
La generación mejorada por recuperación (RAG) es un marco de inteligencia artificial diseñado para mejorar un LLM al integrarlo con información recuperada de una base de conocimientos externa. Y dado el creciente enfoque que RAG ha obtenido últimamente, es razonable concluir que RAG es ahora un tema prominente en el ecosistema de IA/PNL (Inteligencia Artificial/Procesamiento del Lenguaje Natural). Por lo tanto, vamos a discutir qué esperar de los sistemas RAG cuando se combinan con LLM autohospedados.
En la publicación del blog titulada: “Descubre el aumento de rendimiento con la generación mejorada por recuperación (opens new window),”, investigamos cómo el número de documentos recuperados puede mejorar la calidad de las respuestas del LLM. También describimos cómo el LLM vectorizado basado en el conjunto de datos MMLU, almacenado en una base de datos vectorial como MyScale (opens new window), genera respuestas más precisas al integrarse con conocimientos contextualmente relevantes y sin ajustar finamente el conjunto de datos.
Por lo tanto, el punto destacado es:
RAG llena las lagunas de conocimiento, reduciendo las alucinaciones al mejorar las indicaciones con datos externos.
El uso de API de LLM externos en su aplicación puede plantear riesgos potenciales para la seguridad de los datos, disminuir el control y aumentar significativamente los costos, especialmente con un alto volumen de usuarios. Por lo tanto, la pregunta que surge es:
¿Cómo puede garantizar una mayor seguridad de los datos y mantener el control sobre su sistema?
La respuesta concisa es utilizar un LLM autohospedado. Este enfoque no solo ofrece un control superior sobre los datos y el modelo, sino que también fortalece la privacidad y seguridad de los datos, al tiempo que mejora la eficiencia de costos.
# ¿Por qué LLM autohospedados?
Los modelos de lenguaje basados en la nube como servicio (como ChatGPT de OpenAI) son fáciles de acceder y pueden agregar valor a una amplia gama de dominios de aplicaciones, proporcionando acceso instantáneo y responsable. Sin embargo, los proveedores de LLM públicos pueden violar la seguridad y privacidad de los datos, así como plantear preocupaciones sobre el control excesivo, las filtraciones de conocimiento y la eficiencia de costos.
Nota:
Si alguna o todas estas preocupaciones le resultan familiares, entonces vale la pena utilizar un LLM autohospedado.
A medida que continuamos con nuestra discusión, analicemos en detalle estas cuatro preocupaciones importantes:
# 🔒 Privacidad
La privacidad debe ser una preocupación primordial al integrar API de LLM en su aplicación.
¿Por qué la privacidad es un problema?
La respuesta a esta pregunta tiene varias partes, como se destaca en los siguientes puntos:
- Los proveedores de servicios de LLM pueden utilizar su información personal para entrenamiento o análisis, comprometiendo la privacidad y seguridad.
- En segundo lugar, los proveedores de LLM podrían incorporar sus consultas de búsqueda en sus datos de entrenamiento.
Los LLM autohospedados resuelven estos problemas, ya que son seguros y sus datos nunca se exponen a una API de terceros.
# 🔧 Control
Los servicios de LLM, como OpenAI GPT-3.5, generalmente censuran temas como la violencia y la solicitud de consejos médicos. No tiene control sobre qué contenido se censura. Sin embargo, es posible que desee desarrollar su propio modelo de censura (y reglas).
¿Cómo adoptar un modelo de censura que cumpla con sus requisitos?
La respuesta teórica a grandes rasgos es que es preferible ajustar finamente un LLM mediante la construcción de filtros personalizados en lugar de utilizar indicaciones, ya que un modelo ajustado finamente es más estable. Además, alojar un modelo ajustado finamente proporciona la libertad de modificar y anular la censura predeterminada incluida en los LLM de dominio público.
# 📖 Filtraciones de conocimiento
Como se describió anteriormente, las filtraciones de conocimiento son una preocupación al utilizar un servidor de LLM de terceros, especialmente si se ejecutan consultas que incluyen información empresarial propietaria.
Nota:
Las posibles filtraciones de conocimiento fluyen en ambas direcciones, desde las indicaciones hasta el LLM y de vuelta a la aplicación de consulta.
¿Cómo prevenir las filtraciones de conocimiento?
En resumen, utilice un LLM autohospedado, no un LLM de dominio público, ya que su base de conocimientos empresariales propietarias es uno de sus activos más valiosos.
# 💰 Eficiencia de costos
Es discutible si los LLM autohospedados son eficientes en cuanto a costos en comparación con los LLM alojados en la nube. La investigación descrita en el artículo: "Cómo el procesamiento por lotes continuo permite un rendimiento 23 veces mayor en la inferencia de LLM mientras se reduce la latencia p50", informa que los LLM autohospedados son más rentables cuando se equilibra correctamente la latencia y el rendimiento con una estrategia avanzada de procesamiento por lotes continuo.
