
Si bien las búsquedas de texto son bastante comunes, a menudo hay escenarios en los que necesitamos buscar imágenes utilizando una imagen (opens new window) en sí como consulta de búsqueda, como encontrar fotos similares o identificar productos a partir de una imagen. Este enfoque, conocido como búsqueda basada en imágenes o búsqueda inversa de imágenes, tiene muchas aplicaciones, como compras en línea, donde tomas una foto de algo que te gusta para encontrar dónde comprarlo, identificación de plantas o lugares desconocidos, entre otros. Es un campo fascinante que se está volviendo más relevante a medida que nuestros datos visuales crecen.
Obviamente, es un desafío porque no tenemos una consulta de texto directa para comparar. En cambio, necesitamos una forma de representar las imágenes de manera que se puedan comparar de manera efectiva. Aquí es donde entran en juego las incrustaciones. Al convertir las imágenes en vectores numéricos en un espacio de alta dimensión, las incrustaciones nos permiten medir la similitud entre imágenes en función de sus características.
En este blog, repasaremos algunos de estos métodos. Exploraremos cómo se utilizan los modelos de incrustación en la búsqueda de imágenes, examinaremos los algoritmos detrás de ellos y veremos cómo hacen posible encontrar imágenes similares. Ya sea que seas un desarrollador que busca implementar la búsqueda de imágenes o simplemente estés interesado en cómo funciona, esta publicación arrojará algo de luz sobre el tema.
# Métodos clásicos
En la era del aprendizaje profundo, el concepto de encontrar características de imágenes similares en los motores de búsqueda en realidad precede a la adopción generalizada de las técnicas de aprendizaje profundo. Ya en 2009, Google Images incorporó una función de imágenes similares (opens new window), y poco después se introdujeron sistemas de recuperación de imágenes basados en contenido (CBIR, por sus siglas en inglés). Esto plantea una pregunta natural: ¿cuáles fueron los métodos que permitieron estas búsquedas de imágenes sin depender de los modelos de aprendizaje profundo de última generación?
# SIFT
La Transformación de características invariante a la escala (SIFT, por sus siglas en inglés) fue una vez un algoritmo altamente eficiente y popular antes de la aparición de las arquitecturas de aprendizaje profundo. SIFT identifica puntos clave de interés en una imagen que son invariantes a la escala, la rotación e incluso cierto grado de distorsión afín y cambios de iluminación. Después de detectar estos puntos clave, SIFT calcula descriptores de características analizando la información de gradiente local alrededor de cada punto. Estos descriptores suelen ser vectores de 128 dimensiones que capturan de manera efectiva la estructura local de una imagen. Se pueden utilizar como incrustaciones en diversas aplicaciones, como la coincidencia y recuperación de imágenes.
SIFT tampoco se queda sin críticas. Tiene una eficiencia baja para imágenes más pequeñas, utiliza mucha memoria (imagina vectores de 128 dimensiones para miles de puntos clave) y es sensible a la iluminación. Además, fue patentado recientemente en 2020 y, como resultado, no se hizo tan popular entre la comunidad como los otros métodos.
# SURF
Abordando algunas de las críticas de complejidad computacional de SIFT, se introdujo Características robustas aceleradas (SURF, por sus siglas en inglés) como una alternativa más rápida. SURF sacrifica un poco de precisión de rendimiento a cambio de velocidad computacional. Mientras que SIFT se basa en derivadas de imagen de primer orden (gradientes) para la detección y descripción de características, SURF utiliza una aproximación de derivadas de segundo orden (matriz Hessiana) para una computación más rápida. Los descriptores de características generados por SURF suelen ser vectores de 64 dimensiones, o de 128 dimensiones para la versión extendida, lo que los hace adecuados para representaciones de incrustación en tareas de recuperación de imágenes.
Además de estos, existen otros métodos como Histograma de gradientes orientados (HOG, por sus siglas en inglés), FAST orientado y BRIEF rotado (ORB, por sus siglas en inglés), entre otros.
# Implementación
Tanto SIFT como SURF son fáciles de implementar utilizando el paquete OpenCV (opens new window). OpenCV (a partir de la versión 4.4.0) tiene una función SIFT_create() lista para usar para inicializar los objetos SIFT. Estos objetos se pueden utilizar luego para detectar y calcular los puntos clave junto con sus descriptores (vectores de incrustación).
import cv
image = cv2.imread('AdventureKKH/15.jpg')
grayScaleImage = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
sift = cv2.SIFT_create()
keypoints, descriptors = sift.detectAndCompute(grayScaleImage, None)
Una imagen puede tener muchos puntos clave. Una vez encontrados, simplemente podemos dibujarlos.
import matplotlib.pyplot as plt
image_with_keypoints = cv2.drawKeypoints(image, keypoints, None)
plt.imshow(cv2.cvtColor(image_with_keypoints, cv2.COLOR_BGR2RGB))
plt.axis('off')
plt.show()

Como puedes ver, estos puntos clave son numerosos (precisamente 6433), pero debido al bajo contraste con la imagen, la mayoría de ellos no se pueden identificar. Como una mejor alternativa, podemos establecer flags=cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS para visualizarlos de una manera un poco mejor.

