
En esta serie sobre la canalización RAG Avanzada, hemos discutido cómo otros componentes como los modelos de incrustación, los métodos de indexación y las técnicas de fragmentación construyen la base de sistemas eficientes. Ahora, exploremos una parte muy importante de esta canalización: la búsqueda vectorial.
La capacidad clave de una base de datos reside en su rendimiento de búsqueda. Desde la búsqueda web hasta la identificación de objetos, sus aplicaciones son innumerables y, por lo tanto, mucho depende de la eficiencia, versatilidad y precisión de la búsqueda. Una búsqueda un poco más lenta o inexacta (o limitada) puede ser la diferencia entre un cliente satisfecho o uno que nunca regresa, y las empresas son muy conscientes de esto.
La búsqueda vectorial es esencial en los sistemas de recuperación modernos. Impulsa la búsqueda semántica y garantiza que los datos recuperados coincidan contextualmente con la consulta. La idea central detrás de la búsqueda vectorial es representar cada elemento como un vector de alta dimensión, donde cada dimensión corresponde a una característica o propiedad del elemento. La similitud entre dos elementos se puede medir como la distancia entre sus representaciones vectoriales.
# Breve Introducción a la Indexación Vectorial
La indexación es la fuerza impulsora clave detrás de la búsqueda vectorial. Es lo que hace que las búsquedas sean rápidas, eficientes y significativas. Antes de ejecutar cualquier búsqueda en una tabla, primero debe indexarse. Este proceso organiza los datos de una manera que permite que la búsqueda recupere resultados relevantes rápidamente. Entonces, primero centrémonos en el "índice (opens new window)".
Aquí hay algunas consideraciones al agregar un índice:
- Los índices solo se pueden crear en columnas vectoriales (
Array(Float32)) o columnas de texto. - Para las columnas vectoriales, es crucial especificar la longitud máxima de la matriz de antemano. Esto garantiza la coherencia en la estructura de los datos y ayuda a que el índice funcione de manera eficiente.
- Los índices se utilizan principalmente en búsquedas de similitud, lo que significa que debe definir una métrica de similitud al crear el índice. Por ejemplo, puede elegir la similitud
Coseno, que es una de las métricas más comunes para comparar vectores.
Los índices son la columna vertebral de las búsquedas vectoriales eficientes, ya que reducen drásticamente el tiempo y el esfuerzo computacional necesarios para encontrar los datos correctos. Elegir la estrategia de indexación correcta y comprender estas consideraciones puede marcar la diferencia en el rendimiento de su sistema.
# Ejemplo
Agregar un índice en MyScale (opens new window) es igual que como lo agregamos para cualquier tabla SQL. Como ejemplo, definimos una tabla y agregamos una columna vectorial allí.
CREATE TABLE test_float_vector
(
id UInt32,
data Array(Float32),
CONSTRAINT check_length CHECK length(data) = 128,
date Date,
label Enum8('persona' = 1, 'edificio' = 2, 'animal' = 3)
)
ENGINE = MergeTree
ORDER BY id
Como puede ver, hemos agregado la restricción de longitud máxima, ya que es necesaria antes de agregar un índice.
ALTER TABLE default.test_float_vector
ADD VECTOR INDEX data_index data
TYPE MSTG ('metric_type=Cosine');
Y utilizando el mismo SQL que usamos para las consultas tradicionales de bases de datos relacionales, podemos obtener los documentos más relevantes para el término de búsqueda ("¿Cuál fue la solución propuesta al problema de los agricultores por Levin?"). La frase de búsqueda debe convertirse primero en una incrustación. Podemos hacerlo utilizando cualquier modelo o servicio de incrustación. Después de obtener la incrustación (en input_embedding), obtenemos los documentos más relevantes.

Nota:
MyScale también proporciona la función EMBEDTEXT(), que se puede utilizar directamente tanto en la interfaz de Python (u otra) como en SQL.