Nota:
Ampliamos este concepto más adelante en este texto.
# Maximizando su RAG con LLM autohospedados
![]()
Los LLM consumen recursos computacionales. Requieren una gran cantidad de recursos para inferir y servir respuestas. Agregar un RAG solo aumentará la necesidad de recursos computacionales, ya que pueden agregar más de 2,000 tokens a los tokens requeridos para responder preguntas para mejorar la precisión. Desafortunadamente, estos tokens adicionales incurren en costos adicionales, especialmente si está utilizando API de LLM de código abierto como OpenAI.
Estas cifras pueden mejorar al autohospedar un LLM, utilizando matrices y métodos como KV Cache (opens new window) y Continuous Batching (opens new window), mejorando la eficiencia a medida que aumentan sus indicaciones. Sin embargo, por otro lado, la mayoría de las plataformas de computación en GPU principales basadas en la nube, como RunPod (opens new window), facturan las horas de funcionamiento, no el rendimiento de los tokens: buenas noticias para los sistemas RAG autohospedados, lo que resulta en una tarifa de costo más baja por token de indicación.
La siguiente tabla cuenta su propia historia: los LLM autohospedados combinados con RAG pueden proporcionar eficiencia de costos y precisión. En resumen:
- El costo se reduce a solo el 10% de
gpt-3.5-turbocuando se maximiza. - El pipeline RAG
llama-2-13b-chatcon diez contextos solo cuesta $0.04 por 1840 tokens, un tercio del costo degpt-3.5-turbosin ningún contexto.
Nota:
Consulte nuestra primera publicación de blog sobre RAG (opens new window) para obtener más detalles sobre el aumento de rendimiento con RAG.
Tabla: Comparación total de costos en centavos de dólar estadounidense
| # Contextos | Tokens promedio | Ganancia de precisión LLaMA-2-13B | llama-2-13b-chat @ 1 hilo | llama-2-13b-chat @ 8 hilos | llama-2-13b-chat @ 32 hilos | gpt-3.5-turbo |
|---|---|---|---|---|---|---|
| 0 | 417 | +0.00% | 0.3090 | 0.0423 | 0.0143 | 0.1225 |
| 1 | 554 | +4.83% | 0.3151 | 0.0450 | 0.0166 | 0.1431 |
| 3 | 737 | +6.80% | 0.3366 | 0.0514 | 0.0201 | 0.1705 |
| 5 | 1159 | +9.07% | 0.3627 | 0.0575 | 0.0271 | 0.2339 |
| 10 | 1840 | +8.77% | 0.4207 | 0.0717 | 0.0400 | 0.3360 |
