
Como uno de nuestros artículos anteriores exploró (opens new window), la búsqueda vectorial avanza significativamente en la recuperación de información con un enfoque más matizado y contextualmente consciente que el emparejamiento tradicional de palabras clave. La transformación de texto en vectores numéricos alinea el significado contextual de las consultas de búsqueda con los datos, mejorando así la relevancia de los resultados de búsqueda.
Sin embargo, también surgen desafíos con la búsqueda vectorial, especialmente la posible pérdida de información durante las transformaciones de texto a vector, lo que requiere la adopción de métodos adicionales para mejorar la precisión de la búsqueda.
¿Cuáles son estos métodos adicionales?
La respuesta breve a esta pregunta es que uno de los "métodos adicionales" más significativos es implementar un sistema de recuperación en dos etapas al utilizar la búsqueda vectorial para recuperar información.
Ampliemos esta respuesta adentrándonos en una guía paso a paso para implementar una metodología de recuperación en dos etapas con MyScale, demostrando cómo combinar la búsqueda vectorial y el reordenamiento para optimizar los sistemas de recuperación de información de manera eficiente y efectiva.
# ¿Qué es el reordenamiento?
Pero primero, definamos el reordenamiento y consideremos por qué forma parte del proceso de recuperación en dos etapas.
De manera sucinta, el reordenamiento reordena los resultados de búsqueda para aumentar la relevancia contextual de una búsqueda vectorial. Según https://en.wiktionary.org/wiki/reranking (opens new window), es "el acto de clasificar algo nuevamente o de manera diferente... [Por ejemplo,] el algoritmo realiza varios reordenamientos antes de llegar al resultado óptimo".
El reordenamiento, a menudo implementado con un modelo de codificador cruzado (opens new window), mejora los resultados de búsqueda al proporcionar un conjunto más refinado de resultados. A diferencia de la búsqueda vectorial inicial, que resume los documentos en vectores antes de consultar estos documentos, el reordenamiento procesa la consulta y los documentos juntos, reordenando los resultados de búsqueda con mayor precisión según la relevancia.
Sin embargo, como todo, existen desafíos al utilizar el reordenamiento, siendo el más significativo su alta demanda computacional y su posterior falta de practicidad al procesar conjuntos de datos grandes, lo que restringe considerablemente su potencial de aplicación independiente.
