
Los sistemas de Generación con Recuperación (RAG) (opens new window) han sido diseñados para mejorar la calidad de respuesta de un modelo de lenguaje grande (LLM, por sus siglas en inglés). Cuando un usuario envía una consulta, el sistema RAG extrae información relevante de una base de datos vectorial y la pasa al LLM como contexto. El LLM utiliza este contexto para generar una respuesta para el usuario. Este proceso mejora significativamente la calidad de las respuestas del LLM con menos “alucinaciones” (opens new window).
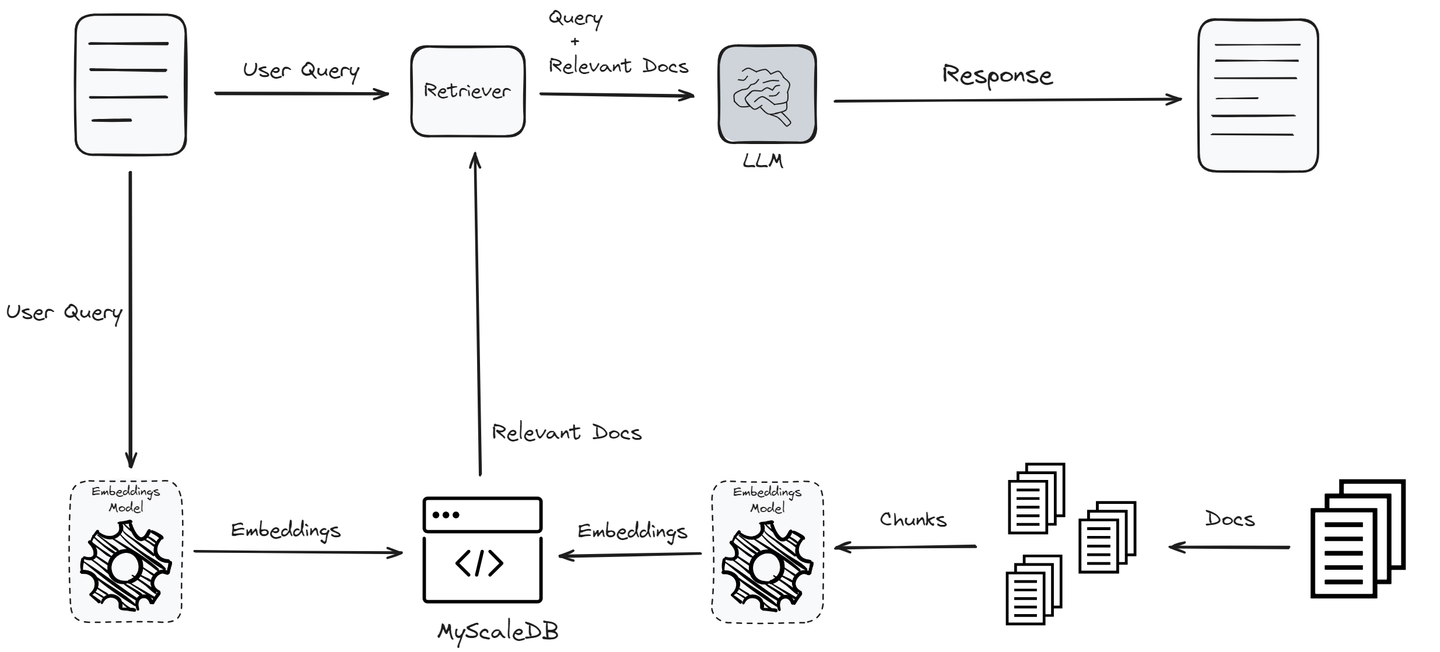
Entonces, en el flujo de trabajo anterior, hay dos componentes principales en un sistema RAG:
Recuperador: Identifica la información más relevante de la base de datos vectorial utilizando la potencia de la búsqueda de similitud. Esta etapa es la parte más crítica de cualquier sistema RAG, ya que sienta las bases para la calidad de la salida final. El recuperador busca en una base de datos vectorial para encontrar documentos relevantes para la consulta del usuario. Esto implica codificar la consulta y los documentos en vectores y utilizar medidas de similitud para encontrar las coincidencias más cercanas.
