
Tradicionalmente, el aprendizaje automático (ML, por sus siglas en inglés) (opens new window) se puede clasificar ampliamente en dos tipos: aprendizaje supervisado y aprendizaje no supervisado (opens new window). En el aprendizaje supervisado, tenemos datos con etiquetas y estas etiquetas se utilizan para entrenar el modelo. Por ejemplo, se pueden utilizar imágenes etiquetadas de diferentes objetos para entrenar un clasificador de imágenes.
El aprendizaje no supervisado, por otro lado, no requiere ninguna etiqueta y aquí exploramos los patrones sin ninguna información previa. Inevitablemente, es difícil pero también atractivo. Con toneladas de datos disponibles (y nuevos datos producidos todos los días), siempre es fácil obtener los datos, aunque etiquetarlos requiere mucho tiempo y dinero.
Para aprovechar las enormes cantidades de datos disponibles a nuestro alrededor, existe una estrategia de aprendizaje avanzada, conocida como aprendizaje auto-supervisado. En el aprendizaje auto-supervisado, tomamos los datos no etiquetados y imitamos el aprendizaje supervisado.
# Aprendizaje Auto-Supervisado (SSL)
En el aprendizaje auto-supervisado, dividimos los datos en muestras positivas y negativas, similar a la clasificación binaria (supervisada), tratando el objeto en consideración como un ejemplo positivo y todas las demás muestras como negativas.
Los métodos de aprendizaje auto-supervisado aprenden incrustaciones conjuntas y se pueden clasificar ampliamente en dos tipos:
- Métodos contrastivos
- Métodos no contrastivos
En los métodos contrastivos, tomamos diferentes muestras de los mismos datos, como diferentes vistas de la misma imagen, e intentamos maximizar sus puntuaciones de similitud, mientras intentamos minimizarlas para las otras muestras/imágenes. Los métodos no contrastivos, por otro lado, no tienen en cuenta las muestras negativas. Algunos de los métodos SSL famosos como BYOL o DINO son buenos ejemplos de métodos no contrastivos, mientras que SimCLR y MoCo también utilizan ejemplos negativos y son buenos ejemplos de métodos contrastivos.
# Aprendizaje Contrastivo (CL)
El aprendizaje contrastivo se centra en un concepto simple de elegir una representación que maximice las similitudes entre pares de datos positivos, mientras se minimiza para los pares negativos. Por ejemplo, ingreso una imagen de una mango y ahora su objetivo debería ser maximizar la similitud entre las imágenes de mangos mientras se minimiza para otras imágenes.
La configuración más simple es considerar cada punto de datos (al considerarlo) como un punto de datos positivo, mientras que se considera a todos los demás como puntos de datos negativos. Supongamos que el punto es
# Entrenamiento
Para cada par de puntos de datos
Para hacer que el entrenamiento sea más práctico, lo realizamos en lotes y supongamos que tenemos un lote de 32 imágenes, entonces 1 imagen (en sí misma) debe tener una puntuación de similitud maximizada, mientras que las otras 31 deben tener una puntuación de similitud minimizada tanto como sea posible.
Sin embargo, tener un solo ejemplo positivo frente a varios ejemplos negativos hace que sea bastante difícil aprender características discriminativas, por lo que empleamos algunas técnicas inteligentes como la ampliación de datos para hacer múltiples copias del mismo punto de datos.
# Ejemplos de CL
El aprendizaje contrastivo ha estado presente durante algún tiempo. En los últimos 10 años, ha recorrido un largo camino desde la discriminación de imágenes basada en CNN normal (opens new window) (que simplemente superaba a SIFT) hasta CLIP. Algunos de los algoritmos modernos de CL son:
- Contrastive Predictive Coding, CPC
- Un marco simple para el aprendizaje contrastivo de representaciones (visuales), SimCLR
- Momentum Contrast, MoCo
- Preentrenamiento contrastivo de lenguaje-imagen, CLIP
Veamos brevemente cada uno de ellos para tener una mejor idea de cómo se está utilizando el aprendizaje contrastivo en la práctica.