# El sistema de recuperación en dos etapas
Para abordar estos desafíos, se desarrolló un sistema de recuperación en dos etapas, que combina las fortalezas de la búsqueda vectorial y el reordenamiento, comenzando con una búsqueda vectorial para obtener un conjunto inicial de resultados amplio y luego aplicando selectivamente el reordenamiento para lograr una mayor precisión.
# El sistema de recuperación en dos etapas de MyScale
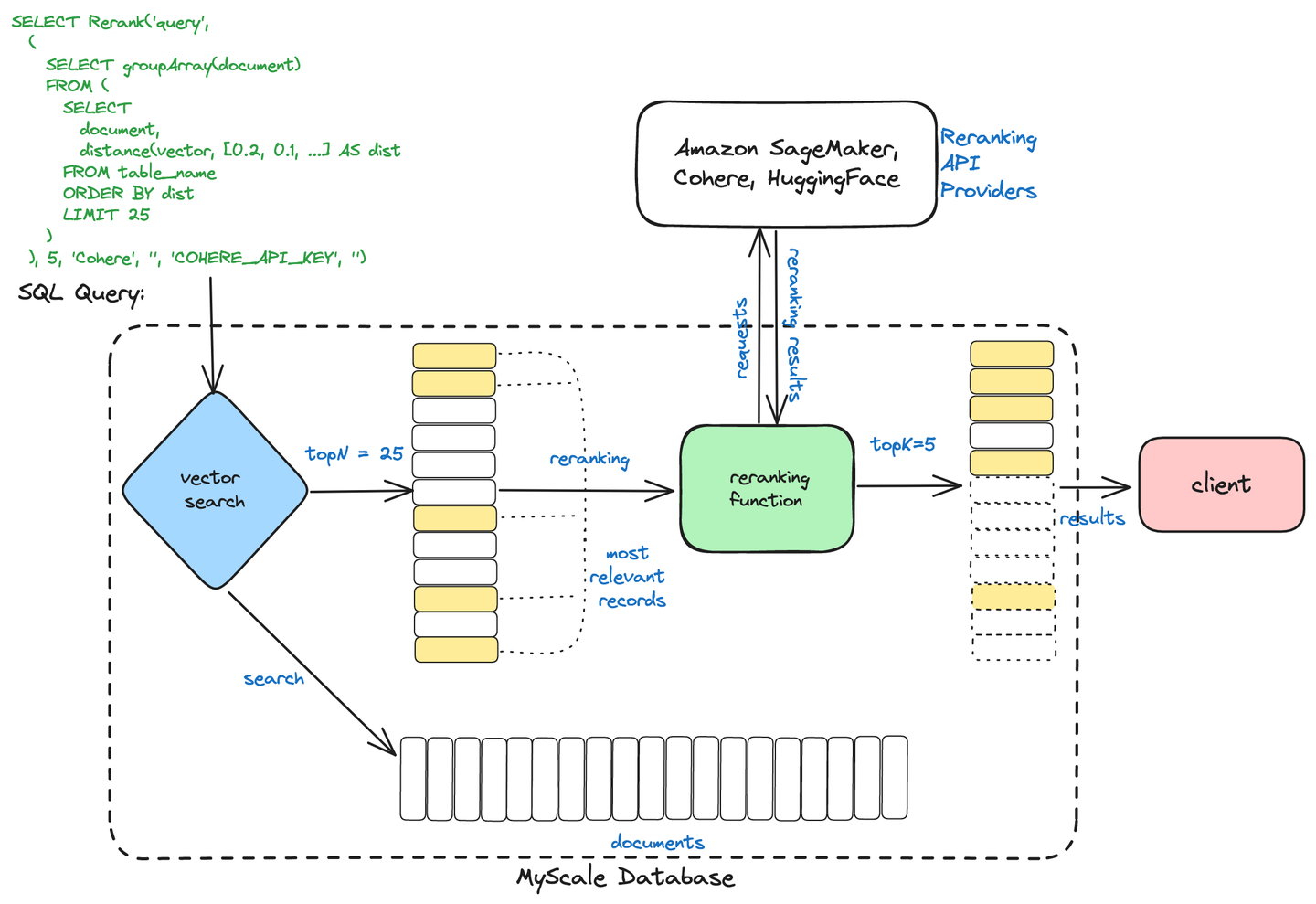
El sistema de recuperación en dos etapas de MyScale comienza con una búsqueda vectorial que escanea la base de datos, seleccionando una amplia gama de documentos que coinciden estrechamente con la semántica de la consulta de búsqueda y reduciendo eficientemente el conjunto de datos masivamente extenso a un subconjunto relevante.
A continuación: Este subconjunto se refina utilizando una función de reordenamiento, ordenándolo cuidadosamente según las puntuaciones de similitud, priorizando la precisión y alineando el conjunto de resultados final lo más cerca posible de la intención del usuario.
Para agilizar este sistema de recuperación en dos etapas, hemos integrado estas funciones de reordenamiento (opens new window) con MyScale, nuestra base de datos vectorial, lo que las hace accesibles mediante una simple consulta SQL.
Nota:
Estas funciones utilizan API de reordenamiento sofisticadas, brindando a los usuarios una interfaz fácil de usar para operaciones de clasificación de datos complejas, así como para condensar la funcionalidad de búsqueda robusta en una experiencia de usuario concisa y eficiente.
Como se ilustra en el siguiente diagrama, los usuarios pueden iniciar este mecanismo de recuperación en dos etapas con un comando sencillo, que incorpora una subconsulta de búsqueda vectorial para devolver los primeros N documentos y una consulta de reordenamiento para ajustar este conjunto de resultados, extrayendo los K documentos más relevantes.
La efectividad de este sistema es evidente en sus métricas de rendimiento. Utilizando OpenAI Embeddings (opens new window) para el análisis, observamos mejoras significativas en la precisión de recuperación. La tasa de acierto aumentó de 0.854545 a 0.895455 utilizando el modelo bge-reranker-base. La Media del Recíproco del Rango (MRR) también aumentó de 0.640303 a 0.707652, lo que demuestra la eficacia del método para obtener resultados de búsqueda relevantes. Estas mejoras subrayan el valor de integrar el reordenamiento en el proceso de recuperación de información.