# Algoritmos de Indexación
La sintaxis anterior no es única, pero la indexación de vectores (opens new window) funciona de manera un poco diferente detrás de escena. Generalmente, emplea clustering y se complementa con algún gráfico/árbol de vectores para una búsqueda más rápida. Elegir un algoritmo de indexación adecuado puede ser un factor importante para la eficiencia de búsqueda. Aquí algunos algoritmos populares:
- Local Sensitivity Hashing (LSH): Locality-Sensitive Hashing (LSH) utiliza funciones hash especiales para agrupar puntos de datos similares en el mismo contenedor. Este proceso garantiza que los embeddings o vectores cercanos entre sí tengan más probabilidades de colisionar en la misma tabla hash. Permite búsquedas más rápidas en espacios de alta dimensión, siendo ideal para tareas de vecinos más cercanos aproximados.
- Inverted File (IVF) (opens new window): El índice de archivo invertido (IVF) funciona agrupando los vectores en clústeres. Cuando se proporciona un vector de consulta, el sistema calcula la distancia de la consulta desde los centros de todos los clústeres. Luego, busca dentro del clúster más cercano a la consulta. Sin embargo, dado que esta búsqueda depende de los centros de los clústeres (similar a k-Nearest Neighbors), una posible desventaja es que se podrían omitir vectores cercanos en otros clústeres. Además, en algunos casos, puede ser necesario buscar en varios clústeres para obtener mejores resultados.
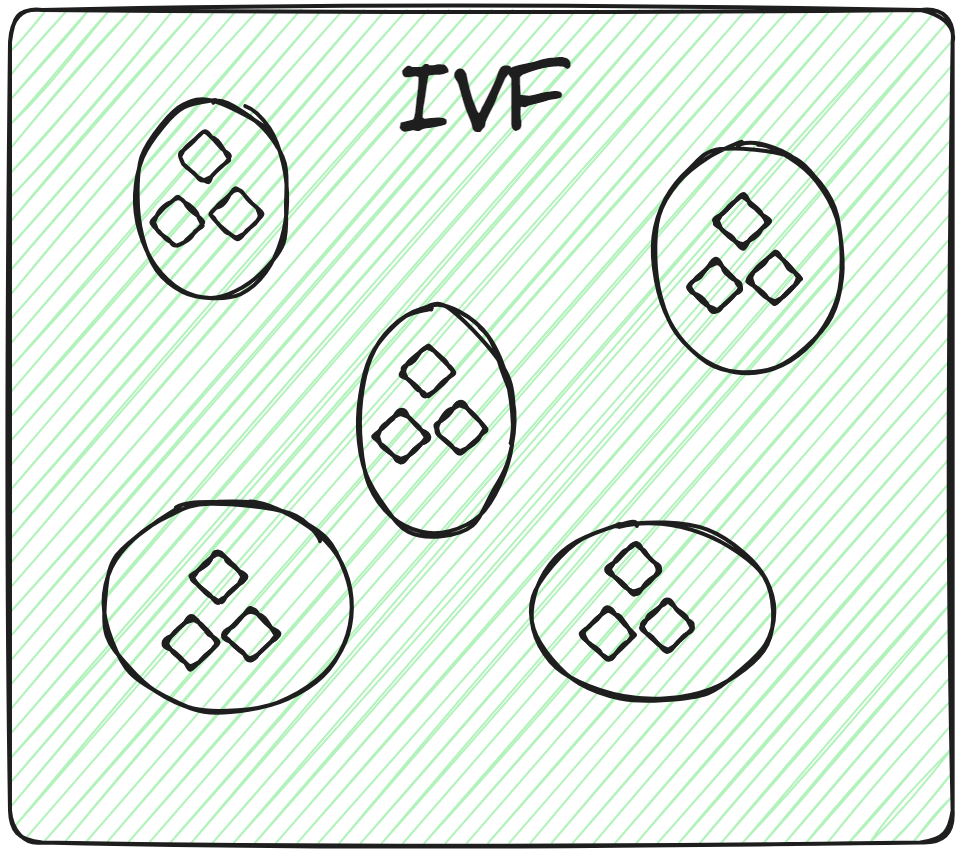
IVF también tiene varias variantes, como IVF-Flat (opens new window) y IVF-PQ (opens new window), que ofrecen diferentes compensaciones en términos de rendimiento y almacenamiento.