# Nuestra metodología
Utilizamos text-generation-inference (opens new window) para ejecutar un modelo llama-2-13b-chat no cuantizado para todas las evaluaciones en este artículo. También alquilamos un pod en la nube con 1x NVIDIA A100 80GB, que cuesta $1.99 por hora. Un pod de este tamaño puede implementar llama-2-13b-chat. Es importante destacar que cada figura utiliza el primer cuartil como límite inferior y el tercer cuartil como límite superior, representando visualmente la dispersión de los datos mediante diagramas de caja.
Nota:
Implementar modelos con 70B requiere más memoria GPU disponible.
# Empujando el rendimiento del LLM al límite
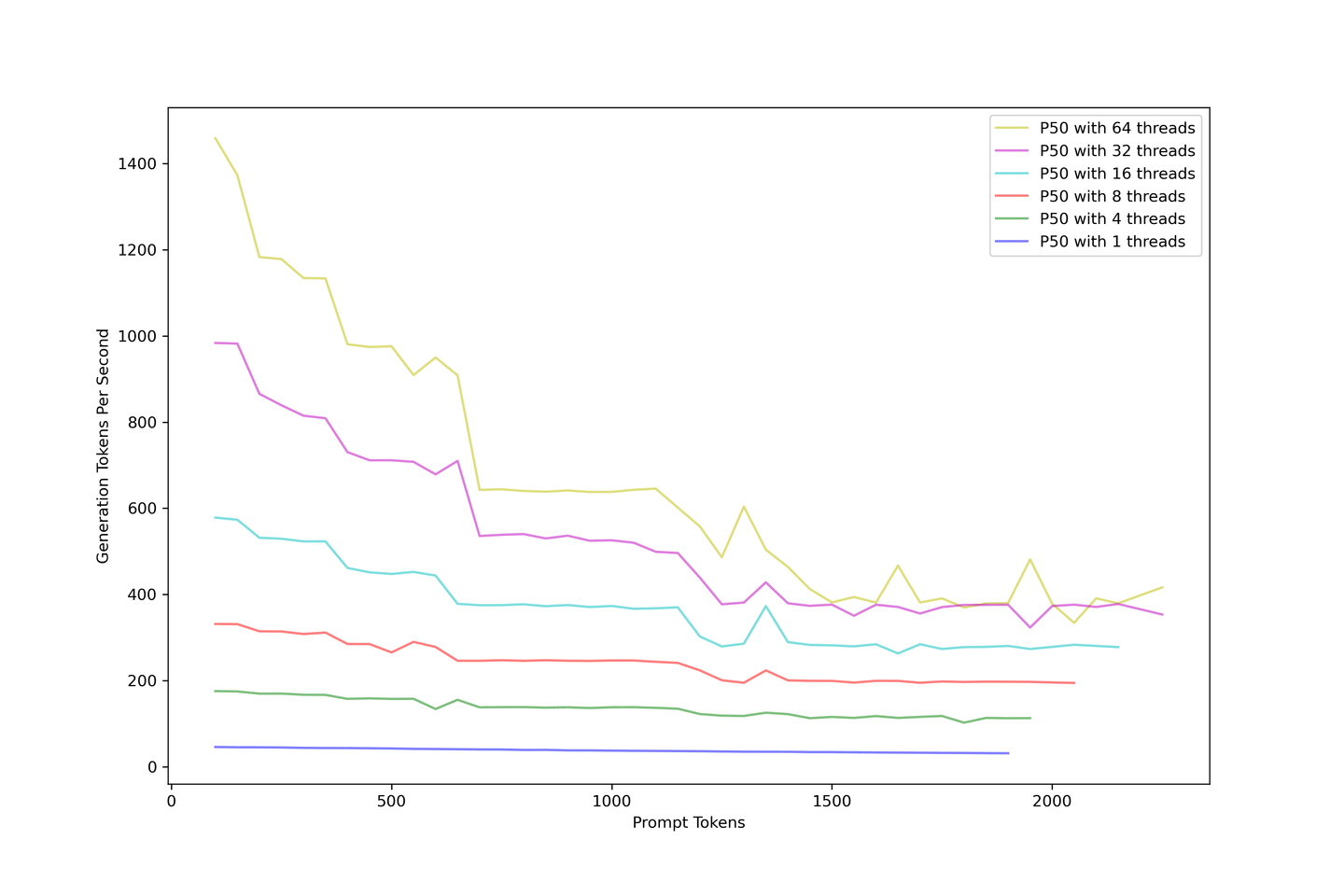
El rendimiento general debe ser lo primero que se considere. Sobrecargamos el LLM de 1 a 64 hilos para simular muchas consultas entrantes simultáneas. La imagen a continuación describe cómo disminuye el rendimiento de generación con indicaciones más grandes. El rendimiento de generación converge alrededor de 400 tokens por segundo, sin importar cómo aumente la concurrencia.
Agregar indicaciones reduce el rendimiento. Como solución, recomendamos utilizar un RAG con menos de 10 contextos para equilibrar la precisión y el rendimiento.
# Medición del tiempo de inicio para indicaciones más largas
La capacidad de respuesta del modelo es crítica para nosotros. También sabemos que el proceso de generación para el modelado de lenguaje casual es iterativo. Para mejorar el tiempo de respuesta del modelo, almacenamos en caché los resultados de la generación anterior para reducir el tiempo de cálculo con KV Cache. Llamamos a este proceso "inicio" al generar un LLM utilizando KV Cache.
Nota:
Siempre deberá calcular claves y valores para todas las indicaciones de entrada al comienzo del proceso.

A medida que aumentamos la longitud de la indicación, continuamos evaluando el tiempo de inicio del modelo. El siguiente gráfico utiliza una escala logarítmica para ilustrar el tiempo de inicio.
Los siguientes puntos se refieren a este gráfico:
- Los tiempos de inicio con menos de 32 hilos son aceptables.
- El tiempo de inicio de la mayoría de las muestras está por debajo de 1000 ms.
- El tiempo de inicio aumenta drásticamente cuando aumentamos la concurrencia.
- Los ejemplos que utilizan 64 hilos comienzan por encima de 1000 ms y terminan alrededor de 10 segundos.
- Eso es demasiado tiempo para que los usuarios esperen.