Las características (descriptores) también se pueden visualizar de una mejor manera utilizando un DataFrame. Como puedes ver, tenemos una fila para cada punto SIFT (keypoints) y la característica de cada punto es un vector de 128 dimensiones.
Dado que SURF es un algoritmo patentado, no se permite su uso directo desde OpenCV. Ahora, centrémonos en los más comunes, los modelos basados en arquitecturas de aprendizaje profundo.
# Incrustaciones basadas en arquitecturas de aprendizaje profundo
Basándose en métodos tradicionales como SIFT y SURF, que se centran en extraer características locales de las imágenes, los modelos de aprendizaje profundo ofrecen un enfoque más potente para la representación de imágenes. Estos modelos aprenden características jerárquicas directamente de los datos, capturando patrones y estructuras intrincados que no son fácilmente identificables por algoritmos hechos a mano. Este avance permite incrustaciones más robustas y discriminativas, mejorando tareas como la búsqueda y recuperación de imágenes.
Existen varios modelos preentrenados listos para usar, como VGG, ResNets, Inception, MobileNet y otros. Estas redes neuronales convolucionales (CNN, por sus siglas en inglés) han sido entrenadas en grandes conjuntos de datos como ImageNet, lo que les permite extraer características ricas y diversas de las imágenes. A diferencia de los algoritmos tradicionales, los modelos de aprendizaje profundo pueden capturar tanto características de bajo nivel (como bordes y texturas) como conceptos de alto nivel (como objetos y escenas).
Usar estos modelos para calcular incrustaciones es relativamente sencillo. Tomamos un modelo preentrenado y, en lugar de utilizar la salida de la capa de clasificación final, extraemos la salida de una capa anterior, generalmente la que está justo antes de la capa de clasificación (opens new window). Esta salida es un vector de características de alta dimensión que sirve como incrustación, representando eficazmente la imagen en una forma numérica adecuada para comparaciones de similitud.
Por ejemplo, usemos ResNet-50, un modelo de aprendizaje profundo popular conocido por sus conexiones residuales que ayudan a entrenar redes más profundas de manera efectiva. Al eliminar su última capa, podemos obtener incrustaciones para una determinada imagen:
import torch
import torchvision.models as models
model = models.resnet50(pretrained=True)
model = torch.nn.Sequential(*(list(model.children())[:-1]))
with torch.no_grad():
embedding = model(image.unsqueeze(0))
# Incrustaciones basadas en ViT
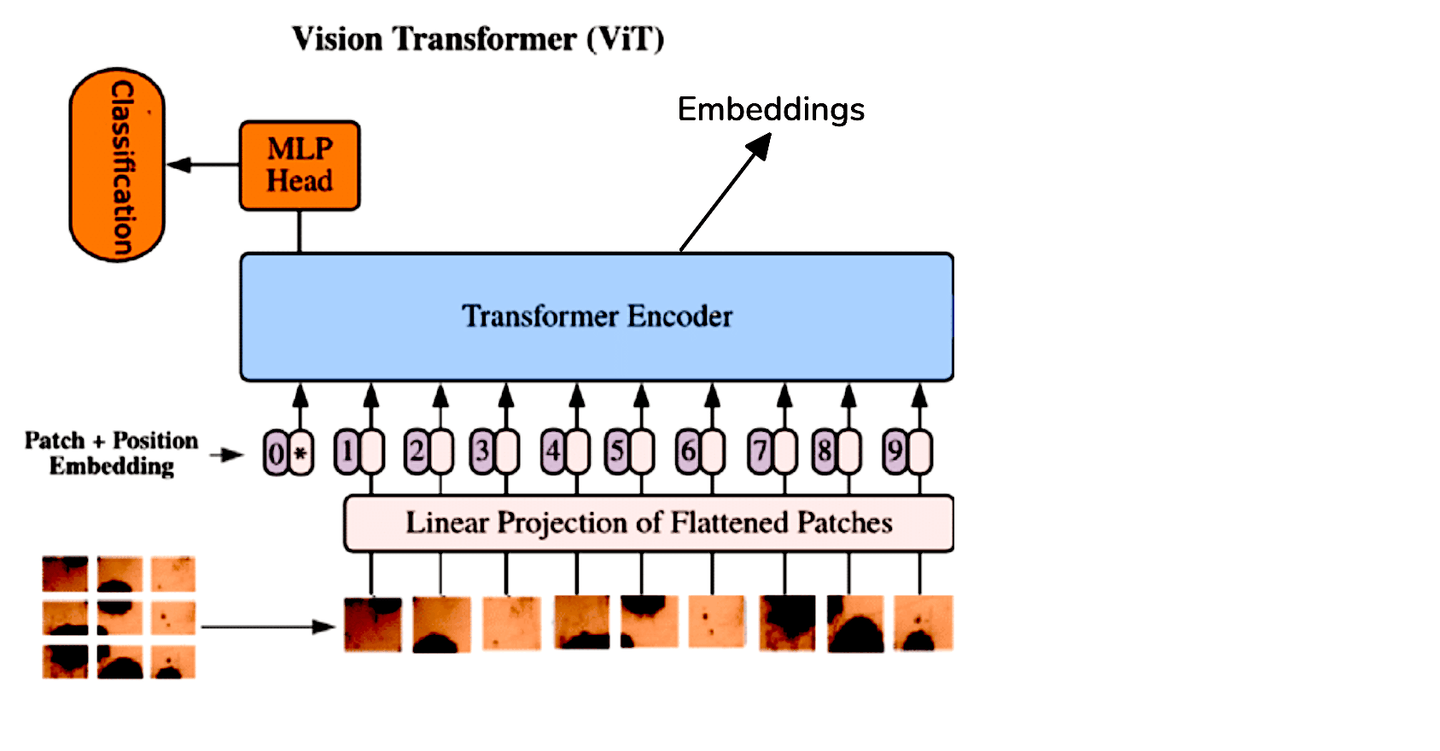