Generador de respuestas: Una vez que se han recuperado los documentos relevantes, la consulta del usuario y los documentos recuperados se pasan al modelo LLM para generar una respuesta coherente, relevante e informativa. El generador (LLM) utiliza el contexto proporcionado por el recuperador y la consulta original para generar una respuesta precisa.
La efectividad y el rendimiento de cualquier sistema RAG dependen significativamente de estos dos componentes principales: el recuperador y el generador. El recuperador debe identificar y recuperar eficientemente los documentos más relevantes, mientras que el generador debe producir respuestas coherentes, relevantes y precisas utilizando la información recuperada. La evaluación rigurosa de estos componentes es crucial para garantizar un rendimiento y una confiabilidad óptimos del modelo RAG antes de su implementación.
# Evaluación de RAG
Para evaluar un sistema RAG, comúnmente utilizamos dos tipos de evaluaciones:
- Evaluación de recuperación
- Evaluación de respuestas
A diferencia de las técnicas tradicionales de aprendizaje automático, donde existen métricas cuantitativas bien definidas (como Gini, R-cuadrado, AIC, BIC, matriz de confusión, etc.), la evaluación de los sistemas RAG es más compleja. Esta complejidad surge porque las respuestas generadas por los sistemas RAG son texto no estructurado, lo que requiere una combinación de métricas cualitativas y cuantitativas para evaluar su rendimiento de manera precisa.
# Marco TRIAD
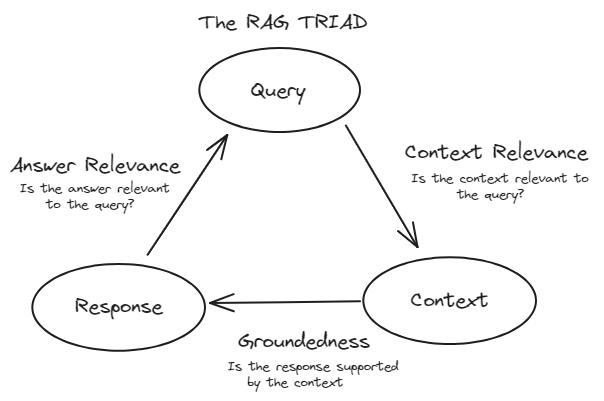
Para evaluar eficazmente los sistemas RAG, comúnmente seguimos el marco TRIAD. Este marco consta de tres componentes principales:
Relevancia del contexto: Este componente evalúa la parte de recuperación del sistema RAG. Evalúa qué tan precisamente se recuperaron los documentos de la gran cantidad de datos. Aquí se utilizan métricas como precisión, recall, MRR y MAP.
Fidelidad (Fundamentación): Este componente se encuentra dentro de la evaluación de respuestas. Verifica si la respuesta generada es precisa y se basa en los documentos recuperados. Se utilizan métodos como la evaluación humana, herramientas de verificación de hechos automatizadas y verificaciones de consistencia para evaluar la fidelidad.
Relevancia de la respuesta: Esto también forma parte de la evaluación de respuestas. Mide qué tan bien la respuesta generada aborda la consulta del usuario y proporciona información útil. Se utilizan métricas como BLEU, ROUGE, METEOR y evaluaciones basadas en embeddings.
# Evaluación de recuperación
Las evaluaciones de recuperación se aplican al componente de recuperación de un sistema RAG, que generalmente utiliza una base de datos vectorial. Estas evaluaciones miden qué tan eficazmente el recuperador identifica y clasifica los documentos relevantes en respuesta a una consulta del usuario. El objetivo principal de las evaluaciones de recuperación es evaluar la relevancia del contexto, es decir, qué tan bien se alinean los documentos recuperados con la consulta del usuario. Esto asegura que el contexto proporcionado al componente de generación sea pertinente y preciso.

Cada una de las métricas ofrece una perspectiva única sobre la calidad de los documentos recuperados y contribuye a una comprensión integral de la relevancia del contexto.
# Precisión
La precisión mide la exactitud de los documentos recuperados. Es la relación entre el número total de documentos relevantes recuperados y el número total de documentos recuperados. Se define como:
Esto significa que la precisión evalúa cuántos de los documentos recuperados por el sistema son realmente relevantes para la consulta del usuario. Por ejemplo, si el recuperador recupera 10 documentos y 7 de ellos son relevantes, la precisión sería 0.7 o 70%.
