidos. Este fenómeno se conoce como alucinación.
![]()
# ¿Qué es la alucinación?
Antes de ver un ejemplo de alucinación de un LLM, consideremos una definición del término "alucinación" según Wikipedia.com (opens new window):
"Una alucinación es una percepción en ausencia de un estímulo externo que tiene las cualidades de una percepción real."
Además:
"Las alucinaciones son vívidas, sustanciales y se perciben como ubicadas en un espacio objetivo externo."
En otras palabras, una alucinación es un error en (o una percepción falsa de) algo real o concreto. Por ejemplo, se le preguntó a ChatGPT (un famoso LLM de OpenAI) qué son las alucinaciones de LLM, y la respuesta fue:

Por lo tanto, la pregunta es: ¿cómo mejoramos (o corregimos) este resultado? La respuesta concisa es agregar hechos a tu pregunta, como proporcionar la definición de LLM antes o después de hacer la pregunta.
Por ejemplo:
Un LLM es un modelo de lenguaje grande, una red neuronal artificial que modela cómo hablan y escriben los humanos. Por favor, dime, ¿qué es la alucinación de LLM?
La respuesta de dominio público a esta pregunta, proporcionada por ChatGPT, es:

Nota:
La razón de la primera frase, "Disculpa por la confusión en mi respuesta anterior", es que le hicimos a ChatGPT nuestra primera pregunta, qué son las alucinaciones de LLM, antes de darle nuestra segunda indicación: "Un LLM..."
Estas adiciones han mejorado la calidad de la respuesta. Al menos ya no piensa que una alucinación de LLM es un "Acompañamiento de migraña tardía en la vida" 😆
# El conocimiento externo reduce las alucinaciones
En este punto, es absolutamente crucial tener en cuenta que un LLM no es infalible ni la máxima autoridad en todo el conocimiento. Los LLM se entrenan con grandes cantidades de datos y aprenden patrones en el lenguaje, pero no siempre tienen acceso a la información más actualizada ni tienen una comprensión completa de temas complejos.
¿Y ahora qué? ¿Cómo aumentas la probabilidad de reducir las alucinaciones de LLM?
La solución a este problema es incluir documentos de apoyo en la consulta (o indicación) para guiar al LLM hacia una respuesta más precisa e informada. Al igual que los humanos, necesita aprender de estos documentos para responder tu pregunta de manera precisa y correcta.
Los documentos útiles pueden provenir de muchas fuentes, como un motor de búsqueda como Google o Bing y una biblioteca digital como Arxiv, entre otros, que proporcionan una interfaz para buscar pasajes relevantes. El uso de una base de datos también es una buena opción, ya que proporciona una interfaz de consulta más flexible y privada.
El conocimiento recuperado de las fuentes debe ser relevante para la pregunta/indicación. Hay varias formas de recuperar documentos relevantes, que incluyen:
- Basado en palabras clave: Búsqueda de palabras clave en texto plano, adecuado para una coincidencia exacta en términos.
- Basado en búsqueda vectorial: Búsqueda de registros más cercanos a los vectores, útil para buscar paráfrasis adecuadas o documentos generales.
Hoy en día, las búsquedas vectoriales son populares porque pueden resolver problemas de paráfrasis y calcular el significado de los párrafos. La búsqueda vectorial no es una solución única para todos los casos; debe combinarse con filtros específicos para mantener su rendimiento, especialmente al buscar volúmenes masivos de registros. Por ejemplo, si solo deseas recuperar conocimiento sobre física (como materia), debes filtrar toda la información sobre cualquier otra materia. De esta manera, el LLM no se confundirá con el conocimiento de otras disciplinas.
# Automatiza todo el proceso con SQL... y búsqueda vectorial
El LLM también debe aprender a consultar datos de sus fuentes de datos antes de responder las preguntas, automatizando todo el proceso. De hecho, los LLM ya son capaces de escribir consultas SQL y seguir instrucciones.