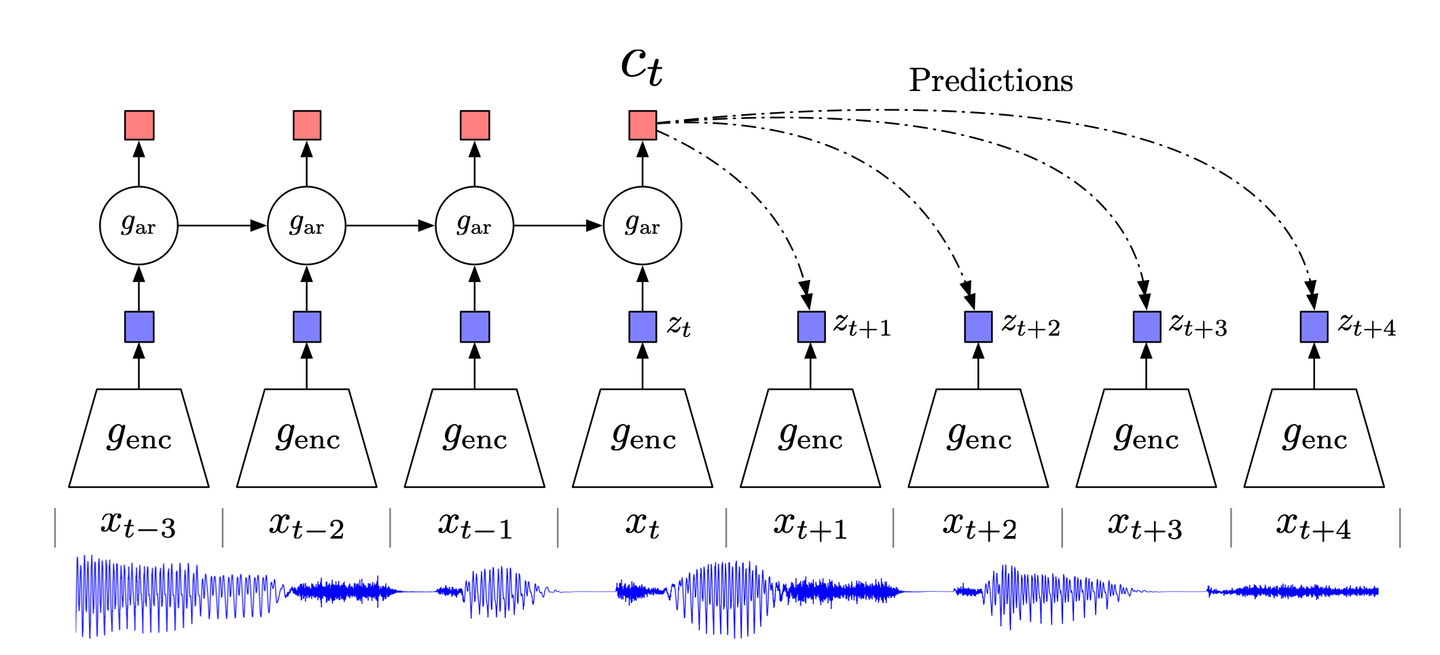
# Contrastive Predictive Coding
Inspirado en la técnica clásica de compresión de datos de codificación predictiva y su adaptación en neurociencia, CPC (Contrastive Predictive Coding) (opens new window) se centra en la información de alto nivel en los datos, mientras ignora el nivel de detalle/ruido.
CPC, en pocas palabras, funciona de la siguiente manera:
- Los datos de alta dimensión se comprimen en un espacio de incrustación latente adecuado. Esta compresión facilita el modelado de los datos y la realización de predicciones en consecuencia.
- Se realizan predicciones en el espacio de incrustación elegido.
- El modelo se entrena utilizando la función de pérdida de Estimación Contrastiva de Ruido (NCE, por sus siglas en inglés).
