
En nuestra exploración anterior del Aprendizaje Contrastivo (opens new window), descubrimos cómo los modelos pueden aprender a diferenciar entre datos similares y diferentes acercando los elementos similares y alejando los diferentes en un espacio de incrustación. Discutimos métodos como SimCLR (opens new window), MoCo (opens new window) y CLIP (opens new window), que han avanzado significativamente en el aprendizaje auto-supervisado (opens new window).
Continuando este viaje hacia el aprendizaje métrico, hablemos de la pérdida de tripleta. Se basa en los principios del aprendizaje contrastivo y desempeña un papel crucial en tareas que requieren distinciones detalladas, como el reconocimiento facial, la recuperación de imágenes y la verificación de firmas.
# Aprendizaje Métrico
Antes de sumergirnos en la pérdida de tripleta, es importante entender el Aprendizaje Métrico. El aprendizaje métrico es un tipo de aprendizaje automático que se centra en aprender una función de distancia (o métrica) que mide la similitud entre puntos de datos. La idea principal es simple:
- Los puntos de datos similares deben estar cerca uno del otro en el espacio de incrustación.
- Los puntos de datos diferentes deben estar lejos uno del otro.
Utilizamos un modelo de aprendizaje automático para generar incrustaciones, luego entrenamos el modelo para minimizar la distancia entre puntos de datos similares mientras maximizamos la distancia entre puntos de datos que pertenecen a diferentes categorías o etiquetas.
# Métricas de distancia comunes
Al hablar de distancia, la elección de la distancia depende del usuario. Puede ser euclidiana, de Manhattan o alguna medida de distancia avanzada. Algunas distancias comúnmente utilizadas son:
- Distancia de Minkowski - Minkowski es una generalización de las distancias basadas en la norma al calcular la norma p, donde
- Similitud del coseno - La similitud del coseno se basa en el producto escalar de vectores. Toma en cuenta que los vectores paralelos tienen una similitud de 1 (cos 0º), los perpendiculares de 0 (cos 90º) y los opuestos de -1 (cos 180º) entre ellos.
- Distancia de Manhattan: También conocida como distancia de bloque de la ciudad o L1, la distancia de Manhattan calcula la suma de las diferencias absolutas entre las coordenadas de dos puntos. Es particularmente útil cuando se trata de trayectorias en forma de cuadrícula o en situaciones donde no es posible el movimiento diagonal.
- Distancia de Jaccard - La distancia de Jaccard mide la similitud (o disimilitud) entre dos grupos (conjuntos) al tomar la proporción de sus elementos coincidentes frente a sus elementos totales.
- Distancia de Mahalanobis - La distancia de Mahalanobis es una medida única que tiene en cuenta la distribución de los datos. Se define como:
Aquí
# ¿Qué es la pérdida de tripleta?
Ahora volvamos al tema principal. La pérdida de tripleta funciona según un principio simple. Seleccionamos un punto en el espacio de incrustación (generalmente llamado ancla) con un punto positivo y un punto negativo respectivamente. Inevitablemente, queremos maximizar la distancia con los puntos negativos y minimizarla para los positivos.