Si bien las CNN han sido el estándar para tareas de procesamiento de imágenes, los Transformadores de Visión (ViT, por sus siglas en inglés) ofrecen un enfoque diferente al aplicar la arquitectura de transformador a los datos de imágenes. ViT trata una imagen como una secuencia de parches y la procesa de manera similar a cómo los transformadores manejan secuencias en el procesamiento de lenguaje natural. Este método permite que el modelo capture relaciones globales dentro de la imagen de manera más efectiva.
Debido a las diferencias arquitectónicas entre ViT y las CNN, extraemos incrustaciones de ViT promediando los tokens de salida del codificador del transformador. Para mayor comodidad, podemos utilizar modelos preentrenados de ViT disponibles a través de Hugging Face:
from transformers import ViTModel, ViTFeatureExtractor
import torch
model = ViTModel.from_pretrained('google/vit-base-patch16-224-in21k')
feature_extractor = ViTFeatureExtractor.from_pretrained('google/vit-base-patch16-224-in21k')
image = Image.open('AdventureKKH/15.jpg')
inputs = feature_extractor(images=image, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
embedding = outputs.last_hidden_state.mean(dim=1)
print(embedding)
Dado que estamos utilizando la arquitectura ViT predeterminada (la utilizada en el artículo original [1]), el vector de incrustación tendrá 768 dimensiones, como podemos ver aquí. Si deseas una mejor resolución, puedes cambiar a ViT-Large o ViT-Huge (longitudes de 1024 y 1280, respectivamente).

# Ajuste fino
Cuando se trabaja con tipos de imágenes especializadas que requieren un ajuste fino del modelo, ya sea utilizando una Red Neuronal Convolucional (CNN, por sus siglas en inglés) o un Transformador de Visión (ViT, por sus siglas en inglés), a menudo es beneficioso congelar todas las capas excepto la capa final del modelo. Este enfoque permite el ajuste fino de la última capa sin alterar las características aprendidas de las capas anteriores.
Una vez completado el proceso de ajuste fino, se puede eliminar la última capa, de manera similar a los procedimientos anteriores. Con el modelo modificado, las imágenes se pueden pasar a través del pase hacia adelante para generar las incrustaciones deseadas. Este método garantiza que el modelo mantenga su comprensión fundamental mientras se adapta a las particularidades de los datos de imágenes específicos.
# Métodos de auto-supervisión
Solo revisa tu propia carpeta de imágenes y comienza a anotarla. Te cansarás después de 50 o 100. El ajuste fino requiere muchos datos etiquetados, que lamentablemente no están fácilmente disponibles ni valen la pena invertir tiempo en ellos. Por lo tanto, una mejor solución es utilizar el aprendizaje de auto-supervisión. Hay varios métodos de aprendizaje de auto-supervisión disponibles, como:
Tanto SimCLR como MoCo producen dos copias de la imagen de entrada y sus incrustaciones. Luego, se entrena una arquitectura subyacente (generalmente una ResNet) para asegurar que la pérdida contrastiva se minimice.