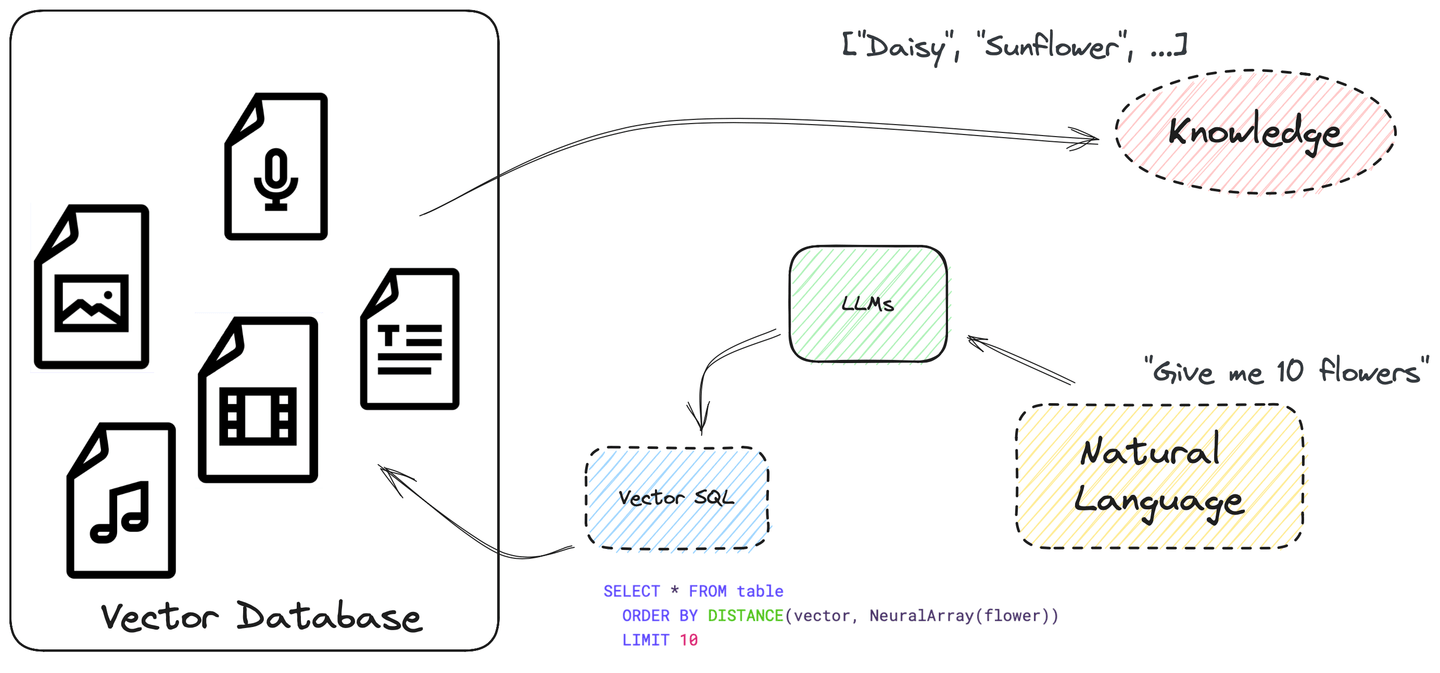
SQL es poderoso y se puede utilizar para construir consultas de búsqueda complejas. Admite muchos tipos de datos y funciones. Y te permite escribir una búsqueda vectorial en SQL con ORDER BY y LIMIT, tratando la puntuación de similitud entre vectores como una columna distancia. Bastante sencillo, ¿verdad?
Consulta la siguiente sección, Cómo se ve SQL vectorial, para obtener más información sobre cómo estructurar una consulta SQL vectorial.