La precisión evalúa, "De todos los documentos que el sistema recuperó, ¿cuántos eran realmente relevantes?”
La precisión es especialmente importante cuando presentar información irrelevante puede tener consecuencias negativas. Por ejemplo, en un sistema de recuperación de información médica, una alta precisión es crucial porque proporcionar documentos médicos irrelevantes podría llevar a desinformación y resultados potencialmente perjudiciales.
# Recall
Recall mide la exhaustividad de los documentos recuperados. Es la relación entre el número de documentos relevantes recuperados y el número total de documentos relevantes en la base de datos para la consulta dada. Se define como:
Esto significa que el recall evalúa cuántos de los documentos relevantes que existen en la base de datos fueron recuperados con éxito por el sistema.
El recall evalúa: "De todos los documentos relevantes que existen en la base de datos, ¿cuántos logró recuperar el sistema?"
El recall es fundamental en situaciones en las que perder información relevante puede ser costoso. Por ejemplo, en un sistema de recuperación de información legal, un alto recall es esencial porque no recuperar un documento legal relevante podría llevar a una investigación de casos incompleta y afectar potencialmente el resultado de los procedimientos legales.
# Equilibrio entre precisión y recall
A menudo es necesario equilibrar la precisión y el recall, ya que mejorar uno puede reducir el otro. El objetivo es encontrar un equilibrio óptimo que se adapte a las necesidades específicas de la aplicación. Este equilibrio a veces se cuantifica utilizando la puntuación F1, que es la media armónica de la precisión y el recall:
# Mean Reciprocal Rank (MRR)
Mean Reciprocal Rank (MRR) es una métrica que evalúa la eficacia del sistema de recuperación considerando la posición de rango del primer documento relevante. Es particularmente útil cuando solo el primer documento relevante es de interés primario. El rango recíproco es el inverso del rango en el que se encuentra el primer documento relevante. MRR es el promedio de estos rangos recíprocos en múltiples consultas. La fórmula para MRR es:
Donde Q es el número de consultas y
MRR evalúa "En promedio, ¿qué tan rápido se recupera el primer documento relevante en respuesta a una consulta del usuario?"
Por ejemplo, en un sistema de preguntas y respuestas basado en RAG, MRR es crucial porque refleja qué tan rápido el sistema puede presentar la respuesta correcta al usuario. Si la respuesta correcta aparece con más frecuencia en la parte superior de la lista, el valor de MRR será mayor, lo que indica un sistema de recuperación más efectivo.
# Mean Average Precision (MAP)
Mean Average Precision (MAP) es una métrica que evalúa la precisión de la recuperación en múltiples consultas. Toma en cuenta tanto la precisión de la recuperación como el orden de los documentos recuperados. MAP se define como la media de las puntuaciones de precisión promedio para un conjunto de consultas. Para calcular la precisión promedio para una sola consulta, se calcula la precisión en cada posición de la lista clasificada de documentos recuperados, considerando solo los documentos recuperados en las primeras K posiciones, donde cada precisión se pondera según si el documento es relevante o no. La fórmula para MAP en múltiples consultas es:
Donde ( Q ) es el número de consultas y
MAP evalúa, "En promedio, ¿qué tan precisa es la recuperación de los documentos mejor clasificados por el sistema en múltiples consultas?”
Por ejemplo, en un motor de búsqueda basado en RAG, MAP es crucial porque considera la precisión de la recuperación en diferentes rangos, asegurando que los documentos relevantes aparezcan más arriba en los resultados de búsqueda, lo que mejora la experiencia del usuario al presentar la información más relevante primero.
# Una visión general de las evaluaciones de recuperación
- Precisión: Calidad de los resultados recuperados.
- Recall: Completitud de los resultados recuperados.
- MRR: Qué tan rápido se recupera el primer documento relevante.
- MAP: Evaluación integral que combina precisión y rango de documentos relevantes.
