
Los Modelos de Lenguaje de Gran Tamaño (LLMs, por sus siglas en inglés) han facilitado muchas tareas como la creación de chatbots, la traducción de idiomas, la síntesis de texto y muchas más. En el pasado, solíamos escribir modelos para diferentes tareas y siempre había problemas con su rendimiento. Ahora, podemos realizar la mayoría de las tareas fácilmente con la ayuda de los LLMs. Sin embargo, los LLMs tienen algunas limitaciones cuando se aplican a casos de uso del mundo real. Carecen de información específica o actualizada, lo que lleva a un fenómeno llamado alucinación (opens new window), donde el modelo genera resultados incorrectos o impredecibles.
Las bases de datos vectoriales (opens new window) resultaron ser muy útiles para mitigar el problema de la alucinación en los LLMs al proporcionar una base de datos de datos específicos del dominio a los modelos. Esto reduce los casos de respuestas inexactas o sin sentido.
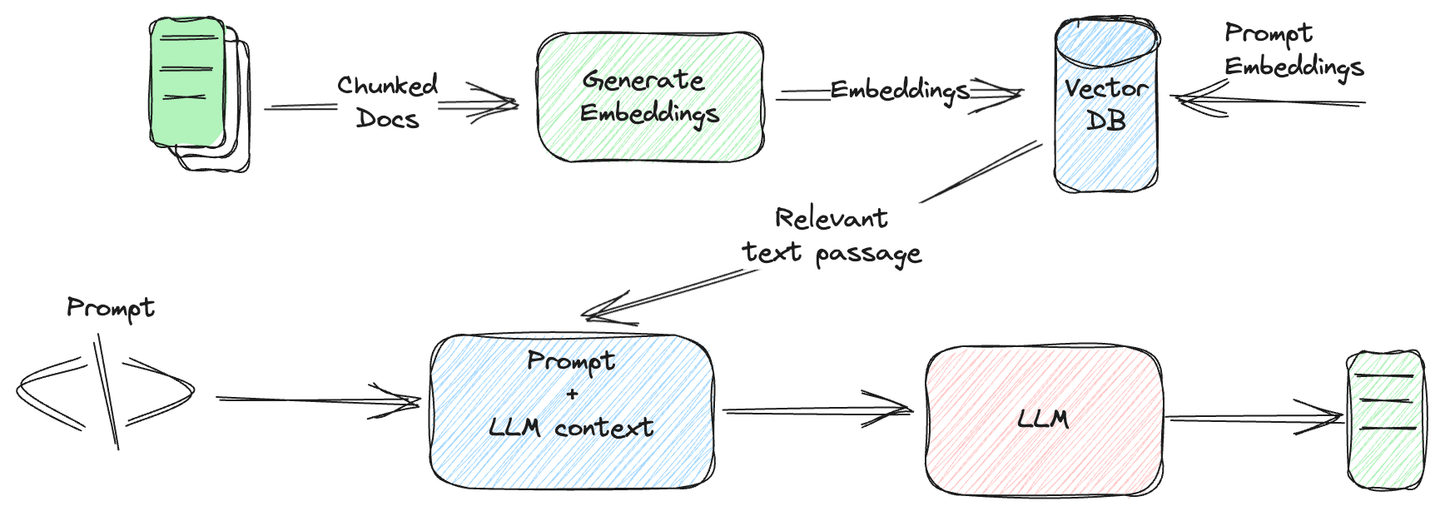
En esta publicación de blog, veremos cómo la integración de las bases de datos vectoriales con SQL ha facilitado la vida de las empresas. Discutiremos algunas limitaciones de las bases de datos tradicionales y lo que llevó a esta nueva integración, la base de datos vectorial SQL. Al final del blog, veremos cómo funcionan estas bases de datos y por qué MyScale (opens new window) podría ser su primera opción al seleccionar bases de datos vectoriales.
# ¿Qué son las Bases de Datos Vectoriales SQL?
Una base de datos vectorial SQL es un tipo especializado de base de datos que combina las capacidades de las bases de datos SQL tradicionales con las capacidades de una base de datos vectorial. Te proporciona la capacidad de almacenar y consultar vectores de alta dimensión de manera eficiente con la ayuda de SQL.