Por otro lado, CLIP utiliza tanto las incrustaciones de la imagen como las incrustaciones de su descripción textual respectiva para entrenar el modelo. Este método se ha vuelto famoso ya que hemos visto una serie de métodos similares desde entonces. Ejemplos incluyen BEiT (preentrenamiento de BERT de transformadores de imágenes), VisualBERT y ViLBERT.
Nota: Para obtener más información sobre CLIP, puedes leer nuestro blog sobre Clasificación de cero disparos con CLIP (opens new window).
Aquí, utilizaremos Moco (v2) para calcular las incrustaciones de las imágenes.
import torch
import torch.nn as nn
from torchvision import models
class MoCoResNet(nn.Module):
def __init__(self, base_encoder=models.resnet50, feature_dim=128):
super(MoCoResNet, self).__init__()
self.encoder_q = base_encoder(pretrained=False)
self.encoder_q.fc = nn.Identity() # Eliminando la última capa
def forward(self, x):
return self.encoder_q(x)
model = MoCoResNet()
checkpoint = torch.load('/Users/talha/Downloads/moco_v2_800ep_pretrain.tar', map_location='mps', weights_only=True)
model.load_state_dict(checkpoint['state_dict'])
Las incrustaciones de las imágenes se pueden calcular de la misma manera que hicimos anteriormente para los modelos CNN normales preentrenados.
with torch.no_grad():
embedding = model(image.unsqueeze(0))
También devuelve un vector de 2048 dimensiones, como podemos confirmar.

# Aplicaciones
Estas incrustaciones de imágenes pueden ser muy útiles en algunas aplicaciones de búsqueda de imágenes. Por ejemplo:
- Comercio electrónico: Como mencionamos anteriormente, puede ser muy útil en las compras en línea. Se puede utilizar de varias formas. Y es uno de los muchos usos de CBIR.
- Clasificación de imágenes: También podemos utilizar estas incrustaciones para entrenar CNN y ViT.
- Subtitulado de imágenes: Si también utilizamos incrustaciones de texto, podemos crear un sistema de subtitulado de imágenes. CLIP es un muy buen ejemplo.
# Comparación
Sería bueno proporcionar un análisis comparativo de todos los modelos respectivos.
| Algoritmo | Velocidad | Fortalezas | Debilidades |
|---|---|---|---|
| SIFT | Moderada | Puede operar con una menor cantidad de datos | No es escalable, más lento para un método que no es de aprendizaje profundo |
| SURF | Rápida | Más rápida | No es tan robusta como otros métodos |
| CNN preentrenadas | Rápida | Varios modelos para elegir, robustas | Demasiado genéricas |
| ViTs preentrenados | Moderada a rápida | Robustas | Ninguna significativa |
| Modelos ajustados fino | Lenta (la inferencia es rápida, pero el entrenamiento puede llevar mucho tiempo) | Puede adaptarse mejor a los datos objetivo, puede dar los mejores resultados | Requiere muchas imágenes anotadas y recursos de entrenamiento |
| Modelos de auto-supervisión | Depende del conjunto de entrenamiento, pero generalmente lenta | No requiere imágenes anotadas, da resultados bastante buenos | Requiere recursos de entrenamiento |

# Conclusión
Los métodos de incrustación han transformado la búsqueda de imágenes, permitiéndonos localizar visualizaciones con una velocidad y precisión sin precedentes. Desde métodos clásicos como SIFT y SURF hasta arquitecturas modernas de aprendizaje profundo, la evolución de las incrustaciones de imágenes ha hecho posible esta transformación.
El futuro de las incrustaciones de imágenes parece aún más emocionante, con tendencias como las incrustaciones multimodales (que combinan datos de texto, imagen y audio) y los métodos de auto-supervisión que eliminan la dependencia de grandes conjuntos de datos etiquetados. Con bases de datos como MyScale (opens new window), que combina SQL y búsqueda vectorial, ahora es más fácil que nunca construir aplicaciones avanzadas de búsqueda de imágenes (opens new window). MyScale admite incrustaciones de imágenes potentes y una recuperación rápida a través de índices vectoriales, proporcionando una base sólida para futuras innovaciones en la búsqueda de imágenes.
A medida que la investigación avanza, es probable que veamos capacidades de búsqueda de imágenes aún más rápidas, precisas e inteligentes. Estos avances no solo mejorarán las experiencias de los usuarios en diferentes plataformas, sino que también redefinirán la forma en que interactuamos con la información visual en línea, haciendo que la búsqueda de imágenes sea tan natural y eficiente como la búsqueda de texto.