# Evaluación de respuestas
Las evaluaciones de respuestas se aplican al componente de generación de un sistema. Estas evaluaciones miden qué tan efectivamente el sistema genera respuestas basadas en el contexto proporcionado por los documentos recuperados. Dividimos las evaluaciones de respuestas en dos tipos:
- Fidelidad (Fundamentación)
- Relevancia de la respuesta
# Fidelidad (Fundamentación)
La fidelidad evalúa si la respuesta generada es precisa y se basa en los documentos recuperados. Asegura que la respuesta no contenga alucinaciones o información incorrecta. Esta métrica es crucial porque rastrea la respuesta generada hasta su origen, asegurando que la información se base en una verdad verificable. La fidelidad ayuda a prevenir alucinaciones, donde el sistema genera respuestas que suenan plausibles pero son incorrectas desde el punto de vista factual.
Para medir la fidelidad, se utilizan los siguientes métodos comúnmente:
- Evaluación humana: Los expertos evalúan manualmente si las respuestas generadas son precisas desde el punto de vista factual y si se basan correctamente en los documentos recuperados. Este proceso implica verificar cada respuesta con los documentos de origen para asegurar que todas las afirmaciones estén respaldadas.
- Herramientas de verificación de hechos automatizadas: Estas herramientas comparan la respuesta generada con una base de datos de hechos verificados para identificar inexactitudes. Proporcionan una forma automatizada de verificar la validez de la información sin intervención humana.
- Verificaciones de consistencia: Estas evalúan si el modelo proporciona consistentemente la misma información factual en diferentes consultas. Esto asegura que el modelo sea confiable y no produzca información contradictoria.
# Relevancia de la respuesta
La relevancia de la respuesta mide qué tan bien la respuesta generada aborda la consulta del usuario y proporciona información útil.
# BLEU (Bilingual Evaluation Understudy)
BLEU mide la superposición entre la respuesta generada y un conjunto de respuestas de referencia, centrándose en la precisión de los n-gramos. Se calcula midiendo la superposición de n-gramos (secuencias contiguas de n palabras) entre la respuesta generada y las respuestas de referencia. La fórmula para la puntuación BLEU es:
Donde ( BP ) es la penalización por brevedad para penalizar las respuestas cortas, ( P_n ) es la precisión de los n-gramos y ( w_n ) son los pesos para cada nivel de n-gramo. BLEU mide cuantitativamente qué tan cerca está la respuesta generada de la respuesta de referencia.
# ROUGE (Recall-Oriented Understudy for Gisting Evaluation)
ROUGE mide la superposición de n-gramos, secuencias de palabras y pares de palabras entre la respuesta generada y las respuestas de referencia, considerando tanto la recall como la precisión. La variante más común, ROUGE-N, mide la superposición de n-gramos entre la respuesta generada y las respuestas de referencia. La fórmula para ROUGE-N es:
ROUGE evalúa tanto la precisión como la recall, proporcionando una medida equilibrada de cuánto contenido relevante de la referencia está presente en la respuesta generada.
# METEOR (Metric for Evaluation of Translation with Explicit ORdering)
METEOR considera la sinonimia, el stemming y el orden de las palabras para evaluar la similitud entre la respuesta generada y las respuestas de referencia. La fórmula para la puntuación METEOR es:
Donde $ F_{\text{mean}}$ es la media armónica de la precisión y la recall, y
# Evaluación basada en embeddings
Este método utiliza representaciones vectoriales de palabras (embeddings) para medir la similitud semántica entre la respuesta generada y las respuestas de referencia. Se utilizan técnicas como la similitud del coseno para comparar los embeddings, proporcionando una evaluación basada en el significado de las palabras en lugar de sus coincidencias exactas.

# Consejos y trucos para optimizar los sistemas RAG
Hay algunos consejos y trucos fundamentales que puedes utilizar para optimizar tus sistemas RAG:
- Utiliza técnicas de reordenamiento: El reordenamiento ha sido la técnica más utilizada para optimizar el rendimiento de cualquier sistema RAG. Toma el conjunto inicial de documentos recuperados y clasifica aún más los más relevantes en función de su similitud. Podemos evaluar de manera más precisa la relevancia de los documentos utilizando técnicas como codificadores cruzados y reordenadores basados en BERT. Esto asegura que los documentos proporcionados al generador sean contextualmente ricos y altamente relevantes, lo que conduce a mejores respuestas.