Nota:
Elegir un algoritmo de indexación adecuado se vuelve aún más importante en el contexto de cómo crecen rápidamente las bases de datos vectoriales con millones de vectores, donde cada segundo ahorrado es valioso.
- Hierarchical Navigable Small Worlds (HNSW) (opens new window): HNSW funciona construyendo capas de gráficos que se pueblan progresivamente (es decir, la capa superior tiene el menor número de nodos). Este enfoque jerárquico significa que no es necesario buscar en demasiados nodos, lo que lo hace bastante rápido. Sin embargo, crear nuevos gráficos (cada vez que se agrega un nuevo vector) puede ser un proceso muy lento.
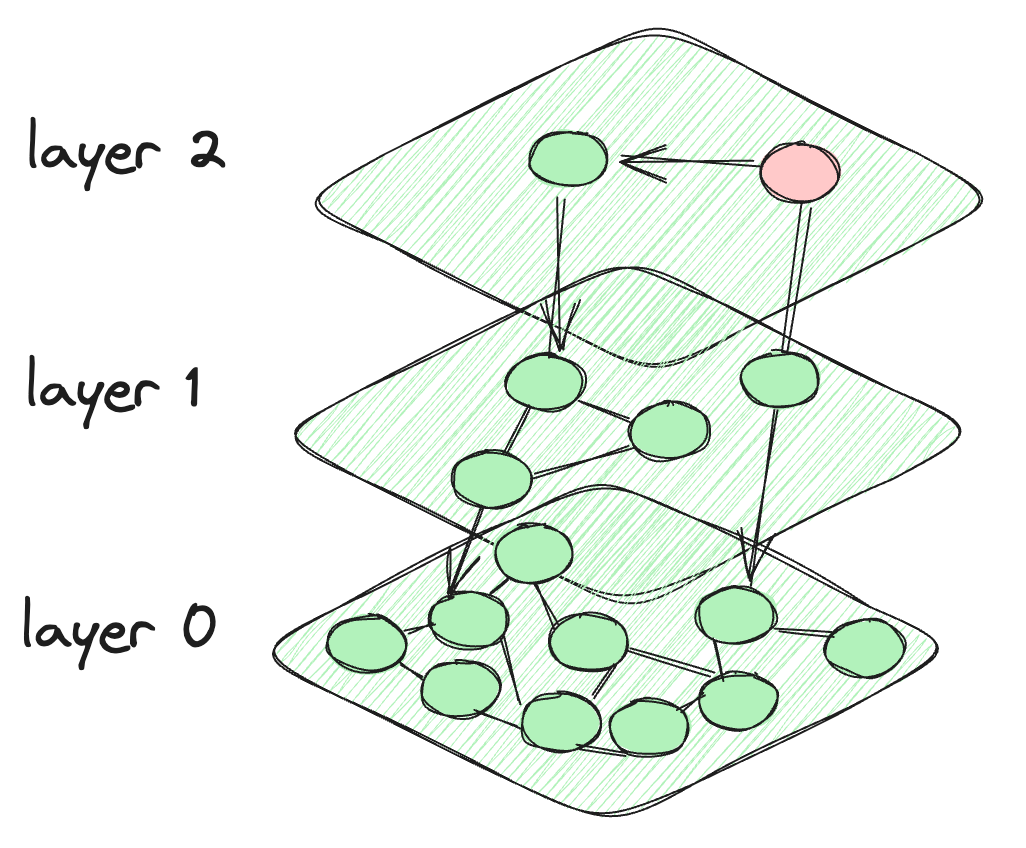
- Multi-Scale Tree Graph (MSTG) (opens new window): Tanto HNSW como IVF son bastante buenos, pero sus problemas de rendimiento comienzan cuando se escalan para conjuntos de datos más grandes. La búsqueda en gráficos es muy efectiva en la convergencia inicial, pero presenta dificultades en búsquedas filtradas, mientras que la búsqueda en árboles es eficiente en búsquedas filtradas pero más lenta. MSTG combina ambos mediante una combinación de gráficos jerárquicos y árboles.