Aquí
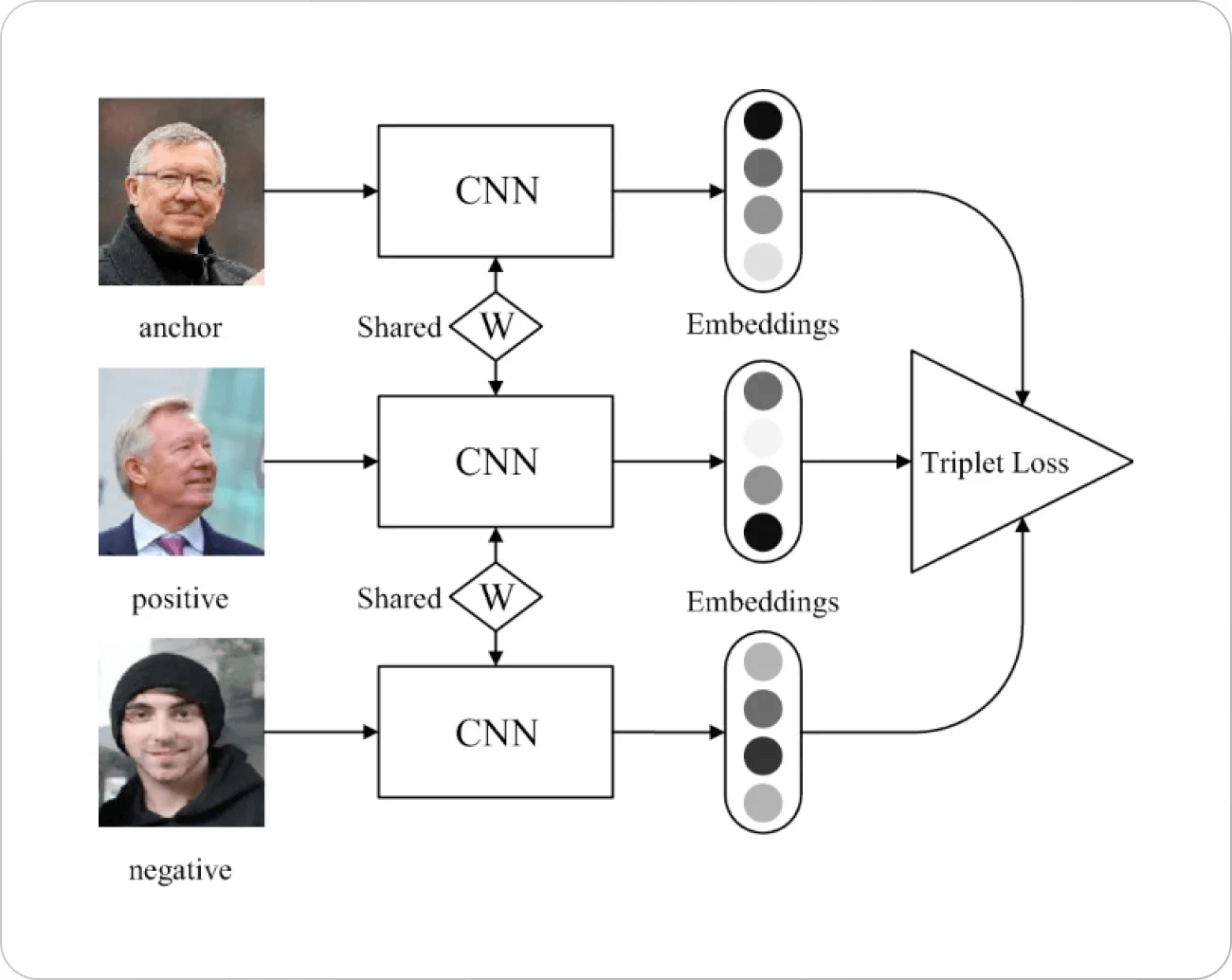
Fuente de la imagen: Artículo de Springer
Hay algo de antecedentes detrás de la motivación de la pérdida de tripleta. Una de las primeras funciones de pérdida para el reconocimiento facial (principalmente basada en la distancia
# Cómo funciona la pérdida de tripleta
Imagina trazar puntos de datos en un espacio de incrustación. Con la pérdida de tripleta:
- Las anclas y los positivos (misma clase) se acercan entre sí.
- Las anclas y los negativos (clases diferentes) se alejan.
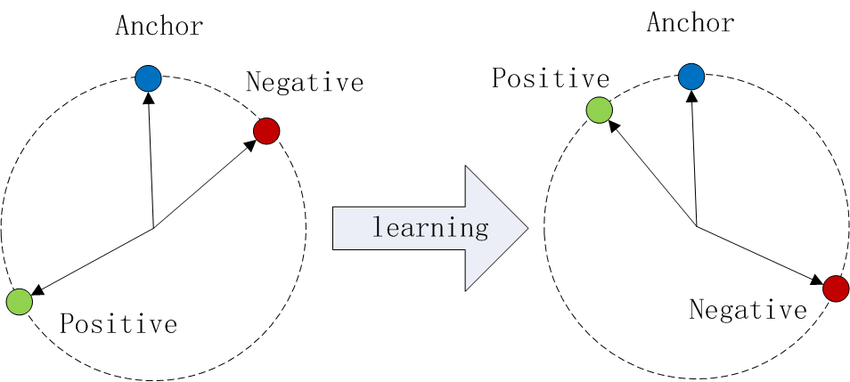
Fuente de la imagen: Wikipedia
Este proceso crea grupos distintos para cada clase, mejorando la capacidad del modelo para distinguir entre ellas.