Nota:
Hemos detallado nuestra metodología de evaluación y los resultados en este cuaderno (opens new window), siguiendo los métodos discutidos en este blog (opens new window) de LlamaIndex.
# Implementación del sistema de recuperación en dos etapas de MyScale
Ahora trabajemos en un ejemplo práctico para comprender mejor nuestro sistema de recuperación en dos etapas, centrándonos en mejorar la aplicación de Preguntas y Respuestas Abstractivas (opens new window) con los detalles descritos en la documentación de MyScale.
Nota:
El único cambio requerido es en la fase de consulta (opens new window) del ejemplo original, todavía estamos utilizando la misma tabla y datos.
La aplicación original de Preguntas y Respuestas Abstractivas transforma las preguntas en vectores utilizando un recuperador separado. A continuación, ejecuta una consulta de búsqueda para encontrar los mejores candidatos (top_k). Ahora, como muestra la siguiente instrucción SQL, con la función de incrustación de MyScale, estos pasos se fusionan en un solo comando SQL.
SELECT summary,
distance(
summary_feature,
CohereEmbedText('what is the difference between bitcoin and traditional money?')
) AS dist
FROM default.myscale_llm_bitcoin_qa
WHERE article_rank < 500
ORDER BY dist LIMIT 10
Esta instrucción SQL utiliza una función de incrustación personalizada, CohereEmbedText, creada con el modelo embed-english-light-v3.0 de Cohere (opens new window), definida en el siguiente fragmento de código.
CREATE FUNCTION CohereEmbedText ON CLUSTER '{cluster}'
AS (x) -> EmbedText(
x,
'Cohere',
'',
'YOUR_COHERE_API_KEY',
'{"model":"embed-english-light-v3.0", "input_type":"search_query"}')
Para agilizar aún más el proceso, introducimos una función de reordenamiento personalizada como se describe en la documentación de funciones (opens new window):
CREATE FUNCTION CohereRerank ON CLUSTER '{cluster}'
AS (x,y,z) -> Rerank(
x, y, z, 'Cohere', '', 'YOUR_COHERE_API_KEY', '');
Con estas funciones en su lugar, ahora podemos implementar el sistema de recuperación en dos etapas utilizando la siguiente instrucción SQL:
SELECT
tupleElement(arrayElement, 2) AS summary,
tupleElement(arrayElement, 3) AS score
FROM (
SELECT arrayJoin(CohereRerank('what is the difference between bitcoin and traditional money?',
(SELECT groupArray(summary)
FROM (
SELECT summary, distance(summary_feature, CohereEmbedText('what is the difference between bitcoin and traditional money?')) as dist
FROM default.myscale_llm_bitcoin_qa
WHERE article_rank < 500
ORDER BY dist
LIMIT 50
)
), 10
)) AS arrayElement
)
Esta instrucción SQL comprende los siguientes pasos para implementar nuestro sistema de recuperación en dos etapas:
- Ampliar los resultados de búsqueda de 10 a 50 para evitar perder información relevante;
- Agrupar los 50 mejores candidatos en un array, para el reordenamiento, utilizando groupArray (opens new window);
- Reordenar estos candidatos según su relevancia con la función
CohereRerank, extrayendo los 10 resúmenes más pertinentes; y finalmente - Utilizar arrayJoin (opens new window) (para desplegar el conjunto de resultados en múltiples filas) y tupleElement (opens new window) (para extraer una columna específica de las filas de resultados) para estructurar los resultados y mejorar su presentación al usuario.

# Conclusión
En resumen, el sistema de recuperación en dos etapas de MyScale ejemplifica el poder de la simplicidad y la eficiencia en la tecnología de búsqueda moderna. Demuestra que incluso procesos sofisticados como la búsqueda vectorial combinada con funciones avanzadas de reordenamiento pueden ejecutarse sin problemas con una sola y sencilla consulta SQL. Este enfoque no solo hace que los procesos de recuperación complejos sean accesibles a una gama más amplia de usuarios, sino que también destaca el compromiso de MyScale de proporcionar herramientas de búsqueda y análisis de datos potentes, pero fáciles de usar.