# SimCLR
Un marco simple para el aprendizaje contrastivo de representaciones visuales, SimCLR es una técnica avanzada de aprendizaje contrastivo para la visión por computadora. Sin necesidad de ninguna pre-ampliación o arquitectura especializada, SimCLR funciona de la siguiente manera:
- Se elige una imagen al azar y se generan sus vistas (dos en la implementación original) utilizando diferentes técnicas de ampliación como recorte aleatorio, distorsión de color aleatoria o desenfoque gaussiano.
- Se calcula la representación/incrustación de la imagen utilizando una CNN basada en ResNet.
- Esta representación se transforma aún más en una proyección (no lineal) utilizando una MLP.
- Tanto la CNN como la MLP se entrenan para minimizar la función de pérdida contrastiva.
Hasta ahora, hemos estado hablando de la necesidad de aprendizaje no supervisado, pero también tenemos algunos datos etiquetados a nuestra disposición. Al final, si ajustamos finamente la CNN en algunas imágenes etiquetadas, esto ayuda a aumentar su rendimiento y generalización en diversas otras tareas (subsiguientes).
Algunos conocimientos sobre cómo funciona el aprendizaje contrastivo
No solo SimCLR introdujo un nuevo modelo con un rendimiento muy bueno (puedes consultar su artículo para un análisis detallado de los resultados), sino que sus autores también dieron algunas ideas nuevas que pueden ser útiles para casi cualquier método de aprendizaje contrastivo. Así que consideré que valía la pena compartirlos aquí:
Una combinación de técnicas de ampliación es fundamental: El recorte aleatorio y la distorsión de color no dieron resultados destacados cuando se usaron individualmente, pero cuando se usaron en conjunto, dieron los mejores resultados.
La proyección no lineal es importante: La naturaleza compleja de las redes neuronales y la función de pérdida contrastiva significa que es difícil entender qué está sucediendo detrás de escena, pero empíricamente está claro que la proyección no lineal (mediante MLP) es útil ya que aumenta el rendimiento hasta en un 10%. Este hecho también se observará de manera independiente en la publicación de MoCov2, como veremos en breve.
Aumentar la escala mejora el rendimiento: Si bien algunas de las observaciones son específicas de SimCLR, son principalmente genéricas en el aprendizaje contrastivo. Aumentar la capacidad del modelo (ya sea el ancho o la profundidad), aumentar el tamaño del lote o incluso el número de épocas, todo conduce a un aumento en el rendimiento.
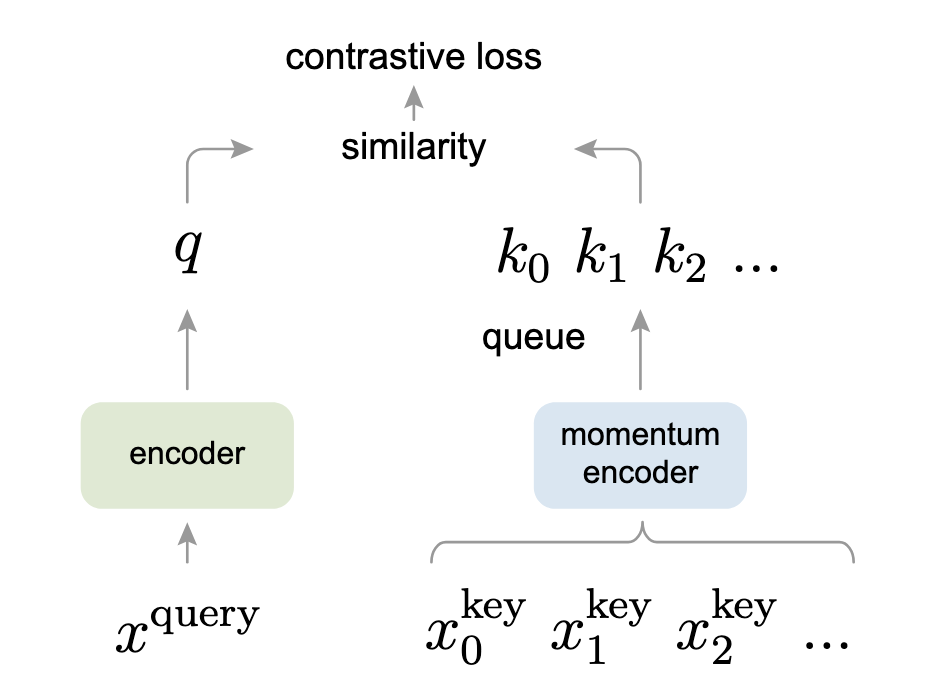
# Momentum Contrast (MoCo)
Momentum Contrast (MoCo) adopta una visión alternativa del aprendizaje contrastivo como una búsqueda en un diccionario. Este punto de vista interesante, que tiene algunas similitudes con los modelos de transformadores, funciona de la siguiente manera:
- Se aplica ampliación de datos para producir dos copias,
- El codificador de consulta (a la izquierda en la imagen de abajo) toma
- El codificador de momento toma la otra copia ampliada,
Para que sea relevante, se implementa como una cola, que toma
- La consulta codificada,
- Ambos codificadores se entrenan juntos para minimizar esta pérdida contrastiva.