# El papel del margen α
El margen α es un hiperparámetro que establece la distancia mínima deseada entre los pares positivos y negativos en relación con el ancla. Evita que el modelo colapse todas las incrustaciones en el mismo punto y fomenta una separación significativa entre las clases.
α α
Seleccionar un margen adecuado es crucial para un entrenamiento efectivo.
# ¿Por qué usar la pérdida de tripleta?
La pérdida de tripleta es particularmente útil cuando:
- Las distinciones detalladas son importantes: En tareas como el reconocimiento facial, donde se deben capturar diferencias sutiles.
- Las distribuciones de clases están desequilibradas: Se centra en distancias relativas en lugar de posiciones absolutas en el espacio de incrustación.
- Aprender características discriminativas: Obliga al modelo a prestar atención a las características que diferencian entre clases.
# Minería de tripletas
La pérdida de tripleta definitivamente tiene un costo, ya que necesitamos comparar cada punto con todos los puntos positivos y negativos, lo que significa que el entrenamiento es inviable a medida que crece el conjunto de datos, lo que lleva a una complejidad en el peor de los casos de
Para abordar esto, se realiza un uso inteligente de encontrar positivos difíciles y negativos difíciles. Por ejemplo, en el reconocimiento facial, un positivo difícil pueden ser imágenes de la misma persona pero en entornos bastante diferentes (como iluminación, vestimenta, pose, etc.) y de manera similar, los negativos difíciles pueden ser personas diferentes en entornos similares. El proceso de encontrar estos positivos y negativos difíciles se conoce como minería. Al igual que otros algoritmos que involucran una gran cantidad de datos, también se realiza en lotes pequeños.
# Desafíos
Encontrar estos positivos y negativos difíciles es un problema definitivo, pero surgen desafíos aún mayores más adelante en el entrenamiento.
- Elegir el tamaño de lote adecuado: Tener muy pocos ejemplos conduce a una representación deficiente de los datos y, por lo tanto, a ejemplos difíciles ineficientes. Por otro lado, tener lotes demasiado grandes limita los recursos computacionales (principalmente la memoria de la GPU).
- Grado de dificultad: Presentar los ejemplos difíciles, especialmente los negativos difíciles al principio, conduce a un entrenamiento deficiente [1] y es bastante comprensible. Como resultado, se buscan algunos ejemplos negativos para los cuales se cumple la siguiente desigualdad:
En otras palabras, seleccionamos las muestras negativas,
Nota:
El concepto de aprendizaje curricular es bastante relevante para elegir el grado adecuado de dificultad. Esta técnica, como su nombre lo indica, se inspira en el aprendizaje en la escuela. Usando esta técnica, presentamos al modelo los ejemplos más fáciles primero (como muestras contrastantes en blanco y negro) y gradualmente aumentamos la dificultad. El aprendizaje anti-curricular va en sentido contrario al presentar los ejemplos más difíciles primero y relajarse gradualmente. En 2021, los investigadores [3] realizaron un estudio exhaustivo para descubrir que el aprendizaje curricular puede ser útil en algunos casos, especialmente con datos ruidosos y tiempo de entrenamiento limitado.
- ¿Generar en línea o no generar en línea? Otra opción es si generar todas las tripletas de antemano (en línea) o generarlas dinámicamente. Ambas opciones tienen sus propios méritos y deméritos. La generación en línea nos permite generar lotes normalmente, mientras que la generación en línea es adaptativa. Puede haber una sobrecarga para generar ejemplos difíciles, por otro lado.