Hay beneficios significativos al utilizar SQL vectorial para construir consultas de búsqueda complejas, que incluyen:
- Mayor flexibilidad para admitir tipos de datos y funciones
- Mejora de la eficiencia porque SQL está altamente optimizado y se ejecuta dentro de la base de datos
- Es legible para los humanos y fácil de aprender, ya que es una extensión de SQL estándar
- Es amigable para los LLM
Nota:
Hay muchos ejemplos y tutoriales de SQL disponibles en Internet. Los LLM están familiarizados con SQL estándar y algunos de sus dialectos.
Además de MyScale, muchas soluciones de bases de datos SQL como ClickHouse y PostgreSQL están agregando búsqueda vectorial a su funcionalidad existente, lo que permite a los usuarios utilizar SQL vectorial y LLM para responder preguntas sobre temas complejos. Del mismo modo, un número creciente de desarrolladores de aplicaciones están comenzando a integrar búsquedas vectoriales con SQL en sus aplicaciones.
# Cómo se ve SQL vectorial
El lenguaje de consulta estructurado vectorial (Vector SQL) está diseñado para enseñar a los LLM cómo consultar bases de datos SQL vectoriales y contiene las siguientes funciones adicionales:
DISTANCE(columna, vector_consulta): Esta función compara la distancia entre la columna de vectores y el vector de consulta ya sea de manera exacta o aproximada.NeuralArray(entidad): Esta función convierte una entidad (por ejemplo, una imagen o un fragmento de texto) en un vector incrustado.
Con estas dos funciones, podemos ampliar el SQL estándar para la búsqueda vectorial. Por ejemplo, si deseas buscar 10 registros relevantes para la palabra flor, puedes usar la siguiente instrucción SQL:
SELECT * FROM tabla
ORDER BY DISTANCE(vector, NeuralArray(flor))
LIMIT 10
La función DISTANCE consta de lo siguiente:
- La función interna
NeuralArray(flor)convierte la palabrafloren un vector incrustado. - Este vector incrustado se serializa e inyecta en la función
DISTANCE.
El SQL vectorial es una versión extendida de SQL que requiere una traducción adicional según la base de datos vectorial utilizada. Por ejemplo, muchas implementaciones tienen nombres diferentes para la función DISTANCE. Se llama distance en MyScale y L2Distance o CosineDistance en ClickHouse. Además, según la base de datos, este nombre de función se traducirá de manera diferente.
# Cómo enseñar a un LLM a escribir Vector SQL
Ahora que entendemos los principios básicos de SQL vectorial y sus funciones únicas, usemos un LLM para ayudarnos a escribir una consulta SQL vectorial.
# 1. Enseña a un LLM qué es el SQL vectorial estándar
Primero, debemos enseñar a nuestro LLM qué es el SQL vectorial estándar. Nuestro objetivo es asegurarnos de que el LLM haga espontáneamente las siguientes tres cosas al escribir una consulta SQL vectorial:
- Extraer las palabras clave de nuestra pregunta/indicación. Puede ser un objeto, un concepto o un tema.
- Decidir qué columna utilizar para realizar la búsqueda de similitud. Siempre debe elegir una columna de vectores para la similitud.
- Traducir el resto de las restricciones de nuestra pregunta en SQL válido.
# 2. Diseña la indicación del LLM
Una vez que hayas determinado exactamente qué información necesita el LLM para construir una consulta SQL vectorial, puedes diseñar la indicación de la siguiente manera:
# Aquí tienes un ejemplo de una indicación de SQL vectorial
_prompt = f"""Eres un experto en MyScale. Dada una pregunta de entrada, primero crea una consulta de MyScale sintácticamente correcta para ejecutar, luego observa los resultados de la consulta y devuelve la respuesta a la pregunta de entrada.
Las consultas de MyScale tienen una función de distancia vectorial llamada `DISTANCE(columna, array)` para calcular la relevancia con la pregunta del usuario y ordenar la columna de características por relevancia.
Cuando la consulta solicite {top_k} fila(s) más cercana(s), debes utilizar esta función de distancia para calcular la distancia al vector de la entidad en la columna vector y ordenar por la distancia para recuperar las filas relevantes.