Resumiéndolo en una tabla para referencia rápida en el futuro:
| N° | Algoritmo | Fortalezas | Áreas de mejora | Adecuado para |
|---|---|---|---|---|
| 1 | LSH | Datos de alta dimensión; soporte para paralelización | Alto uso de memoria; lento | Datos dispersos en alta dimensión |
| 2 | IVF | Bueno para datos pequeños y medianos | Clústeres cercanos pueden causar omisiones | Conjuntos de datos con clústeres distinguibles |
| 3 | HNSW | Rápido | Intensivo en recursos para nuevas entradas; escalabilidad | Versátil |
| 4 | MSTG | Rápido; escalable; alta precisión | Nuevo y, por lo tanto, menos maduro | Versátil |
# Búsqueda Vectorial Básica
La búsqueda vectorial es una técnica sofisticada de recuperación de datos que se centra en emparejar los significados contextuales de las consultas de búsqueda y las entradas de datos, en lugar de una coincidencia simple de texto. Para implementar esta técnica, primero debemos convertir tanto la consulta de búsqueda como una columna específica del conjunto de datos en representaciones numéricas, conocidas como embeddings de vectores.
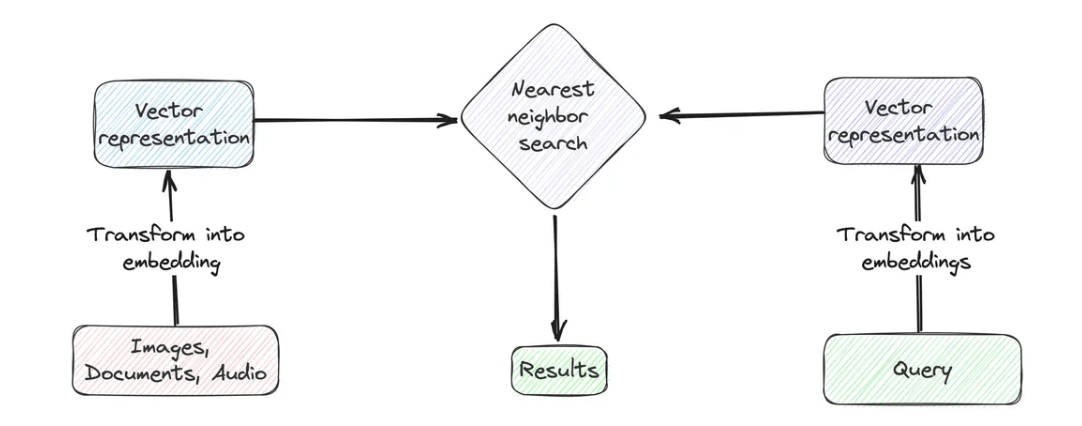
Luego, se calcula la distancia (similaridad del coseno o distancia euclidiana) entre el vector de consulta y los embeddings de vectores en la base de datos. A continuación, se identifican las entradas más cercanas o similares basándose en estas distancias calculadas. Finalmente, se devuelven los resultados top-k con las distancias más pequeñas al vector de consulta.
Nota:
La búsqueda semántica se basa en la definición básica de la búsqueda vectorial para devolver resultados más relevantes basados en el significado del texto en lugar de términos exactos. Sin embargo, en la práctica, la búsqueda vectorial y la búsqueda semántica suelen usarse indistintamente.