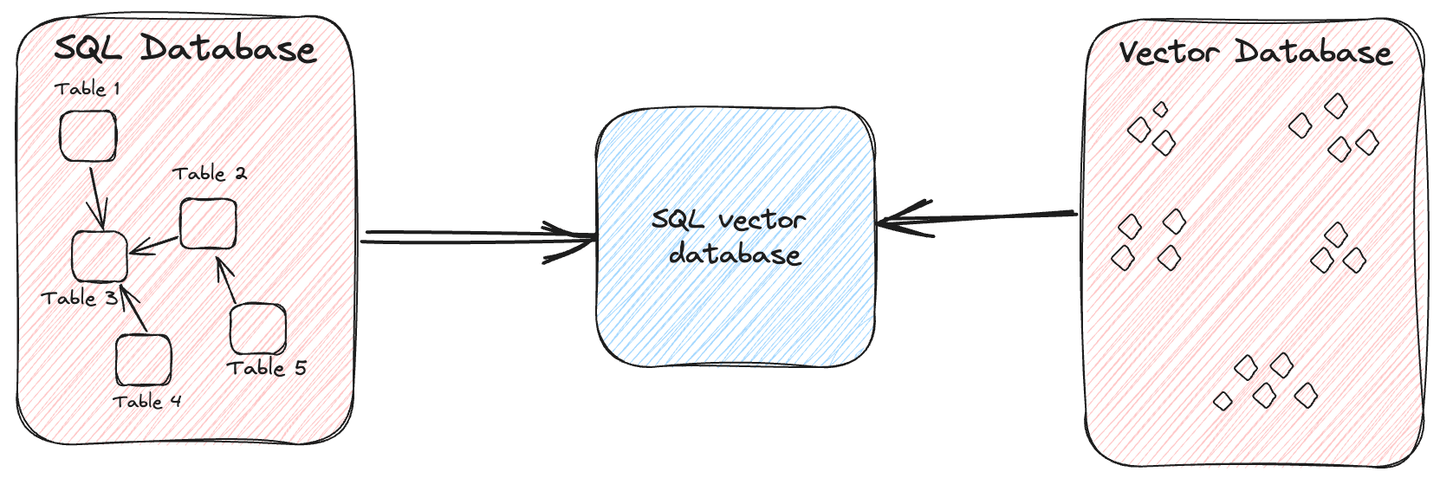
En términos sencillos, es como una base de datos regular que puedes utilizar para almacenar tanto datos estructurados como datos no estructurados, pero con la capacidad adicional de realizar consultas rápidas en varios tipos de datos, incluyendo imágenes, videos, audio y texto. El mecanismo detrás de esta eficiencia radica en la creación de vectores para los datos, lo que facilita la identificación rápida de entradas similares.
Ahora, intentemos comprender los conceptos fundamentales de las bases de datos vectoriales SQL que ayudarán a comprender por qué necesitamos bases de datos vectoriales SQL.
# Conceptos Clave en las Bases de Datos Vectoriales SQL
Las bases de datos vectoriales SQL introdujeron algunos conceptos innovadores que mejoran significativamente la recuperación y el análisis de datos, especialmente en el contexto de datos no estructurados y de alta dimensión. Exploraremos algunos de ellos:
- Manejo de datos no estructurados: Las representaciones vectoriales de los datos te permiten realizar búsquedas de vecinos más cercanos aproximados (ANN, por sus siglas en inglés) en datos no estructurados. Cuando encuentras las incrustaciones de datos no estructurados como texto, imágenes o audio, capturas el significado semántico que te permite realizar comparaciones de similitud midiendo la distancia entre vectores para encontrar los vecinos más cercanos, independientemente del formato original de los datos.
- Búsqueda ANN: Las bases de datos vectoriales SQL almacenan datos como vectores y realizan un tipo de búsqueda conocida como búsqueda de similitud, que no se realiza en una sola fila, sino que realiza una búsqueda de vecinos más cercanos aproximados (ANN). Este proceso implica identificar los vectores que están más cerca de un vector de consulta dado, es decir, aquellos cuyas propiedades se alinean más estrechamente con las propiedades del vector de consulta.
- Indexación de vectores: La indexación de vectores se refiere a las estructuras de datos y algoritmos especializados utilizados para organizar y consultar grandes cantidades de datos vectoriales de manera eficiente. Las bases de datos vectoriales utilizan diversas estrategias de indexación de vectores para optimizar la recuperación y gestión de datos. Algunas bases de datos vectoriales utilizan algoritmos de gráficos jerárquicos para acelerar el rendimiento de búsqueda. Algunos proveedores pueden desarrollar su propio algoritmo de indexación, por ejemplo, MyScale ha desarrollado una técnica novedosa llamada Multi-Scale Tree Graph (MSTG) que supera significativamente los enfoques existentes (opens new window).