*AVISO*: `DISTANCE(columna, array)` solo acepta una columna de tipo array como su primer argumento y un `NeuralArray(entidad)` como su segundo argumento. También necesitas una función definida por el usuario llamada `NeuralArray(entidad)` para recuperar el vector de la entidad.
A menos que el usuario especifique en la pregunta un número específico de ejemplos a obtener, consulta como máximo {top_k} resultados utilizando la cláusula LIMIT según MyScale. Solo debes ordenar según la función de distancia.
Nunca consultes todas las columnas de una tabla. Solo debes consultar las columnas necesarias para responder la pregunta. Envuelve cada nombre de columna entre comillas dobles (") para denotarlas como identificadores delimitados.
Presta atención a utilizar solo los nombres de columna que puedas ver en las tablas a continuación. Ten cuidado de no consultar columnas que no existan. Además, presta atención a qué columna está en qué tabla.
Presta atención a utilizar la función today() para obtener la fecha actual, si la pregunta involucra "hoy". La cláusula `ORDER BY` siempre debe ir después de la cláusula `WHERE`. NO agregues punto y coma al final del SQL. Presta atención al comentario en el esquema de la tabla.
Utiliza el siguiente formato:
======== información de la tabla ========
<alguna información de la tabla>
Pregunta: "Aquí va la pregunta"
ConsultaSQL: "Consulta SQL a ejecutar"
Comencemos:
======== información de la tabla ========
{información_de_la_tabla}
Pregunta: {entrada}
ConsultaSQL:
Esta indicación debería funcionar. Pero cuanto más ejemplos agregues, mejor será, como usar el siguiente par de SQL a texto como indicación:
La declaración de creación de tabla SQL:
------ esquema de la tabla ------
CREATE TABLE "ChatPaper" (
abstract String,
id String,
vector Array(Float32),
categories Array(String),
pubdate DateTime,
title String,
authors Array(String),
primary_category String
) ENGINE = ReplicatedReplacingMergeTree()
ORDER BY id
PRIMARY KEY id
La pregunta y respuesta:
Pregunta: ¿Qué es PaperRank? ¿Cuál es la contribución de estos trabajos? Utiliza los trabajos con más de 2 categorías.
ConsultaSQL: SELECT ChatPaper.title, ChatPaper.id, ChatPaper.authors FROM ChatPaper WHERE length(categories) > 2 ORDER BY DISTANCE(vector, NeuralArray(PaperRank contribution)) LIMIT {top_k}
Cuanto más ejemplos relevantes agregues a tu indicación, mejor será el proceso del LLM para construir la consulta SQL vectorial correcta.
Por último, aquí tienes algunos consejos adicionales para ayudarte al diseñar tu indicación:
- Cubre todas las funciones posibles que puedan aparecer en cualquier pregunta realizada.
- Evita preguntas monótonas.
- Modifica el esquema de la tabla, como agregar/eliminar/modificar nombres y tipos de datos.
- Alinea el formato de la indicación.

# Un ejemplo del mundo real: utilizando MyScale
Ahora construyamos un ejemplo del mundo real (opens new window), que se desarrolla en los siguientes pasos:

# Prepara la base de datos
Hemos preparado un entorno de pruebas para ti con más de 2 millones de artículos listos para ser consultados. Puedes acceder a estos datos agregando el siguiente código Python a tu aplicación.
from sqlalchemy import create_engine
MYSCALE_HOST = "msc-950b9f1f.us-east-1.aws.myscale.com"
MYSCALE_PORT = 443
MYSCALE_USER = "chatdata"
MYSCALE_PASSWORD = "myscale_rocks"
engine = create_engine(f'clickhouse://{MYSCALE_USER}:{MYSCALE_PASSWORD}@{MYSCALE_HOST}:{MYSCALE_PORT}/default?protocol=https')
Si lo prefieres, puedes omitir los siguientes pasos, donde creamos la tabla e insertamos los datos utilizando la consola de MyScale, y saltar a donde jugamos con SQL vectorial y creamos la SQLDatabaseChain para consultar la base de datos.