Si estás familiarizado con los transformadores, puedes ver que la pérdida InfoNCE es bastante similar a la forma en que calculamos la atención en los transformadores.
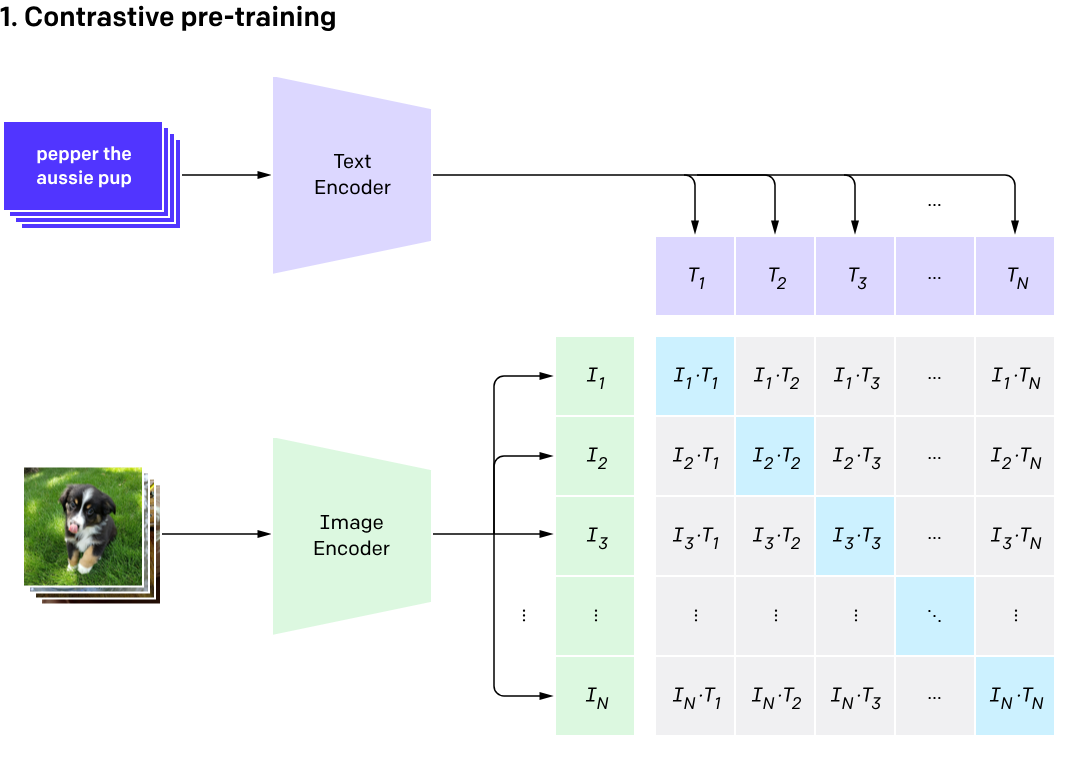
# CLIP
Introducido en 2021, CLIP sube la apuesta al combinar tanto imágenes como sus descripciones. Si bien no funciona de manera similar a un promedio móvil basado en el momento, también funciona con dos codificadores, uno para texto y otro para imágenes. Aquí está su flujo de trabajo breve:
- La imagen se ingresa en el codificador de imágenes y su descripción se ingresa en el codificador de texto.