# Búsqueda de Texto Completo
Las búsquedas tradicionales en SQL e incluso las expresiones regulares son bastante limitadas al tomar solo el término exacto o un patrón específico para la comparación. Este ejemplo ilustra el concepto. Estamos usando sintaxis SQL para buscar documentos relevantes para “Thanksgiving for vegans”.
| Condición AND | Condición OR |
|---|---|
SELECT
id,
title,
body
FROM
default.en_wiki_abstract
WHERE
body LIKE '%Thanksgiving%'
AND body LIKE '%vegans%'
ORDER BY
id
LIMIT
4;
| SELECT
id,
title,
body
FROM
default.en_wiki_abstract
WHERE
body LIKE '%Thanksgiving%'
OR body LIKE '%vegans%'
ORDER BY
id
LIMIT
4;
|
Aplicar la búsqueda con AND claramente no arroja ningún resultado, mientras que usar el operador OR amplía el alcance al devolver documentos que contienen "Thanksgiving" o "vegans". Si bien este enfoque recupera resultados, no todos los documentos pueden ser altamente relevantes para ambos términos.

# Las Limitaciones de la Búsqueda SQL Tradicional
Las búsquedas SQL tradicionales como estas son rígidas. No tienen en cuenta las similitudes semánticas o las variaciones en la redacción. Por ejemplo, SQL trata "doctor aplicando anestesia" y "doctor aplica anestesia" como frases completamente diferentes, lo que significa que a menudo se pasan por alto coincidencias similares.
# Cómo Mejora la Búsqueda de Texto Completo
En el primer caso, realizamos búsquedas basadas en la frase exacta, mientras que en el segundo, las búsquedas se realizan utilizando palabras clave. La búsqueda de texto completo admite ambos métodos, lo que permite flexibilidad según las preferencias del usuario. A diferencia de la rígida búsqueda SQL predeterminada, la búsqueda de texto completo admite cierto grado de variación en el texto.
# Cómo funciona
La indexación de la búsqueda de texto completo funciona en estos subpasos.
- Tokenización: La tokenización se utiliza para dividir el texto en partes más pequeñas. En la tokenización de palabras, tomamos un texto y lo dividimos en palabras, mientras que las tokenizaciones de oraciones y caracteres lo dividen a nivel de oración y carácter, respectivamente.
- Lematización/Stemming: El stemming y la lematización descomponen las palabras en su forma "cruda". Por ejemplo, "jugando" se reducirá a "jugar", "niños" a "niño", etc.
- Eliminación de palabras vacías: Algunas palabras como artículos o preposiciones contienen menos información y se pueden evitar utilizando esta opción. El filtro predeterminado de palabras vacías "inglés" no solo se enfoca en eliminar artículos y preposiciones, sino también algunas otras palabras, como "cuándo", "nosotros mismos", "mi", "no", "no", etc.
- Indexación: Una vez que el texto está preprocesado, se almacena en un índice invertido.
Una vez realizada la indexación, podemos aplicar la búsqueda.
- Puntuación y clasificación: BM25 (Best Match 25) es un algoritmo muy utilizado. Clasifica los documentos de forma similar a como la búsqueda vectorial clasifica las incrustaciones (o cualquier vector general) por similitud. BM25 es solo una forma mejorada de TF-IDF y depende de 3 factores: frecuencia del término, frecuencia inversa del documento (recompensando los términos raros) y normalización de la longitud del documento.
# Ejempl
El índice de búsqueda de texto completo se puede agregar simplemente especificando el tipo fts. Podemos especificar si elegir lematización o stemming, así como la elección de los filtros de palabras vacías.