Crea la tabla de la base de datos:
CREATE TABLE default.ChatArXiv (
`abstract` String,
`id` String,
`vector` Array(Float32),
`metadata` Object('JSON'),
`pubdate` DateTime,
`title` String,
`categories` Array(String),
`authors` Array(String),
`comment` String,
`primary_category` String,
CONSTRAINT vec_len CHECK length(vector) = 768)
ENGINE = ReplacingMergeTree ORDER BY id SETTINGS index_granularity = 8192
Inserta los datos:
INSERT INTO ChatArXiv
SELECT
abstract, id, vector, metadata,
parseDateTimeBestEffort(JSONExtractString(toJSONString(metadata), 'pubdate')) AS pubdate,
JSONExtractString(toJSONString(metadata), 'title') AS title,
arrayMap(x->trim(BOTH '"' FROM x), JSONExtractArrayRaw(toJSONString(metadata), 'categories')) AS categories,
arrayMap(x->trim(BOTH '"' FROM x), JSONExtractArrayRaw(toJSONString(metadata), 'authors')) AS authors,
JSONExtractString(toJSONString(metadata), 'comment') AS comment,
JSONExtractString(toJSONString(metadata), 'primary_category') AS primary_category
FROM
s3(
'https://myscale-demo.s3.ap-southeast-1.amazonaws.com/chat_arxiv/data.part*.zst',
'JSONEachRow',
'abstract String, id String, vector Array(Float32), metadata Object(''JSON'')',
'zstd'
);
ALTER TABLE ChatArXiv ADD VECTOR INDEX vec_idx vector TYPE MSTG('metric_type=Cosine');
# Crea la VectorSQLDatabaseChain
Necesitarás el paquete experimental LangChain para VectorSQLDatabaseChain. Puedes instalarlo ejecutando el siguiente script de instalación:
python3 -m venv .venv
source .venv/bin/activate
pip3 install langchain langchain-experimental --upgrade
Una vez que hayas instalado esta función, el siguiente paso es utilizarla para consultar la base de datos, como se muestra en el siguiente código Python:
from sqlalchemy import create_engine
MYSCALE_HOST = "msc-950b9f1f.us-east-1.aws.myscale.com"
MYSCALE_PORT = 443
MYSCALE_USER = "chatdata"
MYSCALE_PASSWORD = "myscale_rocks"
# crea una conexión a la base de datos
engine = create_engine(f'clickhouse://{MYSCALE_USER}:{MYSCALE_PASSWORD}@{MYSCALE_HOST}:{MYSCALE_PORT}/default?protocol=https')
from langchain.embeddings import HuggingFaceInstructEmbeddings
from langchain.callbacks import StdOutCallbackHandler
from langchain.llms import OpenAI
from langchain.utilities.sql_database import SQLDatabase
from langchain_experimental.sql.prompt import MYSCALE_PROMPT
from langchain_experimental.sql.vector_sql import VectorSQLDatabaseChain
from langchain_experimental.sql.vector_sql import VectorSQLRetrieveAllOutputParser
# este analizador convierte `NeuralArray()` en vectores incrustados
output_parser = VectorSQLRetrieveAllOutputParser(
model=HuggingFaceInstructEmbeddings(model_name='hkunlp/instructor-xl')
)
# utiliza la indicación anterior
PROMPT = PromptTemplate(
input_variables=["input", "table_info", "top_k"],
template=_prompt,
)
# vincula los metadatos al motor de SqlAlchemy
metadata = MetaData(bind=engine)
# crea la cadena de SQLDatabaseChain
query_chain = VectorSQLDatabaseChain.from_llm(
# GPT-3.5 genera SQL válido mejor
llm=OpenAI(openai_api_key=OPENAI_API_KEY, temperature=0),
# utiliza la indicación predefinida, cámbiala por tu propia indicación
prompt=PROMPT,
# devuelve los 10 documentos relevantes principales
top_k=10,
# utiliza el resultado directamente de la base de datos
return_direct=True,
# utiliza nuestra base de datos para la recuperación
db=SQLDatabase(engine, None, metadata),
# convierte `NeuralArray()` en vectores incrustados
sql_cmd_parser=output_parser)
# ¡lanza la cadena! Y rastrea todas las llamadas de la cadena en la salida estándar
query_chain.run("Presenta algunos artículos que utilizan Redes Generativas Adversarias publicados alrededor de 2019.",
callbacks=[StdOutCallbackHandler()])
# Pregunta con RetrievalQAwithSourcesChain
También puedes utilizar esta VectorSQLDatabaseChain como un recuperador. Puedes conectarlo a algunas cadenas de preguntas y respuestas con recuperadores, al igual que otros recuperadores en LangChain.