- El codificador de imágenes, basado en un ViT (Vision Transformer), obtiene la incrustación de la imagen, mientras que el codificador de texto tokeniza la descripción para obtener las características de texto. Estas características se agrupan como un par en el espacio de incrustación.
- Tanto los codificadores de texto como de imágenes se entrenan de manera que se maximice la distancia de cualquier par dado de
- Durante las pruebas, proporcionamos un diccionario de descripciones (que no debe confundirse con el diccionario dinámico en MoCo) y la imagen deseada. Basándose en la imagen, devuelve la descripción con la probabilidad más alta.
Nota: Para obtener más detalles sobre CLIP, por favor lee esto (opens new window).
# Ejemplo de Código
Vamos a concluir con un ejemplo de código para completar el panorama. Aquí, utilizaré la implementación oficial de MoCo (opens new window) de Meta Research. Este código se centra principalmente en la clase MoCo.
# Constructor
El constructor de la clase MoCo inicializa los atributos como K, m y T. Como podemos ver, utiliza los valores predeterminados de la dimensión de características (dim) como 128, el tamaño de la cola (K) como 16 bits (65,536), mientras que el coeficiente de momento, μ, es 0.999 (promedio móvil bastante lento). La temperatura softmax τ, como ya se especificó en el artículo, es 0.07.
También podemos ver la implementación de MLP que vimos primero en SimCLR y luego en MoCov2 (esta implementación incluye ambas versiones).
def __init__(self, base_encoder, dim=128, K=65536, m=0.999, T=0.07, mlp=False):
super(MoCo, self).__init__()
self.K = K
self.m = m
self.T = T
# create the encoders
# num_classes is the output fc dimension
self.encoder_q = base_encoder(num_classes=dim)
self.encoder_k = base_encoder(num_classes=dim)
if mlp: # hack: brute-force replacement
dim_mlp = self.encoder_q.fc.weight.shape[1]
self.encoder_q.fc = nn.Sequential(
nn.Linear(dim_mlp, dim_mlp), nn.ReLU(), self.encoder_q.fc
)
self.encoder_k.fc = nn.Sequential(
nn.Linear(dim_mlp, dim_mlp), nn.ReLU(), self.encoder_k.fc
)
for param_q, param_k in zip(
self.encoder_q.parameters(), self.encoder_k.parameters()
):
param_k.data.copy_(param_q.data) # initialize
param_k.requires_grad = False # not update by gradient
# create the queue
self.register_buffer("queue", torch.randn(dim, K))
self.queue = nn.functional.normalize(self.queue, dim=0)
self.register_buffer("queue_ptr", torch.zeros(1, dtype=torch.long))
# Codificador de Momento
La parte principal es simple pero muy efectiva. En el codificador de momento, simplemente implementamos esta ecuación para el promedio basado en el momento:
@torch.no_grad()
def _momentum_update_key_encoder(self):
for param_q, param_k in zip(
self.encoder_q.parameters(), self.encoder_k.parameters()
):
param_k.data = param_k.data * self.m + param_q.data * (1.0 - self.m)
# Gestión de la Cola
Finalmente, la cola se actualiza para eliminar los datos antiguos del lote. Funciona de la siguiente manera:
- Primero recopilamos las claves.