Nota:
El objetivo de la indexación de vectores es optimizar la velocidad y precisión de búsqueda al realizar operaciones como la búsqueda de similitud para encontrar vecinos más cercanos aproximados en vectores de alta dimensión.
# ¿Por qué necesitamos Bases de Datos Vectoriales SQL?
Entonces, surge la pregunta: ¿Por qué necesitamos bases de datos vectoriales SQL? Las bases de datos tradicionales como MySQL, PostgreSQL y Oracle han funcionado bien durante mucho tiempo y tienen todas las características necesarias para mantener los datos organizados. Tienen métodos rápidos de indexación que garantizan que obtengas los datos exactos que necesitas sin problemas. ¿Por qué necesitamos una base de datos vectorial SQL?
Sin duda, las bases de datos tradicionales son excelentes, pero tienen algunas limitaciones cuando los datos se vuelven enormes y no estructurados. Veamos:
- Falta de velocidad y comprensión semántica: Las bases de datos tradicionales se basan en la coincidencia exacta de palabras clave y la indexación para recuperar datos. Pero con el crecimiento exponencial de datos no estructurados de las redes sociales, los sensores, etc., las bases de datos tradicionales no comprenden la semántica de los datos. Se necesita una base de datos que no solo pueda recuperar datos rápidamente, sino que también comprenda el contexto y la semántica de las consultas. Por ejemplo, al tratar con consultas en lenguaje natural o relaciones de datos complejas, los métodos tradicionales tienen dificultades para proporcionar resultados rápidos y relevantes.
- Problemas con datos de alta dimensión: Las bases de datos relacionales almacenan datos en forma de filas y columnas. A medida que aumenta el número de columnas o dimensiones, el rendimiento de las consultas disminuye y se produce un fenómeno llamado "maldición de la dimensionalidad". Por lo tanto, necesitamos una base de datos que pueda eliminar el problema de la dimensionalidad sin perder el rendimiento de las consultas.
- Datos no estructurados: Las bases de datos relacionales requieren que los datos no estructurados se transformen y se aplasten en filas y columnas en tablas. Pero una cantidad cada vez mayor de datos valiosos en la actualidad es no estructurada: imágenes, videos, audio, documentos de texto, etc., lo cual es muy difícil de almacenar en las bases de datos relacionales.
- Preocupaciones de escalabilidad: La escalabilidad es un desafío para las bases de datos tradicionales, especialmente cuando se trata de volúmenes masivos de datos. Esto se convierte en un problema para las organizaciones que manejan grandes conjuntos de datos, lo que les dificulta procesar y analizar los datos de manera efectiva. Por lo tanto, necesitamos una base de datos que pueda manejar grandes cantidades de datos manteniendo la misma velocidad y eficiencia.
Para abordar estos desafíos, surgió el desarrollo de las bases de datos vectoriales SQL, presentando una alternativa superior a las bases de datos tradicionales.
# Cómo las Bases de Datos Vectoriales SQL Superan a las Bases de Datos Tradicionales
La combinación de SQL con vectores ofrece muchos beneficios, entre los cuales destacan varias ventajas por su impacto significativo:
- Mayor rendimiento y búsqueda semántica: La representación vectorial permite a la base de datos extraer los significados semánticos de los datos almacenados. Además, el proceso se vuelve aún más rápido porque encontramos la similitud de vectores aquí. Esto es útil para muchas aplicaciones, como los sistemas de recomendación, donde la relación semántica entre los datos es más importante.
- Recuperación eficiente de datos: Las bases de datos vectoriales SQL utilizan la técnica de vecino más cercano aproximado (ANN) para encontrar los registros coincidentes. Al calcular la similitud del coseno entre tu consulta y el conjunto de datos, proporciona eficientemente los resultados más relevantes principales 'K'.
- Soporte para datos estructurados y no estructurados: La introducción de SQL en la base de datos vectorial permite representar los datos no estructurados en vectores y almacenar los significados semánticos. De esta manera, puedes consultar fácilmente cualquier tipo de datos estructurados o no estructurados.
- Interfaz SQL familiar: Una de las mayores ventajas de las bases de datos vectoriales SQL es que proporcionan una interfaz SQL familiar para consultar datos. Te permite utilizar tus habilidades de SQL y minimizar la curva de aprendizaje al adoptar las capacidades vectoriales. Las consultas se pueden escribir utilizando la sintaxis estándar de SQL.