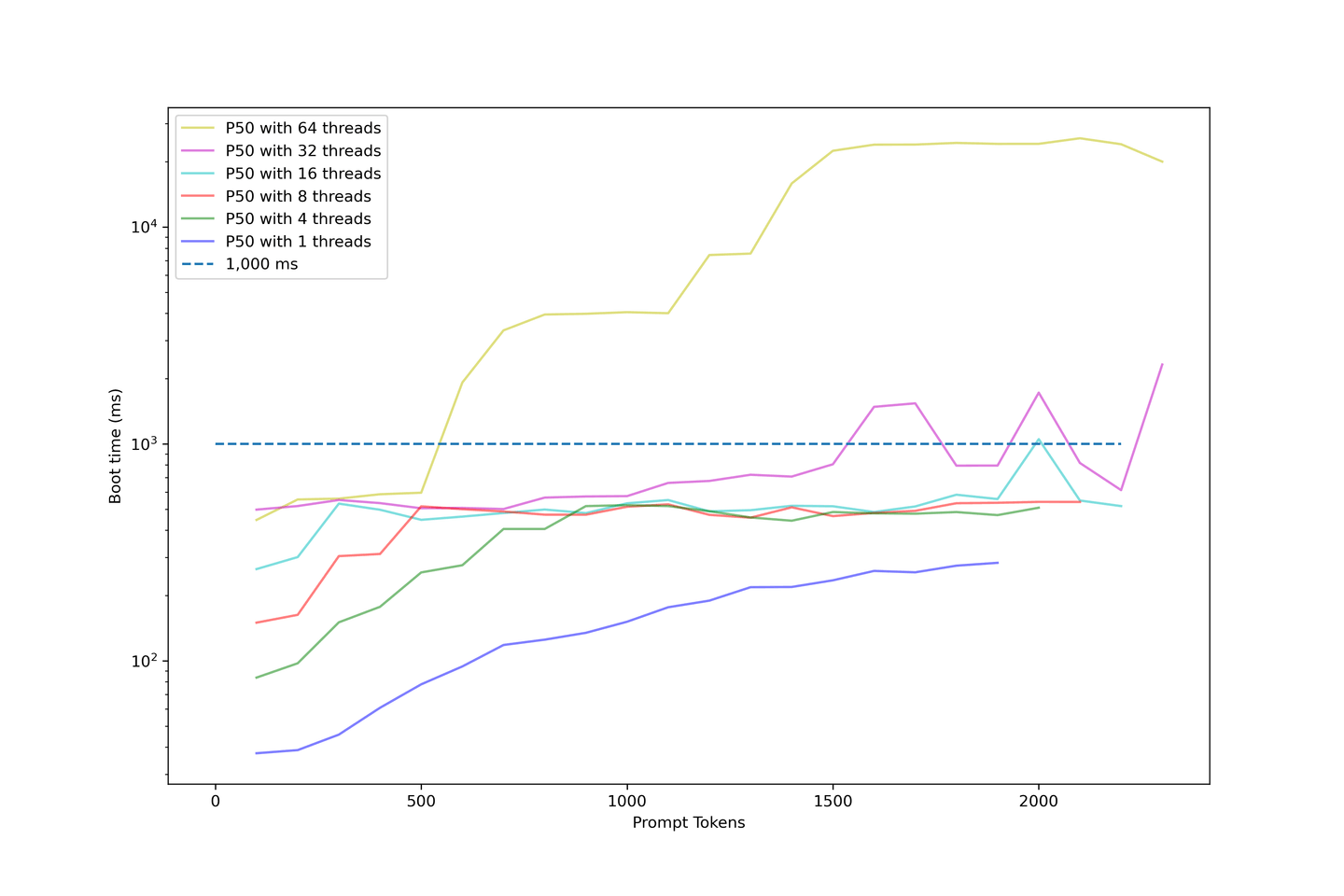
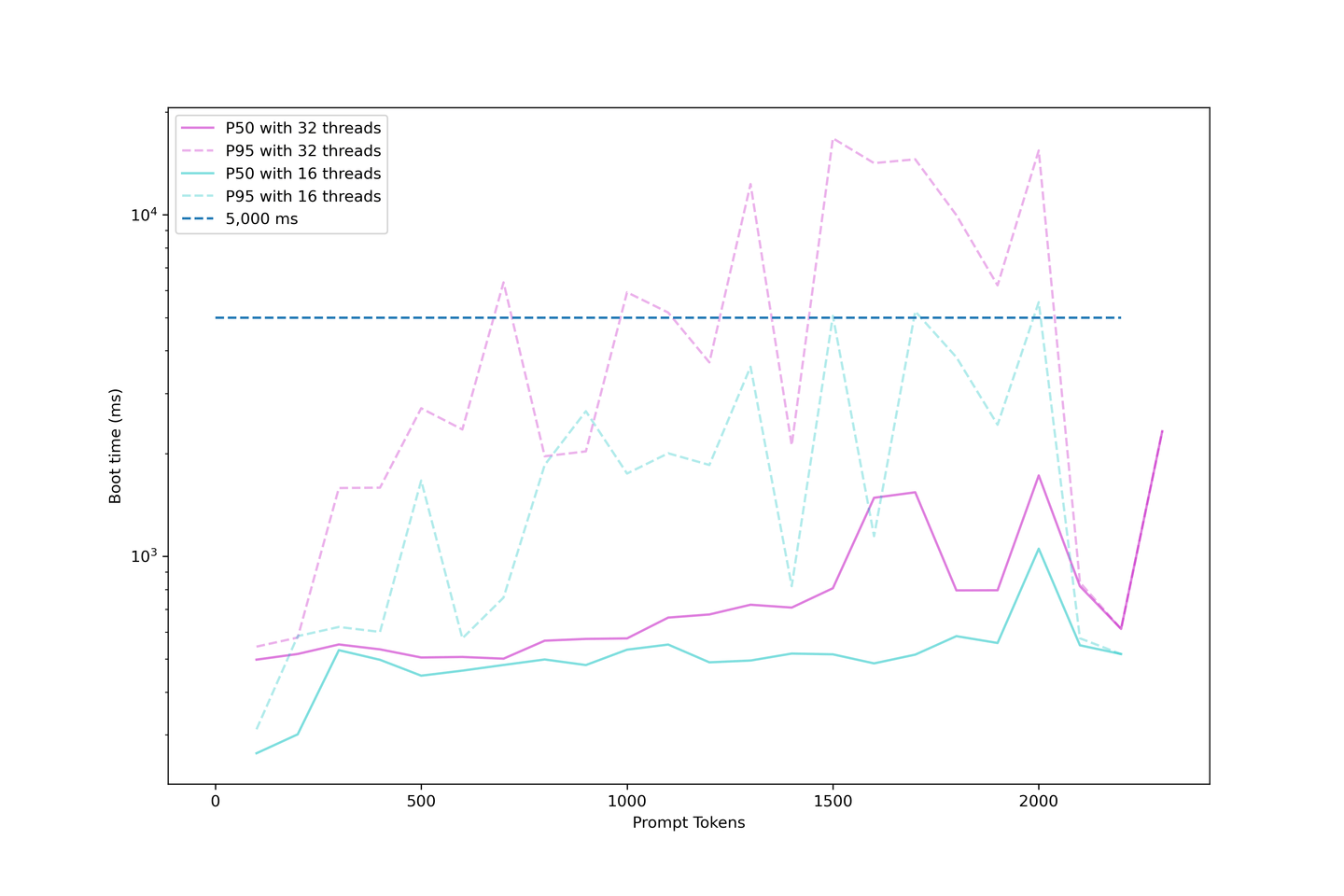
Nuestra configuración muestra un tiempo de inicio promedio de alrededor de 1000 ms cuando la concurrencia es inferior a 32 hilos. Por lo tanto, no recomendamos sobrecargar demasiado el LLM, ya que el tiempo de inicio se volverá ridículamente largo.
# Evaluación de la latencia de generación
Sabemos que la generación de LLM con KV Cache se puede categorizar como tiempo de inicio y tiempo de generación; podemos evaluar la latencia real de generación o el tiempo que tarda el usuario en esperar para ver el siguiente token en la aplicación.
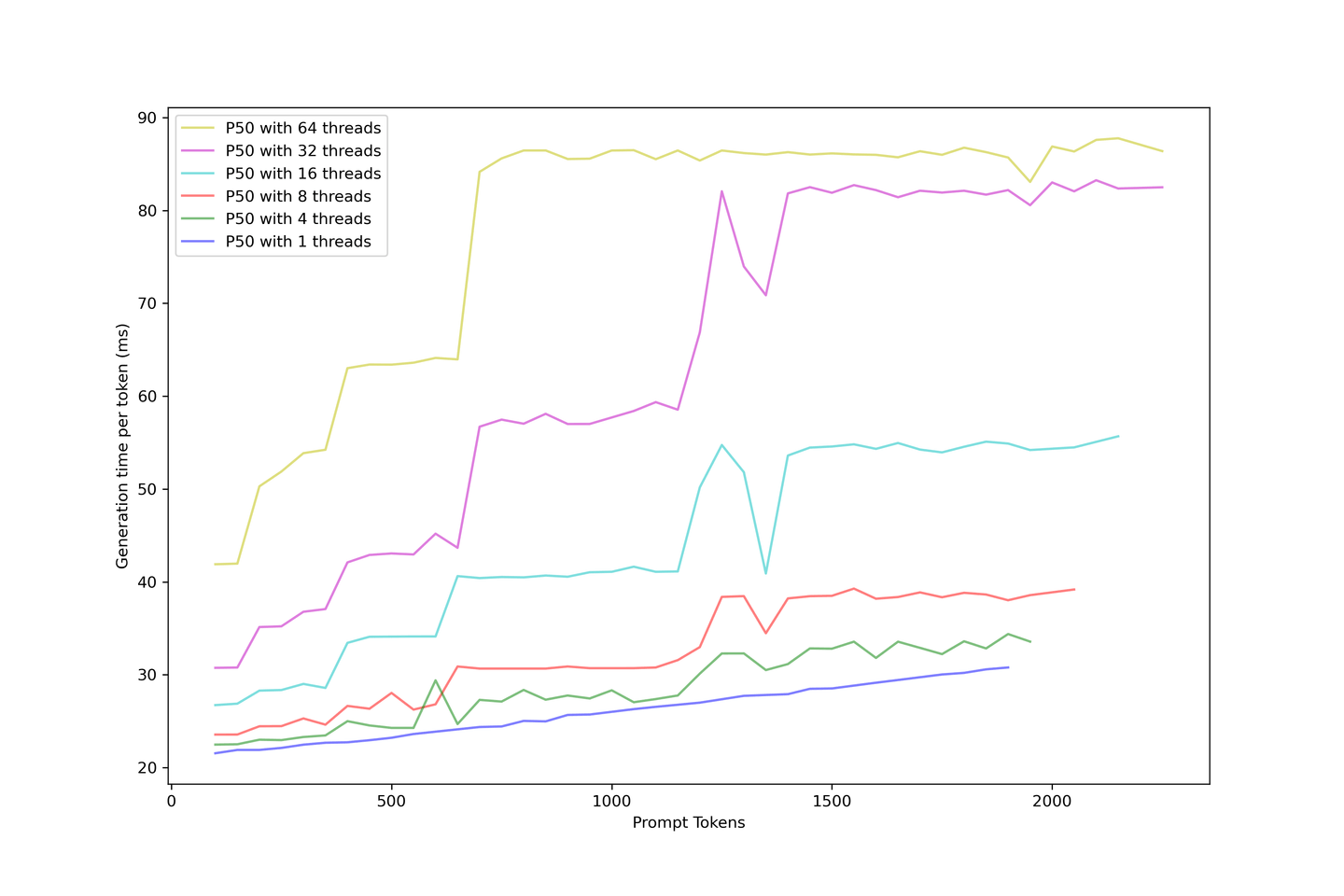
La latencia de generación es más estable que el tiempo de inicio porque las indicaciones más grandes en el proceso de inicio son difíciles de colocar en una estrategia de procesamiento por lotes continuo. Entonces, cuando tiene más solicitudes simultáneas, debe esperar hasta que las indicaciones anteriores estén en caché antes de que se muestre el siguiente token.
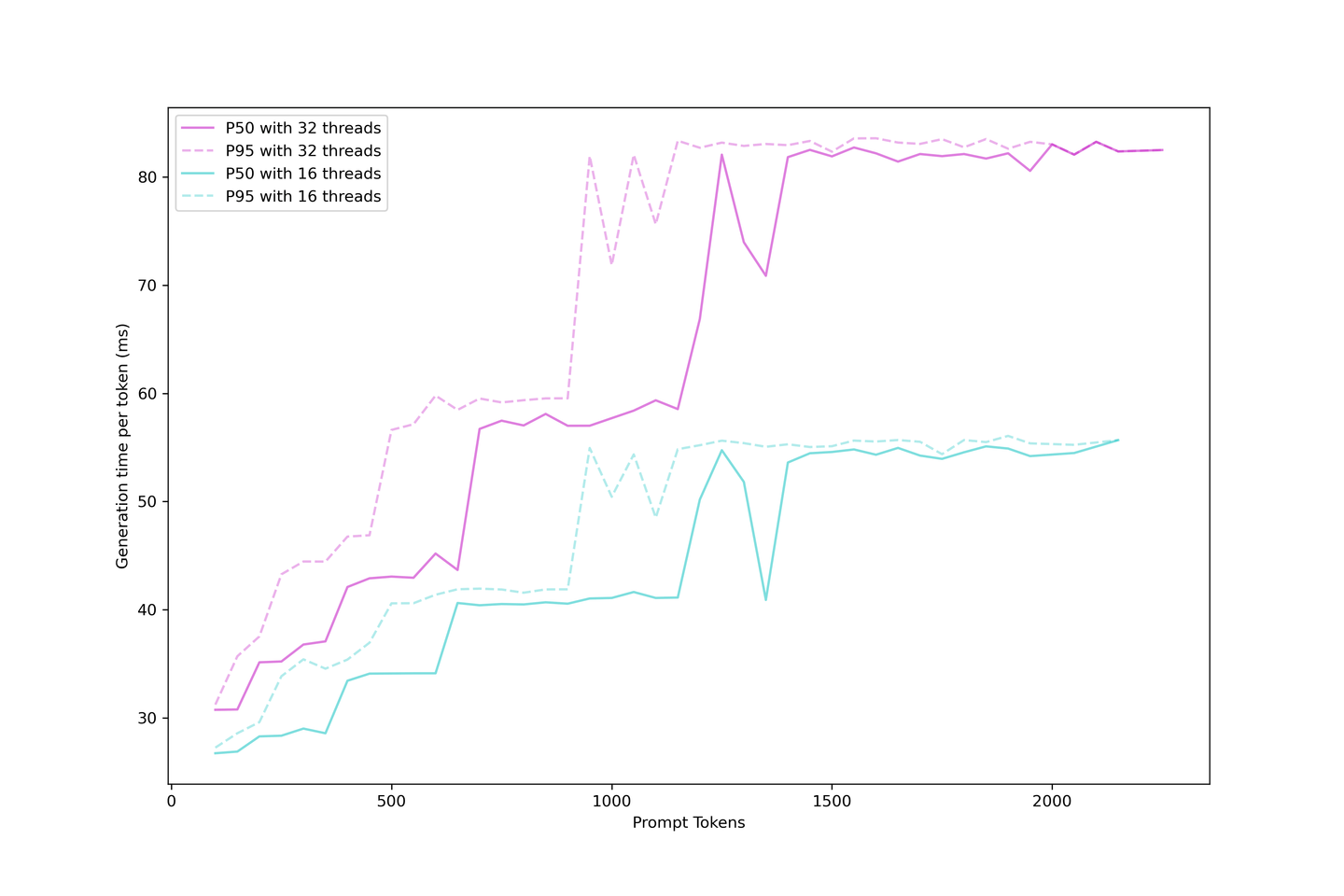