- El puntero de la cola apunta a la transposición de las
claves. Ahora, por qué se hace precisamente para las columnas y no para las filas es algo que me intriga. - Al final, el puntero se mueve al siguiente lote (el módulo aquí es para la cola circular) y se refleja en el atributo (
self.queue_ptr) también.
def _dequeue_and_enqueue(self, keys):
keys = concat_all_gather(keys)
batch_size = keys.shape[0]
ptr = int(self.queue_ptr)
assert self.K % batch_size == 0
self.queue[:, ptr : ptr + batch_size] = keys.T
ptr = (ptr + batch_size) % self.K
self.queue_ptr[0] = ptr
# Entrenamiento
En el paso de entrenamiento, combinamos todo esto de la siguiente manera:
- Calcular características de consulta
- Calcular características de clave (usando la actualización de momento)
- Calcular los logits (tanto positivos como negativos)
- Desencolar y encolar usando la función que acabamos de discutir anteriormente
def forward(self, im_q, im_k):
"""
Input:
im_q: a batch of query images
im_k: a batch of key images
Output:
logits, targets
"""
# compute query features
q = self.encoder_q(im_q) # queries: NxC
q = nn.functional.normalize(q, dim=1)
# compute key features
with torch.no_grad(): # no gradient to keys
self._momentum_update_key_encoder() # update the key encoder
# shuffle for making use of BN
im_k, idx_unshuffle = self._batch_shuffle_ddp(im_k)
k = self.encoder_k(im_k) # keys: NxC
k = nn.functional.normalize(k, dim=1)
# undo shuffle
k = self._batch_unshuffle_ddp(k, idx_unshuffle)
# compute logits
# Einstein sum is more intuitive
# positive logits: Nx1
l_pos = torch.einsum("nc,nc->n", [q, k]).unsqueeze(-1)
# negative logits: NxK
l_neg = torch.einsum("nc,ck->nk", [q, self.queue.clone().detach()])
# logits: Nx(1+K)
logits = torch.cat([l_pos, l_neg], dim=1)
# apply temperature
logits /= self.T
# labels: positive key indicators
labels = torch.zeros(logits.shape[0], dtype=torch.long).cuda()
# dequeue and enqueue
self._dequeue_and_enqueue(k)
return logits, labels
Por cierto, todos estos comentarios están escritos por los propios autores y muestran que no solo escribieron un artículo claro, sino también un código bueno y fácil de entender.

# Aprendizaje Contrastivo y Bases de Datos Vectoriales
Dado que el aprendizaje contrastivo se centra en las incrustaciones de datos de entrada y su distancia, son altamente relevantes para las bases de datos vectoriales. Utilizando un modelo de CL entrenado, simplemente podemos aplicar una métrica como la distancia euclidiana, la similitud del coseno o la distancia
Como resultado, podemos tener innumerables aplicaciones del aprendizaje contrastivo en conjunto con las bases de datos vectoriales, por ejemplo:
- Reconocimiento de cero disparo (puede tener varias aplicaciones en sí mismo) utilizando CLIP
- Sistema de recomendación para un usuario en línea: basado en el historial del usuario, sugerirá los productos que tienen la mayor proximidad a esas incrustaciones.
- Recuperación de documentos: recuperar el documento de la base de datos que está más cerca de la incrustación de consulta del usuario.
- Detección de anomalías: si una nueva transacción con esta tarjeta de crédito es normal o fraudulenta se puede verificar utilizando las incrustaciones de transacciones anteriores y encontrando la similitud (o disimilitud) entre esta transacción y la "región" del historial de transacciones en el espacio de incrustación.
# Referencias
- Dosovitskiy, et al., Discriminative Unsupervised Feature Learning with Exemplar Convolutional Neural Networks, IEEE PAMI, 2016.
- Hjelm, et al., Learning Deep Representations by Mutual Information Estimation and Maximization, ICLR, 2019.
- Oord, et al., Representation Learning with Contrastive Predictive Coding, arXiv 2018.
- Chen, et al., A Simple Framework for Contrastive Learning of Visual Representations, ICML 2020.
- Radford, et al., Learning Transferable Visual Models From Natural Language Supervision, arXiv 2020
- He, et al., Momentum Contrast for Unsupervised Visual Representation Learning, arXiv 2020
- He, et al., Improved Baselines with Momentum Contrastive Learning, arXiv 2020