ALTER TABLE default.en_wiki_abstract
ADD INDEX body_idx body
TYPE fts('{"body":{"tokenizer":{"type":"stem", "stop_word_filters":["english"]}}}');
SELECT
id,
title,
body,
TextSearch(body, 'thanksgiving for vegans') AS score
FROM default.en_wiki_abstract
ORDER BY score DESC
LIMIT 5;

# Búsqueda Híbrida
Si bien la búsqueda de texto completo proporciona cierta flexibilidad, todavía tiene una capacidad limitada para encontrar texto semánticamente similar. Para ello, debemos confiar en las incrustaciones, que pueden capturar el significado semántico más profundo del texto. Por otro lado, la búsqueda de texto completo tiene sus propias ventajas, ya que es excelente para la recuperación básica de palabras clave y la coincidencia de texto.
Por otro lado, la búsqueda vectorial (impulsada por incrustaciones) sobresale en la coincidencia semántica entre documentos y la comprensión profunda de la semántica. Sin embargo, puede carecer de eficiencia cuando se trata de consultas de texto corto.
Para obtener lo mejor de ambos mundos, se puede emplear un enfoque de búsqueda híbrido. Al integrar la búsqueda de texto completo y la búsqueda vectorial, el enfoque híbrido puede ofrecer una experiencia de búsqueda más completa y potente. Los usuarios pueden beneficiarse de la precisión de la recuperación basada en palabras clave, así como de la comprensión semántica más profunda que permiten las incrustaciones. Esto permite resultados de búsqueda más precisos y relevantes, que se adaptan a una amplia gama de necesidades de los usuarios y tipos de consultas.
# Ejemplo
Usemos un ejemplo para ilustrarlo más a fondo. Seguiremos utilizando la misma tabla wiki_abstract_mini para facilitar la comparación. El índice de búsqueda de texto completo se agrega en body, mientras que el índice vectorial en la incrustación respectiva lo complementará aún más.
ALTER TABLE default.wiki_abstract_mini
ADD INDEX body_idx (body)
TYPE fts('{"body":{"tokenizer":{"type":"stem", "stop_word_filters":["english"]}}}');
#Crear índice vectorial
ALTER TABLE default.wiki_abstract_mini
ADD VECTOR INDEX body_vec_idx body_vector
TYPE MSTG('metric_type=Cosine');
Dado que la búsqueda vectorial se aplica directamente a las incrustaciones en lugar del texto, utilizaremos el modelo E5 grande aquí (a través de Hugging Face). Crear una función nos permitirá llamarla directamente cuando la necesitemos.
CREATE FUNCTION EmbeddingE5Large
ON CLUSTER '{cluster}' AS (x) -> EmbedText (
concat('query: ', x),
'HuggingFace',
'https://api-inference.huggingface.co/models/intfloat/multilingual-e5-large',
'hf_xxxx',
''
);
# Función de Búsqueda Híbrida
La función HybridSearch() es un método de búsqueda que combina las fortalezas de la búsqueda vectorial y la búsqueda de texto. Este enfoque no solo mejora la comprensión de la semántica del texto largo, sino que también aborda las deficiencias semánticas de la búsqueda vectorial en el dominio del texto corto.
SELECT
id,
title,
body,
HybridSearch('fusion_type=RSF', 'fusion_weight=0.6')(body_vector, body, EmbeddingE5Large('Charted by the BGLE'), ' BGLE') AS score
FROM default.wiki_abstract_mini
ORDER BY score DESC
LIMIT 5;

# Búsqueda Multimodal
La búsqueda híbrida nos ofrece una combinación de búsqueda de texto completo y búsqueda vectorial. Sin embargo, la búsqueda multimodal va un paso más allá al habilitar búsquedas en diferentes tipos de datos, como imágenes, videos, audio y texto.
Este concepto se basa en el aprendizaje contrastivo (opens new window), y la búsqueda multimodal funciona con un mecanismo simple:
- Un modelo unificado como CLIP (Preentrenamiento Contrastivo de Lenguaje e Imagen) (opens new window) procesa varios tipos de datos (como imágenes o texto) y los convierte en embeddings.