Por otro lado, la generación es mucho más sencilla una vez que se construye la caché, ya que la caché KV reduce el número de iteraciones y la generación se programa una vez que hay un lugar disponible en el lote. La latencia aumenta en diferentes pasos, con estos pasos llegando antes con indicaciones más grandes y el lote está saturado. Pronto, más solicitudes agotarán el LLM, aumentando el límite al atender más solicitudes.
Es razonable esperar siempre una latencia de generación inferior a 90 ms e incluso alrededor de 60 ms si no se presiona demasiado en los contextos y la concurrencia. En consecuencia, recomendamos cinco contextos con una concurrencia de 32 en esta configuración.
# Comparación de costos de gpt-3.5-turbo
Nos interesa mucho saber cuánto cuesta esta solución. Por lo tanto, estimamos el costo utilizando los datos recopilados anteriormente y creamos el siguiente modelo de costos para nuestro pipeline:
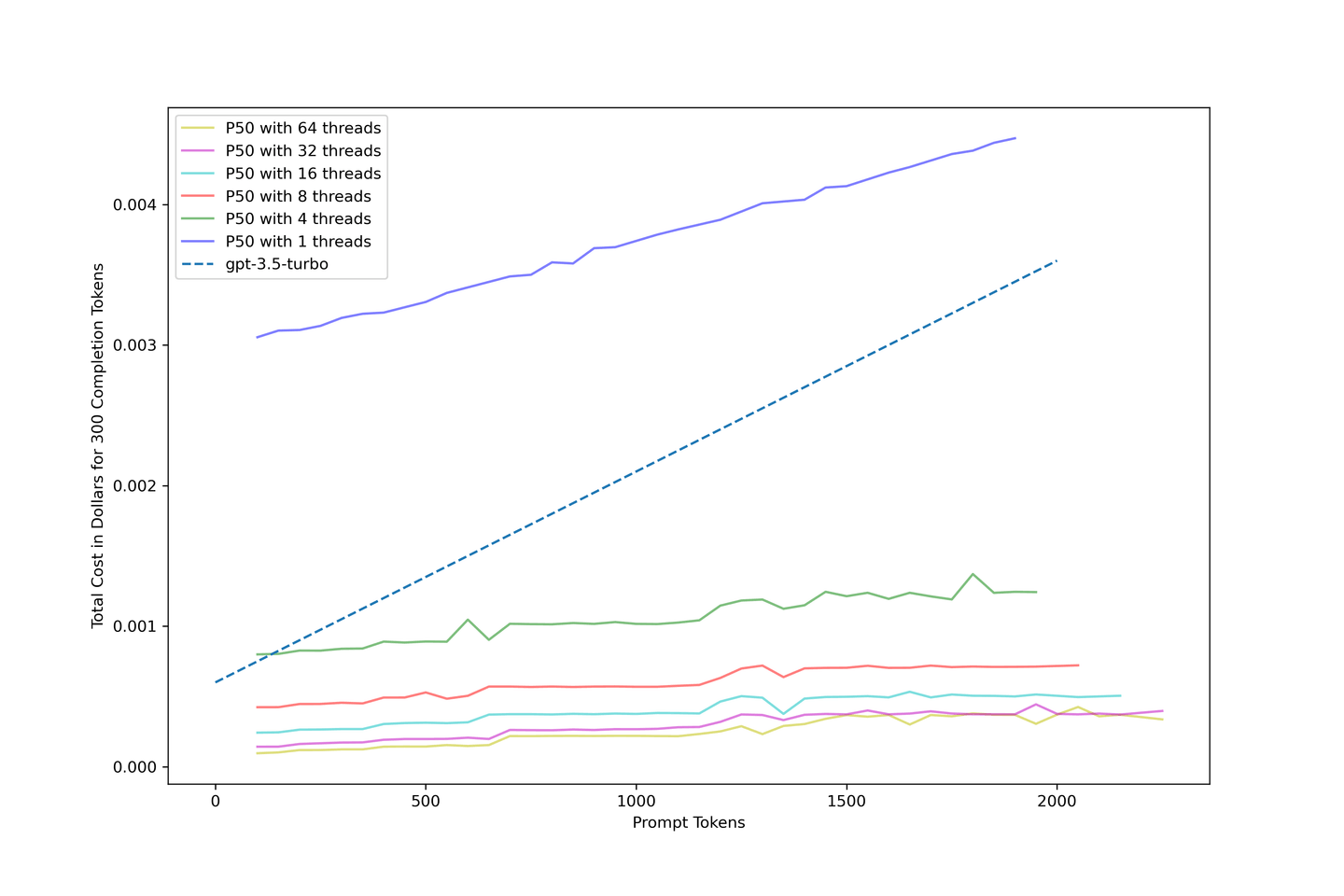
El uso de KV Cache y el procesamiento por lotes continuo mejora la eficiencia de costos del sistema, reduciendo los costos a una décima parte de gpt-3.5-turbo con la configuración correcta. Se recomienda una concurrencia de 32 hilos para obtener resultados óptimos.