from langchain_experimental.retrievers.vector_sql_database \
import VectorSQLDatabaseChainRetriever
from langchain.chains.qa_with_sources.map_reduce_prompt import combine_prompt_template
OPENAI_API_KEY = "sk-***"
# define cómo serializas esos datos estructurados de la base de datos
document_with_metadata_prompt = PromptTemplate(
input_variables=["page_content", "id", "title", "authors", "pubdate", "categories"],
template="Contenido:\n\tTítulo: {title}\n\tResumen: {page_content}\n\t" +
"Autores: {authors}\n\tFecha de publicación: {pubdate}\n\tCategorías: {categories}\nFUENTE: {id}"
)
# define la indicación que utilizas para preguntar al LLM
COMBINE_PROMPT = PromptTemplate(
template=combine_prompt_template, input_variables=["summaries", "question"])
# define un recuperador con una SQLDatabaseChain
retriever = VectorSQLDatabaseChainRetriever(
sql_db_chain=query_chain, page_content_key="abstract")
# finalmente, la cadena de preguntas para organizar todo esto
ask_chain = RetrievalQAWithSourcesChain.from_chain_type(
ChatOpenAI(model_name='gpt-3.5-turbo-16k',
openai_api_key=OPENAI_API_KEY, temperature=0.6),
retriever=retriever,
chain_type='stuff',
chain_type_kwargs={
'prompt': COMBINE_PROMPT,
'document_prompt': document_with_metadata_prompt,
}, return_source_documents=True)
# ¡Ejecuta la cadena! y obtén el resultado del LLM
ask_chain("Presenta algunos artículos que utilizan Redes Generativas Adversarias publicados alrededor de 2019.",
callbacks=[StdOutCallbackHandler()])
¡También proporcionamos una demostración en vivo en huggingface (opens new window) y el código está disponible en GitHub (opens new window)! ¡Utilizamos una cadena de preguntas y respuestas de recuperación personalizada (opens new window) para maximizar el rendimiento de nuestro pipeline de búsqueda y pregunta con LangChain!
# En conclusión
En la realidad, la mayoría de los LLM alucinan. La forma más práctica de reducir su aparición es agregar hechos adicionales (conocimiento externo) a tu pregunta. El conocimiento externo es crucial para mejorar el rendimiento de los sistemas de LLM, permitiendo la recuperación eficiente y precisa de respuestas. Cada palabra cuenta, y no quieres desperdiciar tu dinero en información no utilizada que se recupera mediante consultas inexactas.
¿Cómo?
Introduce Vector SQL, que te permite realizar búsquedas vectoriales detalladas para encontrar y recuperar la información requerida.
Vector SQL es poderoso y fácil de aprender para humanos y máquinas. Puedes utilizar muchos tipos de datos y funciones para crear consultas complejas. A los LLM también les gusta Vector SQL, ya que su conjunto de datos de entrenamiento incluye muchas referencias.
Por último, es posible traducir Vector SQL a muchas bases de datos vectoriales utilizando diferentes modelos de incrustación. Creemos que ese es el futuro de las bases de datos vectoriales.
¿Estás interesado en lo que estamos haciendo? ¡Únete a nosotros en discord (opens new window) hoy mismo!