- Estos embeddings se mapean en un único espacio vectorial compartido, lo que los hace comparables entre tipos de datos.
- Independientemente de la forma original de los datos, se devuelven los embeddings más cercanos al embedding de la consulta.
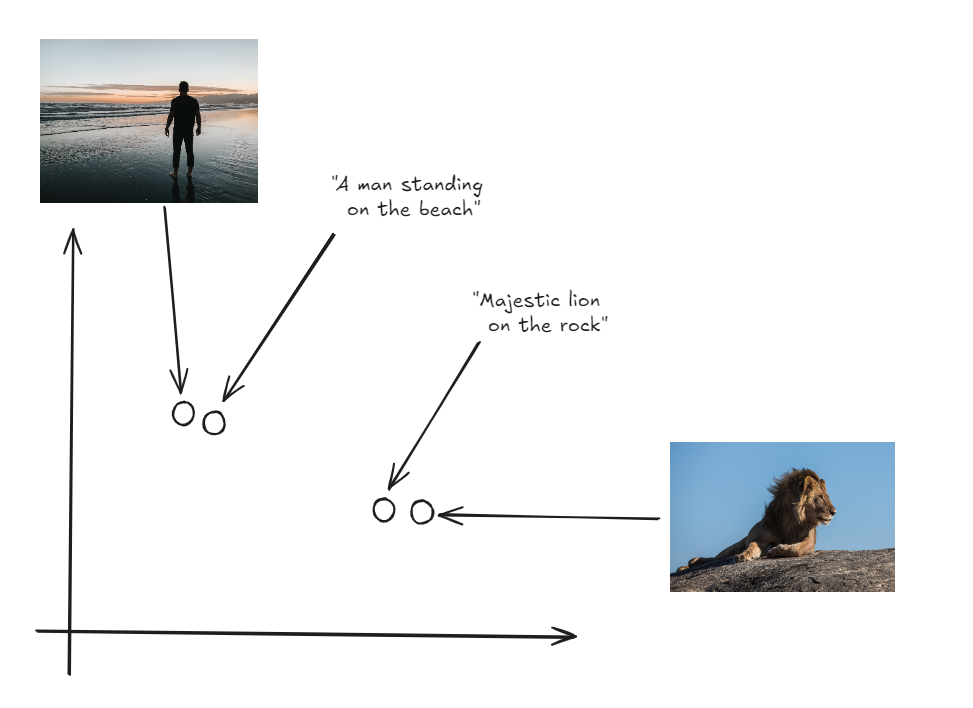
Este enfoque nos permite recuperar resultados diversos y relevantes, ya sean imágenes, texto, audio o videos, basándonos en una única consulta. Por ejemplo, puedes buscar una imagen proporcionando una descripción en texto (opens new window) o encontrar un video utilizando un clip de audio.
Al alinear todos los tipos de datos en un único espacio vectorial, la búsqueda multimodal elimina la necesidad de combinar resultados separados de diferentes modelos. Esto también demuestra cuán poderosas y flexibles pueden ser las bases de datos vectoriales, ayudando a recuperar datos de múltiples tipos de fuentes sin problemas.
# Conclusión
Las bases de datos vectoriales han revolucionado la forma en que se almacenan los datos, proporcionando no solo una velocidad mejorada, sino también una inmensa utilidad en diversos dominios, como la inteligencia artificial y el análisis de big data. Y la piedra angular de esta tecnología reside en las capacidades de búsqueda.
MyScale proporciona 3 tipos de búsqueda, que hemos cubierto: vectorial, texto completo y búsqueda híbrida. Al cubrir los algoritmos de indexación y proporcionar estas diversas funcionalidades de búsqueda, MyScale permite a los usuarios abordar una amplia gama de desafíos de recuperación de datos en diferentes dominios y casos de uso. Esperamos que los ejemplos proporcionados le brinden una buena comprensión de estas capacidades de búsqueda y de cómo aprovecharlas de manera efectiva.