# Pérdida de tripleta y aprendizaje contrastivo
Tanto la pérdida de tripleta como el aprendizaje contrastivo tienen como objetivo aprender manteniendo las incrustaciones más cerca de la clase deseada (es decir, distancias más pequeñas) y alejándolas de los valores atípicos, por lo que a menudo se disfrazan como iguales. Si bien su propósito es el mismo, hay una clara diferencia ya que la pérdida contrastiva contrasta cada muestra con un lote de muestras positivas y negativas, mientras que la pérdida de tripleta lo hace (teóricamente) para todas las tripletas posibles.
Dado que el aprendizaje contrastivo no necesita hacer todas las tripletas (o pares), es computacionalmente mucho más rápido que las implementaciones de la pérdida de tripleta. La pérdida de tripleta, por otro lado, tiene una mejor precisión en la mayoría de los casos.
# Diferencia entre el aprendizaje contrastivo y la pérdida de tripleta
Agrupación de datos:
- Aprendizaje contrastivo: Opera en pares de muestras (pares positivos o negativos).
- Pérdida de tripleta: Opera en tripletas de muestras (ancla, positiva, negativa).
Mecanismo de pérdida:
- Aprendizaje contrastivo: Utiliza una decisión binaria sobre si los pares son similares o diferentes.
- Pérdida de tripleta: Se centra en las distancias relativas entre los pares ancla-positiva y ancla-negativa, asegurando que los ejemplos positivos estén más cerca del ancla que los ejemplos negativos.
Flexibilidad:
- Aprendizaje contrastivo: Más simple en términos de cálculo, ya que solo implica pares, pero puede ser menos efectivo en casos complejos donde múltiples ejemplos negativos están cerca del ancla.
- Pérdida de tripleta: Más compleja pero proporciona un mejor control sobre el espacio de incrustación porque optimiza directamente las distancias relativas.
Complejidad del entrenamiento:
- Aprendizaje contrastivo: Generalmente menos complejo de implementar, ya que solo se necesitan pares.
- Pérdida de tripleta: Más complejo ya que requiere tripletas cuidadosamente seleccionadas (a menudo se utilizan negativos difíciles para aumentar el rendimiento).
# Implementación
Podemos implementarlo tomando el ancla (punto de referencia) con muestras positivas y negativas. Aquí, utilizaremos la distancia de Minkowski - es decir, dejaremos la elección del orden de la norma en manos del usuario.
import torch
import torch.nn as nn
class TripletLoss(nn.Module):
def __init__(self, margin=1.0):
super(TripletLoss, self).__init__()
self.margin = margin
def forward(self, anchor, positive, negative, norm_order):
pos_dist = torch.norm(anchor - positive, p=norm_order, dim=1)
neg_dist = torch.norm(anchor - negative, p=norm_order, dim=1)
loss = torch.mean(torch.clamp(pos_dist - neg_dist + self.margin, min=0.0))
return loss
# Mejores prácticas
Algunas de las mejores prácticas para usar la pérdida de tripleta son:
- La distancia euclidiana normal tiene mejores resultados que la euclidiana al cuadrado.
- La normalización (como la normalización por lotes o por capas) generalmente no ayuda en el entrenamiento.
- Un tamaño de lote óptimo ([1] utilizó alrededor de 1800 en la mayoría de los experimentos).

# Conclusión
La pérdida de tripleta es una herramienta valiosa en el aprendizaje métrico que ayuda a los modelos a diferenciar entre puntos de datos similares y diferentes al centrarse en sus distancias relativas. Basándose en las ideas detrás del aprendizaje contrastivo, es especialmente útil para tareas que requieren distinciones sutiles entre clases.
Al incorporar la pérdida de tripleta en nuestros modelos, adquirimos la capacidad de enseñarles a reconocer patrones de una manera más refinada, abriendo emocionantes posibilidades para aplicaciones en campos como la visión por computadora, el procesamiento del lenguaje y mucho más.
# Referencias
- Schroff, et al (CVPR 2015) FaceNet: A Unified Embedding for Face Recognition and Clustering
- Hermans, et al (2017), In Defense of the Triplet Loss for Person Re-Identification
- Wu, et al. (ICLR 2021), When Do Curricula Work?