# ¿Qué sigue?
La última pregunta que nos hacemos es:
¿Qué podemos aprender de estos gráficos y hacia dónde vamos desde aquí?
# Equilibrio entre latencia y rendimiento
Siempre hay un equilibrio entre latencia y rendimiento. Estimar su uso diario y la tolerancia de sus usuarios a la latencia es un buen punto de partida. Para maximizar su rendimiento por dólar, le recomendamos que espere una concurrencia de 32 hilos en 1x NVIDIA A100 80GB con llama-2-13b u otros modelos similares. Le brinda el mejor rendimiento, una latencia relativamente baja y un presupuesto razonable. Siempre puede cambiar su decisión; recuerde siempre estimar su caso de uso primero.
# Ajuste fino del modelo: más largo y más fuerte
Ahora puede ajustar finamente su modelo con sistemas RAG. Esto ayudará al modelo a acostumbrarse a contextos largos. Hay repositorios de código abierto que ajustan finamente los LLM para una longitud de entrada más larga, como Long-LLaMA (opens new window). Los modelos ajustados finamente con contextos más largos son buenos aprendices en contexto y tienen un mejor rendimiento que los modelos estirados por reescalado RoPE (opens new window).
# Combinar MyScale con un sistema RAG: análisis de costo de inferencia frente a base de datos
Al combinar MyScale y 10 GPU A100 de RunPod con MyScale (base de datos vectorial), puede configurar fácilmente un sistema RAG llama2-13B + base de conocimientos de Wikipedia, que se adapta perfectamente a las necesidades de hasta 100 usuarios concurrentes.
Antes de concluir esta discusión, consideremos un análisis de costo simple de ejecutar dicho sistema:
| Producto recomendado | Especificaciones sugeridas | Costo aproximado/mes (USD) |
|---|---|---|
| RunPod | 10 GPU A100 | $14,000 |
| MyScale | 40 millones de vectores (registros) x 2 réplicas | $2,000 |
| Total | $16,000 |
Nota:
- Estos costos son una aproximación basada en los cálculos de costo resaltados anteriormente.
- Los sistemas RAG a gran escala mejoran significativamente el rendimiento del LLM con menos del 15% de costo adicional en el servicio de base de datos vectorial.
- El costo amortizado de la base de datos vectorial será aún menor a medida que aumente el número de usuarios.

# En conclusión...
Es intuitivo concluir que las indicaciones adicionales en RAG cuestan más y son más lentas. Sin embargo, nuestras evaluaciones muestran que esta es una solución factible para aplicaciones del mundo real. Esta evaluación también examinó qué esperar de los LLM autohospedados, evaluando el costo y el rendimiento general de esta solución y ayudándole a construir su modelo de costos al implementar un LLM con la base de conocimientos externa.
¡Finalmente, podemos ver que la eficiencia de costos de MyScale hace que los sistemas RAG sean mucho más escalables!
Por lo tanto, si está interesado en evaluar el rendimiento de QA de los pipelines RAG, únase a nosotros en discord (opens new window) o Twitter (opens new window). ¡También puede evaluar sus propios pipelines RAG con RQABenchmark (opens new window)!
¡Lo mantendremos informado con nuestros últimos hallazgos sobre LLM y bases de datos vectoriales!