# Cómo Funcionan las Bases de Datos Vectoriales SQL
La integración de SQL y las bases de datos vectoriales implica almacenar e indexar vectores de alta dimensión de manera que se puedan consultar de manera eficiente utilizando SQL. Este proceso implica ciertos pasos.
Nota:
En este proyecto, utilizamos MyScale, una base de datos vectorial basada en SQL para la implementación inicial. Sin embargo, diferentes bases de datos vectoriales SQL pueden funcionar de diferentes maneras.
# Paso 1: Configurar la Base de Datos
En primer lugar, debes configurar una base de datos que admita tanto operaciones SQL como operaciones vectoriales. Algunas bases de datos modernas tienen soporte incorporado para vectores, mientras que otras se pueden ampliar con tipos de datos y funciones personalizadas.
CREATE TABLE products (
id INT PRIMARY KEY,
name VARCHAR(100),
description TEXT,
vector Array(Float32),
CONSTRAINT check_length CHECK length(vector) = 1536,
);
En este ejemplo, creamos una tabla products con una columna vector de 1536 dimensiones que almacena los vectores de alta dimensión.
# Paso 2: Inserción de Datos
Al insertar datos, debes almacenar tanto los atributos estructurados como las representaciones vectoriales de los datos no estructurados.
INSERT INTO products (id, name, description, vector)
VALUES (1, 'Smartphone', 'A high-end smartphone with a great camera.', ARRAY[0.13, 0.67, 0.29, ...]);
En esta declaración SQL, insertamos un nuevo registro de producto junto con su vector.
Nota:
Para obtener la representación vectorial de los datos no estructurados, puedes utilizar modelos como GPT-4 y BERT.
# Paso 3: Indexación de Vectores
El siguiente paso es crear índices de vectores. Es la técnica que define la rapidez con la que la base de datos aplica la búsqueda de similitud. Muchas bases de datos vectoriales utilizan técnicas de indexación especializadas como árboles KD, árboles R o estructuras de índice invertido para optimizar estas operaciones.
ALTER TABLE products ADD VECTOR INDEX idx vector TYPE MSTG
Aquí, creamos un índice MSTG, que es adecuado para indexar datos multidimensionales.
Nota:
El algoritmo MSTG fue creado por el equipo de MyScale y ha superado a todos los índices de búsqueda de vectores convencionales (en términos de rendimiento y eficiencia de costos) utilizados por muchas bases de datos vectoriales (opens new window).
# Paso 4: Consulta de Datos
Para consultar los datos, simplemente combinas consultas SQL tradicionales con operaciones vectoriales. Por ejemplo, si deseas encontrar productos similares a un vector de consulta, puedes utilizar la función de distancia entre vectores.
SELECT name, description, distance(vector, query_vector) as dist
FROM products
ORDER BY dist LIMIT 5;
Esta consulta encuentra la distancia entre las representaciones vectoriales de la columna de vectores y el query_vector. Luego, ordena los resultados en orden ascendente con respecto a la distancia.

# La Solución Ideal: MyScale - una Base de Datos Vectorial SQL
Aquí es donde entra en juego MyScale como una solución que combina bases de datos relacionales y bases de datos vectoriales. Construido sobre la base de datos SQL de código abierto ClickHouse, MyScale permite ejecutar consultas vectoriales avanzadas directamente con la sintaxis SQL estándar. Esto elimina la molestia de integrar bases de datos relacionales y vectoriales por separado. A diferencia de otras bases de datos vectoriales como Pinecone, Milvus y Qdrant, MyScale proporciona una única interfaz SQL para la búsqueda vectorial. Permite el almacenamiento de datos escalares y vectoriales, todo dentro de una sola base de datos. Ahora puedes obtener resultados vectoriales ultrarrápidos directamente con SQL familiar.
Se asume ampliamente que las bases de datos relacionales no pueden proporcionar un rendimiento que se equipare al de las bases de datos vectoriales. MyScale rompe este mito. En comparaciones directas, MyScale no solo supera significativamente a pgvector en términos de precisión de búsqueda y velocidad de procesamiento de consultas, sino que también muestra una ventaja significativa sobre bases de datos vectoriales especializadas como Pinecone, especialmente en cuanto a eficiencia de costos y tiempos de construcción de índices. Este rendimiento excepcional, combinado con la simplicidad de SQL, convierte a MyScale en la primera opción para las empresas.
Si tienes más preguntas o estás interesado en nuestra oferta, no dudes en contactarnos en Discord (opens new window) o seguir a MyScale en Twitter (opens new window).