- Ajusta los hiperparámetros: Ajustar regularmente los hiperparámetros como el tamaño del fragmento, la superposición y el número de documentos recuperados principales puede optimizar el rendimiento del componente de recuperación. Experimentar con diferentes configuraciones y evaluar su impacto en la calidad de la recuperación puede llevar a un mejor rendimiento general del sistema RAG.
- Modelos de embeddings: Seleccionar un modelo de embeddings adecuado es crucial para optimizar el componente de recuperación de un sistema RAG. El modelo correcto, ya sea de propósito general o específico del dominio, puede mejorar significativamente la capacidad del sistema para representar y recuperar información relevante con precisión. Al elegir un modelo que se ajuste a tu caso de uso específico, puedes mejorar la precisión de las búsquedas de similitud y el rendimiento general de tu sistema RAG. Considera factores como los datos de entrenamiento del modelo, la dimensionalidad y las métricas de rendimiento al hacer tu selección.
- Estrategias de fragmentación: La personalización de los tamaños de fragmentos y las superposiciones puede mejorar en gran medida el rendimiento de los sistemas RAG al capturar más información relevante para el LLM. Por ejemplo, la fragmentación semántica de Langchain divide los documentos en función de la semántica, asegurando que cada fragmento sea coherente en contexto. Las estrategias de fragmentación adaptativas que varían según los tipos de documentos (como PDF, tablas e imágenes) pueden ayudar a retener información contextualmente apropiada.
# Papel de las bases de datos vectoriales en los sistemas RAG
Las bases de datos vectoriales son fundamentales para el rendimiento de los sistemas RAG. Cuando un usuario envía una consulta, el componente de recuperación del sistema RAG aprovecha la base de datos vectorial para encontrar los documentos más relevantes en función de la similitud de vectores. Este proceso es crucial para proporcionar al modelo de lenguaje el contexto adecuado para generar respuestas precisas y relevantes. Una base de datos vectorial robusta garantiza una recuperación rápida y precisa, lo que influye directamente en la efectividad y capacidad de respuesta general del sistema RAG.
MyScaleDB (opens new window) es una base de datos vectorial SQL construida sobre la base de datos de alto rendimiento ClickHouse (opens new window). ClickHouse ofrece características avanzadas de manejo de datos como almacenamiento orientado a columnas y ejecución de consultas vectorizadas. El algoritmo Multi-Scale Tree Graph (MSTG) (opens new window) de MyScale ha superado a otros métodos de indexación con 390 QPS (Consultas por Segundo) en el conjunto de datos LAION 5M, logrando una tasa de recall del 95% y manteniendo una latencia promedio de consulta de 18ms con el pod s1.x1. Este algoritmo único mejora la eficiencia de indexación y búsqueda al combinar agrupación jerárquica de árboles con técnicas de recorrido de grafos, lo que lo hace más rápido y preciso. MSTG también reduce el uso de recursos y acelera las operaciones de búsqueda en comparación con métodos tradicionales como HNSW (Hierarchical Navigable Small World) y IVF (Inverted File). Además, la compatibilidad de MyScaleDB con SQL y sus potentes capacidades de búsqueda vectorial facilitan la integración en flujos de trabajo existentes, utilizando consultas SQL familiares para operaciones vectoriales complejas.
# Conclusión
Desarrollar un sistema RAG no es inherentemente difícil, pero evaluar los sistemas RAG es crucial para medir el rendimiento, permitir la mejora continua, alinearse con los objetivos comerciales, equilibrar los costos, garantizar la confiabilidad y adaptarse a nuevos métodos. Este proceso de evaluación integral ayuda a construir un sistema RAG robusto, eficiente y centrado en el usuario.
Al abordar estos aspectos críticos, las bases de datos vectoriales sirven como base para sistemas RAG de alto rendimiento, lo que les permite ofrecer respuestas precisas, relevantes y oportunas al tiempo que gestionan eficientemente datos complejos a gran escala. MyScaleDB cuenta con el algoritmo MSTG propietario, consultas conjuntas de SQL y Vector que pueden mejorar significativamente el rendimiento del sistema RAG, lo que convierte a MyScaleDB en una excelente opción para construir sistemas RAG.



